mirror of
https://github.com/lobehub/lobe-chat.git
synced 2026-06-14 19:50:09 +00:00
Compare commits
37 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
01ac0c438a | ||
|
|
99023811d8 | ||
|
|
480a2979e1 | ||
|
|
531900cf70 | ||
|
|
c9325794e5 | ||
|
|
4a11ed9887 | ||
|
|
be7b759820 | ||
|
|
fa76928f62 | ||
|
|
f6db1361ee | ||
|
|
5d6eaf53f3 | ||
|
|
c4e4469083 | ||
|
|
800b534741 | ||
|
|
03b9d07d0b | ||
|
|
f60d1fe8dd | ||
|
|
e5a27dc97c | ||
|
|
c7e0c83174 | ||
|
|
ab958a0b98 | ||
|
|
5362be4078 | ||
|
|
6887930428 | ||
|
|
da94942d9c | ||
|
|
a9141c8ade | ||
|
|
8ab5ec5364 | ||
|
|
222534dbe1 | ||
|
|
f31c94490d | ||
|
|
52eaf2702e | ||
|
|
ce81ea44bf | ||
|
|
29974d3ab9 | ||
|
|
f4c431b028 | ||
|
|
34fbd9ffd3 | ||
|
|
09b5e926bf | ||
|
|
d3e8e7cb65 | ||
|
|
60bed5782f | ||
|
|
35b6bc55b8 | ||
|
|
365dd1ff64 | ||
|
|
7633c0e83f | ||
|
|
87b1f39c0f | ||
|
|
ca91d2d756 |
@@ -38,9 +38,9 @@ lists `packages/**`, `e2e`, `apps/server`, and only `apps/desktop/src/main` —
|
||||
refresh them, so install in every app the test will touch:
|
||||
|
||||
```bash
|
||||
pnpm install # root workspace
|
||||
cd apps/desktop && pnpm install # Electron surface
|
||||
cd apps/cli && pnpm install # CLI surface
|
||||
pnpm install # root workspace
|
||||
cd apps/desktop && pnpm install # Electron surface
|
||||
cd apps/cli && pnpm install # CLI surface
|
||||
```
|
||||
|
||||
Symptom of a stale standalone install: the build/launch fails to resolve a
|
||||
@@ -55,7 +55,94 @@ directory — a script launched while `cwd` is `apps/desktop` fails with
|
||||
`No such file or directory`. Verify `pwd` is the repo root before launching
|
||||
long-running scripts.
|
||||
|
||||
### 0.3 Auth is green
|
||||
### 0.3 Init local dev env without `.env`
|
||||
|
||||
For Web smoke against local code, start a **normal local dev environment**.
|
||||
First check the repo root for `.env`:
|
||||
|
||||
- If `.env` exists, use the existing local configuration and start the dev
|
||||
server normally.
|
||||
- If `.env` does not exist, use the agent-testing env bootstrap.
|
||||
|
||||
Do not start the standalone e2e server as the product under test.
|
||||
|
||||
Use `scripts/init-dev-env.sh`. It follows the e2e setup pattern — Postgres,
|
||||
migrations, auth/key-vault/S3 test env, seed user — but it is owned by this
|
||||
skill and starts the repo's dev server (`pnpm run dev:next` / `bun run dev`),
|
||||
not `e2e/scripts/setup.ts --start`. The script hard-blocks when root `.env`
|
||||
exists, so it cannot accidentally override a user's local config. When `.env`
|
||||
exists, do not call any `init-dev-env.sh` subcommand.
|
||||
|
||||
Decision flow:
|
||||
|
||||
```bash
|
||||
if [[ -f .env ]]; then
|
||||
bun run dev
|
||||
else
|
||||
./.agents/skills/agent-testing/scripts/init-dev-env.sh setup-db
|
||||
./.agents/skills/agent-testing/scripts/init-dev-env.sh seed-user
|
||||
./.agents/skills/agent-testing/scripts/init-dev-env.sh dev
|
||||
fi
|
||||
```
|
||||
|
||||
Bootstrap flow when no `.env` exists:
|
||||
|
||||
```bash
|
||||
# From repo root. Managed DB flow requires Docker Desktop.
|
||||
./.agents/skills/agent-testing/scripts/init-dev-env.sh setup-db
|
||||
./.agents/skills/agent-testing/scripts/init-dev-env.sh seed-user
|
||||
./.agents/skills/agent-testing/scripts/init-dev-env.sh dev
|
||||
```
|
||||
|
||||
If using an existing Postgres instead of the managed Docker DB, set
|
||||
`DATABASE_URL` and skip `setup-db`:
|
||||
|
||||
```bash
|
||||
DATABASE_URL=postgresql://... ./.agents/skills/agent-testing/scripts/init-dev-env.sh migrate
|
||||
DATABASE_URL=postgresql://... ./.agents/skills/agent-testing/scripts/init-dev-env.sh seed-user
|
||||
DATABASE_URL=postgresql://... ./.agents/skills/agent-testing/scripts/init-dev-env.sh dev
|
||||
```
|
||||
|
||||
For backend-only checks, `dev-next` is available, but Web smoke needs the
|
||||
full-stack `dev` command so Next can proxy the SPA HTML from Vite:
|
||||
|
||||
```bash
|
||||
./.agents/skills/agent-testing/scripts/init-dev-env.sh dev-next
|
||||
```
|
||||
|
||||
Useful subcommands:
|
||||
|
||||
```bash
|
||||
./.agents/skills/agent-testing/scripts/init-dev-env.sh env # print exports
|
||||
./.agents/skills/agent-testing/scripts/init-dev-env.sh write # write .records/env/agent-testing-dev.env
|
||||
./.agents/skills/agent-testing/scripts/init-dev-env.sh migrate # migrations only
|
||||
./.agents/skills/agent-testing/scripts/init-dev-env.sh clean-db # remove managed DB container
|
||||
```
|
||||
|
||||
Default script env:
|
||||
|
||||
- `APP_URL=http://localhost:3010`
|
||||
- `DATABASE_URL=postgresql://postgres:postgres@localhost:5433/postgres`
|
||||
- `DATABASE_DRIVER=node`
|
||||
- `FEATURE_FLAGS=-agent_self_iteration` so local smoke does not require QStash
|
||||
- `KEY_VAULTS_SECRET`, `AUTH_SECRET`, auth verification off
|
||||
- S3 mock vars
|
||||
- Managed DB container: `lobehub-agent-testing-postgres`
|
||||
|
||||
`seed-user` creates `agent-testing@lobehub.com` / `TestPassword123!` with
|
||||
onboarding already completed for manual or agent-browser checks. When running
|
||||
Cucumber against this dev server, pass the same script env into the test process
|
||||
too; Cucumber has its own `BeforeAll` seed path and it must see `DATABASE_URL`
|
||||
instead of silently skipping setup:
|
||||
|
||||
```bash
|
||||
cd e2e
|
||||
# Only in the no-.env branch.
|
||||
eval "$(../.agents/skills/agent-testing/scripts/init-dev-env.sh env)"
|
||||
BASE_URL=http://localhost:3010 HEADLESS=true bun run test:smoke
|
||||
```
|
||||
|
||||
### 0.4 Auth is green
|
||||
|
||||
**Auth is the gate for all automated testing.**
|
||||
|
||||
@@ -63,12 +150,12 @@ long-running scripts.
|
||||
./.agents/skills/agent-testing/scripts/setup-auth.sh status
|
||||
```
|
||||
|
||||
| Surface | Mechanism | One-key path | Standard check |
|
||||
| -------- | ------------------------------------------------- | ------------------------------ | ------------------------------ |
|
||||
| CLI | OIDC Device Code Flow (`apps/cli/.lobehub-dev`) | `setup-auth.sh cli` | `setup-auth.sh status` |
|
||||
| Web | better-auth cookie injection into `agent-browser` | `pbpaste \| setup-auth.sh web` | `setup-auth.sh web-verify` |
|
||||
| Electron | App's own persistent login state | Log in once in the app | `app-probe.sh auth` |
|
||||
| Bot | Native apps already logged in | — | per-platform screenshot |
|
||||
| Surface | Mechanism | One-key path | Standard check |
|
||||
| -------- | ------------------------------------------------- | ------------------------------ | -------------------------- |
|
||||
| CLI | OIDC Device Code Flow (`apps/cli/.lobehub-dev`) | `setup-auth.sh cli` | `setup-auth.sh status` |
|
||||
| Web | better-auth cookie injection into `agent-browser` | `pbpaste \| setup-auth.sh web` | `setup-auth.sh web-verify` |
|
||||
| Electron | App's own persistent login state | Log in once in the app | `app-probe.sh auth` |
|
||||
| Bot | Native apps already logged in | — | per-platform screenshot |
|
||||
|
||||
Login-state checks are standardized — do NOT hand-roll `window.__LOBE_STORES`
|
||||
eval snippets; use `scripts/app-probe.sh auth` (returns `{ isSignedIn, userId }`,
|
||||
@@ -148,17 +235,18 @@ Surface guides above carry the detailed workflows. Shared infrastructure:
|
||||
|
||||
All under `.agents/skills/agent-testing/scripts/`:
|
||||
|
||||
| Script | Usage |
|
||||
| ------------------------- | ------------------------------------------------------------------------------ |
|
||||
| `setup-auth.sh` | One-stop auth setup & status check (`status` / `cli` / `web`) |
|
||||
| `app-probe.sh` | LobeHub app probes: `auth` / `route` / `ops` / `goto <path>` / `errors` |
|
||||
| `record-gif.sh` | Frame-sequence → GIF for time-based behavior (streaming, timers, animations) |
|
||||
| `report-init.sh` | Scaffold a structured test report (Step 3) |
|
||||
| `electron-dev.sh` | Manage Electron dev env (start/stop/status/restart, CDP 9222) |
|
||||
| `capture-app-window.sh` | Screenshot a specific app window (general; used by bot tests) |
|
||||
| `record-app-screen.sh` | Record app screen (video + periodic screenshots) |
|
||||
| `record-electron-demo.sh` | Record Electron app demo with ffmpeg |
|
||||
| `agent-gateway/` | Gateway probe / dump / analyze tools |
|
||||
| Script | Usage |
|
||||
| ------------------------- | ---------------------------------------------------------------------------- |
|
||||
| `setup-auth.sh` | One-stop auth setup & status check (`status` / `cli` / `web`) |
|
||||
| `init-dev-env.sh` | Self-contained local dev env (`setup-db` / `seed-user` / `dev-next` / `dev`) |
|
||||
| `app-probe.sh` | LobeHub app probes: `auth` / `route` / `ops` / `goto <path>` / `errors` |
|
||||
| `record-gif.sh` | Frame-sequence → GIF for time-based behavior (streaming, timers, animations) |
|
||||
| `report-init.sh` | Scaffold a structured test report (Step 3) |
|
||||
| `electron-dev.sh` | Manage Electron dev env (start/stop/status/restart, CDP 9222) |
|
||||
| `capture-app-window.sh` | Screenshot a specific app window (general; used by bot tests) |
|
||||
| `record-app-screen.sh` | Record app screen (video + periodic screenshots) |
|
||||
| `record-electron-demo.sh` | Record Electron app demo with ffmpeg |
|
||||
| `agent-gateway/` | Gateway probe / dump / analyze tools |
|
||||
|
||||
`app-probe.sh` is the LobeHub-specific fast path into app state — auth check,
|
||||
current route, running operations, and `goto <path>` quick navigation
|
||||
@@ -174,12 +262,13 @@ not a chat-only summary. Scaffold it up front and fill it as you test:
|
||||
```bash
|
||||
DIR=$(./.agents/skills/agent-testing/scripts/report-init.sh my-feature "Verify my feature")
|
||||
# ... test, saving screenshots / CLI transcripts into $DIR/assets/ ...
|
||||
# fill $DIR/report.md (case table, embedded evidence, verdict) and $DIR/result.json
|
||||
# fill $DIR/report.md (scope, case table with inline evidence, verdict, score) and $DIR/result.json
|
||||
```
|
||||
|
||||
Reports live in `.records/reports/<timestamp>-<slug>/` (gitignored): `report.md`
|
||||
(human-readable, with embedded screenshots), `result.json` (machine-readable
|
||||
pass/fail + score), `assets/` (evidence). Format spec and evidence rules:
|
||||
(human-readable, with screenshots/GIFs embedded directly in the case table),
|
||||
`result.json` (machine-readable pass/fail + score), `assets/` (evidence).
|
||||
Format spec and evidence rules:
|
||||
[references/report.md](./references/report.md).
|
||||
|
||||
Two hard rules worth front-loading:
|
||||
@@ -187,6 +276,14 @@ Two hard rules worth front-loading:
|
||||
- **Report language = the user's conversation language.** Write the ENTIRE
|
||||
`report.md` (headings included) in the language the user is conversing in —
|
||||
no mixed English. `result.json` keys/status values stay English.
|
||||
- **The case table is the main reading surface.** Prefer the compact
|
||||
`# | case | result | key observation | evidence` shape and embed the
|
||||
screenshot/GIF in the evidence cell. Use separate evidence sections only for
|
||||
long CLI transcripts, HAR summaries, or supplemental detail.
|
||||
- **Visual evidence must render inline.** Screenshots and GIFs in `report.md`
|
||||
must use Markdown image syntax like ``. Do not
|
||||
use bare file paths, Markdown links, or local file links as the primary
|
||||
visual evidence; those make the report unreadable without opening each asset.
|
||||
- **Time-based behavior needs a GIF, not a screenshot.** If a case asserts
|
||||
change over time (streaming output, a ticking timer, loading states,
|
||||
animations), record it with `scripts/record-gif.sh` and embed the GIF —
|
||||
|
||||
@@ -8,7 +8,7 @@ surfaces (CLI, Electron, Web) hit.
|
||||
| Command | What it runs | Port |
|
||||
| ------------------- | --------------------------------------------------------- | --------------------------------- |
|
||||
| `pnpm run dev:next` | Next.js backend (API + auth) | `3010` |
|
||||
| `bun run dev` | Full-stack (Next.js + Vite SPA, via `devStartupSequence`) | `3010` (API) + SPA |
|
||||
| `bun run dev` | Full-stack (Next.js + Vite SPA, via `devStartupSequence`) | `3010` (API) + SPA on `9876` |
|
||||
| `bun run dev:spa` | Vite SPA only, proxies API to `3010` | `9876` (prints a Debug Proxy URL) |
|
||||
|
||||
In the **cloud repo** (where this repo is the `lobehub/` submodule) the dev
|
||||
@@ -24,12 +24,25 @@ curl -s -o /dev/null -w '%{http_code}' http://localhost:3010/
|
||||
## Start / restart
|
||||
|
||||
```bash
|
||||
# Start (from repo root)
|
||||
# Start backend only.
|
||||
# With root .env: use the existing local config.
|
||||
pnpm run dev:next
|
||||
|
||||
# Without root .env: use the self-contained agent-testing env.
|
||||
./.agents/skills/agent-testing/scripts/init-dev-env.sh dev-next
|
||||
|
||||
# Full-stack SPA + backend. Required for Web smoke.
|
||||
# With root .env:
|
||||
bun run dev
|
||||
|
||||
# Without root .env:
|
||||
./.agents/skills/agent-testing/scripts/init-dev-env.sh dev
|
||||
|
||||
# Restart — required to pick up server-side code changes
|
||||
lsof -ti:3010 | xargs kill
|
||||
pnpm run dev:next
|
||||
# or, when no root .env exists:
|
||||
# ./.agents/skills/agent-testing/scripts/init-dev-env.sh dev-next
|
||||
```
|
||||
|
||||
## When a server restart is needed
|
||||
|
||||
@@ -11,7 +11,7 @@ output):
|
||||
|
||||
```
|
||||
.records/reports/<YYYYMMDD-HHMMSS>-<slug>/
|
||||
├── report.md # human-readable report (embedded screenshots, case table, verdict)
|
||||
├── report.md # human-readable report (case table with inline screenshots, verdict)
|
||||
├── result.json # machine-readable results (pass/fail counts, score)
|
||||
└── assets/ # evidence: screenshots, HAR files, CLI transcripts
|
||||
```
|
||||
@@ -25,13 +25,16 @@ output):
|
||||
```
|
||||
|
||||
The script creates the directory, pre-fills branch / commit / date in both
|
||||
files, and prints the directory path.
|
||||
files, and prints the directory path. The scaffold uses the compact report
|
||||
shape below; translate its headings and table labels to the user's language
|
||||
before delivery if needed.
|
||||
|
||||
2. **Collect evidence as you test** — every asserted behavior gets one evidence
|
||||
item in `$DIR/assets/`:
|
||||
- UI (static state): `agent-browser screenshot` or `capture-app-window.sh`,
|
||||
then **verify the screenshot with the Read tool before citing it** —
|
||||
never cite an image you haven't looked at.
|
||||
|
||||
- UI (time-based behavior): **screenshot vs GIF is a judgment you must
|
||||
make per case.** If the assertion is about change over time — streaming
|
||||
output, a ticking timer, loading/progress states, animations,
|
||||
@@ -48,10 +51,17 @@ output):
|
||||
|
||||
Embed it like an image: ``. Verify
|
||||
at least the first/last frames visually (Read the GIF) before citing.
|
||||
|
||||
- CLI: exact command + trimmed output (`$CLI task list | tee "$DIR/assets/task-list.txt"`).
|
||||
|
||||
- Network: `agent-browser network requests` dumps or HAR files.
|
||||
|
||||
3. **Fill `report.md` as you go** — don't reconstruct from memory at the end.
|
||||
The primary evidence belongs in the case table itself: each row should pair
|
||||
the assertion with the screenshot/GIF or non-visual artifact that proves it,
|
||||
so readers can scan the result without jumping between sections. UI evidence
|
||||
must render inline with Markdown image syntax; a plain link or file path is
|
||||
not acceptable as primary visual evidence.
|
||||
|
||||
4. **Set the verdict** in both `report.md` and `result.json`, then link the
|
||||
report directory in your final answer to the user.
|
||||
@@ -60,21 +70,69 @@ output):
|
||||
|
||||
**`report.md` MUST be written in the language the user is conversing in** —
|
||||
the whole file, headings included. If the conversation is in Chinese, the
|
||||
report is in Chinese; do not mix English prose into it. The scaffold's English
|
||||
headings are placeholders — translate them when filling. Exceptions that stay
|
||||
as-is: code/commands, identifiers, log excerpts, and `result.json` (its keys
|
||||
and status values are machine-read and stay English; the `title` and case
|
||||
`name` fields follow the user's language).
|
||||
report is in Chinese; do not mix English prose into it. The scaffold headings
|
||||
are placeholders — translate them when filling if the user is not conversing in
|
||||
the scaffold language. Exceptions that stay as-is: code/commands, identifiers,
|
||||
log excerpts, and `result.json` (its keys and status values are machine-read
|
||||
and stay English; the `title` and case `name` fields follow the user's
|
||||
language).
|
||||
|
||||
## report.md sections
|
||||
|
||||
| Section | Content |
|
||||
| --------------- | ---------------------------------------------------------------------------------- |
|
||||
| **Scope** | What changed / what is being verified; branch + commit |
|
||||
| **Environment** | Server URL, surfaces used (cli / electron / web / bot), relevant versions |
|
||||
| **Cases** | Table: `# \| case \| surface \| steps \| expected \| actual \| status \| evidence` |
|
||||
| **Evidence** | Embedded screenshots/GIFs (``), fenced CLI transcripts |
|
||||
| **Verdict** | Pass/fail/blocked counts, optional 0–100 score, open issues / follow-ups |
|
||||
Default report shape:
|
||||
|
||||
| Section | Content |
|
||||
| ---------------- | -------------------------------------------------------------------------------------------- |
|
||||
| **Scope** | What changed / what is being verified; branch, commit, date, surface, entry URL/page, focus |
|
||||
| **Cases** | Compact table: `# \| Case \| Result \| Key observation \| Evidence` |
|
||||
| **Verdict** | Overall verdict first (`pass` / `partial` / `fail`), then the concise reasons and follow-ups |
|
||||
| **Verification** | Commands or automated checks run in this session, with trimmed results |
|
||||
| **Score** | Pass/fail/blocked counts, optional 0–100 score |
|
||||
|
||||
The case table is the main reading surface. Prefer one clear row per user
|
||||
scenario or regression assertion, and put the screenshot/GIF directly in the
|
||||
`Evidence` cell:
|
||||
|
||||
```markdown
|
||||
| # | Case | Result | Key observation | Evidence |
|
||||
| --- | ------------------------ | ------ | ----------------------------------------------------------------- | ------------------------------------------------ |
|
||||
| 1 | Create a new page | pass | Title and body persisted after refresh |  |
|
||||
| 2 | Respect requested length | fail | Requested about 600 Chinese characters; final body was about 1286 |  |
|
||||
```
|
||||
|
||||
## Inline visual evidence
|
||||
|
||||
Screenshots and GIFs must be embedded so the report shows the image inline:
|
||||
|
||||
```markdown
|
||||

|
||||

|
||||
```
|
||||
|
||||
Do **not** use these as the primary evidence for UI cases:
|
||||
|
||||
```markdown
|
||||
[case 1 result](assets/case1-result.png)
|
||||
assets/case1-result.png
|
||||
file:///tmp/case1-result.png
|
||||
```
|
||||
|
||||
Links are acceptable for non-visual artifacts such as CLI transcripts, HAR
|
||||
files, or long logs. For videos, embed a representative screenshot/GIF inline in
|
||||
the case row and link the full video as supplemental evidence.
|
||||
|
||||
Avoid the old wide table with separate `steps`, `expected`, and `actual`
|
||||
columns unless the test is purely non-visual and truly needs that breakdown.
|
||||
For UI reports, those columns make screenshot-backed reading harder. Put
|
||||
procedural detail in the row's key observation only when it changes the
|
||||
interpretation of the result.
|
||||
|
||||
Use an extra evidence/detail section only when the inline table cannot carry
|
||||
the material cleanly, such as long CLI transcripts, HAR summaries, or multiple
|
||||
screenshots for one case. In that situation, keep the table evidence cell as an
|
||||
inline visual proof for UI cases or a concise link for non-visual artifacts,
|
||||
then put the longer material under `Verification` or a brief
|
||||
`Additional Evidence` section.
|
||||
|
||||
Status values: `pass` / `fail` / `blocked` (couldn't run — e.g. auth or env
|
||||
missing; a blocked case is not a pass).
|
||||
@@ -115,7 +173,8 @@ word the user reads first: `pass`, `fail`, or `partial`.
|
||||
## Rules
|
||||
|
||||
- **No evidence, no claim** — every `pass`/`fail` in the case table must link
|
||||
at least one asset.
|
||||
at least one asset. UI cases must inline-embed their primary screenshot/GIF;
|
||||
non-visual CLI/network cases may link transcripts, HAR files, or logs.
|
||||
- **Screenshots must be visually verified** with the Read tool before being
|
||||
cited.
|
||||
- **Report failures faithfully** — a failing case with clear evidence is a good
|
||||
|
||||
+290
@@ -0,0 +1,290 @@
|
||||
#!/usr/bin/env bash
|
||||
# init-dev-env.sh — self-contained local dev env for agent testing.
|
||||
#
|
||||
# This script initializes the env needed to run LobeHub's normal local dev
|
||||
# server without depending on a root .env file. It follows the same shape as
|
||||
# the e2e bootstrap (Postgres + migrations + auth/key-vault/S3 test env), but
|
||||
# starts the repo's dev server, not the standalone e2e server.
|
||||
#
|
||||
# Guardrail: if repo-root .env exists, every non-help command exits immediately.
|
||||
# Existing local config always wins.
|
||||
#
|
||||
# Usage:
|
||||
# init-dev-env.sh env # print shell exports
|
||||
# init-dev-env.sh write [file] # write a source-able env file
|
||||
# init-dev-env.sh setup-db # start local Postgres and run migrations
|
||||
# init-dev-env.sh migrate # run DB migrations against the configured DB
|
||||
# init-dev-env.sh seed-user # seed the baseline test user
|
||||
# init-dev-env.sh dev-next # exec `pnpm run dev:next` with this env
|
||||
# init-dev-env.sh dev # exec `bun run dev` with this env
|
||||
# init-dev-env.sh clean-db # remove the managed Postgres container
|
||||
#
|
||||
# Overrides:
|
||||
# SERVER_PORT=3010 DB_PORT=5433 DB_CONTAINER=lobehub-agent-testing-postgres
|
||||
|
||||
set -euo pipefail
|
||||
|
||||
REPO_ROOT="$(cd "$(dirname "${BASH_SOURCE[0]}")/../../../.." && pwd)"
|
||||
ROOT_ENV_FILE="$REPO_ROOT/.env"
|
||||
|
||||
SERVER_PORT="${SERVER_PORT:-3010}"
|
||||
DB_PORT="${DB_PORT:-5433}"
|
||||
DB_CONTAINER="${DB_CONTAINER:-lobehub-agent-testing-postgres}"
|
||||
DATABASE_URL="${DATABASE_URL:-postgresql://postgres:postgres@localhost:${DB_PORT}/postgres}"
|
||||
ENV_FILE_DEFAULT="$REPO_ROOT/.records/env/agent-testing-dev.env"
|
||||
|
||||
ok() { printf ' \033[32m✔\033[0m %s\n' "$1"; }
|
||||
bad() { printf ' \033[31m✘\033[0m %s\n' "$1"; }
|
||||
note() { printf ' %s\n' "$1"; }
|
||||
|
||||
guard_no_root_env() {
|
||||
if [[ -f "$ROOT_ENV_FILE" ]]; then
|
||||
bad "root .env exists: $ROOT_ENV_FILE"
|
||||
note "Use the existing local configuration instead of init-dev-env.sh."
|
||||
note "Start normally from repo root, e.g. pnpm run dev:next or bun run dev."
|
||||
exit 1
|
||||
fi
|
||||
}
|
||||
|
||||
apply_env() {
|
||||
export APP_URL="${APP_URL:-http://localhost:${SERVER_PORT}}"
|
||||
export AUTH_EMAIL_VERIFICATION="${AUTH_EMAIL_VERIFICATION:-0}"
|
||||
export AUTH_SECRET="${AUTH_SECRET:-agent-testing-local-auth-secret-32chars}"
|
||||
export DATABASE_DRIVER="${DATABASE_DRIVER:-node}"
|
||||
export DATABASE_URL
|
||||
export FEATURE_FLAGS="${FEATURE_FLAGS:--agent_self_iteration}"
|
||||
export KEY_VAULTS_SECRET="${KEY_VAULTS_SECRET:-r2gbBPKyJ8ZRKCLKt+I3DImfcL+wGxaQyRC56xtm9Uk=}"
|
||||
export NEXT_PUBLIC_AUTH_EMAIL_VERIFICATION="${NEXT_PUBLIC_AUTH_EMAIL_VERIFICATION:-0}"
|
||||
export NODE_OPTIONS="${NODE_OPTIONS:---max-old-space-size=6144}"
|
||||
export PORT="${PORT:-$SERVER_PORT}"
|
||||
export S3_ACCESS_KEY_ID="${S3_ACCESS_KEY_ID:-agent-testing-access-key}"
|
||||
export S3_BUCKET="${S3_BUCKET:-agent-testing-bucket}"
|
||||
export S3_ENDPOINT="${S3_ENDPOINT:-https://agent-testing-s3.localhost}"
|
||||
export S3_SECRET_ACCESS_KEY="${S3_SECRET_ACCESS_KEY:-agent-testing-secret-key}"
|
||||
}
|
||||
|
||||
env_keys() {
|
||||
printf '%s\n' \
|
||||
APP_URL \
|
||||
AUTH_EMAIL_VERIFICATION \
|
||||
AUTH_SECRET \
|
||||
DATABASE_DRIVER \
|
||||
DATABASE_URL \
|
||||
FEATURE_FLAGS \
|
||||
KEY_VAULTS_SECRET \
|
||||
NEXT_PUBLIC_AUTH_EMAIL_VERIFICATION \
|
||||
NODE_OPTIONS \
|
||||
PORT \
|
||||
S3_ACCESS_KEY_ID \
|
||||
S3_BUCKET \
|
||||
S3_ENDPOINT \
|
||||
S3_SECRET_ACCESS_KEY
|
||||
}
|
||||
|
||||
print_env() {
|
||||
apply_env
|
||||
while IFS= read -r key; do
|
||||
printf 'export %s=%q\n' "$key" "${!key}"
|
||||
done < <(env_keys)
|
||||
}
|
||||
|
||||
write_env() {
|
||||
local file="${1:-$ENV_FILE_DEFAULT}"
|
||||
apply_env
|
||||
mkdir -p "$(dirname "$file")"
|
||||
{
|
||||
printf '# Source this file before starting LobeHub local dev server.\n'
|
||||
printf '# Generated by %s\n' "$0"
|
||||
while IFS= read -r key; do
|
||||
printf 'export %s=%q\n' "$key" "${!key}"
|
||||
done < <(env_keys)
|
||||
} > "$file"
|
||||
ok "wrote env file: $file"
|
||||
note "source it with: source $file"
|
||||
}
|
||||
|
||||
require_docker() {
|
||||
if ! command -v docker > /dev/null 2>&1; then
|
||||
bad "docker CLI is not available"
|
||||
note "Install/start Docker Desktop, or provide DATABASE_URL for an existing Postgres."
|
||||
return 1
|
||||
fi
|
||||
}
|
||||
|
||||
wait_for_db() {
|
||||
printf ' waiting for Postgres'
|
||||
until docker exec "$DB_CONTAINER" pg_isready -U postgres > /dev/null 2>&1; do
|
||||
printf '.'
|
||||
sleep 2
|
||||
done
|
||||
printf '\n'
|
||||
}
|
||||
|
||||
start_db() {
|
||||
require_docker
|
||||
|
||||
if docker ps --format '{{.Names}}' | grep -Fxq "$DB_CONTAINER"; then
|
||||
ok "Postgres container already running: $DB_CONTAINER"
|
||||
elif docker ps -a --format '{{.Names}}' | grep -Fxq "$DB_CONTAINER"; then
|
||||
docker start "$DB_CONTAINER" > /dev/null
|
||||
ok "started existing Postgres container: $DB_CONTAINER"
|
||||
else
|
||||
docker run -d \
|
||||
--name "$DB_CONTAINER" \
|
||||
-e POSTGRES_PASSWORD=postgres \
|
||||
-p "${DB_PORT}:5432" \
|
||||
paradedb/paradedb:latest > /dev/null
|
||||
ok "created Postgres container: $DB_CONTAINER"
|
||||
fi
|
||||
|
||||
wait_for_db
|
||||
}
|
||||
|
||||
migrate_db() {
|
||||
apply_env
|
||||
cd "$REPO_ROOT"
|
||||
bun run db:migrate
|
||||
}
|
||||
|
||||
seed_user() {
|
||||
apply_env
|
||||
cd "$REPO_ROOT"
|
||||
node <<'NODE'
|
||||
const bcrypt = require('bcryptjs');
|
||||
const pg = require('pg');
|
||||
|
||||
const databaseUrl = process.env.DATABASE_URL;
|
||||
if (!databaseUrl) {
|
||||
throw new Error('DATABASE_URL is required to seed the baseline test user.');
|
||||
}
|
||||
|
||||
const TEST_USER = {
|
||||
email: 'agent-testing@lobehub.com',
|
||||
fullName: 'Agent Testing User',
|
||||
id: 'user_agent_testing_001',
|
||||
password: 'TestPassword123!',
|
||||
username: 'agent_testing_user',
|
||||
};
|
||||
|
||||
const client = new pg.Client({ connectionString: databaseUrl });
|
||||
|
||||
(async () => {
|
||||
await client.connect();
|
||||
const now = new Date().toISOString();
|
||||
const onboarding = JSON.stringify({ finishedAt: now, version: 1 });
|
||||
const passwordHash = await bcrypt.hash(TEST_USER.password, 10);
|
||||
|
||||
await client.query(
|
||||
`INSERT INTO users (id, email, normalized_email, username, full_name, email_verified, onboarding, created_at, updated_at, last_active_at)
|
||||
VALUES ($1, $2, $3, $4, $5, $6, $7, $8, $8, $8)
|
||||
ON CONFLICT (id) DO UPDATE SET onboarding = $7, updated_at = $8`,
|
||||
[
|
||||
TEST_USER.id,
|
||||
TEST_USER.email,
|
||||
TEST_USER.email.toLowerCase(),
|
||||
TEST_USER.username,
|
||||
TEST_USER.fullName,
|
||||
true,
|
||||
onboarding,
|
||||
now,
|
||||
],
|
||||
);
|
||||
|
||||
await client.query(
|
||||
`INSERT INTO accounts (id, user_id, account_id, provider_id, password, created_at, updated_at)
|
||||
VALUES ($1, $2, $3, $4, $5, $6, $6)
|
||||
ON CONFLICT DO NOTHING`,
|
||||
[
|
||||
'agent_testing_account_001',
|
||||
TEST_USER.id,
|
||||
TEST_USER.email,
|
||||
'credential',
|
||||
passwordHash,
|
||||
now,
|
||||
],
|
||||
);
|
||||
|
||||
console.log('seeded baseline user:');
|
||||
console.log(` email: ${TEST_USER.email}`);
|
||||
console.log(` password: ${TEST_USER.password}`);
|
||||
})()
|
||||
.finally(() => client.end())
|
||||
.catch((error) => {
|
||||
console.error(error);
|
||||
process.exit(1);
|
||||
});
|
||||
NODE
|
||||
}
|
||||
|
||||
cmd_status() {
|
||||
apply_env
|
||||
echo "agent-testing local dev env:"
|
||||
note "APP_URL=$APP_URL"
|
||||
note "DATABASE_URL=$DATABASE_URL"
|
||||
note "PORT=$PORT"
|
||||
if command -v docker > /dev/null 2>&1; then
|
||||
ok "docker CLI available"
|
||||
if docker ps --format '{{.Names}}' | grep -Fxq "$DB_CONTAINER"; then
|
||||
ok "managed Postgres running: $DB_CONTAINER"
|
||||
else
|
||||
note "managed Postgres is not running: $DB_CONTAINER"
|
||||
fi
|
||||
else
|
||||
bad "docker CLI is not available"
|
||||
fi
|
||||
}
|
||||
|
||||
cmd_dev_next() {
|
||||
apply_env
|
||||
cd "$REPO_ROOT"
|
||||
exec pnpm run dev:next
|
||||
}
|
||||
|
||||
cmd_dev() {
|
||||
apply_env
|
||||
cd "$REPO_ROOT"
|
||||
exec bun run dev
|
||||
}
|
||||
|
||||
cmd_clean_db() {
|
||||
require_docker
|
||||
if docker ps --format '{{.Names}}' | grep -Fxq "$DB_CONTAINER"; then
|
||||
docker stop "$DB_CONTAINER" > /dev/null
|
||||
fi
|
||||
if docker ps -a --format '{{.Names}}' | grep -Fxq "$DB_CONTAINER"; then
|
||||
docker rm "$DB_CONTAINER" > /dev/null
|
||||
ok "removed Postgres container: $DB_CONTAINER"
|
||||
else
|
||||
note "Postgres container not found: $DB_CONTAINER"
|
||||
fi
|
||||
}
|
||||
|
||||
usage() {
|
||||
sed -n '3,24p' "$0" >&2
|
||||
}
|
||||
|
||||
COMMAND="${1:-status}"
|
||||
|
||||
case "$COMMAND" in
|
||||
help|-h|--help) usage; exit 0 ;;
|
||||
*) guard_no_root_env ;;
|
||||
esac
|
||||
|
||||
case "$COMMAND" in
|
||||
env) print_env ;;
|
||||
write) shift; write_env "${1:-}" ;;
|
||||
setup-db)
|
||||
start_db
|
||||
migrate_db
|
||||
;;
|
||||
migrate) migrate_db ;;
|
||||
seed-user) seed_user ;;
|
||||
dev-next) cmd_dev_next ;;
|
||||
dev) cmd_dev ;;
|
||||
clean-db) cmd_clean_db ;;
|
||||
status) cmd_status ;;
|
||||
*)
|
||||
usage
|
||||
exit 2
|
||||
;;
|
||||
esac
|
||||
@@ -24,39 +24,53 @@ DATE_HUMAN=$(date '+%Y-%m-%d %H:%M')
|
||||
DATE_ISO=$(date '+%Y-%m-%dT%H:%M:%S%z')
|
||||
|
||||
cat > "$DIR/report.md" << EOF
|
||||
# Test Report: $TITLE
|
||||
# 测试报告:$TITLE
|
||||
|
||||
## Scope
|
||||
## 范围
|
||||
|
||||
<!-- What changed / what is being verified -->
|
||||
<!-- 测试目标 / 变更范围 / 重点风险 -->
|
||||
|
||||
- Branch: \`$BRANCH\`
|
||||
- Commit: \`$COMMIT\`
|
||||
- Date: $DATE_HUMAN
|
||||
- 分支:\`$BRANCH\`
|
||||
- 当前提交:\`$COMMIT\`
|
||||
- 日期:$DATE_HUMAN
|
||||
- 表面:<!-- CLI / Electron + CDP / Web / Bot:<platform> -->
|
||||
- 测试页 / 入口:<!-- e.g. /settings or http://localhost:3010 -->
|
||||
- 重点:<!-- 本轮最关心的体验、功能或回归点 -->
|
||||
|
||||
## Environment
|
||||
## 用例
|
||||
|
||||
- Server: <!-- e.g. http://localhost:3010 -->
|
||||
- Surfaces: <!-- cli / electron / web / bot:<platform> -->
|
||||
| # | 用例 | 结果 | 关键现象 | 证据 |
|
||||
| - | ---- | ---- | -------- | ---- |
|
||||
| 1 | | 待测 | |  |
|
||||
|
||||
## Cases
|
||||
## 结论
|
||||
|
||||
| # | Case | Surface | Steps | Expected | Actual | Status | Evidence |
|
||||
| - | ---- | ------- | ----- | -------- | ------ | ------ | -------- |
|
||||
| 1 | | | | | | | |
|
||||
整体结论:\`pending\`。
|
||||
|
||||
## Evidence
|
||||
<!-- 用 1-2 段概括用户最需要知道的结果;失败和阻塞必须明确说明影响。 -->
|
||||
|
||||
<!-- Embed screenshots:  -->
|
||||
<!-- CLI transcripts in fenced blocks, with the exact command -->
|
||||
仍需处理 / 跟进:
|
||||
|
||||
## Verdict
|
||||
- <!-- TODO -->
|
||||
|
||||
- Passed: 0 / 0
|
||||
- Failed: 0
|
||||
- Blocked: 0
|
||||
- Score (optional): —
|
||||
- Open issues / follow-ups:
|
||||
## 本轮验证
|
||||
|
||||
<!-- 如有自动化或命令行验证,保留精简命令与结果;没有则写“未运行额外自动化验证”。 -->
|
||||
|
||||
\`\`\`bash
|
||||
# command
|
||||
\`\`\`
|
||||
|
||||
结果:
|
||||
|
||||
- <!-- TODO -->
|
||||
|
||||
## 评分
|
||||
|
||||
- 通过:0
|
||||
- 失败:0
|
||||
- 阻塞:0
|
||||
- 评分:— / 100
|
||||
EOF
|
||||
|
||||
cat > "$DIR/result.json" << EOF
|
||||
|
||||
@@ -19,12 +19,6 @@ jobs:
|
||||
steps:
|
||||
- uses: actions/checkout@v6
|
||||
|
||||
- name: Clean issue notice
|
||||
uses: actions-cool/issues-helper@e361abf610221f09495ad510cb1e69328d839e1c # v3.7.6
|
||||
with:
|
||||
actions: 'close-issues'
|
||||
labels: '🚨 Sync Fail'
|
||||
|
||||
- name: Sync upstream changes
|
||||
id: sync
|
||||
uses: aormsby/Fork-Sync-With-Upstream-action@v3.4
|
||||
@@ -33,22 +27,4 @@ jobs:
|
||||
upstream_sync_branch: main
|
||||
target_sync_branch: main
|
||||
target_repo_token: ${{ secrets.GITHUB_TOKEN }} # automatically generated, no need to set
|
||||
test_mode: false
|
||||
|
||||
- name: Sync check
|
||||
if: failure()
|
||||
uses: actions-cool/issues-helper@e361abf610221f09495ad510cb1e69328d839e1c # v3.7.6
|
||||
with:
|
||||
actions: 'create-issue'
|
||||
title: '🚨 同步失败 | Sync Fail'
|
||||
labels: '🚨 Sync Fail'
|
||||
body: |
|
||||
Due to a change in the workflow file of the [LobeChat][lobechat] upstream repository, GitHub has automatically suspended the scheduled automatic update. You need to manually sync your fork. Please refer to the detailed [Tutorial][tutorial-en-US] for instructions.
|
||||
|
||||
由于 [LobeChat][lobechat] 上游仓库的 workflow 文件变更,导致 GitHub 自动暂停了本次自动更新,你需要手动 Sync Fork 一次,请查看 [详细教程][tutorial-zh-CN]
|
||||
|
||||
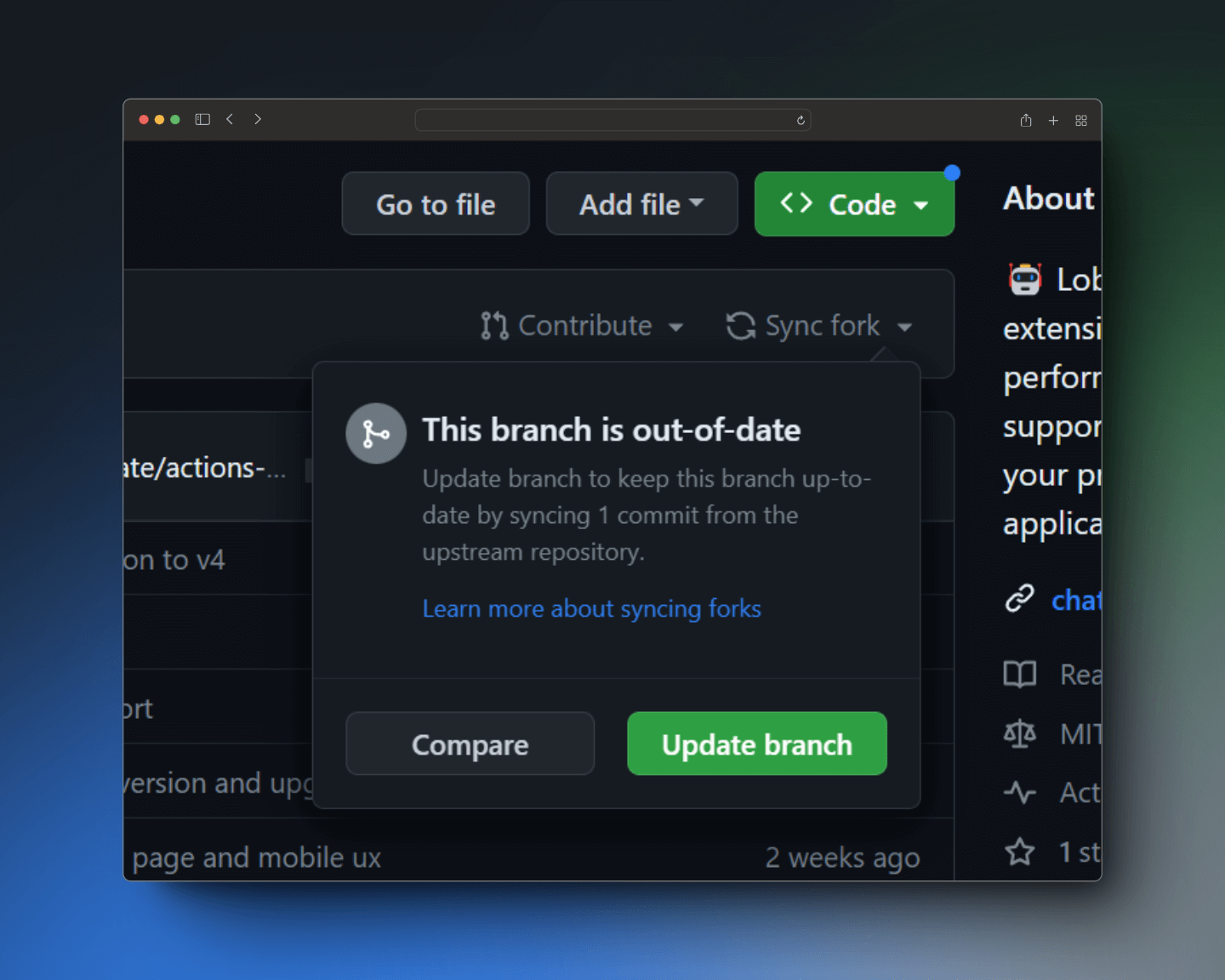
|
||||
|
||||
[lobechat]: https://github.com/lobehub/lobe-chat
|
||||
[tutorial-zh-CN]: https://lobehub.com/zh/docs/self-hosting/advanced/upstream-sync
|
||||
[tutorial-en-US]: https://lobehub.com/docs/self-hosting/advanced/upstream-sync
|
||||
test_mode: false
|
||||
+2
-3
@@ -59,6 +59,7 @@ bun.lockb
|
||||
# Build outputs
|
||||
dist/
|
||||
public/_spa/
|
||||
public/_spa-auth/
|
||||
public/spa/
|
||||
es/
|
||||
lib/
|
||||
@@ -92,10 +93,8 @@ public/swe-worker*
|
||||
|
||||
# Generated files
|
||||
src/app/spa/[variants]/[[...path]]/spaHtmlTemplates.ts
|
||||
src/app/spa-auth/authHtmlTemplate.ts
|
||||
public/*.js
|
||||
public/sitemap.xml
|
||||
public/sitemap-index.xml
|
||||
sitemap*.xml
|
||||
robots.txt
|
||||
|
||||
# Git hooks
|
||||
|
||||
@@ -262,19 +262,23 @@ async function runConnect(options: ConnectOptions, isDaemonChild: boolean) {
|
||||
|
||||
// Handle tool call requests
|
||||
client.on('tool_call_request', async (request: ToolCallRequestMessage) => {
|
||||
const { requestId, timeout, toolCall } = request;
|
||||
const { operationId, requestId, timeout, toolCall } = request;
|
||||
if (isDaemonChild) {
|
||||
appendLog(`[TOOL] ${toolCall.apiName} (${requestId})`);
|
||||
appendLog(
|
||||
`[TOOL] ${toolCall.apiName}${operationId ? ` op=${operationId}` : ''} (${requestId})`,
|
||||
);
|
||||
} else {
|
||||
log.toolCall(toolCall.apiName, requestId, toolCall.arguments);
|
||||
log.toolCall(toolCall.apiName, requestId, toolCall.arguments, operationId);
|
||||
}
|
||||
|
||||
const result = await executeToolCall(toolCall.apiName, toolCall.arguments, timeout);
|
||||
|
||||
if (isDaemonChild) {
|
||||
appendLog(`[RESULT] ${result.success ? 'OK' : 'FAIL'} (${requestId})`);
|
||||
appendLog(
|
||||
`[RESULT] ${result.success ? 'OK' : 'FAIL'}${operationId ? ` op=${operationId}` : ''} (${requestId})`,
|
||||
);
|
||||
} else {
|
||||
log.toolResult(requestId, result.success, result.content);
|
||||
log.toolResult(requestId, result.success, result.content, operationId);
|
||||
}
|
||||
|
||||
client.sendToolCallResponse({
|
||||
|
||||
@@ -4,7 +4,7 @@ import path from 'node:path';
|
||||
|
||||
export interface TaskEntry {
|
||||
agentId?: string;
|
||||
agentType: 'hermes' | 'openclaw';
|
||||
agentType: string;
|
||||
operationId: string;
|
||||
pid: number;
|
||||
startedAt: string;
|
||||
|
||||
@@ -4,14 +4,24 @@ import { afterEach, describe, expect, it, vi } from 'vitest';
|
||||
|
||||
import { spawnHeteroAgentRun } from './agentRun';
|
||||
|
||||
const { spawnMock } = vi.hoisted(() => ({ spawnMock: vi.fn() }));
|
||||
const { removeTaskMock, saveTaskMock, spawnMock } = vi.hoisted(() => ({
|
||||
removeTaskMock: vi.fn(),
|
||||
saveTaskMock: vi.fn(),
|
||||
spawnMock: vi.fn(),
|
||||
}));
|
||||
|
||||
vi.mock('node:child_process', () => ({ spawn: spawnMock }));
|
||||
vi.mock('../daemon/taskRegistry', () => ({
|
||||
removeTask: removeTaskMock,
|
||||
saveTask: saveTaskMock,
|
||||
}));
|
||||
|
||||
const makeFakeChild = () => {
|
||||
const makeFakeChild = (pid = 1234) => {
|
||||
const child = new EventEmitter() as EventEmitter & {
|
||||
pid: number;
|
||||
stdin: { end: ReturnType<typeof vi.fn>; write: ReturnType<typeof vi.fn> };
|
||||
};
|
||||
child.pid = pid;
|
||||
child.stdin = { end: vi.fn(), write: vi.fn() };
|
||||
return child;
|
||||
};
|
||||
@@ -27,6 +37,8 @@ const baseParams = {
|
||||
|
||||
describe('spawnHeteroAgentRun', () => {
|
||||
afterEach(() => {
|
||||
removeTaskMock.mockReset();
|
||||
saveTaskMock.mockReset();
|
||||
spawnMock.mockReset();
|
||||
});
|
||||
|
||||
@@ -66,6 +78,7 @@ describe('spawnHeteroAgentRun', () => {
|
||||
]);
|
||||
expect(opts).toMatchObject({
|
||||
cwd: '/work/dir',
|
||||
detached: process.platform !== 'win32',
|
||||
env: expect.objectContaining({
|
||||
LOBEHUB_JWT: 'jwt-token',
|
||||
LOBEHUB_SERVER: 'https://app.lobehub.com',
|
||||
@@ -79,6 +92,15 @@ describe('spawnHeteroAgentRun', () => {
|
||||
await expect(ackPromise).resolves.toEqual({ status: 'accepted' });
|
||||
expect(child.stdin.write).toHaveBeenCalledWith(JSON.stringify('hi'));
|
||||
expect(child.stdin.end).toHaveBeenCalledTimes(1);
|
||||
expect(saveTaskMock).toHaveBeenCalledWith(
|
||||
expect.objectContaining({
|
||||
agentType: 'claudeCode',
|
||||
operationId: 'op-1',
|
||||
pid: 1234,
|
||||
taskId: 'op-1',
|
||||
topicId: 'tpc-1',
|
||||
}),
|
||||
);
|
||||
});
|
||||
|
||||
it('rejects (no stuck run) when the child errors before spawning, e.g. bad cwd', async () => {
|
||||
@@ -90,6 +112,24 @@ describe('spawnHeteroAgentRun', () => {
|
||||
|
||||
await expect(ackPromise).resolves.toEqual({ reason: 'spawn ENOENT', status: 'rejected' });
|
||||
expect(child.stdin.write).not.toHaveBeenCalled();
|
||||
expect(removeTaskMock).toHaveBeenCalledWith('op');
|
||||
});
|
||||
|
||||
it('removes the registered task when the child exits', async () => {
|
||||
const child = makeFakeChild(4321);
|
||||
spawnMock.mockReturnValue(child);
|
||||
|
||||
const ackPromise = spawnHeteroAgentRun({
|
||||
...baseParams,
|
||||
operationId: 'op-exit',
|
||||
topicId: 'tpc-exit',
|
||||
});
|
||||
child.emit('spawn');
|
||||
await ackPromise;
|
||||
|
||||
child.emit('exit', 0, null);
|
||||
|
||||
expect(removeTaskMock).toHaveBeenCalledWith('op-exit');
|
||||
});
|
||||
|
||||
it('appends --resume when resuming a session', () => {
|
||||
|
||||
@@ -5,6 +5,8 @@ import {
|
||||
type HeteroExecImageRef,
|
||||
} from '@lobechat/heterogeneous-agents/protocol';
|
||||
|
||||
import { removeTask, saveTask } from '../daemon/taskRegistry';
|
||||
|
||||
export interface SpawnHeteroAgentRunParams {
|
||||
agentType: string;
|
||||
cwd?: string;
|
||||
@@ -101,6 +103,7 @@ export function spawnHeteroAgentRun(
|
||||
|
||||
const child = spawn(process.execPath, [...process.execArgv, ...cliArgs], {
|
||||
cwd: workDir,
|
||||
detached: process.platform !== 'win32',
|
||||
env: {
|
||||
...process.env,
|
||||
LOBEHUB_JWT: jwt,
|
||||
@@ -109,7 +112,27 @@ export function spawnHeteroAgentRun(
|
||||
stdio: ['pipe', 'inherit', 'inherit'],
|
||||
});
|
||||
|
||||
let taskSaved = false;
|
||||
const saveRunningTask = () => {
|
||||
if (taskSaved || child.pid === undefined) return;
|
||||
taskSaved = true;
|
||||
saveTask({
|
||||
agentType,
|
||||
operationId,
|
||||
pid: child.pid,
|
||||
startedAt: new Date().toISOString(),
|
||||
taskId: operationId,
|
||||
topicId,
|
||||
});
|
||||
};
|
||||
|
||||
saveRunningTask();
|
||||
|
||||
child.once('spawn', () => {
|
||||
if (child.pid !== undefined) {
|
||||
saveRunningTask();
|
||||
}
|
||||
|
||||
// Only safe to write stdin once the process actually started.
|
||||
try {
|
||||
child.stdin?.write(stdinPayload);
|
||||
@@ -123,11 +146,13 @@ export function spawnHeteroAgentRun(
|
||||
});
|
||||
|
||||
child.once('error', (err) => {
|
||||
removeTask(operationId);
|
||||
logger?.error?.(`hetero exec spawn failed (op=${operationId}): ${err.message}`);
|
||||
settle({ reason: err.message, status: 'rejected' });
|
||||
});
|
||||
|
||||
child.on('exit', (code, signal) => {
|
||||
removeTask(operationId);
|
||||
logger?.info?.(`hetero exec exited (op=${operationId}) code=${code} signal=${signal}`);
|
||||
});
|
||||
});
|
||||
|
||||
@@ -1,7 +1,7 @@
|
||||
import { afterEach, beforeEach, describe, expect, it, vi } from 'vitest';
|
||||
|
||||
import { removeTask, saveTask } from '../../daemon/taskRegistry';
|
||||
import { runHeteroTask } from '../heteroTask';
|
||||
import { cancelHeteroTask, runHeteroTask } from '../heteroTask';
|
||||
|
||||
// ─── Mocks ───
|
||||
|
||||
@@ -249,3 +249,31 @@ describe('runHeteroTask (openclaw)', () => {
|
||||
killSpy.mockRestore();
|
||||
});
|
||||
});
|
||||
|
||||
describe('cancelHeteroTask', () => {
|
||||
beforeEach(() => {
|
||||
vi.clearAllMocks();
|
||||
for (const key of Object.keys(taskStore)) delete taskStore[key];
|
||||
});
|
||||
|
||||
afterEach(() => {
|
||||
vi.restoreAllMocks();
|
||||
});
|
||||
|
||||
it('signals the process group for a registered codex task', async () => {
|
||||
const killSpy = vi.spyOn(process, 'kill').mockImplementation(() => true);
|
||||
taskStore['op-codex'] = {
|
||||
agentType: 'codex',
|
||||
operationId: 'op-codex',
|
||||
pid: 4321,
|
||||
startedAt: '2026-01-01T00:00:00.000Z',
|
||||
taskId: 'op-codex',
|
||||
topicId: 'topic-1',
|
||||
};
|
||||
|
||||
const result = await cancelHeteroTask({ taskId: 'op-codex' });
|
||||
|
||||
expect(result).toBe(JSON.stringify({ pid: 4321, signal: 'SIGINT', taskId: 'op-codex' }));
|
||||
expect(killSpy).toHaveBeenCalledWith(process.platform === 'win32' ? 4321 : -4321, 'SIGINT');
|
||||
});
|
||||
});
|
||||
|
||||
@@ -64,6 +64,19 @@ export interface CancelHeteroTaskParams {
|
||||
taskId: string;
|
||||
}
|
||||
|
||||
function signalTaskProcess(pid: number, signal: NodeJS.Signals): void {
|
||||
if (process.platform === 'win32') {
|
||||
process.kill(pid, signal);
|
||||
return;
|
||||
}
|
||||
|
||||
try {
|
||||
process.kill(-pid, signal);
|
||||
} catch {
|
||||
process.kill(pid, signal);
|
||||
}
|
||||
}
|
||||
|
||||
async function sendAutoNotify(
|
||||
topicId: string,
|
||||
taskId: string,
|
||||
@@ -320,9 +333,11 @@ export async function cancelHeteroTask(params: CancelHeteroTaskParams): Promise<
|
||||
return JSON.stringify({ message: `No task found with taskId: ${taskId}`, success: false });
|
||||
}
|
||||
|
||||
// Both openclaw and hermes: kill by PID and let the child's close handler send the notify.
|
||||
// Signal the whole process group when available. Local CLI agent runs
|
||||
// (claude-code / codex) can spawn their own tool subprocesses, so a
|
||||
// parent-only signal is not enough.
|
||||
try {
|
||||
process.kill(entry.pid, signal);
|
||||
signalTaskProcess(entry.pid, signal);
|
||||
} catch (err) {
|
||||
// Process already exited — exit handler won't fire; clean up manually.
|
||||
log.warn(
|
||||
|
||||
@@ -1,4 +1,3 @@
|
||||
/* eslint-disable no-console */
|
||||
import pc from 'picocolors';
|
||||
|
||||
let verbose = false;
|
||||
@@ -41,18 +40,20 @@ export const log = {
|
||||
console.log(`${timestamp()} ${pc.bold('[STATUS]')} ${color(status)}`);
|
||||
},
|
||||
|
||||
toolCall: (apiName: string, requestId: string, args?: string) => {
|
||||
toolCall: (apiName: string, requestId: string, args?: string, operationId?: string) => {
|
||||
console.log(
|
||||
`${timestamp()} ${pc.magenta('[TOOL]')} ${pc.bold(apiName)} ${pc.dim(`(${requestId})`)}`,
|
||||
`${timestamp()} ${pc.magenta('[TOOL]')} ${pc.bold(apiName)}${operationId ? ` ${pc.dim(`op=${operationId}`)}` : ''} ${pc.dim(`(${requestId})`)}`,
|
||||
);
|
||||
if (args && verbose) {
|
||||
console.log(` ${pc.dim(args)}`);
|
||||
}
|
||||
},
|
||||
|
||||
toolResult: (requestId: string, success: boolean, content?: string) => {
|
||||
toolResult: (requestId: string, success: boolean, content?: string, operationId?: string) => {
|
||||
const icon = success ? pc.green('OK') : pc.red('FAIL');
|
||||
console.log(`${timestamp()} ${pc.magenta('[RESULT]')} ${icon} ${pc.dim(`(${requestId})`)}`);
|
||||
console.log(
|
||||
`${timestamp()} ${pc.magenta('[RESULT]')} ${icon}${operationId ? ` ${pc.dim(`op=${operationId}`)}` : ''} ${pc.dim(`(${requestId})`)}`,
|
||||
);
|
||||
if (content && verbose) {
|
||||
const preview = content.length > 200 ? content.slice(0, 200) + '...' : content;
|
||||
console.log(` ${pc.dim(preview)}`);
|
||||
|
||||
@@ -23,7 +23,7 @@ import type {
|
||||
HeteroExecImageRef,
|
||||
} from '@lobechat/heterogeneous-agents/protocol';
|
||||
import { buildHeteroExecStdinPayload } from '@lobechat/heterogeneous-agents/protocol';
|
||||
import type { AgentStreamEvent } from '@lobechat/heterogeneous-agents/spawn';
|
||||
import type { AgentStreamEvent, UsageData } from '@lobechat/heterogeneous-agents/spawn';
|
||||
import {
|
||||
AgentStreamPipeline,
|
||||
buildAgentInput,
|
||||
@@ -188,6 +188,21 @@ interface AgentSession {
|
||||
modelVerificationLastAttemptAt?: number;
|
||||
modelVerificationLastAttemptSessionId?: string;
|
||||
process?: ChildProcess;
|
||||
/**
|
||||
* Absolute CLI path resolved by spawn preflight detection. Used for spawn()
|
||||
* when the configured command is bare: detection can find the CLI through
|
||||
* the login-shell PATH or a well-known install location (e.g. the Codex.app
|
||||
* bundled CLI) that plain spawn() with the inherited env can't resolve.
|
||||
*/
|
||||
resolvedCommandPath?: string;
|
||||
/**
|
||||
* PATH the preflight detector used to resolve `resolvedCommandPath`, set only
|
||||
* when it fell back to the login-shell PATH. Merged into the child PATH at
|
||||
* spawn so a `#!/usr/bin/env node` shim still finds its interpreter — the
|
||||
* shim resolving in preflight doesn't guarantee `node` is on the leaner
|
||||
* inherited PATH (Finder-launched Electron).
|
||||
*/
|
||||
resolvedCommandSearchPath?: string;
|
||||
resumeSessionId?: string;
|
||||
sessionId: string;
|
||||
verifiedModel?: string;
|
||||
@@ -470,11 +485,20 @@ export default class HeterogeneousAgentCtr extends ControllerModule {
|
||||
session.agentType === 'claude-code' ? 'claude-code' : 'codex',
|
||||
command,
|
||||
);
|
||||
const cliMissingError = this.buildCliMissingError(session);
|
||||
|
||||
if (!status || status.available || !cliMissingError) return;
|
||||
if (!status || status.available) {
|
||||
// Spawn through the detector-resolved absolute path when the configured
|
||||
// command is bare — detection may have located the CLI somewhere plain
|
||||
// spawn() can't (login-shell PATH, Codex.app bundled CLI, …).
|
||||
const useResolvedPath = Boolean(status?.path) && !command.includes(path.sep);
|
||||
session.resolvedCommandPath = useResolvedPath ? status!.path : undefined;
|
||||
// Carry the login-shell PATH the detector resolved through, so a
|
||||
// `#!/usr/bin/env node` shim spawned by absolute path still finds `node`.
|
||||
session.resolvedCommandSearchPath = useResolvedPath ? status!.resolvedPathEnv : undefined;
|
||||
return;
|
||||
}
|
||||
|
||||
return cliMissingError;
|
||||
return this.buildCliMissingError(session);
|
||||
}
|
||||
|
||||
private get shouldTraceCliOutput(): boolean {
|
||||
@@ -911,6 +935,7 @@ export default class HeterogeneousAgentCtr extends ControllerModule {
|
||||
let spawnPlan;
|
||||
let traceSession;
|
||||
let cwd: string;
|
||||
let initialCumulativeUsage: UsageData | undefined;
|
||||
let spawnEnv: NodeJS.ProcessEnv;
|
||||
try {
|
||||
const driver = getHeterogeneousAgentDriver(session.agentType);
|
||||
@@ -934,7 +959,12 @@ export default class HeterogeneousAgentCtr extends ControllerModule {
|
||||
// Forward the user's proxy settings to the CLI. The main-process undici
|
||||
// dispatcher doesn't reach child processes — they need env vars.
|
||||
const proxyEnv = buildProxyEnv(this.app.storeManager.get('networkProxy'));
|
||||
spawnEnv = { ...buildInheritedSpawnEnv(), ...proxyEnv, ...session.env };
|
||||
const inheritedEnv = buildInheritedSpawnEnv();
|
||||
// When preflight resolved the CLI via the login-shell PATH, spawn with
|
||||
// that PATH (a superset of the inherited one) so a `#!/usr/bin/env node`
|
||||
// shim finds its interpreter. `session.env` still wins if it sets PATH.
|
||||
if (session.resolvedCommandSearchPath) inheritedEnv.PATH = session.resolvedCommandSearchPath;
|
||||
spawnEnv = { ...inheritedEnv, ...proxyEnv, ...session.env };
|
||||
|
||||
if (session.agentType === 'codex') {
|
||||
const initialModel = await resolveCodexInitialModel({
|
||||
@@ -945,6 +975,12 @@ export default class HeterogeneousAgentCtr extends ControllerModule {
|
||||
session.model = initialModel.model;
|
||||
session.modelSource = initialModel.source;
|
||||
}
|
||||
|
||||
if (session.agentSessionId) {
|
||||
initialCumulativeUsage = (
|
||||
await readCodexSessionModel(session.agentSessionId, { env: spawnEnv })
|
||||
)?.cumulativeUsage;
|
||||
}
|
||||
}
|
||||
|
||||
traceSession = await this.createCliTraceSession({
|
||||
@@ -966,7 +1002,10 @@ export default class HeterogeneousAgentCtr extends ControllerModule {
|
||||
}
|
||||
const useStdin = spawnPlan.stdinPayload !== undefined;
|
||||
const cliArgs = spawnPlan.args;
|
||||
const resolvedCliSpawnPlan = await resolveCliSpawnPlan(session.command, cliArgs);
|
||||
const resolvedCliSpawnPlan = await resolveCliSpawnPlan(
|
||||
session.resolvedCommandPath ?? session.command,
|
||||
cliArgs,
|
||||
);
|
||||
|
||||
logger.info(
|
||||
'Spawning agent:',
|
||||
@@ -1001,6 +1040,7 @@ export default class HeterogeneousAgentCtr extends ControllerModule {
|
||||
reject,
|
||||
resolve,
|
||||
session,
|
||||
initialCumulativeUsage,
|
||||
spawnEnv,
|
||||
traceSession,
|
||||
useStdin,
|
||||
@@ -1070,6 +1110,7 @@ export default class HeterogeneousAgentCtr extends ControllerModule {
|
||||
|
||||
private handleSpawnedAgentProcess({
|
||||
cwd,
|
||||
initialCumulativeUsage,
|
||||
intervention,
|
||||
params,
|
||||
proc,
|
||||
@@ -1088,6 +1129,7 @@ export default class HeterogeneousAgentCtr extends ControllerModule {
|
||||
reject: (reason?: unknown) => void;
|
||||
resolve: () => void;
|
||||
session: AgentSession;
|
||||
initialCumulativeUsage?: UsageData | undefined;
|
||||
spawnEnv: NodeJS.ProcessEnv;
|
||||
spawnPlan: HeterogeneousAgentBuildPlan;
|
||||
traceSession: CliTraceSession | undefined;
|
||||
@@ -1128,6 +1170,7 @@ export default class HeterogeneousAgentCtr extends ControllerModule {
|
||||
const pipeline = new AgentStreamPipeline({
|
||||
agentType: session.agentType,
|
||||
cwd,
|
||||
initialCumulativeUsage,
|
||||
initialModel: session.model,
|
||||
operationId: params.operationId,
|
||||
});
|
||||
|
||||
@@ -437,11 +437,13 @@ export default class LocalFileCtr extends ControllerModule {
|
||||
|
||||
@IpcMethod()
|
||||
async getLocalFilePreviewUrl({
|
||||
accept,
|
||||
path: filePath,
|
||||
workingDirectory,
|
||||
}: LocalFilePreviewUrlParams): Promise<LocalFilePreviewUrlResult> {
|
||||
try {
|
||||
const url = await this.app.localFileProtocolManager.createPreviewUrl({
|
||||
accept,
|
||||
filePath,
|
||||
workspaceRoot: workingDirectory,
|
||||
});
|
||||
@@ -459,11 +461,13 @@ export default class LocalFileCtr extends ControllerModule {
|
||||
|
||||
@IpcMethod()
|
||||
async getLocalFilePreview({
|
||||
accept,
|
||||
path: filePath,
|
||||
workingDirectory,
|
||||
}: LocalFilePreviewUrlParams): Promise<LocalFilePreviewResult> {
|
||||
try {
|
||||
const preview = await this.app.localFileProtocolManager.readPreviewFile({
|
||||
accept,
|
||||
filePath,
|
||||
workspaceRoot: workingDirectory,
|
||||
});
|
||||
|
||||
@@ -480,6 +480,87 @@ describe('HeterogeneousAgentCtr', () => {
|
||||
expect(spawnCalls).toHaveLength(0);
|
||||
});
|
||||
|
||||
it('spawns through the detector-resolved absolute path when the bare command is off PATH', async () => {
|
||||
// Codex desktop app case: `codex` is not on PATH, but the preflight
|
||||
// detector finds the CLI bundled inside Codex.app. Spawning the bare
|
||||
// command would ENOENT — spawn must use the resolved absolute path.
|
||||
const resolvedPath = '/Applications/Codex.app/Contents/Resources/codex';
|
||||
const detect = vi.fn().mockResolvedValue({ available: true, path: resolvedPath });
|
||||
const { proc } = createFakeProc();
|
||||
nextFakeProc = proc;
|
||||
|
||||
const ctr = new HeterogeneousAgentCtr({
|
||||
appStoragePath,
|
||||
storeManager: { get: vi.fn() },
|
||||
toolDetectorManager: { detect },
|
||||
} as any);
|
||||
const { sessionId } = await ctr.startSession({
|
||||
agentType: 'codex',
|
||||
command: 'codex',
|
||||
});
|
||||
await ctr.sendPrompt({ operationId: 'op-test', prompt: 'hello', sessionId });
|
||||
|
||||
expect(spawnCalls[0].command).toBe(resolvedPath);
|
||||
});
|
||||
|
||||
it('carries the detector login-shell PATH into the spawn env for `env node` shims', async () => {
|
||||
// `codex` resolved via the login-shell PATH (mise/nvm). Spawning the
|
||||
// absolute shim under the leaner inherited PATH would fail at its
|
||||
// `#!/usr/bin/env node` shebang — the resolved PATH must reach the child.
|
||||
const resolvedPath = '/Users/h/.local/share/mise/shims/codex';
|
||||
const searchPath = '/Users/h/.local/share/mise/shims:/usr/bin:/bin';
|
||||
const detect = vi
|
||||
.fn()
|
||||
.mockResolvedValue({ available: true, path: resolvedPath, resolvedPathEnv: searchPath });
|
||||
const { proc } = createFakeProc();
|
||||
nextFakeProc = proc;
|
||||
|
||||
const ctr = new HeterogeneousAgentCtr({
|
||||
appStoragePath,
|
||||
storeManager: { get: vi.fn() },
|
||||
toolDetectorManager: { detect },
|
||||
} as any);
|
||||
const { sessionId } = await ctr.startSession({ agentType: 'codex', command: 'codex' });
|
||||
await ctr.sendPrompt({ operationId: 'op-test', prompt: 'hello', sessionId });
|
||||
|
||||
expect(spawnCalls[0].command).toBe(resolvedPath);
|
||||
expect(spawnCalls[0].options.env.PATH).toBe(searchPath);
|
||||
});
|
||||
|
||||
it('keeps an explicit path-like command for spawn instead of the detector result', async () => {
|
||||
// detectHeterogeneousCliCommand validates the custom path via --version.
|
||||
execFileMock.mockImplementation(
|
||||
(
|
||||
_file: string,
|
||||
_args: string[],
|
||||
optionsOrCallback: unknown,
|
||||
callback?: (error: Error | null, result: { stderr: string; stdout: string }) => void,
|
||||
) => {
|
||||
const resolvedCallback =
|
||||
typeof optionsOrCallback === 'function' ? optionsOrCallback : callback;
|
||||
(resolvedCallback as any)?.(null, { stderr: '', stdout: 'codex-cli 0.99.0' });
|
||||
},
|
||||
);
|
||||
|
||||
const detect = vi.fn();
|
||||
const { proc } = createFakeProc();
|
||||
nextFakeProc = proc;
|
||||
|
||||
const ctr = new HeterogeneousAgentCtr({
|
||||
appStoragePath,
|
||||
storeManager: { get: vi.fn() },
|
||||
toolDetectorManager: { detect },
|
||||
} as any);
|
||||
const { sessionId } = await ctr.startSession({
|
||||
agentType: 'codex',
|
||||
command: '/custom/bin/codex',
|
||||
});
|
||||
await ctr.sendPrompt({ operationId: 'op-test', prompt: 'hello', sessionId });
|
||||
|
||||
expect(detect).not.toHaveBeenCalled();
|
||||
expect(spawnCalls[0].command).toBe('/custom/bin/codex');
|
||||
});
|
||||
|
||||
it('passes prompt via stdin to codex exec instead of argv', async () => {
|
||||
const prompt = '--run a shell-like prompt safely';
|
||||
const { cliArgs, command, writes } = await runSendPrompt(prompt);
|
||||
|
||||
@@ -225,6 +225,7 @@ describe('LocalFileCtr', () => {
|
||||
});
|
||||
|
||||
expect(mockLocalFileProtocolManager.createPreviewUrl).toHaveBeenCalledWith({
|
||||
accept: undefined,
|
||||
filePath: '/workspace/app.ts',
|
||||
workspaceRoot: '/workspace',
|
||||
});
|
||||
@@ -247,6 +248,28 @@ describe('LocalFileCtr', () => {
|
||||
success: false,
|
||||
});
|
||||
});
|
||||
|
||||
it('should forward image-only preview URL constraints', async () => {
|
||||
mockLocalFileProtocolManager.createPreviewUrl.mockResolvedValue(
|
||||
'localfile://file/workspace/image.png?token=abc',
|
||||
);
|
||||
|
||||
const result = await localFileCtr.getLocalFilePreviewUrl({
|
||||
accept: 'image',
|
||||
path: '/workspace/image.png',
|
||||
workingDirectory: '/workspace',
|
||||
});
|
||||
|
||||
expect(mockLocalFileProtocolManager.createPreviewUrl).toHaveBeenCalledWith({
|
||||
accept: 'image',
|
||||
filePath: '/workspace/image.png',
|
||||
workspaceRoot: '/workspace',
|
||||
});
|
||||
expect(result).toEqual({
|
||||
success: true,
|
||||
url: 'localfile://file/workspace/image.png?token=abc',
|
||||
});
|
||||
});
|
||||
});
|
||||
|
||||
describe('getLocalFilePreview', () => {
|
||||
@@ -263,6 +286,7 @@ describe('LocalFileCtr', () => {
|
||||
});
|
||||
|
||||
expect(mockLocalFileProtocolManager.readPreviewFile).toHaveBeenCalledWith({
|
||||
accept: undefined,
|
||||
filePath: '/workspace/app.ts',
|
||||
workspaceRoot: '/workspace',
|
||||
});
|
||||
@@ -289,6 +313,34 @@ describe('LocalFileCtr', () => {
|
||||
success: false,
|
||||
});
|
||||
});
|
||||
|
||||
it('should forward image-only preview read constraints', async () => {
|
||||
mockLocalFileProtocolManager.readPreviewFile.mockResolvedValue({
|
||||
buffer: Buffer.from('image-bytes'),
|
||||
contentType: 'image/png',
|
||||
realPath: '/workspace/image.png',
|
||||
});
|
||||
|
||||
const result = await localFileCtr.getLocalFilePreview({
|
||||
accept: 'image',
|
||||
path: '/workspace/image.png',
|
||||
workingDirectory: '/workspace',
|
||||
});
|
||||
|
||||
expect(mockLocalFileProtocolManager.readPreviewFile).toHaveBeenCalledWith({
|
||||
accept: 'image',
|
||||
filePath: '/workspace/image.png',
|
||||
workspaceRoot: '/workspace',
|
||||
});
|
||||
expect(result).toEqual({
|
||||
preview: {
|
||||
base64: Buffer.from('image-bytes').toString('base64'),
|
||||
contentType: 'image/png',
|
||||
type: 'image',
|
||||
},
|
||||
success: true,
|
||||
});
|
||||
});
|
||||
});
|
||||
|
||||
describe('handleWriteFile', () => {
|
||||
|
||||
@@ -54,6 +54,21 @@ export interface PreviewFileReadResult {
|
||||
realPath: string;
|
||||
}
|
||||
|
||||
type PreviewFileAccept = 'image';
|
||||
|
||||
const normalizeContentType = (contentType: string): string =>
|
||||
contentType.split(';')[0].trim().toLowerCase();
|
||||
|
||||
const isAcceptedPreviewContentType = (
|
||||
contentType: string,
|
||||
accept?: PreviewFileAccept,
|
||||
): boolean => {
|
||||
if (!accept) return true;
|
||||
|
||||
const normalizedContentType = normalizeContentType(contentType);
|
||||
return accept === 'image' && normalizedContentType.startsWith('image/');
|
||||
};
|
||||
|
||||
/**
|
||||
* Custom `localfile://` protocol for project file previews.
|
||||
*
|
||||
@@ -213,16 +228,26 @@ export class LocalFileProtocolManager {
|
||||
}
|
||||
|
||||
async createPreviewUrl({
|
||||
accept,
|
||||
filePath,
|
||||
workspaceRoot,
|
||||
}: {
|
||||
accept?: PreviewFileAccept;
|
||||
filePath: string;
|
||||
workspaceRoot: string;
|
||||
}): Promise<string | null> {
|
||||
const normalizedFilePath = normalizeAbsolutePath(filePath);
|
||||
if (!normalizedFilePath) return null;
|
||||
|
||||
const realFilePath = await this.resolveApprovedPreviewPath({ filePath, workspaceRoot });
|
||||
const realFilePath = accept
|
||||
? (
|
||||
await this.readPreviewFile({
|
||||
accept,
|
||||
filePath,
|
||||
workspaceRoot,
|
||||
})
|
||||
)?.realPath
|
||||
: await this.resolveApprovedPreviewPath({ filePath, workspaceRoot });
|
||||
if (!realFilePath) return null;
|
||||
|
||||
this.cleanupExpiredTokens();
|
||||
@@ -237,9 +262,11 @@ export class LocalFileProtocolManager {
|
||||
}
|
||||
|
||||
async readPreviewFile({
|
||||
accept,
|
||||
filePath,
|
||||
workspaceRoot,
|
||||
}: {
|
||||
accept?: PreviewFileAccept;
|
||||
filePath: string;
|
||||
workspaceRoot: string;
|
||||
}): Promise<PreviewFileReadResult | null> {
|
||||
@@ -250,9 +277,12 @@ export class LocalFileProtocolManager {
|
||||
if (!fileStat.isFile()) return null;
|
||||
|
||||
const buffer = await readFile(realFilePath);
|
||||
const contentType = resolveLocalFileMimeType(realFilePath, buffer);
|
||||
if (!isAcceptedPreviewContentType(contentType, accept)) return null;
|
||||
|
||||
return {
|
||||
buffer,
|
||||
contentType: resolveLocalFileMimeType(realFilePath, buffer),
|
||||
contentType,
|
||||
realPath: realFilePath,
|
||||
};
|
||||
}
|
||||
|
||||
@@ -15,6 +15,15 @@ export interface ToolStatus {
|
||||
error?: string;
|
||||
lastChecked?: Date;
|
||||
path?: string;
|
||||
/**
|
||||
* PATH value used to resolve/validate the command, surfaced only when it
|
||||
* differs from the detector process's `process.env.PATH` (e.g. resolution
|
||||
* fell back to the login-shell PATH). A caller that spawns the resolved
|
||||
* `path` must carry this into the child's PATH, or a `#!/usr/bin/env node`
|
||||
* shim that resolved here still fails with `env: node: No such file or
|
||||
* directory` under the leaner inherited env.
|
||||
*/
|
||||
resolvedPathEnv?: string;
|
||||
version?: string;
|
||||
}
|
||||
|
||||
|
||||
@@ -119,6 +119,21 @@ describe('LocalFileProtocolManager', () => {
|
||||
expect(response.headers.get('Content-Type')).toBe('text/plain; charset=utf-8');
|
||||
});
|
||||
|
||||
it('does not mint image-only preview URLs for text files', async () => {
|
||||
const manager = new LocalFileProtocolManager();
|
||||
await manager.approveWorkspaceRoot('/Users/alice/project');
|
||||
mockReadFile.mockResolvedValue(Buffer.from('const value = 1;'));
|
||||
|
||||
const url = await manager.createPreviewUrl({
|
||||
accept: 'image',
|
||||
filePath: '/Users/alice/project/App.tsx',
|
||||
workspaceRoot: '/Users/alice/project',
|
||||
});
|
||||
|
||||
expect(url).toBeNull();
|
||||
expect(mockReadFile).toHaveBeenCalledWith('/Users/alice/project/App.tsx');
|
||||
});
|
||||
|
||||
it('decodes percent-encoded characters in the path', async () => {
|
||||
const manager = new LocalFileProtocolManager();
|
||||
manager.registerHandler();
|
||||
@@ -296,6 +311,21 @@ describe('LocalFileProtocolManager', () => {
|
||||
expect(mockReadFile).toHaveBeenCalledWith('/Users/alice/project/App.tsx');
|
||||
});
|
||||
|
||||
it('does not return text payloads for image-only preview reads', async () => {
|
||||
const manager = new LocalFileProtocolManager();
|
||||
await manager.approveIndexedProjectRoot('/Users/alice/project');
|
||||
mockReadFile.mockResolvedValue(Buffer.from('SECRET=value'));
|
||||
|
||||
const result = await manager.readPreviewFile({
|
||||
accept: 'image',
|
||||
filePath: '/Users/alice/project/.env',
|
||||
workspaceRoot: '/Users/alice/project',
|
||||
});
|
||||
|
||||
expect(result).toBeNull();
|
||||
expect(mockReadFile).toHaveBeenCalledWith('/Users/alice/project/.env');
|
||||
});
|
||||
|
||||
it('does not read preview payloads outside the approved workspace root', async () => {
|
||||
const manager = new LocalFileProtocolManager();
|
||||
await manager.approveIndexedProjectRoot('/Users/alice/project');
|
||||
|
||||
@@ -1,5 +1,6 @@
|
||||
import * as childProcess from 'node:child_process';
|
||||
import * as os from 'node:os';
|
||||
import path from 'node:path';
|
||||
|
||||
import { afterEach, beforeEach, describe, expect, it, vi } from 'vitest';
|
||||
|
||||
@@ -180,6 +181,76 @@ describe('cliAgentDetectors', () => {
|
||||
expect(status.path).toBe('/usr/local/bin/claude');
|
||||
expect(execMock).not.toHaveBeenCalled();
|
||||
expect(execFileMock).toHaveBeenCalledTimes(2);
|
||||
// Resolved on the inherited PATH — nothing extra to carry into spawn.
|
||||
expect(status.resolvedPathEnv).toBeUndefined();
|
||||
});
|
||||
|
||||
it('falls back to the Codex.app bundled CLI when `codex` is not on any PATH', async () => {
|
||||
const originalPath = process.env.PATH;
|
||||
const originalShell = process.env.SHELL;
|
||||
// Deterministic env: no SHELL → no login-shell lookup, merged PATH
|
||||
// equals process.env.PATH → no second `which` attempt.
|
||||
process.env.PATH = '/usr/bin:/bin';
|
||||
delete process.env.SHELL;
|
||||
|
||||
try {
|
||||
callExecFileError(new Error('not found')); // which codex
|
||||
callExecFile('codex-cli 0.138.0'); // bundled CLI --version
|
||||
|
||||
const { codexDetector } = await import('../cliAgentDetectors');
|
||||
const status = await codexDetector.detect();
|
||||
|
||||
expect(status.available).toBe(true);
|
||||
expect(status.path).toBe('/Applications/Codex.app/Contents/Resources/codex');
|
||||
expect(status.version).toBe('codex-cli 0.138.0');
|
||||
|
||||
expect(execFileMock).toHaveBeenCalledTimes(2);
|
||||
expect(execFileMock.mock.calls[0]![0]).toBe('which');
|
||||
expect(execFileMock.mock.calls[1]![0]).toBe(
|
||||
'/Applications/Codex.app/Contents/Resources/codex',
|
||||
);
|
||||
} finally {
|
||||
process.env.PATH = originalPath;
|
||||
if (originalShell === undefined) delete process.env.SHELL;
|
||||
else process.env.SHELL = originalShell;
|
||||
}
|
||||
});
|
||||
|
||||
it('stays unavailable when neither PATH nor the well-known locations have codex', async () => {
|
||||
const originalPath = process.env.PATH;
|
||||
const originalShell = process.env.SHELL;
|
||||
process.env.PATH = '/usr/bin:/bin';
|
||||
delete process.env.SHELL;
|
||||
|
||||
try {
|
||||
callExecFileError(new Error('not found')); // which codex
|
||||
callExecFileError(new Error('ENOENT')); // /Applications candidate
|
||||
callExecFileError(new Error('ENOENT')); // ~/Applications candidate
|
||||
|
||||
const { codexDetector } = await import('../cliAgentDetectors');
|
||||
const status = await codexDetector.detect();
|
||||
|
||||
expect(status.available).toBe(false);
|
||||
expect(execFileMock).toHaveBeenCalledTimes(3);
|
||||
expect(execFileMock.mock.calls[2]![0]).toBe(
|
||||
path.join(os.homedir(), 'Applications', 'Codex.app', 'Contents', 'Resources', 'codex'),
|
||||
);
|
||||
} finally {
|
||||
process.env.PATH = originalPath;
|
||||
if (originalShell === undefined) delete process.env.SHELL;
|
||||
else process.env.SHELL = originalShell;
|
||||
}
|
||||
});
|
||||
|
||||
it('does not probe well-known locations for an explicit path-like command', async () => {
|
||||
callExecFileError(new Error('ENOENT')); // /custom/bin/codex --version
|
||||
|
||||
const { detectHeterogeneousCliCommand } = await import('../cliAgentDetectors');
|
||||
const status = await detectHeterogeneousCliCommand('codex', '/custom/bin/codex');
|
||||
|
||||
expect(status.available).toBe(false);
|
||||
// Only the explicit path's --version attempt — no fallback probing.
|
||||
expect(execFileMock).toHaveBeenCalledTimes(1);
|
||||
});
|
||||
|
||||
it('falls back to the login shell PATH for tools installed by shell setup', async () => {
|
||||
@@ -200,6 +271,12 @@ describe('cliAgentDetectors', () => {
|
||||
expect(status.available).toBe(true);
|
||||
expect(status.path).toBe('/Users/Hanam/.local/share/mise/shims/gemini');
|
||||
expect(status.version).toBe('gemini 0.2.0');
|
||||
// The login-shell PATH that resolved the shim must be surfaced so the
|
||||
// spawn site can carry it into the child env (mise/nvm `node` lives
|
||||
// there, not on the leaner inherited PATH).
|
||||
expect(status.resolvedPathEnv).toBe(
|
||||
'/opt/homebrew/bin:/Users/Hanam/.local/share/mise/shims:/usr/bin:/bin',
|
||||
);
|
||||
|
||||
expect(execFileMock).toHaveBeenCalledTimes(4);
|
||||
expect(execFileMock.mock.calls[0]![0]).toBe('which');
|
||||
|
||||
@@ -1,5 +1,5 @@
|
||||
import { exec, execFile } from 'node:child_process';
|
||||
import { platform } from 'node:os';
|
||||
import { homedir, platform } from 'node:os';
|
||||
import path from 'node:path';
|
||||
import { promisify } from 'node:util';
|
||||
|
||||
@@ -190,6 +190,11 @@ const detectValidatedCommand = async (
|
||||
return {
|
||||
available: true,
|
||||
path: resolvedPath,
|
||||
// `env` is set only when resolution fell back to the login-shell PATH.
|
||||
// Surface that PATH so the spawn site can carry it into the child env —
|
||||
// otherwise a `#!/usr/bin/env node` shim resolved here can't find `node`
|
||||
// under the leaner inherited PATH (Finder-launched Electron).
|
||||
resolvedPathEnv: env?.PATH,
|
||||
version: output.split(/\r?\n/)[0],
|
||||
};
|
||||
} catch {
|
||||
@@ -209,6 +214,27 @@ const HETEROGENEOUS_CLI_AGENT_OPTIONS = {
|
||||
Pick<ValidatedDetectorOptions, 'validateKeywords'>
|
||||
>;
|
||||
|
||||
// Well-known absolute install locations probed when a bare command isn't on
|
||||
// PATH. The Codex desktop app bundles a fully functional CLI inside Codex.app
|
||||
// (sharing ~/.codex auth/config) but never symlinks it into PATH, so
|
||||
// `which codex` misses an otherwise working install.
|
||||
const getWellKnownCommandPaths = (agentType: HeterogeneousCliAgentType): string[] => {
|
||||
if (platform() !== 'darwin') return [];
|
||||
|
||||
switch (agentType) {
|
||||
case 'codex': {
|
||||
const bundledCli = path.join('Codex.app', 'Contents', 'Resources', 'codex');
|
||||
return [
|
||||
path.join('/Applications', bundledCli),
|
||||
path.join(homedir(), 'Applications', bundledCli),
|
||||
];
|
||||
}
|
||||
default: {
|
||||
return [];
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
export const detectHeterogeneousCliCommand = async (
|
||||
agentType: HeterogeneousCliAgentType,
|
||||
command: string,
|
||||
@@ -216,7 +242,20 @@ export const detectHeterogeneousCliCommand = async (
|
||||
const validator = HETEROGENEOUS_CLI_AGENT_OPTIONS[agentType];
|
||||
if (!validator) return { available: false };
|
||||
|
||||
return detectValidatedCommand(command, validator);
|
||||
const status = await detectValidatedCommand(command, validator);
|
||||
if (status.available) return status;
|
||||
|
||||
// A bare command missing from PATH may still live at a well-known install
|
||||
// location (e.g. the Codex desktop app's bundled CLI). Don't second-guess
|
||||
// an explicit user-configured path.
|
||||
if (!command.trim().includes(path.sep)) {
|
||||
for (const candidate of getWellKnownCommandPaths(agentType)) {
|
||||
const fallbackStatus = await detectValidatedCommand(candidate, validator);
|
||||
if (fallbackStatus.available) return fallbackStatus;
|
||||
}
|
||||
}
|
||||
|
||||
return status;
|
||||
};
|
||||
|
||||
/**
|
||||
@@ -261,14 +300,17 @@ export const claudeCodeDetector: IToolDetector = createValidatedDetector({
|
||||
/**
|
||||
* OpenAI Codex CLI
|
||||
* @see https://github.com/openai/codex
|
||||
*
|
||||
* Goes through `detectHeterogeneousCliCommand` so the Codex.app bundled-CLI
|
||||
* fallback applies here too, keeping the manager path and the custom-command
|
||||
* path in sync.
|
||||
*/
|
||||
export const codexDetector: IToolDetector = createValidatedDetector({
|
||||
candidates: ['codex'],
|
||||
export const codexDetector: IToolDetector = {
|
||||
description: 'Codex - OpenAI agentic coding CLI',
|
||||
detect: () => detectHeterogeneousCliCommand('codex', 'codex'),
|
||||
name: 'codex',
|
||||
priority: 2,
|
||||
validateKeywords: ['codex'],
|
||||
});
|
||||
};
|
||||
|
||||
/**
|
||||
* Google Gemini CLI
|
||||
|
||||
@@ -61,6 +61,7 @@ import { chainCompressContext } from '@lobechat/prompts';
|
||||
import {
|
||||
type ChatToolPayload,
|
||||
type ExecSubAgentParams,
|
||||
type ExecVirtualSubAgentParams,
|
||||
type MessageToolCall,
|
||||
type UIChatMessage,
|
||||
} from '@lobechat/types';
|
||||
@@ -323,7 +324,7 @@ const buildPostProcessUrl = (
|
||||
};
|
||||
|
||||
/**
|
||||
* Build the per-tool-call server sub-agent runner injected into the tool
|
||||
* Build the per-tool-call server virtual sub-agent runner injected into the tool
|
||||
* execution context. Closes over the current tool payload + parent message so
|
||||
* the `callSubAgent` server tool can fork a child op without re-deriving the
|
||||
* message anchor (which it cannot do correctly from its own context).
|
||||
@@ -331,17 +332,18 @@ const buildPostProcessUrl = (
|
||||
* The runner creates the pending placeholder tool message that anchors the
|
||||
* isolation thread (so the UI shows a loading state and the completion bridge
|
||||
* has a message to backfill), then kicks off the child op asynchronously and
|
||||
* returns immediately. Returns `undefined` when sub-agent execution is not
|
||||
* available (no `execSubAgent` callback, or missing agent/topic context).
|
||||
* returns immediately. Returns `undefined` when virtual sub-agent execution is
|
||||
* not available (no `execVirtualSubAgent` callback, or missing agent/topic
|
||||
* context).
|
||||
*/
|
||||
const buildServerSubAgentRunner = (
|
||||
const buildServerVirtualSubAgentRunner = (
|
||||
ctx: RuntimeExecutorContext,
|
||||
state: AgentState,
|
||||
chatToolPayload: ChatToolPayload,
|
||||
parentMessageId: string,
|
||||
): ServerSubAgentRunner | undefined => {
|
||||
const execSubAgent = ctx.execSubAgent;
|
||||
if (!execSubAgent) return undefined;
|
||||
const execVirtualSubAgent = ctx.execVirtualSubAgent;
|
||||
if (!execVirtualSubAgent) return undefined;
|
||||
|
||||
const agentId = state.metadata?.agentId;
|
||||
const topicId = ctx.topicId ?? state.metadata?.topicId;
|
||||
@@ -364,16 +366,15 @@ const buildServerSubAgentRunner = (
|
||||
topicId,
|
||||
});
|
||||
|
||||
// 2. Fork the child op anchored to the placeholder. `resumeParentOnComplete`
|
||||
// tells execSubAgent to register the completion bridge that
|
||||
// backfills this tool message and resumes the parent op.
|
||||
const result = (await execSubAgent({
|
||||
// 2. Fork the virtual child op anchored to the placeholder. The virtual
|
||||
// entry marks the child as `isSubAgent` and registers the completion
|
||||
// bridge that backfills this tool message and resumes the parent op.
|
||||
const result = (await execVirtualSubAgent({
|
||||
agentId: targetAgentId ?? agentId,
|
||||
groupId: state.metadata?.groupId ?? undefined,
|
||||
instruction,
|
||||
parentMessageId: placeholder.id,
|
||||
parentOperationId: ctx.operationId,
|
||||
resumeParentOnComplete: true,
|
||||
timeout,
|
||||
title: description,
|
||||
topicId,
|
||||
@@ -387,7 +388,7 @@ const buildServerSubAgentRunner = (
|
||||
await ctx.messageModel.deleteMessage(placeholder.id);
|
||||
} catch (error) {
|
||||
log(
|
||||
'buildServerSubAgentRunner: failed to clean up placeholder %s: %O',
|
||||
'buildServerVirtualSubAgentRunner: failed to clean up placeholder %s: %O',
|
||||
placeholder.id,
|
||||
error,
|
||||
);
|
||||
@@ -522,11 +523,17 @@ export interface RuntimeExecutorContext {
|
||||
discordContext?: any;
|
||||
evalContext?: EvalContext;
|
||||
/**
|
||||
* Callback to spawn a sub-agent task server-side.
|
||||
* Callback to run a legacy agent invocation server-side.
|
||||
* Injected by AiAgentService so exec_sub_agent / exec_sub_agents executors
|
||||
* can dispatch callAgent-triggered tasks without a circular import.
|
||||
* can dispatch callAgent-triggered runs without a circular import.
|
||||
*/
|
||||
execSubAgent?: (params: ExecSubAgentParams) => Promise<unknown>;
|
||||
/**
|
||||
* Callback to fork a `lobe-agent.callSubAgent` virtual child run. Unlike
|
||||
* execSubAgent, this path installs the async completion bridge and marks the
|
||||
* child operation as a sub-agent.
|
||||
*/
|
||||
execVirtualSubAgent?: (params: ExecVirtualSubAgentParams) => Promise<unknown>;
|
||||
hookDispatcher?: HookDispatcher;
|
||||
loadAgentState?: (operationId: string) => Promise<AgentState | null>;
|
||||
messageModel: MessageModel;
|
||||
@@ -2476,7 +2483,7 @@ export const createRuntimeExecutors = (
|
||||
scope: state.metadata?.scope,
|
||||
serverDB: ctx.serverDB,
|
||||
skipResultTruncation: true,
|
||||
subAgent: buildServerSubAgentRunner(
|
||||
subAgent: buildServerVirtualSubAgentRunner(
|
||||
ctx,
|
||||
state,
|
||||
chatToolPayload,
|
||||
@@ -2718,14 +2725,15 @@ export const createRuntimeExecutors = (
|
||||
|
||||
log('[%s:%d] Tool execution completed', operationId, stepIndex);
|
||||
|
||||
// When the tool result carries an execSubAgent / execSubAgents state the
|
||||
// GeneralChatAgent needs `stop: true` in the payload to detect it and
|
||||
// emit the matching exec_sub_agent / exec_sub_agents instruction. Without
|
||||
// this flag the agent falls through to the normal LLM-call path and the
|
||||
// sub-agent is never spawned.
|
||||
const execTaskStateType = executionResult.state?.type as string | undefined;
|
||||
const isExecTaskState =
|
||||
execTaskStateType === 'execSubAgent' || execTaskStateType === 'execSubAgents';
|
||||
// When a legacy callAgent task result carries execSubAgent / execSubAgents
|
||||
// state, the GeneralChatAgent needs `stop: true` in the payload to detect
|
||||
// it and emit the matching exec_sub_agent / exec_sub_agents instruction.
|
||||
// Without this flag the agent falls through to the normal LLM-call path
|
||||
// and the background agent run is never spawned.
|
||||
const legacyAgentInvocationStateType = executionResult.state?.type as string | undefined;
|
||||
const isLegacyAgentInvocationState =
|
||||
legacyAgentInvocationStateType === 'execSubAgent' ||
|
||||
legacyAgentInvocationStateType === 'execSubAgents';
|
||||
|
||||
executeToolSpan.setAttributes(
|
||||
buildExecuteToolResultAttributes({ attempts: execution.attempts, success: isSuccess }),
|
||||
@@ -2741,7 +2749,7 @@ export const createRuntimeExecutors = (
|
||||
isSuccess,
|
||||
// Pass tool message ID as parentMessageId for the next LLM call
|
||||
parentMessageId: toolMessageId,
|
||||
...(isExecTaskState && { stop: true }),
|
||||
...(isLegacyAgentInvocationState && { stop: true }),
|
||||
toolCall: chatToolPayload,
|
||||
toolCallId: chatToolPayload.id,
|
||||
},
|
||||
@@ -3048,7 +3056,7 @@ export const createRuntimeExecutors = (
|
||||
scope: state.metadata?.scope,
|
||||
serverDB: ctx.serverDB,
|
||||
skipResultTruncation: true,
|
||||
subAgent: buildServerSubAgentRunner(
|
||||
subAgent: buildServerVirtualSubAgentRunner(
|
||||
ctx,
|
||||
state,
|
||||
chatToolPayload,
|
||||
|
||||
@@ -9,6 +9,11 @@ import { afterEach, beforeEach, describe, expect, it, vi } from 'vitest';
|
||||
import { aiAgentRouter } from '../aiAgent';
|
||||
import { cleanupTestUser, createTestUser } from './integration/setup';
|
||||
|
||||
const { mockExecuteToolCall, mockSandboxCallTool } = vi.hoisted(() => ({
|
||||
mockExecuteToolCall: vi.fn(),
|
||||
mockSandboxCallTool: vi.fn(),
|
||||
}));
|
||||
|
||||
// Mock getServerDB to return our test database instance
|
||||
let testDB: LobeChatDatabase;
|
||||
vi.mock('@/database/core/db-adaptor', () => ({
|
||||
@@ -29,6 +34,18 @@ vi.mock('@/server/services/aiChat', () => ({
|
||||
AiChatService: vi.fn().mockImplementation(() => ({})),
|
||||
}));
|
||||
|
||||
vi.mock('@/server/services/deviceGateway', () => ({
|
||||
deviceGateway: {
|
||||
executeToolCall: mockExecuteToolCall,
|
||||
},
|
||||
}));
|
||||
|
||||
vi.mock('@/server/services/sandbox', () => ({
|
||||
createSandboxService: vi.fn(() => ({
|
||||
callTool: mockSandboxCallTool,
|
||||
})),
|
||||
}));
|
||||
|
||||
describe('aiAgentRouter.interruptTask', () => {
|
||||
let serverDB: LobeChatDatabase;
|
||||
let userId: string;
|
||||
@@ -43,6 +60,10 @@ describe('aiAgentRouter.interruptTask', () => {
|
||||
userId = await createTestUser(serverDB);
|
||||
mockInterruptOperation.mockReset();
|
||||
mockInterruptOperation.mockResolvedValue(true);
|
||||
mockExecuteToolCall.mockReset();
|
||||
mockExecuteToolCall.mockResolvedValue({ success: true });
|
||||
mockSandboxCallTool.mockReset();
|
||||
mockSandboxCallTool.mockResolvedValue({ success: true });
|
||||
|
||||
// Create test agent
|
||||
const [agent] = await serverDB
|
||||
@@ -203,6 +224,104 @@ describe('aiAgentRouter.interruptTask', () => {
|
||||
|
||||
expect(updatedThread.status).toBe(ThreadStatus.Cancel);
|
||||
});
|
||||
|
||||
it('should dispatch cancelHeteroTask for a device-dispatched codex operation', async () => {
|
||||
await serverDB
|
||||
.update(topics)
|
||||
.set({
|
||||
metadata: {
|
||||
runningOperation: {
|
||||
assistantMessageId: 'assistant-msg-1',
|
||||
deviceId: 'device-1',
|
||||
heteroType: 'codex',
|
||||
operationId: 'op-codex',
|
||||
},
|
||||
},
|
||||
})
|
||||
.where(eq(topics.id, testTopicId));
|
||||
|
||||
const caller = aiAgentRouter.createCaller(createTestContext());
|
||||
|
||||
const result = await caller.interruptTask({
|
||||
operationId: 'op-codex',
|
||||
topicId: testTopicId,
|
||||
});
|
||||
|
||||
expect(result.success).toBe(true);
|
||||
expect(mockExecuteToolCall).toHaveBeenCalledWith(
|
||||
{ deviceId: 'device-1', userId },
|
||||
{
|
||||
apiName: 'cancelHeteroTask',
|
||||
arguments: JSON.stringify({ signal: 'SIGINT', taskId: 'op-codex' }),
|
||||
identifier: 'cancelHeteroTask',
|
||||
},
|
||||
5000,
|
||||
);
|
||||
|
||||
const [updatedTopic] = await serverDB.select().from(topics).where(eq(topics.id, testTopicId));
|
||||
expect(updatedTopic.metadata?.runningOperation?.cancelRequestedAt).toBeDefined();
|
||||
});
|
||||
|
||||
it('should kill the sandbox background command for a sandbox codex operation', async () => {
|
||||
await serverDB
|
||||
.update(topics)
|
||||
.set({
|
||||
metadata: {
|
||||
runningOperation: {
|
||||
assistantMessageId: 'assistant-msg-1',
|
||||
heteroType: 'codex',
|
||||
operationId: 'op-sandbox',
|
||||
sandboxCommandId: 'cmd-1',
|
||||
},
|
||||
},
|
||||
})
|
||||
.where(eq(topics.id, testTopicId));
|
||||
|
||||
const caller = aiAgentRouter.createCaller(createTestContext());
|
||||
|
||||
const result = await caller.interruptTask({
|
||||
operationId: 'op-sandbox',
|
||||
topicId: testTopicId,
|
||||
});
|
||||
|
||||
expect(result.success).toBe(true);
|
||||
expect(mockSandboxCallTool).toHaveBeenCalledWith('killCommand', { commandId: 'cmd-1' });
|
||||
|
||||
const [updatedTopic] = await serverDB.select().from(topics).where(eq(topics.id, testTopicId));
|
||||
expect(updatedTopic.metadata?.runningOperation?.cancelRequestedAt).toBeDefined();
|
||||
});
|
||||
|
||||
it('should not cancel a topic runningOperation that belongs to another operation', async () => {
|
||||
await serverDB
|
||||
.update(topics)
|
||||
.set({
|
||||
metadata: {
|
||||
runningOperation: {
|
||||
assistantMessageId: 'assistant-msg-current',
|
||||
deviceId: 'device-current',
|
||||
heteroType: 'codex',
|
||||
operationId: 'op-current',
|
||||
sandboxCommandId: 'cmd-current',
|
||||
},
|
||||
},
|
||||
})
|
||||
.where(eq(topics.id, testTopicId));
|
||||
|
||||
const caller = aiAgentRouter.createCaller(createTestContext());
|
||||
|
||||
const result = await caller.interruptTask({
|
||||
operationId: 'op-stale',
|
||||
topicId: testTopicId,
|
||||
});
|
||||
|
||||
expect(result.success).toBe(true);
|
||||
expect(mockExecuteToolCall).not.toHaveBeenCalled();
|
||||
expect(mockSandboxCallTool).not.toHaveBeenCalled();
|
||||
|
||||
const [updatedTopic] = await serverDB.select().from(topics).where(eq(topics.id, testTopicId));
|
||||
expect(updatedTopic.metadata?.runningOperation?.cancelRequestedAt).toBeUndefined();
|
||||
expect(updatedTopic.metadata?.runningOperation?.operationId).toBe('op-current');
|
||||
});
|
||||
});
|
||||
|
||||
describe('interrupt failure handling', () => {
|
||||
|
||||
@@ -119,7 +119,7 @@ describe('aiChatRouter', () => {
|
||||
expect(mockCreateUserAndAssistantMessages).toHaveBeenCalledTimes(1);
|
||||
expect(mockCreateUserAndAssistantMessages).toHaveBeenCalledWith(
|
||||
expect.any(Object),
|
||||
expect.objectContaining({ touchTopicUpdatedAt: false }),
|
||||
expect.not.objectContaining({ touchTopicUpdatedAt: expect.anything() }),
|
||||
);
|
||||
|
||||
expect(mockGet).toHaveBeenCalledWith(
|
||||
@@ -161,7 +161,7 @@ describe('aiChatRouter', () => {
|
||||
expect(mockCreateMessage).toHaveBeenCalled();
|
||||
expect(mockCreateUserAndAssistantMessages).toHaveBeenCalledWith(
|
||||
expect.any(Object),
|
||||
expect.objectContaining({ touchTopicUpdatedAt: true }),
|
||||
expect.not.objectContaining({ touchTopicUpdatedAt: expect.anything() }),
|
||||
);
|
||||
expect(mockGet).toHaveBeenCalledWith(
|
||||
expect.objectContaining({
|
||||
|
||||
@@ -4,12 +4,15 @@ import { pushTokenRouter } from '@/server/routers/lambda/pushToken';
|
||||
|
||||
const mockUpsert = vi.fn();
|
||||
const mockUnregister = vi.fn();
|
||||
const mockDeleteByExpoTokenAndDevice = vi.fn();
|
||||
|
||||
vi.mock('@/database/models/pushToken', () => ({
|
||||
PushTokenModel: vi.fn(() => ({
|
||||
unregister: mockUnregister,
|
||||
upsert: mockUpsert,
|
||||
})),
|
||||
deletePushTokenByExpoTokenAndDevice: (...args: unknown[]) =>
|
||||
mockDeleteByExpoTokenAndDevice(...args),
|
||||
}));
|
||||
|
||||
const createCaller = (ctxOverrides: Partial<any> = {}) => {
|
||||
@@ -91,18 +94,90 @@ describe('pushTokenRouter', () => {
|
||||
});
|
||||
|
||||
describe('unregister', () => {
|
||||
it('should call model.unregister with deviceId', async () => {
|
||||
it('should delete by (expoToken, deviceId) when expoToken is provided', async () => {
|
||||
mockDeleteByExpoTokenAndDevice.mockResolvedValueOnce(undefined);
|
||||
const caller = createCaller();
|
||||
|
||||
const result = await caller.unregister({
|
||||
deviceId: 'device-1',
|
||||
expoToken: 'ExponentPushToken[abc]',
|
||||
});
|
||||
|
||||
expect(mockDeleteByExpoTokenAndDevice).toHaveBeenCalledWith(expect.anything(), {
|
||||
deviceId: 'device-1',
|
||||
expoToken: 'ExponentPushToken[abc]',
|
||||
});
|
||||
expect(result).toEqual({ success: true });
|
||||
// Legacy (userId, deviceId) path must not fire when expoToken is present
|
||||
expect(mockUnregister).not.toHaveBeenCalled();
|
||||
});
|
||||
|
||||
it('should fall back to (userId, deviceId) for legacy clients with a session', async () => {
|
||||
// Path B — v1.0.7 only sends deviceId; if the request still carries a
|
||||
// valid session we MUST delete the row, otherwise PushChannel keeps
|
||||
// notifying a signed-out device (Expo DeviceNotRegistered only fires on
|
||||
// uninstall, not logout).
|
||||
mockUnregister.mockResolvedValueOnce(undefined);
|
||||
const caller = createCaller();
|
||||
|
||||
await caller.unregister({ deviceId: 'device-1' });
|
||||
const result = await caller.unregister({ deviceId: 'device-1' });
|
||||
|
||||
expect(mockUnregister).toHaveBeenCalledWith('device-1');
|
||||
expect(mockDeleteByExpoTokenAndDevice).not.toHaveBeenCalled();
|
||||
expect(result).toEqual({ success: true });
|
||||
});
|
||||
|
||||
it('should silently succeed without expoToken AND without session', async () => {
|
||||
// Path C — v1.0.7 + dead session: the only safe move is silent OK.
|
||||
// Orphan row will be cleaned up by the process-push-receipts worker via
|
||||
// Expo DeviceNotRegistered receipts. Returning 200 here stops the storm.
|
||||
const caller = createCaller({ userId: undefined });
|
||||
|
||||
const result = await caller.unregister({ deviceId: 'device-1' });
|
||||
|
||||
expect(mockDeleteByExpoTokenAndDevice).not.toHaveBeenCalled();
|
||||
expect(mockUnregister).not.toHaveBeenCalled();
|
||||
expect(result).toEqual({ success: true });
|
||||
});
|
||||
|
||||
it('should succeed for an unauthenticated caller carrying expoToken', async () => {
|
||||
// New clients (>=1.0.8) hit Path A regardless of session.
|
||||
const caller = createCaller({ userId: undefined });
|
||||
|
||||
const result = await caller.unregister({
|
||||
deviceId: 'device-1',
|
||||
expoToken: 'ExponentPushToken[abc]',
|
||||
});
|
||||
|
||||
expect(result).toEqual({ success: true });
|
||||
expect(mockDeleteByExpoTokenAndDevice).toHaveBeenCalled();
|
||||
expect(mockUnregister).not.toHaveBeenCalled();
|
||||
});
|
||||
|
||||
it('should prefer expoToken precision over the legacy userId fallback', async () => {
|
||||
// If both are available, always take Path A — the (expoToken, deviceId)
|
||||
// pair is more precise and doesn't risk deleting a wrong row.
|
||||
const caller = createCaller();
|
||||
|
||||
await caller.unregister({
|
||||
deviceId: 'device-1',
|
||||
expoToken: 'ExponentPushToken[abc]',
|
||||
});
|
||||
|
||||
expect(mockDeleteByExpoTokenAndDevice).toHaveBeenCalled();
|
||||
expect(mockUnregister).not.toHaveBeenCalled();
|
||||
});
|
||||
|
||||
it('should reject empty deviceId', async () => {
|
||||
const caller = createCaller();
|
||||
await expect(caller.unregister({ deviceId: '' })).rejects.toThrow();
|
||||
});
|
||||
|
||||
it('should reject empty expoToken when provided', async () => {
|
||||
const caller = createCaller();
|
||||
await expect(
|
||||
caller.unregister({ deviceId: 'device-1', expoToken: '' }),
|
||||
).rejects.toThrow();
|
||||
});
|
||||
});
|
||||
});
|
||||
|
||||
@@ -36,6 +36,7 @@ export const compareDocumentHistoryItemsInputSchema = z.object({
|
||||
});
|
||||
|
||||
export const updateDocumentInputSchema = z.object({
|
||||
breakAutosaveWindow: z.boolean().optional(),
|
||||
content: z.string().optional(),
|
||||
editorData: z.string().optional(),
|
||||
fileType: z.string().optional(),
|
||||
@@ -58,6 +59,7 @@ export interface DocumentHistoryListItem {
|
||||
isCurrent: boolean;
|
||||
savedAt: string;
|
||||
saveSource: DocumentHistorySaveSource;
|
||||
userId: string;
|
||||
}
|
||||
|
||||
export interface ListHistoryOutput {
|
||||
@@ -123,6 +125,7 @@ export interface CompareHistoryItemsInput {
|
||||
}
|
||||
|
||||
export interface UpdateDocumentInput {
|
||||
breakAutosaveWindow?: boolean;
|
||||
content?: string;
|
||||
editorData?: string;
|
||||
fileType?: string;
|
||||
|
||||
@@ -85,6 +85,7 @@ export const agentSignalRouter = router({
|
||||
return enqueueAgentSignalSourceEvent(sourceEvent, {
|
||||
agentId: input.agentId,
|
||||
userId: ctx.userId,
|
||||
workspaceId: ctx.workspaceId ?? undefined,
|
||||
});
|
||||
}),
|
||||
listReceipts: agentSignalProcedure
|
||||
|
||||
@@ -329,9 +329,9 @@ const InterruptTaskSchema = z
|
||||
/** Thread ID */
|
||||
threadId: z.string().optional(),
|
||||
/**
|
||||
* Topic ID — required to cancel remote hetero tasks (openclaw / hermes).
|
||||
* When provided and the topic's runningOperation has a deviceId, the server
|
||||
* will dispatch a cancelHeteroTask tool call to kill the remote process.
|
||||
* Topic ID — required to cancel hetero work that lives outside the server
|
||||
* process. When provided, the topic's runningOperation can route cancellation
|
||||
* to a connected device process or a sandbox background command.
|
||||
*/
|
||||
topicId: z.string().optional(),
|
||||
})
|
||||
|
||||
@@ -370,7 +370,6 @@ export const aiChatRouter = router({
|
||||
{ assistantMessage, userMessage },
|
||||
{
|
||||
...(modelTiming ? { timing: modelTiming } : {}),
|
||||
touchTopicUpdatedAt: !isCreateNewTopic,
|
||||
},
|
||||
);
|
||||
},
|
||||
|
||||
@@ -275,9 +275,17 @@ export const deviceRouter = router({
|
||||
* receives render data, not a `localfile://` URL; saving remains unsupported.
|
||||
*/
|
||||
getLocalFilePreview: deviceProcedure
|
||||
.input(z.object({ deviceId: z.string(), path: z.string(), workingDirectory: z.string() }))
|
||||
.input(
|
||||
z.object({
|
||||
accept: z.enum(['image']).optional(),
|
||||
deviceId: z.string(),
|
||||
path: z.string(),
|
||||
workingDirectory: z.string(),
|
||||
}),
|
||||
)
|
||||
.query(async ({ ctx, input }) =>
|
||||
deviceGateway.getLocalFilePreview({
|
||||
accept: input.accept,
|
||||
deviceId: input.deviceId,
|
||||
path: input.path,
|
||||
userId: ctx.userId,
|
||||
|
||||
@@ -1,10 +1,13 @@
|
||||
import { z } from 'zod';
|
||||
|
||||
import { PushTokenModel } from '@/database/models/pushToken';
|
||||
import { authedProcedure, router } from '@/libs/trpc/lambda';
|
||||
import {
|
||||
deletePushTokenByExpoTokenAndDevice,
|
||||
PushTokenModel,
|
||||
} from '@/database/models/pushToken';
|
||||
import { authedProcedure, publicProcedure, router } from '@/libs/trpc/lambda';
|
||||
import { serverDatabase } from '@/libs/trpc/lambda/middleware';
|
||||
|
||||
const pushTokenProcedure = authedProcedure.use(serverDatabase).use(async (opts) => {
|
||||
const authedPushTokenProcedure = authedProcedure.use(serverDatabase).use(async (opts) => {
|
||||
const { ctx } = opts;
|
||||
|
||||
return opts.next({
|
||||
@@ -13,7 +16,7 @@ const pushTokenProcedure = authedProcedure.use(serverDatabase).use(async (opts)
|
||||
});
|
||||
|
||||
export const pushTokenRouter = router({
|
||||
register: pushTokenProcedure
|
||||
register: authedPushTokenProcedure
|
||||
.input(
|
||||
z.object({
|
||||
appVersion: z.string().optional(),
|
||||
@@ -27,10 +30,53 @@ export const pushTokenRouter = router({
|
||||
return ctx.pushTokenModel.upsert(input);
|
||||
}),
|
||||
|
||||
unregister: pushTokenProcedure
|
||||
.input(z.object({ deviceId: z.string().min(1) }))
|
||||
/**
|
||||
* Public on purpose: clients call this during sign-out, and in the wild many
|
||||
* of those calls arrive after the session is already gone (expired OIDC
|
||||
* token / cleared cookie). Authenticating by session here causes a 401
|
||||
* storm on every such logout.
|
||||
*
|
||||
* Authorization model (Path A — new clients ≥ 1.0.8): the caller presents the
|
||||
* (deviceId, expoToken) pair it received at registration. Holding both = proof
|
||||
* of ownership of the row, same trust model as APNs/FCM unregister.
|
||||
*
|
||||
* Backwards compat for v1.0.7 (only sends `deviceId`):
|
||||
* - Path B — when the request still carries a valid session, fall back to
|
||||
* the original (userId, deviceId) delete. This covers the *active*
|
||||
* sign-out path so PushChannel doesn't keep notifying a signed-out device
|
||||
* until the user uninstalls (Expo's DeviceNotRegistered receipt only
|
||||
* fires on uninstall, not on logout).
|
||||
* - Path C — when there's no session either, silently succeed. The orphan
|
||||
* row will be cleaned up by the existing `process-push-receipts` worker
|
||||
* via Expo's DeviceNotRegistered receipts. Returning 200 here is what
|
||||
* actually stops the 401 storm in production.
|
||||
*/
|
||||
unregister: publicProcedure
|
||||
.use(serverDatabase)
|
||||
.input(
|
||||
z.object({
|
||||
deviceId: z.string().min(1),
|
||||
expoToken: z.string().min(1).optional(),
|
||||
}),
|
||||
)
|
||||
.mutation(async ({ ctx, input }) => {
|
||||
return ctx.pushTokenModel.unregister(input.deviceId);
|
||||
const { deviceId, expoToken } = input;
|
||||
|
||||
// Path A: new clients — precise delete by (expoToken, deviceId), no session needed
|
||||
if (expoToken) {
|
||||
await deletePushTokenByExpoTokenAndDevice(ctx.serverDB, { deviceId, expoToken });
|
||||
return { success: true };
|
||||
}
|
||||
|
||||
// Path B: legacy v1.0.7 + valid session — fall back to (userId, deviceId)
|
||||
if (ctx.userId) {
|
||||
const pushTokenModel = new PushTokenModel(ctx.serverDB, ctx.userId);
|
||||
await pushTokenModel.unregister(deviceId);
|
||||
return { success: true };
|
||||
}
|
||||
|
||||
// Path C: legacy v1.0.7 with no session — silent OK, cron worker cleans up
|
||||
return { success: true };
|
||||
}),
|
||||
});
|
||||
|
||||
|
||||
@@ -685,6 +685,7 @@ export const topicRouter = router({
|
||||
runningOperation: z
|
||||
.object({
|
||||
assistantMessageId: z.string(),
|
||||
cancelRequestedAt: z.string().optional(),
|
||||
completionWebhook: z
|
||||
.object({
|
||||
body: z.record(z.unknown()).optional(),
|
||||
@@ -692,7 +693,10 @@ export const topicRouter = router({
|
||||
url: z.string(),
|
||||
})
|
||||
.optional(),
|
||||
deviceId: z.string().optional(),
|
||||
heteroType: z.string().optional(),
|
||||
operationId: z.string(),
|
||||
sandboxCommandId: z.string().optional(),
|
||||
scope: z.string().optional(),
|
||||
threadId: z.string().nullable().optional(),
|
||||
})
|
||||
|
||||
@@ -1,11 +1,12 @@
|
||||
import { z } from 'zod';
|
||||
|
||||
import { wsCompatProcedure } from '@/business/server/trpc-middlewares/workspaceAuth';
|
||||
import { AgentOperationModel } from '@/database/models/agentOperation';
|
||||
import { LlmGenerationTracingModel } from '@/database/models/llmGenerationTracing';
|
||||
import { VerifyCheckResultModel } from '@/database/models/verifyCheckResult';
|
||||
import { VerifyCriterionModel } from '@/database/models/verifyCriterion';
|
||||
import { VerifyRubricModel } from '@/database/models/verifyRubric';
|
||||
import { authedProcedure, router } from '@/libs/trpc/lambda';
|
||||
import { router } from '@/libs/trpc/lambda';
|
||||
import { serverDatabase } from '@/libs/trpc/lambda/middleware';
|
||||
import {
|
||||
VerifyExecutorService,
|
||||
@@ -35,18 +36,19 @@ const checkItemSchema = z.object({
|
||||
verifierType: verifierTypeSchema,
|
||||
});
|
||||
|
||||
const verifyProcedure = authedProcedure.use(serverDatabase).use(async (opts) => {
|
||||
const verifyProcedure = wsCompatProcedure.use(serverDatabase).use(async (opts) => {
|
||||
const { ctx } = opts;
|
||||
const workspaceId = ctx.workspaceId ?? undefined;
|
||||
return opts.next({
|
||||
ctx: {
|
||||
criterionModel: new VerifyCriterionModel(ctx.serverDB, ctx.userId),
|
||||
executorService: new VerifyExecutorService(ctx.serverDB, ctx.userId),
|
||||
tracingModel: new LlmGenerationTracingModel(ctx.serverDB, ctx.userId),
|
||||
feedbackService: new VerifyFeedbackService(ctx.serverDB, ctx.userId),
|
||||
operationModel: new AgentOperationModel(ctx.serverDB, ctx.userId),
|
||||
planGenerator: new VerifyPlanGeneratorService(ctx.serverDB, ctx.userId),
|
||||
resultModel: new VerifyCheckResultModel(ctx.serverDB, ctx.userId),
|
||||
rubricModel: new VerifyRubricModel(ctx.serverDB, ctx.userId),
|
||||
criterionModel: new VerifyCriterionModel(ctx.serverDB, ctx.userId, workspaceId),
|
||||
executorService: new VerifyExecutorService(ctx.serverDB, ctx.userId, workspaceId),
|
||||
tracingModel: new LlmGenerationTracingModel(ctx.serverDB, ctx.userId, workspaceId),
|
||||
feedbackService: new VerifyFeedbackService(ctx.serverDB, ctx.userId, workspaceId),
|
||||
operationModel: new AgentOperationModel(ctx.serverDB, ctx.userId, workspaceId),
|
||||
planGenerator: new VerifyPlanGeneratorService(ctx.serverDB, ctx.userId, workspaceId),
|
||||
resultModel: new VerifyCheckResultModel(ctx.serverDB, ctx.userId, workspaceId),
|
||||
rubricModel: new VerifyRubricModel(ctx.serverDB, ctx.userId, workspaceId),
|
||||
},
|
||||
});
|
||||
});
|
||||
|
||||
@@ -231,6 +231,57 @@ describe('AgentService', () => {
|
||||
// Avatar should not be present for non-builtin agents
|
||||
expect((result as any)?.avatar).toBeUndefined();
|
||||
});
|
||||
|
||||
it('should NOT inherit the member personal default model for a workspace inbox', async () => {
|
||||
// Workspace inbox is persisted with an empty model/provider.
|
||||
const mockAgent = {
|
||||
id: 'agent-1',
|
||||
slug: 'inbox',
|
||||
};
|
||||
const serverDefaultConfig = { model: 'system-default-model', provider: 'system-provider' };
|
||||
|
||||
const mockAgentModel = {
|
||||
getBuiltinAgent: vi.fn().mockResolvedValue(mockAgent),
|
||||
};
|
||||
|
||||
(AgentModel as any).mockImplementation(() => mockAgentModel);
|
||||
(parseAgentConfig as any).mockReturnValue(serverDefaultConfig);
|
||||
// The member opening the workspace inbox has a personal default model.
|
||||
mockUserModel.getUserSettingsDefaultAgentConfig.mockResolvedValueOnce({
|
||||
config: { model: 'opus-4.6', provider: 'anthropic' },
|
||||
});
|
||||
|
||||
const workspaceService = new AgentService(mockDb, mockUserId, mockWorkspaceId);
|
||||
const result = await workspaceService.getBuiltinAgent('inbox');
|
||||
|
||||
// Should fall back to the system default, NOT the member's personal model.
|
||||
expect(result?.model).toBe('system-default-model');
|
||||
expect(result?.provider).toBe('system-provider');
|
||||
});
|
||||
|
||||
it('should still apply the personal default model for a personal inbox', async () => {
|
||||
const mockAgent = {
|
||||
id: 'agent-1',
|
||||
slug: 'inbox',
|
||||
};
|
||||
|
||||
const mockAgentModel = {
|
||||
getBuiltinAgent: vi.fn().mockResolvedValue(mockAgent),
|
||||
};
|
||||
|
||||
(AgentModel as any).mockImplementation(() => mockAgentModel);
|
||||
(parseAgentConfig as any).mockReturnValue({});
|
||||
mockUserModel.getUserSettingsDefaultAgentConfig.mockResolvedValueOnce({
|
||||
config: { model: 'user-preferred-model', provider: 'user-provider' },
|
||||
});
|
||||
|
||||
// No workspaceId → personal scope keeps the personal default behavior.
|
||||
const newService = new AgentService(mockDb, mockUserId);
|
||||
const result = await newService.getBuiltinAgent('inbox');
|
||||
|
||||
expect(result?.model).toBe('user-preferred-model');
|
||||
expect(result?.provider).toBe('user-provider');
|
||||
});
|
||||
});
|
||||
|
||||
describe('getAgentConfig', () => {
|
||||
|
||||
@@ -174,6 +174,13 @@ export class AgentService {
|
||||
* 2. serverDefaultAgentConfig - from environment variable
|
||||
* 3. userDefaultAgentConfig - from user settings (defaultAgent.config)
|
||||
* 4. agent - actual agent config from database
|
||||
*
|
||||
* Workspace exception: a workspace is a shared resource, so its agents must
|
||||
* NOT inherit any individual member's *personal* default model. Otherwise a
|
||||
* shared agent persisted with an empty model (e.g. the workspace inbox)
|
||||
* resolves to whoever opens it — the creator's personal default leaks in and
|
||||
* the workspace looks "initialized" with their model. For workspace-scoped
|
||||
* reads we skip the user layer and fall back to the system default instead.
|
||||
*/
|
||||
private mergeDefaultConfig(
|
||||
agent: any,
|
||||
@@ -181,12 +188,17 @@ export class AgentService {
|
||||
): LobeAgentConfig | null {
|
||||
if (!agent) return null;
|
||||
|
||||
const userDefaultAgentConfig =
|
||||
(defaultAgentConfig as { config?: PartialDeep<LobeAgentConfig> })?.config || {};
|
||||
|
||||
// Merge configs in order: DEFAULT -> server -> user -> agent
|
||||
// Merge configs in order: DEFAULT -> server -> [user] -> agent
|
||||
const serverDefaultAgentConfig = getServerDefaultAgentConfig();
|
||||
const baseConfig = merge(DEFAULT_AGENT_CONFIG, serverDefaultAgentConfig);
|
||||
|
||||
// Skip the personal default layer for workspace-scoped agents (see above).
|
||||
if (this.workspaceId) {
|
||||
return merge(baseConfig, cleanObject(agent));
|
||||
}
|
||||
|
||||
const userDefaultAgentConfig =
|
||||
(defaultAgentConfig as { config?: PartialDeep<LobeAgentConfig> })?.config || {};
|
||||
const withUserConfig = merge(baseConfig, userDefaultAgentConfig);
|
||||
|
||||
return merge(withUserConfig, cleanObject(agent));
|
||||
|
||||
@@ -25,7 +25,12 @@ import {
|
||||
invokeAgentSpanName,
|
||||
tracer as agentRuntimeTracer,
|
||||
} from '@lobechat/observability-otel/modules/agent-runtime';
|
||||
import { type ChatToolPayload, type ExecSubAgentParams, type UIChatMessage } from '@lobechat/types';
|
||||
import {
|
||||
type ChatToolPayload,
|
||||
type ExecSubAgentParams,
|
||||
type ExecVirtualSubAgentParams,
|
||||
type UIChatMessage,
|
||||
} from '@lobechat/types';
|
||||
import debug from 'debug';
|
||||
import urlJoin from 'url-join';
|
||||
|
||||
@@ -126,13 +131,17 @@ const toAgentSignalSnapshotEvents = (
|
||||
*/
|
||||
export interface AgentRuntimeDelegate {
|
||||
/**
|
||||
* Fork a sub-agent through the full high-level pipeline
|
||||
* Run a legacy agent invocation through the full high-level pipeline
|
||||
* (AiAgentService.execSubAgent → execAgent: agent-config resolution, tool
|
||||
* engine, context engineering, createOperation). Returns a deferred result;
|
||||
* the parent op parks (`waiting_for_async_tool`) until the completion bridge
|
||||
* backfills the placeholder and resumes it.
|
||||
* engine, context engineering, createOperation).
|
||||
*/
|
||||
execSubAgent?: (params: ExecSubAgentParams) => Promise<unknown>;
|
||||
/**
|
||||
* Fork a `lobe-agent.callSubAgent` virtual child run. The child is marked as a
|
||||
* sub-agent and owns the completion bridge that backfills the parent tool
|
||||
* placeholder before resuming the parked parent operation.
|
||||
*/
|
||||
execVirtualSubAgent?: (params: ExecVirtualSubAgentParams) => Promise<unknown>;
|
||||
}
|
||||
|
||||
export interface AgentRuntimeServiceOptions {
|
||||
@@ -1864,10 +1873,7 @@ export class AgentRuntimeService {
|
||||
if (!tool || typeof tool !== 'object') continue;
|
||||
|
||||
const toolPayload = tool as { id?: unknown; result_msg_id?: unknown };
|
||||
if (
|
||||
typeof toolPayload.id === 'string' &&
|
||||
typeof toolPayload.result_msg_id === 'string'
|
||||
) {
|
||||
if (typeof toolPayload.id === 'string' && typeof toolPayload.result_msg_id === 'string') {
|
||||
toolResultMessageIds.set(toolPayload.id, toolPayload.result_msg_id);
|
||||
}
|
||||
}
|
||||
@@ -1944,6 +1950,7 @@ export class AgentRuntimeService {
|
||||
userTimezone: metadata?.userTimezone,
|
||||
evalContext: metadata?.evalContext,
|
||||
execSubAgent: this.delegate.execSubAgent,
|
||||
execVirtualSubAgent: this.delegate.execVirtualSubAgent,
|
||||
hookDispatcher,
|
||||
loadAgentState: this.coordinator.loadAgentState.bind(this.coordinator),
|
||||
messageModel: this.messageModel,
|
||||
|
||||
@@ -344,11 +344,16 @@ export class CompletionLifecycle {
|
||||
metadata?.assistantMessageId,
|
||||
metadata?.userId || this.userId,
|
||||
);
|
||||
void runVerifyOnCompletion(this.serverDB, metadata?.userId || this.userId, {
|
||||
deliverable: event.lastAssistantContent ?? '',
|
||||
goal,
|
||||
operationId,
|
||||
});
|
||||
void runVerifyOnCompletion(
|
||||
this.serverDB,
|
||||
metadata?.userId || this.userId,
|
||||
{
|
||||
deliverable: event.lastAssistantContent ?? '',
|
||||
goal,
|
||||
operationId,
|
||||
},
|
||||
this.workspaceId,
|
||||
);
|
||||
}
|
||||
|
||||
if (reason === 'error') {
|
||||
|
||||
@@ -2,13 +2,17 @@ import { afterEach, beforeEach, describe, expect, it, vi } from 'vitest';
|
||||
|
||||
import { AiAgentService } from '../index';
|
||||
|
||||
const { mockMessageCreate, mockResolveAttachmentMetadata, mockSpawnHeteroSandbox } = vi.hoisted(
|
||||
() => ({
|
||||
mockMessageCreate: vi.fn(),
|
||||
mockResolveAttachmentMetadata: vi.fn(),
|
||||
mockSpawnHeteroSandbox: vi.fn().mockResolvedValue(undefined),
|
||||
}),
|
||||
);
|
||||
const {
|
||||
mockMessageCreate,
|
||||
mockResolveAttachmentMetadata,
|
||||
mockSandboxCallTool,
|
||||
mockSpawnHeteroSandbox,
|
||||
} = vi.hoisted(() => ({
|
||||
mockMessageCreate: vi.fn(),
|
||||
mockResolveAttachmentMetadata: vi.fn(),
|
||||
mockSandboxCallTool: vi.fn(),
|
||||
mockSpawnHeteroSandbox: vi.fn().mockResolvedValue({}),
|
||||
}));
|
||||
|
||||
vi.mock('@/libs/trusted-client', () => ({
|
||||
generateTrustedClientToken: vi.fn().mockReturnValue(undefined),
|
||||
@@ -99,6 +103,12 @@ vi.mock('@/server/services/heterogeneousAgent/sandboxRunner', () => ({
|
||||
spawnHeteroSandbox: mockSpawnHeteroSandbox,
|
||||
}));
|
||||
|
||||
vi.mock('@/server/services/sandbox', () => ({
|
||||
createSandboxService: vi.fn(() => ({
|
||||
callTool: mockSandboxCallTool,
|
||||
})),
|
||||
}));
|
||||
|
||||
vi.mock('@/server/services/file/resolveAttachments', () => ({
|
||||
resolveAttachmentMetadata: mockResolveAttachmentMetadata,
|
||||
resolveAttachmentsByFileIds: vi.fn().mockResolvedValue({
|
||||
@@ -148,7 +158,8 @@ describe('AiAgentService.execAgent - hetero early-exit file attachments', () =>
|
||||
topicMock.updateMetadata.mockResolvedValue(undefined);
|
||||
mockMessageCreate.mockResolvedValue({ id: 'msg-1' });
|
||||
mockResolveAttachmentMetadata.mockResolvedValue([]);
|
||||
mockSpawnHeteroSandbox.mockResolvedValue(undefined);
|
||||
mockSandboxCallTool.mockResolvedValue({ success: true });
|
||||
mockSpawnHeteroSandbox.mockResolvedValue({});
|
||||
|
||||
service = new AiAgentService(mockDb, userId);
|
||||
});
|
||||
@@ -290,4 +301,48 @@ describe('AiAgentService.execAgent - hetero early-exit file attachments', () =>
|
||||
expect(mockResolveAttachmentMetadata).not.toHaveBeenCalled();
|
||||
});
|
||||
});
|
||||
|
||||
describe('sandbox stop race', () => {
|
||||
it('should kill the sandbox command when stop was requested before commandId is persisted', async () => {
|
||||
mockSpawnHeteroSandbox.mockResolvedValue({ commandId: 'cmd-delayed' });
|
||||
topicMock.findById.mockImplementation(async () => {
|
||||
const seededRunningOperation = topicMock.updateMetadata.mock.calls.find(
|
||||
([, metadata]) => metadata.runningOperation?.operationId,
|
||||
)?.[1].runningOperation;
|
||||
|
||||
return {
|
||||
id: 'topic-1',
|
||||
metadata: {
|
||||
runningOperation: seededRunningOperation
|
||||
? {
|
||||
...seededRunningOperation,
|
||||
cancelRequestedAt: '2026-01-01T00:00:00.000Z',
|
||||
}
|
||||
: undefined,
|
||||
},
|
||||
};
|
||||
});
|
||||
|
||||
await service.execAgent({
|
||||
agentId: 'agent-1',
|
||||
prompt: 'Run in sandbox',
|
||||
});
|
||||
|
||||
await vi.waitFor(() => {
|
||||
expect(mockSandboxCallTool).toHaveBeenCalledWith('killCommand', {
|
||||
commandId: 'cmd-delayed',
|
||||
});
|
||||
});
|
||||
|
||||
expect(topicMock.updateMetadata).toHaveBeenCalledWith(
|
||||
'topic-1',
|
||||
expect.objectContaining({
|
||||
runningOperation: expect.objectContaining({
|
||||
cancelRequestedAt: '2026-01-01T00:00:00.000Z',
|
||||
sandboxCommandId: 'cmd-delayed',
|
||||
}),
|
||||
}),
|
||||
);
|
||||
});
|
||||
});
|
||||
});
|
||||
|
||||
+50
-3
@@ -21,6 +21,12 @@ vi.mock('@/database/models/thread', () => ({
|
||||
ThreadModel: vi.fn().mockImplementation(() => mockThreadModel),
|
||||
}));
|
||||
|
||||
vi.mock('@/database/models/agentOperation', () => ({
|
||||
AgentOperationModel: vi.fn().mockImplementation(() => ({
|
||||
findById: vi.fn().mockResolvedValue({ trigger: 'cli' }),
|
||||
})),
|
||||
}));
|
||||
|
||||
// Mock other models
|
||||
vi.mock('@/database/models/agent', () => ({
|
||||
AgentModel: vi.fn().mockImplementation(() => ({
|
||||
@@ -115,7 +121,7 @@ describe('AiAgentService.execSubAgent', () => {
|
||||
service = new AiAgentService(mockDb, userId);
|
||||
});
|
||||
|
||||
describe('successful task execution', () => {
|
||||
describe('successful isolated execution', () => {
|
||||
it('should create Thread with correct parameters', async () => {
|
||||
// Mock execAgent to return success
|
||||
vi.spyOn(service, 'execAgent').mockResolvedValue({
|
||||
@@ -208,6 +214,7 @@ describe('AiAgentService.execSubAgent', () => {
|
||||
agentId: 'agent-1',
|
||||
appContext: {
|
||||
groupId: 'group-1',
|
||||
isSubAgent: false,
|
||||
threadId: 'thread-123',
|
||||
topicId: 'topic-1',
|
||||
},
|
||||
@@ -223,6 +230,46 @@ describe('AiAgentService.execSubAgent', () => {
|
||||
});
|
||||
});
|
||||
|
||||
it('should run deferred lobe-agent children through execVirtualSubAgent', async () => {
|
||||
const execAgentSpy = vi.spyOn(service, 'execAgent').mockResolvedValue({
|
||||
agentId: 'agent-1',
|
||||
assistantMessageId: 'assistant-msg-1',
|
||||
autoStarted: true,
|
||||
createdAt: new Date().toISOString(),
|
||||
message: 'Agent operation created successfully',
|
||||
messageId: 'queue-msg-1',
|
||||
operationId: 'op-123',
|
||||
status: 'created',
|
||||
success: true,
|
||||
timestamp: new Date().toISOString(),
|
||||
topicId: 'topic-1',
|
||||
userMessageId: 'user-msg-1',
|
||||
});
|
||||
|
||||
await service.execVirtualSubAgent({
|
||||
agentId: 'agent-1',
|
||||
instruction: 'Nested research task',
|
||||
parentMessageId: 'tool-msg-1',
|
||||
parentOperationId: 'parent-op-1',
|
||||
topicId: 'topic-1',
|
||||
});
|
||||
|
||||
expect(execAgentSpy).toHaveBeenCalledWith(
|
||||
expect.objectContaining({
|
||||
appContext: expect.objectContaining({
|
||||
isSubAgent: true,
|
||||
threadId: 'thread-123',
|
||||
topicId: 'topic-1',
|
||||
}),
|
||||
hooks: expect.arrayContaining([
|
||||
expect.objectContaining({ id: 'sub-agent-bridge', type: 'onComplete' }),
|
||||
]),
|
||||
parentOperationId: 'parent-op-1',
|
||||
trigger: 'cli',
|
||||
}),
|
||||
);
|
||||
});
|
||||
|
||||
it('should store operationId and startedAt in Thread metadata', async () => {
|
||||
vi.spyOn(service, 'execAgent').mockResolvedValue({
|
||||
agentId: 'agent-1',
|
||||
@@ -409,7 +456,7 @@ describe('AiAgentService.execSubAgent', () => {
|
||||
parentMessageId: 'parent-msg-1',
|
||||
topicId: 'topic-1',
|
||||
}),
|
||||
).rejects.toThrow('Failed to create thread for task execution');
|
||||
).rejects.toThrow('Failed to create thread for agent execution');
|
||||
});
|
||||
|
||||
it('should throw error when Thread creation throws', async () => {
|
||||
@@ -427,7 +474,7 @@ describe('AiAgentService.execSubAgent', () => {
|
||||
});
|
||||
});
|
||||
|
||||
describe('task message summary update', () => {
|
||||
describe('source message summary update', () => {
|
||||
it('should pass sourceMessageId (parentMessageId) to callbacks for summary update', async () => {
|
||||
const execAgentSpy = vi.spyOn(service, 'execAgent').mockResolvedValue({
|
||||
agentId: 'agent-1',
|
||||
@@ -29,6 +29,7 @@ import { buildTaskManagerDefaultsPrompt } from '@lobechat/prompts';
|
||||
import type {
|
||||
ChatFileItem,
|
||||
ChatTopicBotContext,
|
||||
ChatTopicMetadata,
|
||||
ChatVideoItem,
|
||||
ExecAgentParams,
|
||||
ExecAgentResult,
|
||||
@@ -36,6 +37,7 @@ import type {
|
||||
ExecGroupAgentResult,
|
||||
ExecSubAgentParams,
|
||||
ExecSubAgentResult,
|
||||
ExecVirtualSubAgentParams,
|
||||
LobeAgentAgencyConfig,
|
||||
MessagePluginItem,
|
||||
UserInterventionConfig,
|
||||
@@ -105,6 +107,7 @@ import { HeterogeneousAgentService } from '@/server/services/heterogeneousAgent'
|
||||
import type { ConversationHistoryEntry } from '@/server/services/heterogeneousAgent/cloudHeteroContext';
|
||||
import { KlavisService } from '@/server/services/klavis';
|
||||
import { MarketService } from '@/server/services/market';
|
||||
import { createSandboxService } from '@/server/services/sandbox';
|
||||
import { markdownToTxt } from '@/utils/markdownToTxt';
|
||||
|
||||
import { resolveDeviceAccessPolicy } from './deviceAccessPolicy';
|
||||
@@ -318,9 +321,10 @@ export class AiAgentService {
|
||||
// high-level pipelines mid-step. See AgentRuntimeDelegate. New high-level
|
||||
// capabilities the runtime calls into go in this `delegate` object.
|
||||
//
|
||||
// `execSubAgent` is an auto-bound arrow field, so no `.bind(this)`.
|
||||
// Arrow fields are auto-bound, so no `.bind(this)`.
|
||||
delegate: {
|
||||
execSubAgent: this.execSubAgent,
|
||||
execVirtualSubAgent: this.execVirtualSubAgent,
|
||||
},
|
||||
workspaceId: wsId,
|
||||
});
|
||||
@@ -415,9 +419,10 @@ export class AiAgentService {
|
||||
* Execute a single agent step against this service's runtime.
|
||||
*
|
||||
* Delegates to the internal AgentRuntimeService, which is already wired with
|
||||
* the `execSubAgent` fork callback. The QStash step worker drives stepping
|
||||
* through here so `lobe-agent.callSubAgent` can fork sub-agents — building a
|
||||
* bare runtime there would lose the callback and fail with SUB_AGENT_UNAVAILABLE.
|
||||
* the agent-invocation fork callbacks. The QStash step worker drives stepping
|
||||
* through here so `lobe-agent.callSubAgent` can fork virtual sub-agents —
|
||||
* building a bare runtime there would lose the callback and fail with
|
||||
* SUB_AGENT_UNAVAILABLE.
|
||||
*/
|
||||
executeStep(params: AgentExecutionParams): Promise<AgentExecutionResult> {
|
||||
return this.agentRuntimeService.executeStep(params);
|
||||
@@ -1037,22 +1042,49 @@ export class AiAgentService {
|
||||
|
||||
const remoteDeviceId =
|
||||
requestedDeviceId || agentConfig.agencyConfig?.boundDeviceId || undefined;
|
||||
type RunningOperationMetadata = NonNullable<ChatTopicMetadata['runningOperation']>;
|
||||
const buildRunningOperationMetadata = (
|
||||
extra: Partial<RunningOperationMetadata> = {},
|
||||
): RunningOperationMetadata => ({
|
||||
assistantMessageId: assistantMsg.id,
|
||||
completionWebhook: hooks?.find((h) => h.type === 'onComplete')?.webhook,
|
||||
heteroType,
|
||||
operationId,
|
||||
scope: appContext?.scope ?? undefined,
|
||||
threadId: appContext?.threadId ?? undefined,
|
||||
...extra,
|
||||
});
|
||||
const updateRunningOperationMetadata = async (
|
||||
extra: Partial<RunningOperationMetadata>,
|
||||
): Promise<RunningOperationMetadata | undefined> => {
|
||||
const latestTopic = await this.topicModel.findById(topicId);
|
||||
const current = latestTopic?.metadata?.runningOperation;
|
||||
if (current && current.operationId !== operationId) {
|
||||
log(
|
||||
'execAgent: skip runningOperation update for stale op=%s current=%s',
|
||||
operationId,
|
||||
current.operationId,
|
||||
);
|
||||
return;
|
||||
}
|
||||
const runningOperation = {
|
||||
...buildRunningOperationMetadata(),
|
||||
...current,
|
||||
...extra,
|
||||
};
|
||||
await this.topicModel.updateMetadata(topicId, {
|
||||
runningOperation,
|
||||
});
|
||||
return runningOperation;
|
||||
};
|
||||
|
||||
// Seed topic.metadata.runningOperation so heteroIngest can validate the operation.
|
||||
// completionWebhook is stored so heteroFinish can call back to the IM bot-callback
|
||||
// endpoint even though the hetero path bypasses the normal hook registration flow.
|
||||
await this.topicModel.updateMetadata(topicId, {
|
||||
runningOperation: {
|
||||
assistantMessageId: assistantMsg.id,
|
||||
completionWebhook: hooks?.find((h) => h.type === 'onComplete')?.webhook,
|
||||
// Store deviceId + heteroType so interruptTask can cancel remote processes
|
||||
...(isRemoteHetero && remoteDeviceId
|
||||
? { deviceId: remoteDeviceId, heteroType }
|
||||
: undefined),
|
||||
operationId,
|
||||
scope: appContext?.scope ?? undefined,
|
||||
threadId: appContext?.threadId ?? undefined,
|
||||
},
|
||||
runningOperation: buildRunningOperationMetadata(
|
||||
isRemoteHetero && remoteDeviceId ? { deviceId: remoteDeviceId } : {},
|
||||
),
|
||||
});
|
||||
|
||||
// Remote hetero agents (openclaw / hermes) dispatch to the device identified
|
||||
@@ -1238,6 +1270,8 @@ export class AiAgentService {
|
||||
userMessageId: userMsg?.id ?? parentMessageId ?? '',
|
||||
};
|
||||
}
|
||||
await updateRunningOperationMetadata({ deviceId: dispatchDeviceId });
|
||||
|
||||
// Resolve the working directory for the run: a topic-level override
|
||||
// wins, else the device's user-configured defaultCwd. The device row
|
||||
// lives in the DB (the gateway only knows live connections), so read
|
||||
@@ -1315,9 +1349,24 @@ export class AiAgentService {
|
||||
...heteroParams,
|
||||
agentType: heteroType as 'claude-code' | 'codex',
|
||||
marketService: this.marketService,
|
||||
}).catch((err) => {
|
||||
log('execAgent: hetero sandbox spawn failed: %O', err);
|
||||
});
|
||||
})
|
||||
.then(async ({ commandId }) => {
|
||||
if (!commandId) return;
|
||||
const runningOperation = await updateRunningOperationMetadata({
|
||||
sandboxCommandId: commandId,
|
||||
});
|
||||
if (!runningOperation?.cancelRequestedAt) return;
|
||||
await createSandboxService({
|
||||
marketService: this.marketService,
|
||||
topicId,
|
||||
userId: this.userId,
|
||||
})
|
||||
.callTool('killCommand', { commandId })
|
||||
.catch((err) => log('execAgent: delayed sandbox killCommand failed: %O', err));
|
||||
})
|
||||
.catch((err) => {
|
||||
log('execAgent: hetero sandbox spawn failed: %O', err);
|
||||
});
|
||||
}
|
||||
}
|
||||
|
||||
@@ -2296,7 +2345,7 @@ export class AiAgentService {
|
||||
: undefined;
|
||||
|
||||
// 13. Create user message in database
|
||||
// Include threadId if provided (for SubAgent task execution in isolated Thread)
|
||||
// Include threadId if provided (for isolated agent execution)
|
||||
const userMessageRecord = runFromHistory
|
||||
? undefined
|
||||
: await this.messageModel.create({
|
||||
@@ -2344,7 +2393,7 @@ export class AiAgentService {
|
||||
}
|
||||
|
||||
// 14. Create assistant message placeholder in database
|
||||
// Include threadId if provided (for SubAgent task execution in isolated Thread)
|
||||
// Include threadId if provided (for isolated agent execution)
|
||||
const assistantMessageRecord = await this.messageModel.create({
|
||||
agentId: persistAgentId,
|
||||
content: LOADING_FLAT,
|
||||
@@ -2856,35 +2905,46 @@ export class AiAgentService {
|
||||
}
|
||||
|
||||
/**
|
||||
* Execute SubAgent task (supports both Group and Single Agent mode)
|
||||
* Execute an agent in an isolated Thread context.
|
||||
*
|
||||
* This method is called by Supervisor (Group mode) or Agent (Single mode)
|
||||
* to delegate tasks to SubAgents. Each task runs in an isolated Thread context.
|
||||
*
|
||||
* - Group mode: pass groupId, Thread will be associated with the Group
|
||||
* - Single Agent mode: omit groupId, Thread will only be associated with the Agent
|
||||
*
|
||||
* Flow:
|
||||
* 1. Create Thread (type='isolation', status='processing')
|
||||
* 2. Delegate to execAgent with threadId in appContext
|
||||
* 3. Store operationId in Thread metadata
|
||||
* Group/callAgent paths use this entry. It does not mark the child as a
|
||||
* virtual sub-agent and it does not install the async completion bridge.
|
||||
*/
|
||||
// Arrow field (not a method) so it stays bound to this instance when handed to
|
||||
// AgentRuntimeService as the `execSubAgent` fork callback — no `.bind(this)`.
|
||||
execSubAgent = async (params: ExecSubAgentParams): Promise<ExecSubAgentResult> => {
|
||||
const {
|
||||
groupId,
|
||||
topicId,
|
||||
parentMessageId,
|
||||
agentId,
|
||||
instruction,
|
||||
title,
|
||||
parentOperationId,
|
||||
resumeParentOnComplete,
|
||||
} = params;
|
||||
// Arrow field (not a method) so it stays bound when handed to AgentRuntimeService.
|
||||
execSubAgent = async (params: ExecSubAgentParams): Promise<ExecSubAgentResult> =>
|
||||
this.execAgentThreadRun(params, {
|
||||
isSubAgent: false,
|
||||
logScope: 'execSubAgent',
|
||||
});
|
||||
|
||||
/**
|
||||
* Execute a virtual sub-agent created by `lobe-agent.callSubAgent`.
|
||||
*
|
||||
* This path is a child operation of the current agent run. It is marked as a
|
||||
* sub-agent so it cannot recursively spawn more sub-agents, and it registers
|
||||
* the bridge that backfills the parent's placeholder tool message.
|
||||
*/
|
||||
execVirtualSubAgent = async (params: ExecVirtualSubAgentParams): Promise<ExecSubAgentResult> =>
|
||||
this.execAgentThreadRun(params, {
|
||||
isSubAgent: true,
|
||||
logScope: 'execVirtualSubAgent',
|
||||
resumeParentOnComplete: true,
|
||||
});
|
||||
|
||||
private async execAgentThreadRun(
|
||||
params: ExecSubAgentParams | ExecVirtualSubAgentParams,
|
||||
options: {
|
||||
isSubAgent: boolean;
|
||||
logScope: 'execSubAgent' | 'execVirtualSubAgent';
|
||||
resumeParentOnComplete?: boolean;
|
||||
},
|
||||
): Promise<ExecSubAgentResult> {
|
||||
const { groupId, topicId, parentMessageId, agentId, instruction, title, parentOperationId } =
|
||||
params;
|
||||
|
||||
log(
|
||||
'execSubAgent: agentId=%s, groupId=%s, topicId=%s, instruction=%s',
|
||||
'%s: agentId=%s, groupId=%s, topicId=%s, instruction=%s',
|
||||
options.logScope,
|
||||
agentId,
|
||||
groupId,
|
||||
topicId,
|
||||
@@ -2903,7 +2963,7 @@ export class AiAgentService {
|
||||
.catch(() => {});
|
||||
}
|
||||
|
||||
// 1. Create Thread for isolated task execution
|
||||
// 1. Create Thread for isolated agent execution
|
||||
const thread = await this.threadModel.create({
|
||||
agentId,
|
||||
groupId,
|
||||
@@ -2914,10 +2974,10 @@ export class AiAgentService {
|
||||
});
|
||||
|
||||
if (!thread) {
|
||||
throw new Error('Failed to create thread for task execution');
|
||||
throw new Error('Failed to create thread for agent execution');
|
||||
}
|
||||
|
||||
log('execSubAgent: created thread %s', thread.id);
|
||||
log('%s: created thread %s', options.logScope, thread.id);
|
||||
|
||||
// 2. Update Thread status to processing with startedAt timestamp
|
||||
const startedAt = new Date().toISOString();
|
||||
@@ -2926,14 +2986,19 @@ export class AiAgentService {
|
||||
status: ThreadStatus.Processing,
|
||||
});
|
||||
|
||||
// 3. Create hooks for updating Thread metadata and task message
|
||||
const threadHooks = this.createThreadHooks(thread.id, startedAt, parentMessageId);
|
||||
// For the deferred-tool path, also register the completion bridge that
|
||||
// 3. Create hooks for updating Thread metadata and source message
|
||||
const threadHooks = this.createThreadHooks(
|
||||
thread.id,
|
||||
startedAt,
|
||||
parentMessageId,
|
||||
options.logScope,
|
||||
);
|
||||
// For the virtual sub-agent path, also register the completion bridge that
|
||||
// backfills the parent's placeholder tool message and resumes the parked
|
||||
// parent op once the whole batch is done. Registered last so its
|
||||
// tool-message backfill (content + pluginState) is the final write.
|
||||
// parent op once the child run is done. Registered last so its tool-message
|
||||
// backfill (content + pluginState) is the final write.
|
||||
const hooks =
|
||||
resumeParentOnComplete && parentOperationId
|
||||
options.resumeParentOnComplete && parentOperationId
|
||||
? [
|
||||
...threadHooks,
|
||||
this.createSubAgentBridgeHook(parentOperationId, parentMessageId, thread.id),
|
||||
@@ -2953,16 +3018,23 @@ export class AiAgentService {
|
||||
).findById(parentOperationId);
|
||||
inheritedTrigger = parentOp?.trigger ?? undefined;
|
||||
} catch (error) {
|
||||
log('execSubAgent: failed to read parent operation trigger: %O', error);
|
||||
log('%s: failed to read parent operation trigger: %O', options.logScope, error);
|
||||
}
|
||||
}
|
||||
|
||||
const appContext: NonNullable<InternalExecAgentParams['appContext']> = {
|
||||
groupId,
|
||||
isSubAgent: options.isSubAgent,
|
||||
threadId: thread.id,
|
||||
topicId,
|
||||
};
|
||||
|
||||
// 4. Delegate to execAgent with threadId in appContext and hooks
|
||||
// The instruction will be created as user message in the Thread
|
||||
// Use headless mode to skip human approval in async task execution
|
||||
// Use headless mode to skip human approval in async agent execution
|
||||
const result = await this.execAgent({
|
||||
agentId,
|
||||
appContext: { groupId, threadId: thread.id, topicId },
|
||||
appContext,
|
||||
autoStart: true,
|
||||
hooks,
|
||||
parentOperationId,
|
||||
@@ -2972,7 +3044,8 @@ export class AiAgentService {
|
||||
});
|
||||
|
||||
log(
|
||||
'execSubAgent: delegated to execAgent, operationId=%s, success=%s',
|
||||
'%s: delegated to execAgent, operationId=%s, success=%s',
|
||||
options.logScope,
|
||||
result.operationId,
|
||||
result.success,
|
||||
);
|
||||
@@ -3028,7 +3101,7 @@ export class AiAgentService {
|
||||
success: result.success ?? false,
|
||||
threadId: thread.id,
|
||||
};
|
||||
};
|
||||
}
|
||||
|
||||
/**
|
||||
* Create step lifecycle callbacks for updating Thread metadata
|
||||
@@ -3036,12 +3109,13 @@ export class AiAgentService {
|
||||
*
|
||||
* @param threadId - The Thread ID to update
|
||||
* @param startedAt - The start time ISO string
|
||||
* @param sourceMessageId - The task message ID (sourceMessageId from Thread) to update with summary
|
||||
* @param sourceMessageId - The source message ID from Thread to update with summary
|
||||
*/
|
||||
private createThreadMetadataCallbacks(
|
||||
threadId: string,
|
||||
startedAt: string,
|
||||
sourceMessageId: string,
|
||||
logScope: 'execSubAgent' | 'execVirtualSubAgent' = 'execSubAgent',
|
||||
): StepLifecycleCallbacks {
|
||||
// Accumulator for tracking metrics across steps
|
||||
let accumulatedToolCalls = 0;
|
||||
@@ -3067,9 +3141,9 @@ export class AiAgentService {
|
||||
totalToolCalls: accumulatedToolCalls,
|
||||
},
|
||||
});
|
||||
log('execSubAgent: updated thread %s metadata after step %d', threadId, state.stepCount);
|
||||
log('%s: updated thread %s metadata after step %d', logScope, threadId, state.stepCount);
|
||||
} catch (error) {
|
||||
log('execSubAgent: failed to update thread metadata: %O', error);
|
||||
log('%s: failed to update thread metadata: %O', logScope, error);
|
||||
}
|
||||
},
|
||||
|
||||
@@ -3101,13 +3175,13 @@ export class AiAgentService {
|
||||
}
|
||||
}
|
||||
|
||||
// Log error when task fails
|
||||
// Log error when the isolated run fails
|
||||
if (reason === 'error' && finalState.error) {
|
||||
console.error('execSubAgent: task failed for thread %s:', threadId, finalState.error);
|
||||
console.error('%s: run failed for thread %s:', logScope, threadId, finalState.error);
|
||||
}
|
||||
|
||||
try {
|
||||
// Extract summary from last assistant message and update task message content
|
||||
// Extract summary from last assistant message and update source message content
|
||||
const lastAssistantMessage = finalState.messages
|
||||
?.slice()
|
||||
.reverse()
|
||||
@@ -3117,7 +3191,7 @@ export class AiAgentService {
|
||||
await this.messageModel.update(sourceMessageId, {
|
||||
content: lastAssistantMessage.content,
|
||||
});
|
||||
log('execSubAgent: updated task message %s with summary', sourceMessageId);
|
||||
log('%s: updated source message %s with summary', logScope, sourceMessageId);
|
||||
}
|
||||
|
||||
// Format error for proper serialization (Error objects don't serialize with JSON.stringify)
|
||||
@@ -3140,13 +3214,14 @@ export class AiAgentService {
|
||||
});
|
||||
|
||||
log(
|
||||
'execSubAgent: thread %s completed with status %s, reason: %s',
|
||||
'%s: thread %s completed with status %s, reason: %s',
|
||||
logScope,
|
||||
threadId,
|
||||
status,
|
||||
reason,
|
||||
);
|
||||
} catch (error) {
|
||||
console.error('execSubAgent: failed to update thread on completion: %O', error);
|
||||
console.error('%s: failed to update thread on completion: %O', logScope, error);
|
||||
}
|
||||
},
|
||||
};
|
||||
@@ -3160,6 +3235,7 @@ export class AiAgentService {
|
||||
threadId: string,
|
||||
startedAt: string,
|
||||
sourceMessageId: string,
|
||||
logScope: 'execSubAgent' | 'execVirtualSubAgent',
|
||||
): AgentHook[] {
|
||||
let accumulatedToolCalls = 0;
|
||||
|
||||
@@ -3186,7 +3262,7 @@ export class AiAgentService {
|
||||
},
|
||||
});
|
||||
} catch (error) {
|
||||
log('Thread hook afterStep: failed to update metadata: %O', error);
|
||||
log('%s: thread hook afterStep failed to update metadata: %O', logScope, error);
|
||||
}
|
||||
},
|
||||
id: 'thread-metadata-update',
|
||||
@@ -3226,14 +3302,15 @@ export class AiAgentService {
|
||||
|
||||
if (event.reason === 'error' && finalState.error) {
|
||||
console.error(
|
||||
'Thread hook onComplete: task failed for thread %s:',
|
||||
'%s: thread hook onComplete run failed for thread %s:',
|
||||
logScope,
|
||||
threadId,
|
||||
finalState.error,
|
||||
);
|
||||
}
|
||||
|
||||
try {
|
||||
// Update task message with summary
|
||||
// Update source message with summary
|
||||
const lastAssistantMessage = finalState.messages
|
||||
?.slice()
|
||||
.reverse()
|
||||
@@ -3263,13 +3340,14 @@ export class AiAgentService {
|
||||
});
|
||||
|
||||
log(
|
||||
'Thread hook onComplete: thread %s status=%s reason=%s',
|
||||
'%s: thread hook onComplete thread %s status=%s reason=%s',
|
||||
logScope,
|
||||
threadId,
|
||||
status,
|
||||
event.reason,
|
||||
);
|
||||
} catch (error) {
|
||||
console.error('Thread hook onComplete: failed to update: %O', error);
|
||||
console.error('%s: thread hook onComplete failed to update: %O', logScope, error);
|
||||
}
|
||||
},
|
||||
id: 'thread-completion',
|
||||
@@ -3378,31 +3456,50 @@ export class AiAgentService {
|
||||
throw new Error('Operation ID not found');
|
||||
}
|
||||
|
||||
// 2. Cancel remote hetero process (openclaw / hermes) if applicable.
|
||||
// Check topic.metadata.runningOperation for device + heteroType info seeded by execAgent.
|
||||
// 2. Cancel hetero processes when the run lives outside the server process.
|
||||
// Device-dispatched local CLI agents (claude-code / codex) and remote
|
||||
// platform agents (openclaw / hermes) are killed through the connected
|
||||
// device. Sandbox-dispatched local CLI agents are killed through sandbox
|
||||
// command cancellation when the background command id is available.
|
||||
// This runs regardless of whether interruptOperation succeeds — the remote process
|
||||
// is independent of the local operation registry.
|
||||
if (topicId) {
|
||||
const topic = await this.topicModel.findById(topicId);
|
||||
const runningOp = (topic?.metadata as any)?.runningOperation as
|
||||
| { deviceId?: string; heteroType?: string; operationId?: string }
|
||||
| undefined;
|
||||
const runningOp = topic?.metadata?.runningOperation;
|
||||
|
||||
if (
|
||||
runningOp?.deviceId &&
|
||||
runningOp.heteroType &&
|
||||
isRemoteHeterogeneousType(runningOp.heteroType)
|
||||
) {
|
||||
const taskId = runningOp.operationId ?? resolvedOperationId;
|
||||
const runningOperation =
|
||||
runningOp?.operationId === resolvedOperationId
|
||||
? {
|
||||
...runningOp,
|
||||
operationId: resolvedOperationId,
|
||||
}
|
||||
: undefined;
|
||||
|
||||
if (runningOp && runningOp.operationId !== resolvedOperationId) {
|
||||
log(
|
||||
'interruptTask: cancelling remote hetero process heteroType=%s deviceId=%s taskId=%s',
|
||||
runningOp.heteroType,
|
||||
runningOp.deviceId,
|
||||
'interruptTask: skip hetero process cancel for stale op=%s current=%s topicId=%s',
|
||||
resolvedOperationId,
|
||||
runningOp.operationId,
|
||||
topicId,
|
||||
);
|
||||
} else if (runningOperation) {
|
||||
const cancelRequestedAt = runningOperation.cancelRequestedAt ?? new Date().toISOString();
|
||||
await this.topicModel.updateMetadata(topicId, {
|
||||
runningOperation: { ...runningOperation, cancelRequestedAt },
|
||||
});
|
||||
}
|
||||
|
||||
if (runningOperation?.deviceId && runningOperation.heteroType) {
|
||||
const taskId = runningOperation.operationId;
|
||||
log(
|
||||
'interruptTask: cancelling hetero device process heteroType=%s deviceId=%s taskId=%s',
|
||||
runningOperation.heteroType,
|
||||
runningOperation.deviceId,
|
||||
taskId,
|
||||
);
|
||||
await deviceGateway
|
||||
.executeToolCall(
|
||||
{ deviceId: runningOp.deviceId, userId: this.userId },
|
||||
{ deviceId: runningOperation.deviceId, userId: this.userId },
|
||||
{
|
||||
apiName: 'cancelHeteroTask',
|
||||
arguments: JSON.stringify({ signal: 'SIGINT', taskId }),
|
||||
@@ -3412,6 +3509,21 @@ export class AiAgentService {
|
||||
)
|
||||
.catch((err) => log('interruptTask: cancelHeteroTask dispatch failed: %O', err));
|
||||
}
|
||||
|
||||
if (runningOperation?.sandboxCommandId) {
|
||||
log(
|
||||
'interruptTask: cancelling hetero sandbox command commandId=%s topicId=%s',
|
||||
runningOperation.sandboxCommandId,
|
||||
topicId,
|
||||
);
|
||||
await createSandboxService({
|
||||
marketService: this.marketService,
|
||||
topicId,
|
||||
userId: this.userId,
|
||||
})
|
||||
.callTool('killCommand', { commandId: runningOperation.sandboxCommandId })
|
||||
.catch((err) => log('interruptTask: sandbox killCommand failed: %O', err));
|
||||
}
|
||||
}
|
||||
|
||||
// 3. Interrupt the runtime operation first. Only mark the thread cancelled
|
||||
|
||||
@@ -990,6 +990,7 @@ export class BotMessageRouter {
|
||||
agentId,
|
||||
db: serverDB,
|
||||
userId,
|
||||
workspaceId: workspaceId ?? undefined,
|
||||
},
|
||||
{ ignoreError: true },
|
||||
);
|
||||
@@ -1175,6 +1176,7 @@ export class BotMessageRouter {
|
||||
agentId,
|
||||
db: serverDB,
|
||||
userId,
|
||||
workspaceId: workspaceId ?? undefined,
|
||||
},
|
||||
{ ignoreError: true },
|
||||
);
|
||||
@@ -1392,6 +1394,7 @@ export class BotMessageRouter {
|
||||
agentId,
|
||||
db: serverDB,
|
||||
userId,
|
||||
workspaceId: workspaceId ?? undefined,
|
||||
},
|
||||
{ ignoreError: true },
|
||||
);
|
||||
|
||||
@@ -718,7 +718,37 @@ describe('DeviceGateway', () => {
|
||||
{ deviceId: 'dev-1', timeout: 30_000, userId: 'user-1' },
|
||||
{
|
||||
method: 'getLocalFilePreview',
|
||||
params: { path: '/proj/App.tsx', workingDirectory: '/proj' },
|
||||
params: { accept: undefined, path: '/proj/App.tsx', workingDirectory: '/proj' },
|
||||
},
|
||||
);
|
||||
});
|
||||
|
||||
it('forwards image-only preview constraints to the device rpc', async () => {
|
||||
configure();
|
||||
const data = {
|
||||
preview: {
|
||||
base64: 'aW1hZ2U=',
|
||||
contentType: 'image/png',
|
||||
type: 'image',
|
||||
},
|
||||
success: true,
|
||||
};
|
||||
mockClient.invokeRpc.mockResolvedValue({ data, success: true });
|
||||
|
||||
const proxy = new DeviceGateway();
|
||||
await proxy.getLocalFilePreview({
|
||||
accept: 'image',
|
||||
deviceId: 'dev-1',
|
||||
path: '/proj/image.png',
|
||||
userId: 'user-1',
|
||||
workingDirectory: '/proj',
|
||||
});
|
||||
|
||||
expect(mockClient.invokeRpc).toHaveBeenCalledWith(
|
||||
{ deviceId: 'dev-1', timeout: 30_000, userId: 'user-1' },
|
||||
{
|
||||
method: 'getLocalFilePreview',
|
||||
params: { accept: 'image', path: '/proj/image.png', workingDirectory: '/proj' },
|
||||
},
|
||||
);
|
||||
});
|
||||
|
||||
@@ -473,20 +473,24 @@ export class DeviceGateway {
|
||||
* exposing a `localfile://` URL to web callers.
|
||||
*/
|
||||
async getLocalFilePreview(params: {
|
||||
accept?: 'image';
|
||||
deviceId: string;
|
||||
path: string;
|
||||
timeout?: number;
|
||||
userId: string;
|
||||
workingDirectory: string;
|
||||
}): Promise<DeviceLocalFilePreviewResult> {
|
||||
const { userId, deviceId, path, workingDirectory, timeout = 30_000 } = params;
|
||||
const { accept, userId, deviceId, path, workingDirectory, timeout = 30_000 } = params;
|
||||
const client = this.getClient();
|
||||
if (!client) return { error: 'Device gateway not configured', success: false };
|
||||
|
||||
try {
|
||||
const result = await client.invokeRpc<DeviceLocalFilePreviewResult>(
|
||||
{ deviceId, timeout, userId },
|
||||
{ method: 'getLocalFilePreview', params: { path, workingDirectory } },
|
||||
{
|
||||
method: 'getLocalFilePreview',
|
||||
params: { accept, path, workingDirectory },
|
||||
},
|
||||
);
|
||||
|
||||
if (!result.success || !result.data) {
|
||||
@@ -665,7 +669,7 @@ export class DeviceGateway {
|
||||
}
|
||||
|
||||
async executeToolCall(
|
||||
params: { deviceId: string; userId: string },
|
||||
params: { deviceId: string; operationId?: string; userId: string },
|
||||
toolCall: { apiName: string; arguments: string; identifier: string },
|
||||
timeout = 30_000,
|
||||
): Promise<DeviceToolCallResult> {
|
||||
@@ -679,7 +683,8 @@ export class DeviceGateway {
|
||||
}
|
||||
|
||||
log(
|
||||
'executeToolCall: userId=%s, deviceId=%s, tool=%s/%s',
|
||||
'executeToolCall: operationId=%s, userId=%s, deviceId=%s, tool=%s/%s',
|
||||
params.operationId ?? 'N/A',
|
||||
params.userId,
|
||||
params.deviceId,
|
||||
toolCall.identifier,
|
||||
@@ -688,7 +693,12 @@ export class DeviceGateway {
|
||||
|
||||
try {
|
||||
return await client.executeToolCall(
|
||||
{ deviceId: params.deviceId, timeout, userId: params.userId },
|
||||
{
|
||||
deviceId: params.deviceId,
|
||||
operationId: params.operationId,
|
||||
timeout,
|
||||
userId: params.userId,
|
||||
},
|
||||
toolCall,
|
||||
);
|
||||
} catch (error) {
|
||||
|
||||
@@ -3,7 +3,10 @@ import { documentHistories, documents, files, users } from '@lobechat/database/s
|
||||
import { and, desc, eq } from 'drizzle-orm';
|
||||
import { afterEach, beforeEach, describe, expect, it } from 'vitest';
|
||||
|
||||
import { DOCUMENT_HISTORY_SOURCE_LIMITS } from '@/const/documentHistory';
|
||||
import {
|
||||
DOCUMENT_HISTORY_AUTOSAVE_WINDOW_MS,
|
||||
DOCUMENT_HISTORY_SOURCE_LIMITS,
|
||||
} from '@/const/documentHistory';
|
||||
import { getTestDB } from '@/database/core/getTestDB';
|
||||
import { DocumentModel } from '@/database/models/document';
|
||||
import { FileModel } from '@/database/models/file';
|
||||
@@ -420,7 +423,7 @@ describe('DocumentHistoryService', () => {
|
||||
documentId: doc.id,
|
||||
editorData: { v: i },
|
||||
saveSource: 'autosave',
|
||||
savedAt: new Date(2026, 3, 1, 0, i, 0),
|
||||
savedAt: new Date(2026, 3, 1, 0, i * 10, 0),
|
||||
});
|
||||
}
|
||||
|
||||
@@ -463,6 +466,182 @@ describe('DocumentHistoryService', () => {
|
||||
});
|
||||
});
|
||||
|
||||
describe('autosave window coalescing', () => {
|
||||
const base = new Date('2026-04-01T10:00:00Z');
|
||||
const minutes = (n: number) => new Date(base.getTime() + n * 60 * 1000);
|
||||
|
||||
const listRows = (documentId: string) =>
|
||||
serverDB
|
||||
.select()
|
||||
.from(documentHistories)
|
||||
.where(eq(documentHistories.documentId, documentId))
|
||||
.orderBy(desc(documentHistories.savedAt), desc(documentHistories.id));
|
||||
|
||||
it('should overwrite the latest autosave row within the window', async () => {
|
||||
const doc = await createTestDocument('Hello');
|
||||
|
||||
await historyService.createHistory({
|
||||
documentId: doc.id,
|
||||
editorData: { v: 1 },
|
||||
saveSource: 'autosave',
|
||||
savedAt: base,
|
||||
});
|
||||
|
||||
await historyService.createHistory({
|
||||
documentId: doc.id,
|
||||
editorData: { v: 2 },
|
||||
saveSource: 'autosave',
|
||||
savedAt: minutes(5),
|
||||
});
|
||||
|
||||
const rows = await listRows(doc.id);
|
||||
|
||||
expect(rows).toHaveLength(1);
|
||||
expect(rows[0].editorData).toEqual({ v: 2 });
|
||||
expect(rows[0].savedAt).toEqual(minutes(5));
|
||||
});
|
||||
|
||||
it('should insert a new row once the save falls into the next window bucket', async () => {
|
||||
const doc = await createTestDocument('Hello');
|
||||
const windowMinutes = DOCUMENT_HISTORY_AUTOSAVE_WINDOW_MS / 60_000;
|
||||
|
||||
for (const [i, at] of [
|
||||
base,
|
||||
minutes(5),
|
||||
minutes(windowMinutes),
|
||||
minutes(windowMinutes + 5),
|
||||
].entries()) {
|
||||
await historyService.createHistory({
|
||||
documentId: doc.id,
|
||||
editorData: { v: i + 1 },
|
||||
saveSource: 'autosave',
|
||||
savedAt: at,
|
||||
});
|
||||
}
|
||||
|
||||
const rows = await listRows(doc.id);
|
||||
|
||||
expect(rows).toHaveLength(2);
|
||||
expect(rows[0].editorData).toEqual({ v: 4 });
|
||||
expect(rows[0].savedAt).toEqual(minutes(windowMinutes + 5));
|
||||
expect(rows[1].editorData).toEqual({ v: 2 });
|
||||
expect(rows[1].savedAt).toEqual(minutes(5));
|
||||
});
|
||||
|
||||
it('should start a new window when a non-autosave version is the latest', async () => {
|
||||
const doc = await createTestDocument('Hello');
|
||||
|
||||
await historyService.createHistory({
|
||||
documentId: doc.id,
|
||||
editorData: { v: 1 },
|
||||
saveSource: 'autosave',
|
||||
savedAt: base,
|
||||
});
|
||||
|
||||
await historyService.createHistory({
|
||||
documentId: doc.id,
|
||||
editorData: { v: 2 },
|
||||
saveSource: 'manual',
|
||||
savedAt: minutes(1),
|
||||
});
|
||||
|
||||
await historyService.createHistory({
|
||||
documentId: doc.id,
|
||||
editorData: { v: 3 },
|
||||
saveSource: 'autosave',
|
||||
savedAt: minutes(2),
|
||||
});
|
||||
|
||||
const rows = await listRows(doc.id);
|
||||
|
||||
expect(rows).toHaveLength(3);
|
||||
expect(rows.map((r) => r.saveSource)).toEqual(['autosave', 'manual', 'autosave']);
|
||||
});
|
||||
|
||||
it('should never coalesce manual saves', async () => {
|
||||
const doc = await createTestDocument('Hello');
|
||||
|
||||
await historyService.createHistory({
|
||||
documentId: doc.id,
|
||||
editorData: { v: 1 },
|
||||
saveSource: 'manual',
|
||||
savedAt: base,
|
||||
});
|
||||
|
||||
await historyService.createHistory({
|
||||
documentId: doc.id,
|
||||
editorData: { v: 2 },
|
||||
saveSource: 'manual',
|
||||
savedAt: minutes(1),
|
||||
});
|
||||
|
||||
const rows = await listRows(doc.id);
|
||||
|
||||
expect(rows).toHaveLength(2);
|
||||
});
|
||||
|
||||
it('should insert a new row within the same window when breakAutosaveWindow is true', async () => {
|
||||
const doc = await createTestDocument('Hello');
|
||||
|
||||
await historyService.createHistory({
|
||||
documentId: doc.id,
|
||||
editorData: { v: 1 },
|
||||
saveSource: 'autosave',
|
||||
savedAt: base,
|
||||
});
|
||||
|
||||
await historyService.createHistory({
|
||||
breakAutosaveWindow: true,
|
||||
documentId: doc.id,
|
||||
editorData: { v: 2 },
|
||||
saveSource: 'autosave',
|
||||
savedAt: minutes(3),
|
||||
});
|
||||
|
||||
const rows = await listRows(doc.id);
|
||||
|
||||
expect(rows).toHaveLength(2);
|
||||
expect(rows[0].editorData).toEqual({ v: 2 });
|
||||
expect(rows[0].savedAt).toEqual(minutes(3));
|
||||
expect(rows[1].editorData).toEqual({ v: 1 });
|
||||
expect(rows[1].savedAt).toEqual(base);
|
||||
});
|
||||
|
||||
it('should coalesce into the break row on the next autosave without the flag', async () => {
|
||||
const doc = await createTestDocument('Hello');
|
||||
|
||||
await historyService.createHistory({
|
||||
documentId: doc.id,
|
||||
editorData: { v: 1 },
|
||||
saveSource: 'autosave',
|
||||
savedAt: base,
|
||||
});
|
||||
|
||||
await historyService.createHistory({
|
||||
breakAutosaveWindow: true,
|
||||
documentId: doc.id,
|
||||
editorData: { v: 2 },
|
||||
saveSource: 'autosave',
|
||||
savedAt: minutes(3),
|
||||
});
|
||||
|
||||
await historyService.createHistory({
|
||||
documentId: doc.id,
|
||||
editorData: { v: 3 },
|
||||
saveSource: 'autosave',
|
||||
savedAt: minutes(5),
|
||||
});
|
||||
|
||||
const rows = await listRows(doc.id);
|
||||
|
||||
expect(rows).toHaveLength(2);
|
||||
expect(rows[0].editorData).toEqual({ v: 3 });
|
||||
expect(rows[0].savedAt).toEqual(minutes(5));
|
||||
expect(rows[1].editorData).toEqual({ v: 1 });
|
||||
expect(rows[1].savedAt).toEqual(base);
|
||||
});
|
||||
});
|
||||
|
||||
describe('getDocumentHistoryItem', () => {
|
||||
it('should resolve head as current document state', async () => {
|
||||
const editorData = createValidEditorData('Head content');
|
||||
|
||||
@@ -4,6 +4,7 @@ import { documentHistories, documents } from '@lobechat/database/schemas';
|
||||
import { and, desc, eq, gte, inArray, lt, or } from 'drizzle-orm';
|
||||
|
||||
import {
|
||||
DOCUMENT_HISTORY_AUTOSAVE_WINDOW_MS,
|
||||
DOCUMENT_HISTORY_QUERY_LIST_LIMIT,
|
||||
DOCUMENT_HISTORY_SOURCE_LIMITS,
|
||||
} from '@/const/documentHistory';
|
||||
@@ -46,6 +47,7 @@ export class DocumentHistoryService {
|
||||
buildWorkspaceWhere({ userId: this.userId, workspaceId: this.workspaceId }, documentHistories);
|
||||
|
||||
createHistory = async (params: {
|
||||
breakAutosaveWindow?: boolean;
|
||||
documentId: string;
|
||||
editorData: Record<string, any>;
|
||||
saveSource: DocumentHistorySaveSource;
|
||||
@@ -61,6 +63,32 @@ export class DocumentHistoryService {
|
||||
throw new Error('Document not found');
|
||||
}
|
||||
|
||||
// Autosave versions coalesce into fixed 10-min windows (Notion-like),
|
||||
// bucketed on the clock grid so the anchor stays immutable even though the
|
||||
// overwritten row's savedAt keeps moving — a sliding anchor would collapse
|
||||
// an entire continuous editing session into a single version.
|
||||
// Any non-autosave version in between closes the window.
|
||||
if (params.saveSource === 'autosave' && !params.breakAutosaveWindow) {
|
||||
const latest = await this.db.query.documentHistories.findFirst({
|
||||
orderBy: [desc(documentHistories.savedAt), desc(documentHistories.id)],
|
||||
where: and(eq(documentHistories.documentId, params.documentId), this.historiesOwnership()),
|
||||
});
|
||||
|
||||
const withinWindow =
|
||||
latest?.saveSource === 'autosave' &&
|
||||
Math.floor(latest.savedAt.getTime() / DOCUMENT_HISTORY_AUTOSAVE_WINDOW_MS) ===
|
||||
Math.floor(params.savedAt.getTime() / DOCUMENT_HISTORY_AUTOSAVE_WINDOW_MS);
|
||||
|
||||
if (withinWindow) {
|
||||
await this.db
|
||||
.update(documentHistories)
|
||||
.set({ editorData: params.editorData, savedAt: params.savedAt })
|
||||
.where(and(eq(documentHistories.id, latest.id), this.historiesOwnership()));
|
||||
|
||||
return;
|
||||
}
|
||||
}
|
||||
|
||||
await this.db.insert(documentHistories).values({
|
||||
documentId: params.documentId,
|
||||
editorData: params.editorData,
|
||||
@@ -185,6 +213,7 @@ export class DocumentHistoryService {
|
||||
isCurrent: true,
|
||||
saveSource: 'system',
|
||||
savedAt: headDocument.updatedAt,
|
||||
userId: headDocument.userId,
|
||||
});
|
||||
}
|
||||
|
||||
@@ -193,6 +222,7 @@ export class DocumentHistoryService {
|
||||
isCurrent: false,
|
||||
saveSource: row.saveSource as DocumentHistorySaveSource,
|
||||
savedAt: row.savedAt,
|
||||
userId: row.userId,
|
||||
}));
|
||||
|
||||
// If head consumed a slot and we fetched a full page of history rows,
|
||||
|
||||
@@ -395,6 +395,7 @@ export class DocumentService {
|
||||
if (historyAppended) {
|
||||
savedAt = new Date();
|
||||
await documentHistoryService.createHistory({
|
||||
breakAutosaveWindow: params.breakAutosaveWindow,
|
||||
documentId: id,
|
||||
editorData: currentEditorDataAccepted,
|
||||
saveSource: params.saveSource ?? 'autosave',
|
||||
|
||||
@@ -22,6 +22,7 @@ export interface DocumentHistoryListItem {
|
||||
isCurrent: boolean;
|
||||
savedAt: Date;
|
||||
saveSource: DocumentHistorySaveSource;
|
||||
userId: string;
|
||||
}
|
||||
|
||||
export interface DocumentHistoryItemResult {
|
||||
@@ -54,6 +55,7 @@ export interface ListDocumentHistoryResult {
|
||||
export type DatabaseLike = LobeChatDatabase | Transaction;
|
||||
|
||||
export interface UpdateDocumentParams {
|
||||
breakAutosaveWindow?: boolean;
|
||||
content?: string;
|
||||
editorData?: Record<string, any>;
|
||||
fileType?: string;
|
||||
|
||||
@@ -47,6 +47,10 @@ export interface SandboxRunParams {
|
||||
userId: string;
|
||||
}
|
||||
|
||||
export interface SandboxRunResult {
|
||||
commandId?: string;
|
||||
}
|
||||
|
||||
/**
|
||||
* Derive the local directory name from a repo identifier.
|
||||
* Accepts "owner/repo", "https://github.com/owner/repo", or "https://github.com/owner/repo.git".
|
||||
@@ -121,7 +125,7 @@ function buildRepoSetupScript(repos: string[], githubToken?: string): string | n
|
||||
* Fire-and-forget: the caller does NOT await this — the sandbox pushes events
|
||||
* back to the server via `heteroIngest` tRPC batches independently.
|
||||
*/
|
||||
export async function spawnHeteroSandbox(params: SandboxRunParams): Promise<void> {
|
||||
export async function spawnHeteroSandbox(params: SandboxRunParams): Promise<SandboxRunResult> {
|
||||
const {
|
||||
agentType,
|
||||
assistantMessageId,
|
||||
@@ -215,4 +219,16 @@ export async function spawnHeteroSandbox(params: SandboxRunParams): Promise<void
|
||||
if (!result.success) {
|
||||
throw new Error(result.error?.message || 'Failed to spawn heterogeneous sandbox');
|
||||
}
|
||||
|
||||
const resultData = result.result;
|
||||
const commandId =
|
||||
resultData && typeof resultData === 'object'
|
||||
? String(
|
||||
(resultData as Record<string, unknown>).commandId ||
|
||||
(resultData as Record<string, unknown>).shell_id ||
|
||||
'',
|
||||
) || undefined
|
||||
: undefined;
|
||||
|
||||
return { commandId };
|
||||
}
|
||||
|
||||
@@ -64,6 +64,7 @@ describe('localSystemRuntime', () => {
|
||||
it('should call deviceGateway.executeToolCall with correct arguments when a proxy function is invoked', async () => {
|
||||
const context: ToolExecutionContext = {
|
||||
activeDeviceId: 'device-1',
|
||||
operationId: 'op-1',
|
||||
toolManifestMap: {},
|
||||
userId: 'user-1',
|
||||
};
|
||||
@@ -78,7 +79,7 @@ describe('localSystemRuntime', () => {
|
||||
const result = await proxy[apiName](args);
|
||||
|
||||
expect(mockExecuteToolCall).toHaveBeenCalledWith(
|
||||
{ deviceId: 'device-1', userId: 'user-1' },
|
||||
{ deviceId: 'device-1', operationId: 'op-1', userId: 'user-1' },
|
||||
{
|
||||
apiName,
|
||||
arguments: JSON.stringify(args),
|
||||
|
||||
@@ -43,9 +43,9 @@ export const agentManagementRuntime: ServerRuntimeRegistration = {
|
||||
): Promise<ToolExecutionResult> => {
|
||||
const { agentId, instruction, taskTitle, timeout } = params;
|
||||
|
||||
// Server runtime always uses the task path because there is no
|
||||
// client-side `registerAfterCompletion` callback available to execute
|
||||
// synchronous agent calls.
|
||||
// Server runtime always uses the legacy async invocation path because
|
||||
// there is no client-side `registerAfterCompletion` callback available
|
||||
// to execute synchronous agent calls.
|
||||
return {
|
||||
content: `🚀 Triggered async task to call agent "${agentId}"${taskTitle ? `: ${taskTitle}` : ''}`,
|
||||
state: {
|
||||
|
||||
@@ -10,6 +10,7 @@ interface LobeDeliveryCheckerRuntimeContext {
|
||||
operationId?: string;
|
||||
serverDB: LobeChatDatabase;
|
||||
userId: string;
|
||||
workspaceId?: string;
|
||||
}
|
||||
|
||||
const buildError = (content: string, code: string): BuiltinServerRuntimeOutput => ({
|
||||
@@ -28,11 +29,13 @@ class LobeDeliveryCheckerExecutionRuntime {
|
||||
private operationId?: string;
|
||||
private db: LobeChatDatabase;
|
||||
private userId: string;
|
||||
private workspaceId?: string;
|
||||
|
||||
constructor(context: LobeDeliveryCheckerRuntimeContext) {
|
||||
this.operationId = context.operationId;
|
||||
this.db = context.serverDB;
|
||||
this.userId = context.userId;
|
||||
this.workspaceId = context.workspaceId;
|
||||
}
|
||||
|
||||
generateVerifyPlan = async (params: {
|
||||
@@ -64,7 +67,7 @@ class LobeDeliveryCheckerExecutionRuntime {
|
||||
// criteria + a rubric, snapshot it onto this operation, and confirm it. The
|
||||
// tool call is human-reviewed (humanIntervention); this runs post-approval.
|
||||
const { VerifyPlanGeneratorService } = await import('@/server/services/verify');
|
||||
const planGenerator = new VerifyPlanGeneratorService(this.db, this.userId);
|
||||
const planGenerator = new VerifyPlanGeneratorService(this.db, this.userId, this.workspaceId);
|
||||
const { items, rubricId } = await planGenerator.createPlanFromCriteria({
|
||||
criteria,
|
||||
operationId: this.operationId,
|
||||
@@ -110,6 +113,7 @@ export const lobeDeliveryCheckerRuntime: ServerRuntimeRegistration = {
|
||||
operationId: context.operationId,
|
||||
serverDB: context.serverDB,
|
||||
userId: context.userId,
|
||||
workspaceId: context.workspaceId,
|
||||
});
|
||||
},
|
||||
identifier: LobeDeliveryCheckerIdentifier,
|
||||
|
||||
@@ -18,7 +18,11 @@ export const localSystemRuntime: ServerRuntimeRegistration = {
|
||||
for (const api of LocalSystemManifest.api) {
|
||||
proxy[api.name] = async (args: any) => {
|
||||
return deviceGateway.executeToolCall(
|
||||
{ deviceId: context.activeDeviceId!, userId: context.userId! },
|
||||
{
|
||||
deviceId: context.activeDeviceId!,
|
||||
operationId: context.operationId,
|
||||
userId: context.userId!,
|
||||
},
|
||||
{
|
||||
apiName: api.name,
|
||||
arguments: JSON.stringify(args),
|
||||
|
||||
@@ -1,7 +1,7 @@
|
||||
import { builtinSkills } from '@lobechat/builtin-skills';
|
||||
import { LocalSystemApiName, LocalSystemIdentifier } from '@lobechat/builtin-tool-local-system';
|
||||
// Note: only `readFile` is wired through deviceGateway. Directory enumeration is
|
||||
// left to the model via `local-system.listFiles` so we don't double-fetch.
|
||||
// left to the model via `local-system.globFiles` so we don't double-fetch.
|
||||
import {
|
||||
type CommandResult,
|
||||
type ExecScriptActivatedSkill,
|
||||
|
||||
@@ -15,6 +15,7 @@ interface VerifyResultRuntimeContext {
|
||||
operationId?: string;
|
||||
serverDB: LobeChatDatabase;
|
||||
userId: string;
|
||||
workspaceId?: string;
|
||||
}
|
||||
|
||||
/**
|
||||
@@ -27,11 +28,13 @@ class VerifyResultExecutionRuntime {
|
||||
private operationId?: string;
|
||||
private db: LobeChatDatabase;
|
||||
private userId: string;
|
||||
private workspaceId?: string;
|
||||
|
||||
constructor(context: VerifyResultRuntimeContext) {
|
||||
this.operationId = context.operationId;
|
||||
this.db = context.serverDB;
|
||||
this.userId = context.userId;
|
||||
this.workspaceId = context.workspaceId;
|
||||
}
|
||||
|
||||
submitVerifyResult = async (params: SubmitVerifyResultParams) => {
|
||||
@@ -47,11 +50,13 @@ class VerifyResultExecutionRuntime {
|
||||
}
|
||||
|
||||
// The verifier runs as a sub-agent; the row to update belongs to the parent run.
|
||||
const op = await new AgentOperationModel(this.db, this.userId).findById(this.operationId);
|
||||
const op = await new AgentOperationModel(this.db, this.userId, this.workspaceId).findById(
|
||||
this.operationId,
|
||||
);
|
||||
const targetOperationId = op?.parentOperationId ?? this.operationId;
|
||||
|
||||
const status = params.verdict === 'passed' ? 'passed' : 'failed';
|
||||
await new VerifyCheckResultModel(this.db, this.userId).updateByCheckItem(
|
||||
await new VerifyCheckResultModel(this.db, this.userId, this.workspaceId).updateByCheckItem(
|
||||
targetOperationId,
|
||||
params.checkItemId,
|
||||
{
|
||||
@@ -66,10 +71,12 @@ class VerifyResultExecutionRuntime {
|
||||
verdict: params.verdict,
|
||||
},
|
||||
);
|
||||
await new VerifyStatusService(this.db, this.userId).recompute(targetOperationId);
|
||||
await new VerifyStatusService(this.db, this.userId, this.workspaceId).recompute(
|
||||
targetOperationId,
|
||||
);
|
||||
// This may be the last check to resolve — kick auto-repair if the run failed
|
||||
// with auto_repair checks (no-op until everything has a terminal result).
|
||||
await maybeAutoRepair(this.db, this.userId, targetOperationId);
|
||||
await maybeAutoRepair(this.db, this.userId, targetOperationId, this.workspaceId);
|
||||
|
||||
log(
|
||||
'submitted verdict %s for check %s (op %s)',
|
||||
@@ -94,6 +101,7 @@ export const verifyResultRuntime: ServerRuntimeRegistration = {
|
||||
operationId: context.operationId,
|
||||
serverDB: context.serverDB,
|
||||
userId: context.userId,
|
||||
workspaceId: context.workspaceId,
|
||||
});
|
||||
},
|
||||
identifier: VerifyToolIdentifier,
|
||||
|
||||
@@ -61,9 +61,9 @@ export interface ToolExecutionContext {
|
||||
/** Current page document ID for page-scoped conversations */
|
||||
documentId?: string | null;
|
||||
/**
|
||||
* Spawn a sub-agent as an independent async operation. Injected by the agent
|
||||
* runtime (forwarded from `RuntimeExecutorContext.execSubAgent`) so the
|
||||
* `callSubAgent` server tool can fork a child op without a circular import.
|
||||
* Legacy agent invocation callback forwarded from RuntimeExecutorContext.
|
||||
* Kept for tool runtimes that still dispatch through exec_sub_agent style
|
||||
* flows; `lobe-agent.callSubAgent` uses the per-call `subAgent` runner below.
|
||||
*/
|
||||
execSubAgent?: (params: ExecSubAgentParams) => Promise<unknown>;
|
||||
/** Per-call execution timeout resolved by the agent runtime. */
|
||||
|
||||
@@ -52,18 +52,20 @@ export const createVerifierAgentRunner = (params: {
|
||||
provider?: string | null;
|
||||
topicId?: string | null;
|
||||
userId: string;
|
||||
workspaceId?: string;
|
||||
}): VerifierAgentRunner | undefined => {
|
||||
const { db, deliverable, model, provider, topicId, userId } = params;
|
||||
const { db, deliverable, model, provider, topicId, userId, workspaceId } = params;
|
||||
if (!topicId) return undefined;
|
||||
|
||||
return async ({ checkItem, goal, operationId }) => {
|
||||
// The detailed instruction is the criterion's rule body, stored in a document.
|
||||
const instruction = checkItem.documentId
|
||||
? ((await new DocumentModel(db, userId).findById(checkItem.documentId))?.content ?? undefined)
|
||||
? ((await new DocumentModel(db, userId, workspaceId).findById(checkItem.documentId))
|
||||
?.content ?? undefined)
|
||||
: undefined;
|
||||
|
||||
// Materialize the builtin verify agent (idempotent) to get an id for the thread.
|
||||
const verifyAgent = await new AgentModel(db, userId).getBuiltinAgent(
|
||||
const verifyAgent = await new AgentModel(db, userId, workspaceId).getBuiltinAgent(
|
||||
BUILTIN_AGENT_SLUGS.verifyAgent,
|
||||
);
|
||||
if (!verifyAgent) {
|
||||
@@ -71,7 +73,7 @@ export const createVerifierAgentRunner = (params: {
|
||||
return null;
|
||||
}
|
||||
|
||||
const thread = await new ThreadModel(db, userId).create({
|
||||
const thread = await new ThreadModel(db, userId, workspaceId).create({
|
||||
agentId: verifyAgent.id,
|
||||
title: `Verify: ${checkItem.title}`,
|
||||
topicId,
|
||||
@@ -85,7 +87,7 @@ export const createVerifierAgentRunner = (params: {
|
||||
// Dynamic import breaks the static cycle: aiAgent → agentRuntime completion
|
||||
// → verify lifecycle → this runner → aiAgent.
|
||||
const { AiAgentService } = await import('@/server/services/aiAgent');
|
||||
const result = await new AiAgentService(db, userId).execAgent({
|
||||
const result = await new AiAgentService(db, userId, { workspaceId }).execAgent({
|
||||
appContext: { threadId: thread.id, topicId },
|
||||
autoStart: true,
|
||||
// Inherit the parent run's model/provider so the verifier uses a provider
|
||||
|
||||
@@ -80,13 +80,13 @@ export class VerifyExecutorService {
|
||||
private readonly statusService: VerifyStatusService;
|
||||
private readonly documentModel: DocumentModel;
|
||||
|
||||
constructor(db: LobeChatDatabase, userId: string) {
|
||||
constructor(db: LobeChatDatabase, userId: string, workspaceId?: string) {
|
||||
this.db = db;
|
||||
this.userId = userId;
|
||||
this.operationModel = new AgentOperationModel(db, userId);
|
||||
this.resultModel = new VerifyCheckResultModel(db, userId);
|
||||
this.statusService = new VerifyStatusService(db, userId);
|
||||
this.documentModel = new DocumentModel(db, userId);
|
||||
this.operationModel = new AgentOperationModel(db, userId, workspaceId);
|
||||
this.resultModel = new VerifyCheckResultModel(db, userId, workspaceId);
|
||||
this.statusService = new VerifyStatusService(db, userId, workspaceId);
|
||||
this.documentModel = new DocumentModel(db, userId, workspaceId);
|
||||
}
|
||||
|
||||
/**
|
||||
|
||||
@@ -23,8 +23,8 @@ export const computeFalseFlags = (
|
||||
export class VerifyFeedbackService {
|
||||
private readonly resultModel: VerifyCheckResultModel;
|
||||
|
||||
constructor(db: LobeChatDatabase, userId: string) {
|
||||
this.resultModel = new VerifyCheckResultModel(db, userId);
|
||||
constructor(db: LobeChatDatabase, userId: string, workspaceId?: string) {
|
||||
this.resultModel = new VerifyCheckResultModel(db, userId, workspaceId);
|
||||
}
|
||||
|
||||
/** Record a user's decision on a result and precompute its FP/FN flags. */
|
||||
|
||||
@@ -33,9 +33,10 @@ export const runVerifyOnCompletion = async (
|
||||
db: LobeChatDatabase,
|
||||
userId: string,
|
||||
params: RunVerifyOnCompletionParams,
|
||||
workspaceId?: string,
|
||||
): Promise<void> => {
|
||||
try {
|
||||
const operationModel = new AgentOperationModel(db, userId);
|
||||
const operationModel = new AgentOperationModel(db, userId, workspaceId);
|
||||
const state = await operationModel.getVerifyState(params.operationId);
|
||||
|
||||
// Opt-in gate: only runs with a confirmed plan that hasn't been verified yet.
|
||||
@@ -48,7 +49,7 @@ export const runVerifyOnCompletion = async (
|
||||
return;
|
||||
}
|
||||
|
||||
const executor = new VerifyExecutorService(db, userId);
|
||||
const executor = new VerifyExecutorService(db, userId, workspaceId);
|
||||
await executor.execute({
|
||||
deliverable: params.deliverable,
|
||||
goal: params.goal,
|
||||
@@ -63,13 +64,14 @@ export const runVerifyOnCompletion = async (
|
||||
provider: op.provider,
|
||||
topicId: op.topicId,
|
||||
userId,
|
||||
workspaceId,
|
||||
}),
|
||||
});
|
||||
|
||||
// Auto-repair once verification has fully resolved. For runs with only inline
|
||||
// (LLM/program) checks, everything is resolved now; runs with async agent
|
||||
// checks no-op here and re-trigger from the verifier's writeback path.
|
||||
await maybeAutoRepair(db, userId, params.operationId);
|
||||
await maybeAutoRepair(db, userId, params.operationId, workspaceId);
|
||||
} catch (error) {
|
||||
log('runVerifyOnCompletion failed for op %s (non-fatal): %O', params.operationId, error);
|
||||
}
|
||||
|
||||
@@ -75,13 +75,13 @@ export class VerifyPlanGeneratorService {
|
||||
private readonly operationModel: AgentOperationModel;
|
||||
private readonly documentModel: DocumentModel;
|
||||
|
||||
constructor(db: LobeChatDatabase, userId: string) {
|
||||
constructor(db: LobeChatDatabase, userId: string, workspaceId?: string) {
|
||||
this.db = db;
|
||||
this.userId = userId;
|
||||
this.criterionModel = new VerifyCriterionModel(db, userId);
|
||||
this.rubricModel = new VerifyRubricModel(db, userId);
|
||||
this.operationModel = new AgentOperationModel(db, userId);
|
||||
this.documentModel = new DocumentModel(db, userId);
|
||||
this.criterionModel = new VerifyCriterionModel(db, userId, workspaceId);
|
||||
this.rubricModel = new VerifyRubricModel(db, userId, workspaceId);
|
||||
this.operationModel = new AgentOperationModel(db, userId, workspaceId);
|
||||
this.documentModel = new DocumentModel(db, userId, workspaceId);
|
||||
}
|
||||
|
||||
/**
|
||||
|
||||
@@ -22,11 +22,12 @@ const resolveMaxRepairRounds = async (
|
||||
db: LobeChatDatabase,
|
||||
userId: string,
|
||||
plan: VerifyCheckItem[],
|
||||
workspaceId?: string,
|
||||
): Promise<number> => {
|
||||
const rubricId = plan.find((i) => i.sourceRubricId)?.sourceRubricId;
|
||||
if (!rubricId) return DEFAULT_MAX_REPAIR_ROUNDS;
|
||||
|
||||
const rubric = await new VerifyRubricModel(db, userId).findById(rubricId);
|
||||
const rubric = await new VerifyRubricModel(db, userId, workspaceId).findById(rubricId);
|
||||
return rubric?.config?.maxRepairRounds ?? DEFAULT_MAX_REPAIR_ROUNDS;
|
||||
};
|
||||
|
||||
@@ -79,12 +80,13 @@ export const createRepairRunner = (params: {
|
||||
provider?: string | null;
|
||||
topicId?: string | null;
|
||||
userId: string;
|
||||
workspaceId?: string;
|
||||
}): RepairSpawner | undefined => {
|
||||
const { agentId, db, maxRepairRounds, model, provider, topicId, userId } = params;
|
||||
const { agentId, db, maxRepairRounds, model, provider, topicId, userId, workspaceId } = params;
|
||||
if (!agentId || !topicId) return undefined;
|
||||
|
||||
return async ({ instruction, operationId, verifyMessageId }) => {
|
||||
const operationModel = new AgentOperationModel(db, userId);
|
||||
const operationModel = new AgentOperationModel(db, userId, workspaceId);
|
||||
|
||||
const round = await countRepairRounds(operationModel, operationId);
|
||||
if (round >= maxRepairRounds) {
|
||||
@@ -98,7 +100,7 @@ export const createRepairRunner = (params: {
|
||||
// for the operation title / logs. `verifyMessageId` parents the new turn under
|
||||
// the verify card it responds to.
|
||||
const { AiAgentService } = await import('@/server/services/aiAgent');
|
||||
const result = await new AiAgentService(db, userId).execAgent({
|
||||
const result = await new AiAgentService(db, userId, { workspaceId }).execAgent({
|
||||
agentId,
|
||||
appContext: { topicId },
|
||||
autoStart: true,
|
||||
@@ -138,13 +140,16 @@ export const maybeAutoRepair = async (
|
||||
db: LobeChatDatabase,
|
||||
userId: string,
|
||||
operationId: string,
|
||||
workspaceId?: string,
|
||||
): Promise<void> => {
|
||||
const operationModel = new AgentOperationModel(db, userId);
|
||||
const operationModel = new AgentOperationModel(db, userId, workspaceId);
|
||||
const state = await operationModel.getVerifyState(operationId);
|
||||
const plan = (state?.verifyPlan ?? []) as VerifyCheckItem[];
|
||||
if (plan.length === 0) return;
|
||||
|
||||
const results = await new VerifyCheckResultModel(db, userId).listByOperation(operationId);
|
||||
const results = await new VerifyCheckResultModel(db, userId, workspaceId).listByOperation(
|
||||
operationId,
|
||||
);
|
||||
const byItem = new Map(results.map((r) => [r.checkItemId, r]));
|
||||
|
||||
// Wait until every required check has a terminal result (don't repair early).
|
||||
@@ -160,13 +165,14 @@ export const maybeAutoRepair = async (
|
||||
const spawner = createRepairRunner({
|
||||
agentId: op?.agentId,
|
||||
db,
|
||||
maxRepairRounds: await resolveMaxRepairRounds(db, userId, plan),
|
||||
maxRepairRounds: await resolveMaxRepairRounds(db, userId, plan, workspaceId),
|
||||
model: op?.model,
|
||||
provider: op?.provider,
|
||||
topicId: op?.topicId,
|
||||
userId,
|
||||
workspaceId,
|
||||
});
|
||||
await new VerifyRepairService(db, userId).triggerAutoRepair(operationId, spawner);
|
||||
await new VerifyRepairService(db, userId, workspaceId).triggerAutoRepair(operationId, spawner);
|
||||
};
|
||||
|
||||
const isFailed = (r: VerifyCheckResultItem | undefined): boolean =>
|
||||
@@ -191,11 +197,11 @@ export class VerifyRepairService {
|
||||
private readonly resultModel: VerifyCheckResultModel;
|
||||
private readonly statusService: VerifyStatusService;
|
||||
|
||||
constructor(db: LobeChatDatabase, userId: string) {
|
||||
this.messageModel = new MessageModel(db, userId);
|
||||
this.operationModel = new AgentOperationModel(db, userId);
|
||||
this.resultModel = new VerifyCheckResultModel(db, userId);
|
||||
this.statusService = new VerifyStatusService(db, userId);
|
||||
constructor(db: LobeChatDatabase, userId: string, workspaceId?: string) {
|
||||
this.messageModel = new MessageModel(db, userId, workspaceId);
|
||||
this.operationModel = new AgentOperationModel(db, userId, workspaceId);
|
||||
this.resultModel = new VerifyCheckResultModel(db, userId, workspaceId);
|
||||
this.statusService = new VerifyStatusService(db, userId, workspaceId);
|
||||
}
|
||||
|
||||
/** Collect the auto-repairable failures for a run. */
|
||||
|
||||
@@ -17,9 +17,9 @@ export class VerifyStatusService {
|
||||
private readonly operationModel: AgentOperationModel;
|
||||
private readonly resultModel: VerifyCheckResultModel;
|
||||
|
||||
constructor(db: LobeChatDatabase, userId: string) {
|
||||
this.operationModel = new AgentOperationModel(db, userId);
|
||||
this.resultModel = new VerifyCheckResultModel(db, userId);
|
||||
constructor(db: LobeChatDatabase, userId: string, workspaceId?: string) {
|
||||
this.operationModel = new AgentOperationModel(db, userId, workspaceId);
|
||||
this.resultModel = new VerifyCheckResultModel(db, userId, workspaceId);
|
||||
}
|
||||
|
||||
/**
|
||||
|
||||
@@ -0,0 +1,95 @@
|
||||
<!doctype html>
|
||||
<html>
|
||||
<head>
|
||||
<meta charset="utf-8" />
|
||||
<meta name="viewport" content="width=device-width, initial-scale=1" />
|
||||
<link rel="icon" href="/favicon.ico" />
|
||||
<link rel="shortcut icon" href="/favicon-32x32.ico" />
|
||||
<!--SEO_META-->
|
||||
<style>
|
||||
html body {
|
||||
background: #f8f8f8;
|
||||
}
|
||||
html[data-theme='dark'] body {
|
||||
background-color: #000;
|
||||
}
|
||||
</style>
|
||||
<script>
|
||||
(function () {
|
||||
function supportsImportMaps() {
|
||||
return (
|
||||
typeof HTMLScriptElement !== 'undefined' &&
|
||||
typeof HTMLScriptElement.supports === 'function' &&
|
||||
HTMLScriptElement.supports('importmap')
|
||||
);
|
||||
}
|
||||
|
||||
function supportsCascadeLayers() {
|
||||
var el = document.createElement('div');
|
||||
el.className = '__layer_test__';
|
||||
el.style.position = 'absolute';
|
||||
el.style.left = '-99999px';
|
||||
el.style.top = '-99999px';
|
||||
|
||||
var style = document.createElement('style');
|
||||
style.textContent =
|
||||
'@layer a, b;' +
|
||||
'@layer a { .__layer_test__ { color: rgb(1, 2, 3); } }' +
|
||||
'@layer b { .__layer_test__ { color: rgb(4, 5, 6); } }';
|
||||
|
||||
document.documentElement.append(style);
|
||||
document.documentElement.append(el);
|
||||
|
||||
var color = getComputedStyle(el).color;
|
||||
|
||||
el.remove();
|
||||
style.remove();
|
||||
|
||||
return color === 'rgb(4, 5, 6)';
|
||||
}
|
||||
|
||||
if (!(supportsImportMaps() && supportsCascadeLayers())) {
|
||||
window.location.href = '/not-compatible.html';
|
||||
return;
|
||||
}
|
||||
|
||||
var theme = 'system';
|
||||
try {
|
||||
theme = localStorage.getItem('theme') || 'system';
|
||||
} catch (_) {}
|
||||
var systemTheme =
|
||||
window.matchMedia && window.matchMedia('(prefers-color-scheme: dark)').matches
|
||||
? 'dark'
|
||||
: 'light';
|
||||
var resolvedTheme = theme === 'system' ? systemTheme : theme;
|
||||
if (resolvedTheme === 'dark' || resolvedTheme === 'light') {
|
||||
document.documentElement.setAttribute('data-theme', resolvedTheme);
|
||||
}
|
||||
|
||||
var hl = new URLSearchParams(location.search).get('hl');
|
||||
var m = document.cookie.match(/(?:^|;\s*)LOBE_LOCALE=([^;]*)/);
|
||||
var cookie = m ? decodeURIComponent(m[1]) : '';
|
||||
var locale = hl || cookie || navigator.language || 'en-US';
|
||||
if (locale === 'auto') locale = navigator.language || 'en-US';
|
||||
if (hl && !cookie) {
|
||||
document.cookie =
|
||||
'LOBE_LOCALE=' + encodeURIComponent(hl) + ';path=/;max-age=7776000;SameSite=Lax';
|
||||
}
|
||||
document.documentElement.lang = locale;
|
||||
var rtl = ['ar', 'arc', 'dv', 'fa', 'ha', 'he', 'khw', 'ks', 'ku', 'ps', 'ur', 'yi'];
|
||||
document.documentElement.dir =
|
||||
rtl.indexOf(locale.split('-')[0].toLowerCase()) >= 0 ? 'rtl' : 'ltr';
|
||||
})();
|
||||
</script>
|
||||
<script>
|
||||
window.__SERVER_CONFIG__ = undefined; /* SERVER_CONFIG */
|
||||
</script>
|
||||
</head>
|
||||
|
||||
<body>
|
||||
<div id="root" style="height: 100%"></div>
|
||||
|
||||
<!--ANALYTICS_SCRIPTS-->
|
||||
<script type="module" src="/src/spa/entry.auth.tsx"></script>
|
||||
</body>
|
||||
</html>
|
||||
@@ -15,6 +15,8 @@
|
||||
"agentBuilder.installPlugin.retry": "إعادة المحاولة",
|
||||
"agentBuilder.title": "منشئ الوكلاء",
|
||||
"agentBuilder.welcome": "أخبرني بحالتك.\n\nكتابة، برمجة، أو تحليل بيانات — أي شيء يناسبك. أنت تملك الهدف والمعايير؛ سأقوم بتقسيمها إلى وكلاء تعاونيين قابلين للتنفيذ.",
|
||||
"agentConfigError.retry": "إعادة المحاولة",
|
||||
"agentConfigError.title": "فشل في تحميل إعدادات الوكيل",
|
||||
"agentDefaultMessage": "مرحبًا، أنا **{{name}}**. جملة واحدة تكفي.\n\nهل ترغب في أن أتناسب مع سير عملك بشكل أفضل؟ انتقل إلى [إعدادات الوكيل]({{url}}) واملأ ملف تعريف الوكيل (يمكنك تعديله في أي وقت).",
|
||||
"agentDefaultMessageWithSystemRole": "مرحبًا، أنا **{{name}}**. جملة واحدة تكفي — أنت المتحكم.",
|
||||
"agentDefaultMessageWithoutEdit": "مرحبًا، أنا **{{name}}**. جملة واحدة تكفي — أنت المتحكم.",
|
||||
@@ -252,6 +254,10 @@
|
||||
"input.costEstimate.tooltip": "تم التقدير بناءً على السياق الحالي، الأدوات، وتسعير النموذج. قد تختلف التكلفة الفعلية.",
|
||||
"input.disclaimer": "قد يخطئ الوكلاء. استخدم حكمك الخاص للمعلومات الحساسة.",
|
||||
"input.errorMsg": "فشل الإرسال: {{errorMsg}}. أعد المحاولة أو أرسل لاحقًا.",
|
||||
"input.inputCompletionError.desc": "توقفت اقتراحات الإدخال بعد حدوث خطأ. حاول مرة أخرى، أو قم بتعديل نموذج الاقتراح في الإعدادات.",
|
||||
"input.inputCompletionError.retry": "إعادة المحاولة",
|
||||
"input.inputCompletionError.settings": "الإعدادات",
|
||||
"input.inputCompletionError.title": "توقفت اقتراحات الإدخال",
|
||||
"input.more": "المزيد",
|
||||
"input.send": "إرسال",
|
||||
"input.sendWithCmdEnter": "اضغط <key/> للإرسال",
|
||||
@@ -915,6 +921,7 @@
|
||||
"workflow.toolDisplayName.addPreferenceMemory": "الذاكرة المحفوظة",
|
||||
"workflow.toolDisplayName.calculate": "محسوب",
|
||||
"workflow.toolDisplayName.callAgent": "تم استدعاء وكيل",
|
||||
"workflow.toolDisplayName.callMcpTool": "تم استدعاء أداة MCP",
|
||||
"workflow.toolDisplayName.callSubAgent": "تم إرسال وكيل فرعي",
|
||||
"workflow.toolDisplayName.clearTodos": "تم مسح المهام",
|
||||
"workflow.toolDisplayName.copyDocument": "تم نسخ مستند",
|
||||
@@ -1005,7 +1012,9 @@
|
||||
"workingPanel.localFile.closeRight": "إغلاق إلى اليمين",
|
||||
"workingPanel.localFile.error": "تعذر تحميل هذا الملف",
|
||||
"workingPanel.localFile.preview.raw": "خام",
|
||||
"workingPanel.localFile.preview.reload": "إعادة تحميل المعاينة",
|
||||
"workingPanel.localFile.preview.render": "معاينة",
|
||||
"workingPanel.localFile.preview.source": "المصدر",
|
||||
"workingPanel.localFile.truncated": "تم تقليص معاينة الملف إلى {{limit}} حرفًا",
|
||||
"workingPanel.progress": "Progress",
|
||||
"workingPanel.progress.allCompleted": "All tasks completed",
|
||||
|
||||
@@ -239,6 +239,7 @@
|
||||
"providerModels.item.modelConfig.extendParams.options.reasoningBudgetToken32k.hint": "لـ GLM-5 و GLM-4.7؛ يتحكم في ميزانية الرموز للتفكير (الحد الأقصى 32k).",
|
||||
"providerModels.item.modelConfig.extendParams.options.reasoningBudgetToken80k.hint": "لسلسلة Qwen3؛ يتحكم في ميزانية الرموز للتفكير (الحد الأقصى 80k).",
|
||||
"providerModels.item.modelConfig.extendParams.options.reasoningEffort.hint": "لنماذج OpenAI وغيرها من النماذج القادرة على الاستدلال؛ يتحكم في جهد الاستدلال.",
|
||||
"providerModels.item.modelConfig.extendParams.options.ring2_6ReasoningEffort.hint": "لسلسلة Ring 2.6؛ يتحكم في شدة التفكير.",
|
||||
"providerModels.item.modelConfig.extendParams.options.step3_5ReasoningEffort.hint": "بالنسبة لسلسلة Step 3.5؛ يتحكم في شدة التفكير.",
|
||||
"providerModels.item.modelConfig.extendParams.options.textVerbosity.hint": "لسلسلة GPT-5+؛ يتحكم في تفصيل النص الناتج.",
|
||||
"providerModels.item.modelConfig.extendParams.options.thinking.hint": "لبعض نماذج Doubao؛ يسمح للنموذج بتحديد ما إذا كان يجب التفكير بعمق.",
|
||||
|
||||
+12
-28
@@ -27,15 +27,15 @@
|
||||
"DeepSeek-OCR.description": "يعد DeepSeek-OCR نموذج رؤية-لغة من DeepSeek AI يركز على التعرف البصري على الحروف و\"الضغط السياقي البصري\". يستكشف ضغط السياق المستخرج من الصور، ويعالج المستندات بكفاءة، ويحوّلها إلى نص منظم (مثل Markdown). يقدّم دقة عالية في التعرف على النص داخل الصور، مما يجعله مناسباً لرقمنة المستندات واستخراج النصوص والمعالجة الهيكلية.",
|
||||
"DeepSeek-R1-Distill-Llama-70B.description": "تم تقطير DeepSeek R1، النموذج الأكبر والأذكى في مجموعة DeepSeek، إلى بنية Llama 70B. تُظهر المعايير والتقييمات البشرية أنه أذكى من Llama 70B الأساسي، خاصة في مهام الرياضيات ودقة الحقائق.",
|
||||
"DeepSeek-R1-Distill-Qwen-1.5B.description": "نموذج مقطر من DeepSeek-R1 يعتمد على Qwen2.5-Math-1.5B. يعمل التعلم المعزز وبيانات البداية الباردة على تحسين أداء الاستدلال، مما يضع معايير جديدة للمهام المتعددة في النماذج المفتوحة.",
|
||||
"DeepSeek-R1-Distill-Qwen-14B.description": "نماذج DeepSeek-R1-Distill مدربة بدقة من نماذج مفتوحة المصدر باستخدام بيانات عينة تم إنشاؤها بواسطة DeepSeek-R1.",
|
||||
"DeepSeek-R1-Distill-Qwen-32B.description": "نماذج DeepSeek-R1-Distill مدربة بدقة من نماذج مفتوحة المصدر باستخدام بيانات عينة تم إنشاؤها بواسطة DeepSeek-R1.",
|
||||
"DeepSeek-R1-Distill-Qwen-14B.description": "نموذج DeepSeek-R1 المقطر يعتمد على Qwen2.5-14B. يعزز التعلم المعزز وبيانات البداية الباردة أداء الاستدلال، مما يضع معايير جديدة للمهام المتعددة للنماذج المفتوحة.",
|
||||
"DeepSeek-R1-Distill-Qwen-32B.description": "سلسلة DeepSeek-R1 تحسن أداء الاستدلال باستخدام التعلم المعزز وبيانات البداية الباردة، مما يضع معايير جديدة للمهام المتعددة للنماذج المفتوحة ويتفوق على OpenAI o1-mini.",
|
||||
"DeepSeek-R1-Distill-Qwen-7B.description": "نموذج مقطر من DeepSeek-R1 يعتمد على Qwen2.5-Math-7B. يعمل التعلم المعزز وبيانات البداية الباردة على تحسين أداء الاستدلال، مما يضع معايير جديدة للمهام المتعددة في النماذج المفتوحة.",
|
||||
"DeepSeek-R1.description": "يطبق DeepSeek-R1 التعلم المعزز واسع النطاق في مرحلة ما بعد التدريب، مما يعزز قدرات الاستدلال بشكل كبير باستخدام القليل من البيانات الموسومة. يضاهي نموذج OpenAI o1 في مهام الرياضيات، البرمجة، والاستدلال اللغوي.",
|
||||
"DeepSeek-R1.description": "نموذج لغة كبير عالي الكفاءة وحديث، يتميز بالقوة في الاستدلال والرياضيات والبرمجة.",
|
||||
"DeepSeek-V3-1.description": "DeepSeek V3.1 هو نموذج استدلال من الجيل التالي يتميز بتحسينات في الاستدلال المعقد وسلسلة التفكير، مناسب لمهام التحليل العميق.",
|
||||
"DeepSeek-V3-Fast.description": "المزود: sophnet. DeepSeek V3 Fast هو الإصدار عالي السرعة من DeepSeek V3 0324، بدقة كاملة (غير مضغوطة) مع أداء أقوى في البرمجة والرياضيات واستجابات أسرع.",
|
||||
"DeepSeek-V3.1-Think.description": "وضع التفكير في DeepSeek-V3.1: نموذج استدلال هجين جديد يدعم أوضاع التفكير وغير التفكير، أكثر كفاءة من DeepSeek-R1-0528. التحسينات بعد التدريب تعزز بشكل كبير استخدام الأدوات وأداء المهام التي تتطلب وكلاء.",
|
||||
"DeepSeek-V3.2.description": "يقدم deepseek-v3.2 آلية انتباه متفرّق تهدف إلى تحسين كفاءة التدريب والاستدلال عند معالجة النصوص الطويلة، مع كلفة أقل مقارنة بـ deepseek-v3.1.",
|
||||
"DeepSeek-V3.description": "DeepSeek-V3 هو نموذج MoE تم تطويره بواسطة DeepSeek. يتفوق على نماذج مفتوحة أخرى مثل Qwen2.5-72B وLlama-3.1-405B في العديد من المعايير، ويتنافس مع النماذج المغلقة الرائدة مثل GPT-4o وClaude 3.5 Sonnet.",
|
||||
"DeepSeek-V3.description": "النشر المفتوح من ByteDance Volcengine هو الأكثر استقرارًا حاليًا؛ موصى به. تم ترقيته تلقائيًا إلى الإصدار الأحدث (250324).",
|
||||
"Doubao-lite-128k.description": "يوفر Doubao-lite استجابات فائقة السرعة وقيمة أفضل، مع خيارات مرنة عبر السيناريوهات. يدعم سياق 128K للاستدلال والتدريب الدقيق.",
|
||||
"Doubao-lite-32k.description": "يوفر Doubao-lite استجابات فائقة السرعة وقيمة أفضل، مع خيارات مرنة عبر السيناريوهات. يدعم سياق 32K للاستدلال والتدريب الدقيق.",
|
||||
"Doubao-lite-4k.description": "يوفر Doubao-lite استجابات فائقة السرعة وقيمة أفضل، مع خيارات مرنة عبر السيناريوهات. يدعم سياق 4K للاستدلال والتدريب الدقيق.",
|
||||
@@ -83,13 +83,12 @@
|
||||
"Kimi-K2.5.description": "Kimi K2.5 هو أقوى نموذج من سلسلة Kimi، ويقدم أداءً متقدماً مفتوح المصدر في مهام الوكلاء والبرمجة وفهم الرؤية. يدعم الإدخال متعدد الوسائط ووضعَي التفكير وغير التفكير.",
|
||||
"Kolors.description": "Kolors هو نموذج تحويل نص إلى صورة طوره فريق Kolors في Kuaishou. مدرب على مليارات المعاملات، يتميز بجودة بصرية عالية، فهم دلالي قوي للغة الصينية، وقدرات متميزة في عرض النصوص.",
|
||||
"Kwai-Kolors/Kolors.description": "Kolors هو نموذج تحويل نص إلى صورة واسع النطاق من فريق Kolors في Kuaishou. مدرب على مليارات أزواج النصوص والصور، يتفوق في الجودة البصرية، الدقة الدلالية المعقدة، وعرض النصوص الصينية/الإنجليزية، مع فهم وتوليد قويين للمحتوى الصيني.",
|
||||
"Ling-2.5-1T.description": "كنموذج رئيسي جديد في سلسلة Ling، يقدم Ling-2.5-1T ترقيات شاملة في بنية النموذج وكفاءة الرموز ومواءمة التفضيلات، بهدف رفع جودة الذكاء الاصطناعي المتاح إلى مستوى جديد.",
|
||||
"Ling-2.6-1T.description": "أحدث نموذج لغة كبير رئيسي، يدعم نافذة سياق تصل إلى 1 مليون رمز، مما يتيح سير عمل متكامل من الاستدلال المنطقي إلى تنفيذ المهام.",
|
||||
"Ling-2.6-flash.description": "Ling-2.6-flash هو الجيل الأحدث من النماذج عالية الأداء في سلسلة Ling. يعتمد على بنية Mixture-of-Experts (MoE)، مع إجمالي عدد معلمات يبلغ 100 مليار و6.1 مليار معلمة مفعلة لكل رمز، مما يحقق توازنًا مثاليًا بين أداء الاستدلال وتكلفة الحوسبة.",
|
||||
"Llama-3.2-11B-Vision-Instruct.description": "استدلال بصري قوي على الصور عالية الدقة، مناسب لتطبيقات الفهم البصري.",
|
||||
"Llama-3.2-90B-Vision-Instruct\t.description": "استدلال بصري متقدم لتطبيقات الفهم البصري المعتمدة على الوكلاء.",
|
||||
"Llama-3.2-90B-Vision-Instruct.description": "استدلال متقدم للصور لتطبيقات الوكلاء ذات الفهم البصري.",
|
||||
"LongCat-2.0-Preview.description": "الميزات الأساسية لـ LongCat-2.0-Preview هي كما يلي: مصمم لسيناريوهات تطوير الوكلاء، مع دعم أصلي لاستخدام الأدوات، التفكير متعدد الخطوات، ومهام السياق الطويل؛ يتفوق في توليد الأكواد، سير العمل الآلي، وتنفيذ التعليمات المعقدة؛ متكامل بعمق مع أدوات الإنتاجية مثل Claude Code، OpenClaw، OpenCode، وKilo Code.",
|
||||
"LongCat-Flash-Chat.description": "تم ترقية نموذج LongCat-Flash-Chat إلى إصدار جديد. يتضمن هذا التحديث تحسينات في قدرات النموذج فقط؛ يظل اسم النموذج وطريقة استدعاء API دون تغيير. بناءً على ميزاته المميزة مثل \"الكفاءة القصوى\" و\"الاستجابة السريعة للغاية\"، يعزز الإصدار الجديد فهم السياق وأداء البرمجة الواقعية: قدرات البرمجة المحسنة بشكل كبير: تم تحسين النموذج بشكل عميق لسيناريوهات المطورين، مما يوفر تحسينات كبيرة في مهام إنشاء الأكواد وتصحيح الأخطاء وشرحها. يُشجع المطورون بشدة على تقييم هذه التحسينات ومقارنتها. دعم سياق طويل للغاية 256K: تضاعف نافذة السياق من الجيل السابق (128K) إلى 256K، مما يتيح معالجة فعالة للوثائق الضخمة والمهام ذات التسلسل الطويل. تحسين شامل للأداء متعدد اللغات: يوفر دعمًا قويًا لتسع لغات، بما في ذلك الإسبانية والفرنسية والعربية والبرتغالية والروسية والإندونيسية. قدرات وكيل أكثر قوة: يظهر النموذج كفاءة أكبر في استدعاء الأدوات المعقدة وتنفيذ المهام متعددة الخطوات.",
|
||||
"LongCat-Flash-Lite.description": "تم إصدار نموذج LongCat-Flash-Lite رسميًا. يعتمد على بنية فعالة من نوع Mixture-of-Experts (MoE)، مع إجمالي 68.5 مليار معلمة وحوالي 3 مليارات معلمة مفعلة. من خلال استخدام جدول تضمين N-gram، يحقق استخدامًا فعالًا للغاية للمعلمات، وتم تحسينه بشكل عميق لكفاءة الاستنتاج وسيناريوهات التطبيقات المحددة. مقارنةً بالنماذج ذات الحجم المماثل، فإن ميزاته الأساسية هي كما يلي: كفاءة استنتاج ممتازة: من خلال الاستفادة من جدول تضمين N-gram لتخفيف عنق الزجاجة في الإدخال والإخراج في بنية MoE، جنبًا إلى جنب مع آليات التخزين المؤقت المخصصة وتحسينات على مستوى النواة، يقلل بشكل كبير من زمن الاستنتاج ويحسن الكفاءة العامة. أداء قوي في الوكيل والبرمجة: يظهر قدرات تنافسية عالية في استدعاء الأدوات ومهام تطوير البرمجيات، مما يوفر أداءً استثنائيًا بالنسبة لحجم النموذج.",
|
||||
"LongCat-Flash-Thinking-2601.description": "تم إصدار نموذج LongCat-Flash-Thinking-2601 رسميًا. كنموذج استنتاج مطور يعتمد على بنية Mixture-of-Experts (MoE)، يتميز بإجمالي 560 مليار معلمة. مع الحفاظ على تنافسية قوية عبر معايير الاستنتاج التقليدية، يعزز بشكل منهجي قدرات الاستنتاج على مستوى الوكيل من خلال التعلم المعزز متعدد البيئات واسع النطاق. مقارنةً بنموذج LongCat-Flash-Thinking، فإن الترقيات الرئيسية هي كما يلي: قوة استثنائية في البيئات المليئة بالضوضاء: من خلال تدريب منهجي بأسلوب المناهج يستهدف الضوضاء وعدم اليقين في البيئات الواقعية، يظهر النموذج أداءً ممتازًا في استدعاء أدوات الوكيل، البحث القائم على الوكيل، والاستنتاج المدمج بالأدوات، مع تحسين كبير في التعميم. قدرات وكيل قوية: من خلال إنشاء رسم بياني يعتمد على أكثر من 60 أداة، وتوسيع التدريب عبر بيئات متعددة واستكشاف واسع النطاق، يحسن النموذج بشكل ملحوظ قدرته على التعميم إلى سيناريوهات واقعية معقدة وخارج التوزيع. وضع التفكير العميق المتقدم: يوسع نطاق الاستنتاج عبر الاستنتاج المتوازي ويعمق القدرة التحليلية من خلال آليات التلخيص والتجريد المدفوعة بالتغذية الراجعة، مما يعالج المشكلات الصعبة للغاية بشكل فعال.",
|
||||
"LongCat-Flash-Thinking.description": "لضمان حصولك على أداء تفكير من الدرجة الأولى، قامت منصة LongCat API بتوحيد وترقية الطلبات إلى نموذج LongCat-Flash-Thinking. سيتم توجيه جميع الطلبات الحالية باستخدام `model=LongCat-Flash-Thinking` تلقائيًا إلى الإصدار الأحدث، LongCat-Flash-Thinking-2601، دون الحاجة إلى تغييرات في الكود.",
|
||||
"M2-her.description": "نموذج حوار نصي مصمم لتقمص الأدوار والمحادثات متعددة الأدوار، مع تخصيص الشخصيات والتعبير العاطفي.",
|
||||
"Meta-Llama-3-3-70B-Instruct.description": "Llama 3.3 70B هو نموذج Transformer متعدد الاستخدامات لمهام المحادثة والتوليد.",
|
||||
"Meta-Llama-3.1-405B-Instruct.description": "نموذج Llama 3.1 مضبوط على التعليمات، محسن للمحادثة متعددة اللغات، ويؤدي بقوة في معايير الصناعة الشائعة بين النماذج المفتوحة والمغلقة.",
|
||||
@@ -187,27 +186,10 @@
|
||||
"Qwen2.5-Coder-14B-Instruct.description": "Qwen2.5-Coder-14B-Instruct هو نموذج تعليمات برمجة مدرب مسبقًا على نطاق واسع يتمتع بفهم وتوليد قوي للشيفرة. يتعامل بكفاءة مع مجموعة واسعة من مهام البرمجة، ومثالي للبرمجة الذكية، وتوليد السكربتات التلقائي، والأسئلة والأجوبة البرمجية.",
|
||||
"Qwen2.5-Coder-32B-Instruct.description": "نموذج لغوي متقدم لتوليد الشيفرة، والاستدلال، وإصلاح الأخطاء عبر لغات البرمجة الرئيسية.",
|
||||
"Qwen3-235B-A22B-Instruct-2507-FP8.description": "Qwen3 235B A22B Instruct 2507 مُحسَّن للاستدلال المتقدم واتباع التعليمات، ويستخدم بنية MoE للحفاظ على كفاءة الاستدلال على نطاق واسع.",
|
||||
"Qwen3-235B.description": "Qwen3-235B-A22B هو نموذج MoE يُقدِّم وضع استدلال هجين، يتيح للمستخدمين التبديل بسلاسة بين التفكير وعدم التفكير. يدعم الفهم والاستدلال عبر 119 لغة ولهجة، ويتمتع بقدرات قوية على استدعاء الأدوات، ويتنافس مع نماذج رائدة مثل DeepSeek R1 وOpenAI o1 وo3-mini وGrok 3 وGoogle Gemini 2.5 Pro في اختبارات القدرات العامة، والبرمجة والرياضيات، والقدرات متعددة اللغات، واستدلال المعرفة.",
|
||||
"Qwen3-32B.description": "Qwen3-32B هو نموذج كثيف يُقدِّم وضع استدلال هجين، يتيح للمستخدمين التبديل بين التفكير وعدم التفكير. بفضل تحسينات في البنية، وبيانات أكثر، وتدريب أفضل، يقدم أداءً مماثلًا لـ Qwen2.5-72B.",
|
||||
"Qwen3.5-Plus.description": "يدعم Qwen3.5 Plus إدخال النصوص والصور والفيديو. أداؤه في المهام النصية البحتة مماثل لـ Qwen3 Max، مع أداء أفضل وتكلفة أقل. وقد تحسّنت قدراته متعددة الوسائط بشكل ملحوظ مقارنة بسلسلة Qwen3 VL.",
|
||||
"Ring-2.5-1T.description": "بالمقارنة مع Ring-1T الذي تم إصداره سابقًا، يحقق Ring-2.5-1T تحسينات كبيرة عبر ثلاثة أبعاد رئيسية: كفاءة التوليد، عمق الاستدلال، وقدرة تنفيذ المهام طويلة الأمد: **كفاءة التوليد**: من خلال الاستفادة من نسبة عالية من آليات الانتباه الخطي، يقلل Ring-2.5-1T من عبء الوصول إلى الذاكرة بأكثر من 10×. عند معالجة تسلسلات تتجاوز 32 ألف رمز، يوفر إنتاجية توليد أعلى بأكثر من 3×، مما يجعله مناسبًا بشكل خاص للاستدلال العميق وتنفيذ المهام طويلة الأمد. **الاستدلال العميق**: بناءً على RLVR، يتم تقديم آلية مكافأة كثيفة لتوفير تغذية راجعة حول دقة عملية الاستدلال. يتيح ذلك لـ Ring-2.5-1T تحقيق أداء بمستوى الميدالية الذهبية في كل من IMO 2025 وCMO 2025 (تقييم ذاتي). **تنفيذ المهام طويلة الأمد**: من خلال تدريب واسع النطاق قائم على التعلم المعزز غير المتزامن بالكامل، يعزز النموذج بشكل كبير قدرته على تنفيذ المهام المعقدة بشكل مستقل على مدى فترات طويلة. يتيح ذلك لـ Ring-2.5-1T التكامل بسلاسة مع أطر برمجة الوكلاء مثل Claude Code ومساعدي الذكاء الاصطناعي الشخصيين OpenClaw.",
|
||||
"Ring-2.6-1T.description": "Ring-2.6-1T هو نموذج استدلال بمقياس تريليون معلمة يقوم بتفعيل حوالي 63 مليار معلمة لكل استدلال. مصمم لسير عمل الوكلاء، يركز على قدرات الوكلاء، واستخدام الأدوات، وتنفيذ المهام طويلة الأمد، محققًا أداءً رائدًا في معايير مثل PinchBench وClawEval وTAU2-Bench وGAIA2-search. تم تحسين النموذج عبر جودة التنفيذ، والكمون، والتكلفة، مما يجعله مناسبًا لوكلاء البرمجة المتقدمة، وخطوط الاستدلال المعقدة، والأنظمة المستقلة واسعة النطاق.",
|
||||
"S2V-01.description": "النموذج الأساسي لتحويل المرجع إلى فيديو من سلسلة 01.",
|
||||
"SenseChat-128K.description": "الإصدار الرابع الأساسي مع سياق 128 ألف رمز، قوي في فهم وتوليد النصوص الطويلة.",
|
||||
"SenseChat-32K.description": "الإصدار الرابع الأساسي مع سياق 32 ألف رمز، مرن لمجموعة متنوعة من السيناريوهات.",
|
||||
"SenseChat-5-1202.description": "أحدث إصدار مبني على V5.5، مع تحسينات كبيرة في الأساسيات الصينية/الإنجليزية، والدردشة، ومعرفة العلوم والتكنولوجيا، والمعرفة الإنسانية، والكتابة، والرياضيات/المنطق، والتحكم في الطول.",
|
||||
"SenseChat-5-Cantonese.description": "مصمم ليتماشى مع عادات الحوار في هونغ كونغ، واللغة العامية، والمعرفة المحلية؛ يتفوق على GPT-4 في فهم الكانتونية ويضاهي GPT-4 Turbo في المعرفة، والاستدلال، والرياضيات، والبرمجة.",
|
||||
"SenseChat-5-beta.description": "يتفوق في بعض الجوانب على SenseChat-5-1202.",
|
||||
"SenseChat-5.description": "أحدث إصدار V5.5 مع سياق 128 ألف رمز؛ تحسينات كبيرة في الاستدلال الرياضي، والدردشة باللغة الإنجليزية، واتباع التعليمات، وفهم النصوص الطويلة، ويقارن بـ GPT-4o.",
|
||||
"SenseChat-Character-Pro.description": "نموذج دردشة متقدم للشخصيات مع سياق 32 ألف رمز، وقدرات محسنة، ودعم للغتين الصينية والإنجليزية.",
|
||||
"SenseChat-Character.description": "نموذج دردشة قياسي للشخصيات مع سياق 8 آلاف رمز وسرعة استجابة عالية.",
|
||||
"SenseChat-Turbo-1202.description": "أحدث نموذج خفيف الوزن يصل إلى أكثر من 90% من قدرات النموذج الكامل بتكلفة تنفيذ أقل بكثير.",
|
||||
"SenseChat-Turbo.description": "مناسب لأسئلة وأجوبة سريعة وسيناريوهات تحسين النماذج.",
|
||||
"SenseChat-Vision.description": "أحدث إصدار V5.5 مع إدخال متعدد الصور وتحسينات شاملة في التعرف على السمات، والعلاقات المكانية، واكتشاف الأحداث/الحركات، وفهم المشاهد، والتعرف على المشاعر، والاستدلال المنطقي، وفهم/توليد النصوص.",
|
||||
"SenseChat.description": "الإصدار الرابع الأساسي مع سياق 4 آلاف رمز وقدرات عامة قوية.",
|
||||
"SenseNova-V6-5-Pro.description": "مع تحديثات شاملة في البيانات متعددة الوسائط واللغوية والاستدلالية، إلى جانب تحسين استراتيجية التدريب، يُظهر النموذج الجديد تحسنًا كبيرًا في الاستدلال متعدد الوسائط واتباع التعليمات العامة، ويدعم نافذة سياق تصل إلى 128 ألف رمز، ويتفوق في مهام التعرف على النصوص (OCR) والتعرف على الملكية الفكرية في السياحة الثقافية.",
|
||||
"SenseNova-V6-5-Turbo.description": "مع تحديثات شاملة في البيانات متعددة الوسائط واللغوية والاستدلالية، إلى جانب تحسين استراتيجية التدريب، يُظهر النموذج الجديد تحسنًا كبيرًا في الاستدلال متعدد الوسائط واتباع التعليمات العامة، ويدعم نافذة سياق تصل إلى 128 ألف رمز، ويتفوق في مهام التعرف على النصوص (OCR) والتعرف على الملكية الفكرية في السياحة الثقافية.",
|
||||
"SenseNova-V6-Pro.description": "يوحد بشكل أصيل بين الصورة والنص والفيديو، متجاوزًا الحواجز التقليدية بين الوسائط المتعددة؛ ويحتل المراتب الأولى في OpenCompass وSuperCLUE.",
|
||||
"SenseNova-V6-Reasoner.description": "يجمع بين الرؤية واللغة في استدلال عميق، ويدعم التفكير البطيء وسلسلة التفكير الكاملة.",
|
||||
"SenseNova-V6-Turbo.description": "يوحد بشكل أصيل بين الصورة والنص والفيديو، متجاوزًا الحواجز التقليدية بين الوسائط المتعددة. يتفوق في القدرات الأساسية للوسائط المتعددة واللغة، ويحتل مرتبة متقدمة في العديد من التقييمات.",
|
||||
"Skylark2-lite-8k.description": "الجيل الثاني من نموذج Skylark. يتميز Skylark2-lite بسرعة استجابة عالية في السيناريوهات الحساسة للتكلفة والتي لا تتطلب دقة عالية، مع نافذة سياق تصل إلى 8 آلاف رمز.",
|
||||
"Skylark2-pro-32k.description": "الجيل الثاني من نموذج Skylark. يوفر Skylark2-pro دقة أعلى في توليد النصوص المعقدة مثل كتابة المحتوى الاحترافي، وتأليف الروايات، والترجمة عالية الجودة، مع نافذة سياق تصل إلى 32 ألف رمز.",
|
||||
"Skylark2-pro-4k.description": "الجيل الثاني من نموذج Skylark. يوفر Skylark2-pro دقة أعلى في توليد النصوص المعقدة مثل كتابة المحتوى الاحترافي، وتأليف الروايات، والترجمة عالية الجودة، مع نافذة سياق تصل إلى 4 آلاف رمز.",
|
||||
@@ -1197,6 +1179,8 @@
|
||||
"r1-1776.description": "R1-1776 هو إصدار ما بعد التدريب من DeepSeek R1 مصمم لتقديم معلومات واقعية غير خاضعة للرقابة أو التحيز.",
|
||||
"seedance-1-5-pro-251215.description": "Seedance 1.5 Pro من ByteDance يدعم تحويل النص إلى فيديو، تحويل الصورة إلى فيديو (الإطار الأول، الإطار الأول + الأخير)، وتوليد الصوت المتزامن مع المرئيات.",
|
||||
"seedream-5-0-260128.description": "ByteDance-Seedream-5.0-lite من BytePlus يتميز بتوليد معزز بالاسترجاع من الويب للحصول على معلومات في الوقت الفعلي، تفسير محسّن للمطالبات المعقدة، وتحسين اتساق المراجع لإنشاء مرئي احترافي.",
|
||||
"sensenova-6.7-flash-lite.description": "نموذج وكيل متعدد الوسائط خفيف الوزن مصمم لسير العمل الواقعي، يدعم المحادثات النصية وفهم الصور. خفيف الوزن وفعال، يوازن بين الأداء والتكلفة وقابلية النشر. بنية متعددة الوسائط أصلية مع دعم لفهم الصور، بما في ذلك التعرف الضوئي على الحروف (OCR) وتفسير الرسوم البيانية. معزز لسيناريوهات المكتب والإنتاجية، مع دعم مستقر للمهام المعقدة طويلة السلسلة. تحسين كفاءة الرموز، مما يتيح تحكمًا أفضل في التكلفة لأعباء العمل المعقدة. طول السياق يصل إلى 256 ألف رمز (المدخلات القصوى: 252 ألف، المخرجات القصوى: 64 ألف).",
|
||||
"sensenova-u1-fast.description": "نسخة مسرعة تعتمد على SenseNova U1، تم تحسينها خصيصًا لإنشاء الرسوم المعلوماتية.",
|
||||
"solar-mini-ja.description": "Solar Mini (Ja) يوسع Solar Mini مع تركيز على اللغة اليابانية مع الحفاظ على الأداء القوي والكفاءة في الإنجليزية والكورية.",
|
||||
"solar-mini.description": "Solar Mini هو نموذج لغة مدمج يتفوق على GPT-3.5، يتميز بقدرات متعددة اللغات قوية تدعم الإنجليزية والكورية، ويقدم حلاً فعالاً بصمة صغيرة.",
|
||||
"solar-pro.description": "Solar Pro هو نموذج لغة عالي الذكاء من Upstage، يركز على اتباع التعليمات باستخدام وحدة معالجة رسومات واحدة، مع درجات IFEval تتجاوز 80. حالياً يدعم اللغة الإنجليزية؛ وكان من المقرر إصدار النسخة الكاملة في نوفمبر 2024 مع دعم لغات موسع وسياق أطول.",
|
||||
|
||||
@@ -17,6 +17,8 @@
|
||||
"storage_overage_cap_reached_title": "تم الوصول إلى الحد الأقصى للدفع حسب الاستخدام للتخزين",
|
||||
"video_generation_completed": "الفيديو الخاص بك \"{{prompt}}\" جاهز.",
|
||||
"video_generation_completed_title": "اكتملت عملية إنشاء الفيديو",
|
||||
"workspace_member_invited": "{{inviterLabel}} دعاك للانضمام إلى مساحة العمل \"{{workspaceName}}\" ك{{role}}.",
|
||||
"workspace_member_invited_title": "دعوة للانضمام إلى {{workspaceName}}",
|
||||
"workspace_member_joined": "{{memberLabel}} انضم إلى مساحة العمل \"{{workspaceName}}\" كـ {{role}}.",
|
||||
"workspace_member_joined_member": "{{memberLabel}} انضم إلى مساحة العمل \"{{workspaceName}}\" كعضو.",
|
||||
"workspace_member_joined_member_title": "عضو جديد انضم إلى {{workspaceName}}",
|
||||
|
||||
@@ -1,6 +1,34 @@
|
||||
{
|
||||
"arguments.moreParams": "إجمالي {{count}} من المعاملات",
|
||||
"arguments.title": "المعلمات",
|
||||
"builtins.codex.apiName.collab_tool_call": "تنسيق الوكلاء الفرعيين",
|
||||
"builtins.codex.apiName.command_execution": "تشغيل الأمر",
|
||||
"builtins.codex.apiName.file_change": "تعديل الملفات",
|
||||
"builtins.codex.apiName.mcp_tool_call": "استدعاء أداة MCP",
|
||||
"builtins.codex.apiName.todo_list": "تحديث المهام",
|
||||
"builtins.codex.apiName.web_search": "البحث على الويب",
|
||||
"builtins.codex.collabTool.agentCount_one": "{{count}} وكيل فرعي",
|
||||
"builtins.codex.collabTool.agentCount_other": "{{count}} وكلاء فرعيون",
|
||||
"builtins.codex.collabTool.agentLabel": "وكيل فرعي {{index}}",
|
||||
"builtins.codex.collabTool.agents": "الوكلاء الفرعيون",
|
||||
"builtins.codex.collabTool.closeAgent": "إغلاق الوكيل الفرعي",
|
||||
"builtins.codex.collabTool.instruction": "تعليمات",
|
||||
"builtins.codex.collabTool.sendInput": "إرسال رسالة إلى الوكيل الفرعي",
|
||||
"builtins.codex.collabTool.spawnAgent": "إنشاء وكيل فرعي",
|
||||
"builtins.codex.collabTool.wait": "انتظر الوكلاء الفرعيين",
|
||||
"builtins.codex.commandExecution.grep": "بحث",
|
||||
"builtins.codex.commandExecution.noResults": "لا توجد نتائج",
|
||||
"builtins.codex.commandExecution.readFile": "قراءة الملف",
|
||||
"builtins.codex.fileChange.editedFiles_one": "تم تعديل {{count}} ملف",
|
||||
"builtins.codex.fileChange.editedFiles_other": "تم تعديل {{count}} ملفات",
|
||||
"builtins.codex.fileChange.editing": "تعديل الملفات",
|
||||
"builtins.codex.fileChange.noChanges": "لا توجد تغييرات في الملفات",
|
||||
"builtins.codex.fileChange.unknownFile": "ملف غير معروف",
|
||||
"builtins.codex.mcpTool.error": "خطأ",
|
||||
"builtins.codex.mcpTool.input": "إدخال",
|
||||
"builtins.codex.mcpTool.result": "النتيجة",
|
||||
"builtins.codex.mcpTool.unknownTool": "أداة MCP",
|
||||
"builtins.codex.webSearch.query": "استعلام",
|
||||
"builtins.lobe-activator.apiName.activateTools": "تفعيل الأدوات",
|
||||
"builtins.lobe-activator.inspector.activateTools.notFoundCount": "{{count}} غير موجود",
|
||||
"builtins.lobe-agent-builder.apiName.getAvailableModels": "الحصول على النماذج المتاحة",
|
||||
@@ -429,6 +457,15 @@
|
||||
"dev.mcp.auth.desc": "اختر طريقة المصادقة لخادم MCP",
|
||||
"dev.mcp.auth.label": "نوع المصادقة",
|
||||
"dev.mcp.auth.none": "بدون مصادقة",
|
||||
"dev.mcp.auth.oauth": "أووث",
|
||||
"dev.mcp.auth.oauth.authorize": "التفويض والاتصال",
|
||||
"dev.mcp.auth.oauth.clientId.desc": "اتركه فارغًا لتسجيل عميل تلقائيًا (تسجيل عميل ديناميكي)",
|
||||
"dev.mcp.auth.oauth.clientId.label": "معرف عميل أووث",
|
||||
"dev.mcp.auth.oauth.clientId.placeholder": "اختياري",
|
||||
"dev.mcp.auth.oauth.clientSecret.desc": "مطلوب فقط لعملاء أووث السريين",
|
||||
"dev.mcp.auth.oauth.clientSecret.label": "سر عميل أووث",
|
||||
"dev.mcp.auth.oauth.clientSecret.placeholder": "اختياري",
|
||||
"dev.mcp.auth.oauth.redirectHint": "عنوان URI لإعادة التوجيه لتسجيله مع تطبيق أووث الخاص بك:",
|
||||
"dev.mcp.auth.placeholder": "اختر نوع المصادقة",
|
||||
"dev.mcp.auth.token.desc": "أدخل مفتاح API أو رمز Bearer",
|
||||
"dev.mcp.auth.token.label": "مفتاح API",
|
||||
|
||||
@@ -4,6 +4,7 @@
|
||||
"ai360.description": "360 AI هي منصة نماذج وخدمات من شركة 360، تقدم نماذج معالجة اللغة الطبيعية مثل 360GPT2 Pro و360GPT Pro و360GPT Turbo. تجمع هذه النماذج بين المعلمات واسعة النطاق والقدرات متعددة الوسائط لتوليد النصوص، وفهم المعاني، والدردشة، والبرمجة، مع تسعير مرن لتلبية احتياجات متنوعة.",
|
||||
"aihubmix.description": "يوفر AiHubMix الوصول إلى نماذج ذكاء اصطناعي متعددة من خلال واجهة برمجة تطبيقات موحدة.",
|
||||
"akashchat.description": "أكاش هو سوق موارد سحابية غير مركزي يتميز بأسعار تنافسية مقارنة بمزودي الخدمات السحابية التقليديين.",
|
||||
"antgroup.description": "Ant Ling هو سلسلة النماذج الأساسية لمبادرة الذكاء العام الاصطناعي (AGI) التابعة لمجموعة Ant Group، مكرسة لبناء وفتح قدرات النماذج الأساسية المتقدمة. نحن نؤمن بأن تطوير الذكاء يجب أن يتجه نحو الانفتاح والمشاركة والقابلية للتوسع—بدءًا من خطوات صغيرة وعملية لدفع التطور المستمر ونشر الذكاء العام الاصطناعي في العالم الحقيقي.",
|
||||
"anthropic.description": "تقوم Anthropic بتطوير نماذج لغوية متقدمة مثل Claude 3.5 Sonnet وClaude 3 Sonnet وClaude 3 Opus وClaude 3 Haiku، وتوازن بين الذكاء والسرعة والتكلفة لتناسب مختلف حالات الاستخدام من المؤسسات إلى الاستجابات السريعة.",
|
||||
"azure.description": "تقدم Azure نماذج ذكاء اصطناعي متقدمة، بما في ذلك سلسلة GPT-3.5 وGPT-4، لمعالجة أنواع بيانات متنوعة ومهام معقدة مع التركيز على الأمان والموثوقية والاستدامة.",
|
||||
"azureai.description": "توفر Azure نماذج ذكاء اصطناعي متقدمة، بما في ذلك سلسلة GPT-3.5 وGPT-4، لمعالجة أنواع بيانات متنوعة ومهام معقدة مع التركيز على الأمان والموثوقية والاستدامة.",
|
||||
|
||||
+36
-1
@@ -280,7 +280,33 @@
|
||||
"defaultAgent.title": "إعدادات الوكيل الافتراضي",
|
||||
"devices.actions.edit": "تعديل",
|
||||
"devices.actions.remove": "إزالة",
|
||||
"devices.capabilities.commands.desc": "قم بتنفيذ أوامر الطرفية بأمان في بيئتك.",
|
||||
"devices.capabilities.commands.title": "تشغيل الأوامر",
|
||||
"devices.capabilities.files.desc": "اسمح للوكلاء بالوصول المباشر إلى الملفات على جهاز الكمبيوتر الخاص بك وتنظيمها.",
|
||||
"devices.capabilities.files.title": "قراءة وكتابة الملفات المحلية",
|
||||
"devices.capabilities.title": "ما يمكنك فعله بمجرد الاتصال",
|
||||
"devices.capabilities.tools.desc": "قم بتوصيل الأدوات المحلية لتوسيع ما يمكن للوكلاء القيام به.",
|
||||
"devices.capabilities.tools.title": "استدعاء أدوات النظام",
|
||||
"devices.channel.connected": "متصل {{time}}",
|
||||
"devices.connectWizard.button": "اتصال الجهاز",
|
||||
"devices.connectWizard.cli.connectDesc": "ابدأ تشغيل الخلفية للحفاظ على الجهاز متصلاً ومستعدًا للعمليات عن بُعد.",
|
||||
"devices.connectWizard.cli.connectTitle": "ابدأ تشغيل الخلفية",
|
||||
"devices.connectWizard.cli.installDesc": "قم بتثبيت LobeHub CLI عالميًا باستخدام مدير الحزم المفضل لديك لتمكين الاتصال وإدارة الجهاز.",
|
||||
"devices.connectWizard.cli.installTitle": "تثبيت CLI",
|
||||
"devices.connectWizard.cli.loginDesc": "أكمل تفويض OAuth في متصفحك لربط CLI بحسابك.",
|
||||
"devices.connectWizard.cli.loginTitle": "تسجيل الدخول",
|
||||
"devices.connectWizard.desktop.downloadLink": "تحميل تطبيق LobeHub Desktop",
|
||||
"devices.connectWizard.desktop.step1": "قم بتنزيل تطبيق سطح المكتب",
|
||||
"devices.connectWizard.desktop.step1Desc": "قم بزيارة صفحة تنزيلات LobeHub واحصل على التطبيق لنظام التشغيل الخاص بك.",
|
||||
"devices.connectWizard.desktop.step2": "سجل الدخول وافتح بوابة الجهاز",
|
||||
"devices.connectWizard.desktop.step2Desc": "بعد تسجيل الدخول، انقر على أيقونة بوابة الجهاز في الزاوية العلوية اليمنى وتأكد من تشغيلها.",
|
||||
"devices.connectWizard.desktop.step3": "يظهر جهازك تلقائيًا",
|
||||
"devices.connectWizard.desktop.step3Desc": "يسجل تطبيق سطح المكتب نفسه كجهاز عند التشغيل — ستراه في القائمة بمجرد الاتصال.",
|
||||
"devices.connectWizard.footer": "يتم تسجيل بيانات تعريف الجهاز فقط — لا يتم الوصول إلى بياناتك أبدًا.",
|
||||
"devices.connectWizard.method.cli": "عبر CLI",
|
||||
"devices.connectWizard.method.desktop": "عبر سطح المكتب",
|
||||
"devices.connectWizard.subtitle": "اختر كيفية توصيل جهاز الكمبيوتر الخاص بك بـ LobeHub.",
|
||||
"devices.connectWizard.title": "اتصال الجهاز",
|
||||
"devices.currentBadge": "هذا الجهاز",
|
||||
"devices.detail.addDir": "إضافة دليل",
|
||||
"devices.detail.connections": "الاتصالات",
|
||||
@@ -294,7 +320,13 @@
|
||||
"devices.edit.friendlyNamePlaceholder": "اسم للتعرف على هذا الجهاز",
|
||||
"devices.edit.save": "حفظ",
|
||||
"devices.edit.title": "تعديل الجهاز",
|
||||
"devices.empty": "لا توجد أجهزة حتى الآن. قم بتوصيل جهاز باستخدام `lh connect` أو عن طريق تسجيل الدخول إلى تطبيق سطح المكتب.",
|
||||
"devices.empty.desc": "بمجرد الاتصال، يمكن لوكلاء LobeHub قراءة/كتابة الملفات، تشغيل الأوامر، واستدعاء أدوات النظام مباشرة على جهاز الكمبيوتر الخاص بك.",
|
||||
"devices.empty.methodCli.desc": "قم بتثبيت CLI في الطرفية الخاصة بك — مثالي للخوادم أو الأجهزة بدون واجهة.",
|
||||
"devices.empty.methodCli.title": "الاتصال عبر CLI",
|
||||
"devices.empty.methodDesktop.badge": "موصى به",
|
||||
"devices.empty.methodDesktop.desc": "قم بتنزيل تطبيق سطح المكتب، سجل الدخول، وسيتم توصيل جهازك تلقائيًا.",
|
||||
"devices.empty.methodDesktop.title": "الاتصال عبر سطح المكتب",
|
||||
"devices.empty.title": "قم بتوصيل جهازك الأول",
|
||||
"devices.fallbackBadge": "هوية غير مستقرة",
|
||||
"devices.fallbackTooltip": "لم يتمكن هذا الجهاز من التعرف عليه بواسطة معرف الجهاز، لذا قد يؤدي إعادة تثبيت التطبيق إلى إنشاء إدخال مكرر.",
|
||||
"devices.lastSeen": "آخر نشاط {{time}}",
|
||||
@@ -522,6 +554,7 @@
|
||||
"notification.item.image_generation_completed": "اكتمل إنشاء الصورة",
|
||||
"notification.item.storage_overage_cap_reached": "تم الوصول إلى الحد الأقصى للدفع حسب الاستخدام للتخزين",
|
||||
"notification.item.video_generation_completed": "اكتمل إنشاء الفيديو",
|
||||
"notification.item.workspace_member_invited": "دعوة إلى مساحة العمل",
|
||||
"notification.item.workspace_member_joined": "انضم عضو جديد",
|
||||
"notification.item.workspace_member_removed": "تمت إزالته من مساحة العمل",
|
||||
"notification.item.workspace_payment_failed": "فشل تجديد الدفع",
|
||||
@@ -1766,6 +1799,7 @@
|
||||
"workspace.members.invite.errors.alreadyMember": "{{email}} هو بالفعل عضو في هذه مساحة العمل.",
|
||||
"workspace.members.invite.failed": "فشل في إرسال الدعوة",
|
||||
"workspace.members.invite.limitReached": "يمكن أن تحتوي هذه مساحة العمل على ما يصل إلى {{limit}} أعضاء. قم بإزالة عضو قبل دعوة المزيد.",
|
||||
"workspace.members.invite.modal.billIncrease": "ستزيد فاتورتك بمقدار ${{amount}}/شهريًا.",
|
||||
"workspace.members.invite.modal.cancel": "إلغاء",
|
||||
"workspace.members.invite.modal.confirm": "تأكيد",
|
||||
"workspace.members.invite.modal.description_one": "فريقك يتوسع! بالتأكيد، ستدعو عضو فريق جديد واحد إلى هذه مساحة العمل.",
|
||||
@@ -1873,6 +1907,7 @@
|
||||
"workspace.upgradeModal.chargeDisclosure": "عند النقر على الترقية، سيتم فرض رسوم ${{fee}}، بالإضافة إلى أي ضرائب ورسوم قابلة للتطبيق، فورًا ثم كل شهر، حتى تقوم بالإلغاء. يتم تسوية رسوم المقاعد والاستخدام حسب الطلب في نهاية الشهر؛ إذا تجاوز استخدامك حد الفوترة خلال دورة، قد يتم فرض رسوم على طريقة الدفع الخاصة بك قبل انتهاء الدورة.",
|
||||
"workspace.upgradeModal.continueCta": "متابعة",
|
||||
"workspace.upgradeModal.createTeam": "إنشاء مساحة العمل",
|
||||
"workspace.upgradeModal.formDescription": "راجع التفاصيل أدناه وقم بتأكيد الترقية.",
|
||||
"workspace.upgradeModal.formSubtitle": "يتم فرض رسوم المنصة فقط اليوم — يتم تسوية رسوم المقاعد في نهاية الشهر.",
|
||||
"workspace.upgradeModal.formTitle": "ترقية {{name}} إلى Pro",
|
||||
"workspace.upgradeModal.heading": "ترقية مساحة العمل إلى Pro",
|
||||
|
||||
@@ -15,6 +15,8 @@
|
||||
"agentBuilder.installPlugin.retry": "Опитай отново",
|
||||
"agentBuilder.title": "Създател на Агенти",
|
||||
"agentBuilder.welcome": "Разкажете ми за вашия случай на употреба.\n\nПисане, програмиране или анализ на данни — всичко е възможно. Вие определяте целта и стандартите; аз ще ги разделя на съвместими, изпълними Агенти.",
|
||||
"agentConfigError.retry": "Опитай отново",
|
||||
"agentConfigError.title": "Неуспешно зареждане на настройките на агента",
|
||||
"agentDefaultMessage": "Здравей, аз съм **{{name}}**. Едно изречение е достатъчно.\n\nИскате да се адаптирам по-добре към вашия работен процес? Отидете в [Настройки на Агента]({{url}}) и попълнете Профила на Агента (можете да го редактирате по всяко време).",
|
||||
"agentDefaultMessageWithSystemRole": "Здравей, аз съм **{{name}}**. Едно изречение е достатъчно — вие контролирате.",
|
||||
"agentDefaultMessageWithoutEdit": "Здравей, аз съм **{{name}}**. Едно изречение е достатъчно — вие контролирате.",
|
||||
@@ -252,6 +254,10 @@
|
||||
"input.costEstimate.tooltip": "Оценено въз основа на текущия контекст, инструменти и ценообразуване на модела. Реалната цена може да варира.",
|
||||
"input.disclaimer": "Агентите могат да допускат грешки. Използвайте собствена преценка за важна информация.",
|
||||
"input.errorMsg": "Изпращането не бе успешно: {{errorMsg}}. Опитайте отново или по-късно.",
|
||||
"input.inputCompletionError.desc": "Предложенията за въвеждане спряха след грешка. Опитайте отново или коригирайте модела за предложения в Настройки.",
|
||||
"input.inputCompletionError.retry": "Опитай отново",
|
||||
"input.inputCompletionError.settings": "Настройки",
|
||||
"input.inputCompletionError.title": "Предложенията за въвеждане са паузирани",
|
||||
"input.more": "Още",
|
||||
"input.send": "Изпрати",
|
||||
"input.sendWithCmdEnter": "Натиснете <key/>, за да изпратите",
|
||||
@@ -915,6 +921,7 @@
|
||||
"workflow.toolDisplayName.addPreferenceMemory": "Запазена памет",
|
||||
"workflow.toolDisplayName.calculate": "Изчислено",
|
||||
"workflow.toolDisplayName.callAgent": "Извикан агент",
|
||||
"workflow.toolDisplayName.callMcpTool": "Извикан MCP инструмент",
|
||||
"workflow.toolDisplayName.callSubAgent": "Изпратен под-агент",
|
||||
"workflow.toolDisplayName.clearTodos": "Изчистени задачи",
|
||||
"workflow.toolDisplayName.copyDocument": "Копиран документ",
|
||||
@@ -1005,7 +1012,9 @@
|
||||
"workingPanel.localFile.closeRight": "Затвори надясно",
|
||||
"workingPanel.localFile.error": "Не може да се зареди този файл",
|
||||
"workingPanel.localFile.preview.raw": "Суров",
|
||||
"workingPanel.localFile.preview.reload": "Презареди визуализацията",
|
||||
"workingPanel.localFile.preview.render": "Преглед",
|
||||
"workingPanel.localFile.preview.source": "Източник",
|
||||
"workingPanel.localFile.truncated": "Прегледът на файла е съкратен до {{limit}} символа",
|
||||
"workingPanel.progress": "Progress",
|
||||
"workingPanel.progress.allCompleted": "All tasks completed",
|
||||
|
||||
@@ -239,6 +239,7 @@
|
||||
"providerModels.item.modelConfig.extendParams.options.reasoningBudgetToken32k.hint": "За GLM-5 и GLM-4.7; контролира бюджета за токени за разсъждение (максимум 32k).",
|
||||
"providerModels.item.modelConfig.extendParams.options.reasoningBudgetToken80k.hint": "За серията Qwen3; контролира бюджета за токени за разсъждение (максимум 80k).",
|
||||
"providerModels.item.modelConfig.extendParams.options.reasoningEffort.hint": "За OpenAI и други модели с логическо мислене; контролира усилието за разсъждение.",
|
||||
"providerModels.item.modelConfig.extendParams.options.ring2_6ReasoningEffort.hint": "За серия Ring 2.6; контролира интензивността на разсъжденията.",
|
||||
"providerModels.item.modelConfig.extendParams.options.step3_5ReasoningEffort.hint": "За серията Step 3.5; контролира интензивността на разсъжденията.",
|
||||
"providerModels.item.modelConfig.extendParams.options.textVerbosity.hint": "За серията GPT-5+; контролира обемността на изходния текст.",
|
||||
"providerModels.item.modelConfig.extendParams.options.thinking.hint": "За някои модели Doubao; позволява на модела да реши дали да мисли задълбочено.",
|
||||
|
||||
+12
-28
@@ -27,15 +27,15 @@
|
||||
"DeepSeek-OCR.description": "DeepSeek-OCR е мултимоделен модел на DeepSeek AI, фокусиран върху OCR и „контекстуална оптична компресия“. Той изследва техники за компресиране на контекст от изображения, обработва документи ефективно и ги преобразува в структуриран текст (например Markdown). Точно разпознава текст в изображения и е подходящ за дигитализация на документи, извличане на текст и структурирана обработка.",
|
||||
"DeepSeek-R1-Distill-Llama-70B.description": "DeepSeek R1, по-големият и по-интелигентен модел от серията DeepSeek, е дистилиран в архитектурата Llama 70B. Бенчмаркове и човешки оценки показват, че е по-умен от базовия Llama 70B, особено при задачи по математика и точност на фактите.",
|
||||
"DeepSeek-R1-Distill-Qwen-1.5B.description": "Дистилиран модел DeepSeek-R1, базиран на Qwen2.5-Math-1.5B. Подсилващо обучение и cold-start данни оптимизират логическата производителност, поставяйки нови мултизадачни бенчмаркове за отворени модели.",
|
||||
"DeepSeek-R1-Distill-Qwen-14B.description": "Моделите DeepSeek-R1-Distill са фино настроени от отворени модели с помощта на примерни данни, генерирани от DeepSeek-R1.",
|
||||
"DeepSeek-R1-Distill-Qwen-32B.description": "Моделите DeepSeek-R1-Distill са фино настроени от отворени модели с помощта на примерни данни, генерирани от DeepSeek-R1.",
|
||||
"DeepSeek-R1-Distill-Qwen-14B.description": "Дистилиран модел DeepSeek-R1, базиран на Qwen2.5-14B. Усъвършенстването на производителността при разсъждения се постига чрез обучение с подсилване и данни за студен старт, поставяйки нови стандарти за многозадачност за отворени модели.",
|
||||
"DeepSeek-R1-Distill-Qwen-32B.description": "Серията DeepSeek-R1 подобрява производителността при разсъждения чрез обучение с подсилване и данни за студен старт, поставяйки нови стандарти за многозадачност за отворени модели и надминавайки OpenAI o1-mini.",
|
||||
"DeepSeek-R1-Distill-Qwen-7B.description": "Дистилиран модел DeepSeek-R1, базиран на Qwen2.5-Math-7B. Подсилващо обучение и cold-start данни оптимизират логическата производителност, поставяйки нови мултизадачни бенчмаркове за отворени модели.",
|
||||
"DeepSeek-R1.description": "DeepSeek-R1 прилага мащабно подсилващо обучение в етапа след предварителното обучение, значително подобрявайки логическото мислене с много малко етикетирани данни. Сравнява се с продукционния модел OpenAI o1 при задачи по математика, програмиране и езиково разсъждение.",
|
||||
"DeepSeek-R1.description": "Ефективен LLM от най-висок клас, силен в разсъждения, математика и програмиране.",
|
||||
"DeepSeek-V3-1.description": "DeepSeek V3.1 е следващо поколение модел за логическо мислене с подобрено сложно разсъждение и верига на мисълта, подходящ за задачи с дълбок анализ.",
|
||||
"DeepSeek-V3-Fast.description": "Доставчик: sophnet. DeepSeek V3 Fast е високоскоростната версия на DeepSeek V3 0324, с пълна прецизност (без квантизация), по-силен при програмиране и математика и по-бързи отговори.",
|
||||
"DeepSeek-V3.1-Think.description": "Режим на мислене на DeepSeek-V3.1: нов хибриден модел за разсъждение с мислещ и немислещ режим, по-ефективен от DeepSeek-R1-0528. Оптимизациите след обучение значително подобряват използването на инструменти от агенти и производителността при агентни задачи.",
|
||||
"DeepSeek-V3.2.description": "deepseek-v3.2 въвежда механизъм за разредено внимание, който подобрява ефективността при обучение и инференция при обработка на дълги текстове, като е по-евтин от deepseek-v3.1.",
|
||||
"DeepSeek-V3.description": "DeepSeek-V3 е MoE модел, разработен от DeepSeek. Надминава други отворени модели като Qwen2.5-72B и Llama-3.1-405B в много бенчмаркове и е конкурентен с водещи затворени модели като GPT-4o и Claude 3.5 Sonnet.",
|
||||
"DeepSeek-V3.description": "Отвореното внедряване на ByteDance Volcengine в момента е най-стабилното; препоръчва се. Автоматично е обновено до последната версия (250324).",
|
||||
"Doubao-lite-128k.description": "Doubao-lite предлага изключително бързи отговори и по-добра стойност, с гъвкави опции за различни сценарии. Поддържа 128K контекст за извеждане и фина настройка.",
|
||||
"Doubao-lite-32k.description": "Doubao-lite предлага изключително бързи отговори и по-добра стойност, с гъвкави опции за различни сценарии. Поддържа 32K контекст за извеждане и фина настройка.",
|
||||
"Doubao-lite-4k.description": "Doubao-lite предлага изключително бързи отговори и по-добра стойност, с гъвкави опции за различни сценарии. Поддържа 4K контекст за извеждане и фина настройка.",
|
||||
@@ -83,13 +83,12 @@
|
||||
"Kimi-K2.5.description": "Kimi K2.5 е най-способният модел от серията Kimi, постигащ водещи резултати при агентни задачи, програмиране и визуално разбиране. Поддържа мултимодални входове и режими с мислене и без мислене.",
|
||||
"Kolors.description": "Kolors е модел за преобразуване на текст в изображение, разработен от екипа на Kuaishou Kolors. Обучен с милиарди параметри, той има значителни предимства във визуалното качество, разбиране на китайски семантики и визуализиране на текст.",
|
||||
"Kwai-Kolors/Kolors.description": "Kolors е мащабен латентен дифузионен модел за преобразуване на текст в изображение от екипа на Kuaishou Kolors. Обучен върху милиарди двойки текст-изображение, той се отличава с високо визуално качество, точност при сложни семантики и визуализиране на китайски/английски текст, с отлично разбиране и генериране на китайско съдържание.",
|
||||
"Ling-2.5-1T.description": "Като най-новия флагмански модел в реално време от серията Ling, Ling-2.5-1T въвежда цялостни подобрения в архитектурата на модела, ефективността на токените и съгласуването на предпочитанията, с цел да издигне качеството на достъпния AI на ново ниво.",
|
||||
"Ling-2.6-1T.description": "Най-новият флагмански голям езиков модел, който поддържа контекстен прозорец от 1M токена и позволява цялостен работен процес от логическо разсъждение до изпълнение на задачи.",
|
||||
"Ling-2.6-flash.description": "Ling-2.6-flash е най-новото поколение модел с висока ефективност от серията Ling. Той използва архитектура Mixture-of-Experts (MoE) с общ брой параметри от 100B и 6.1B активирани параметри на токен, постигайки оптимален баланс между производителност при изводи и изчислителни разходи.",
|
||||
"Llama-3.2-11B-Vision-Instruct.description": "Силен визуален анализ на изображения с висока резолюция, подходящ за приложения за визуално разбиране.",
|
||||
"Llama-3.2-90B-Vision-Instruct\t.description": "Разширено визуално разсъждение за приложения с агенти за визуално разбиране.",
|
||||
"Llama-3.2-90B-Vision-Instruct.description": "Напреднало разсъждение върху изображения за приложения за визуално разбиране на агенти.",
|
||||
"LongCat-2.0-Preview.description": "LongCat‑2.0‑Preview предлага основни функции: създаден за разработки с агенти; поддържа инструменти, многоетапно разсъждение и дълъг контекст; отличава се в генериране на код, автоматизирани работни потоци и сложни инструкции; интегриран с инструменти като Claude Code, OpenClaw, OpenCode и Kilo Code.",
|
||||
"LongCat-Flash-Chat.description": "Моделът LongCat-Flash-Chat е обновен до нова версия. Това обновление включва подобрения само в способностите на модела; името на модела и методът за извикване на API остават непроменени. Въз основа на отличителните му характеристики „екстремна ефективност“ и „светкавично бърз отговор“, новата версия допълнително укрепва контекстуалното разбиране и производителността при програмиране в реалния свят: Значително подобрени способности за кодиране: Дълбоко оптимизиран за сценарии, ориентирани към разработчици, моделът предоставя значителни подобрения в генерирането на код, отстраняването на грешки и обяснителните задачи. Разработчиците са силно насърчени да оценят и сравнят тези подобрения. Поддръжка за 256K ултра-дълъг контекст: Контекстният прозорец е удвоен от предишното поколение (128K) до 256K, позволявайки ефективна обработка на масивни документи и задачи с дълги последователности. Комплексно подобрена многоезична производителност: Осигурява силна поддръжка за девет езика, включително испански, френски, арабски, португалски, руски и индонезийски. По-мощни способности на агентите: Демонстрира по-голяма устойчивост и ефективност при сложни извиквания на инструменти и изпълнение на многоетапни задачи.",
|
||||
"LongCat-Flash-Lite.description": "Моделът LongCat-Flash-Lite е официално пуснат. Той използва ефективна архитектура Mixture-of-Experts (MoE) с общо 68.5 милиарда параметри и приблизително 3 милиарда активирани параметри. Чрез използването на таблица за вграждане на N-грам, той постига високо ефективно използване на параметрите и е дълбоко оптимизиран за ефективност на изводите и специфични приложения. В сравнение с модели от подобен мащаб, основните му характеристики са следните: Изключителна ефективност на изводите: Чрез използване на таблицата за вграждане на N-грам за фундаментално облекчаване на I/O ограниченията, присъщи на архитектурите MoE, комбинирано с специализирани механизми за кеширане и оптимизации на ниво ядро, значително намалява латентността на изводите и подобрява общата ефективност. Силна производителност на агентите и кода: Демонстрира високо конкурентни способности при извикване на инструменти и задачи за разработка на софтуер, предоставяйки изключителна производителност спрямо размера на модела.",
|
||||
"LongCat-Flash-Thinking-2601.description": "Моделът LongCat-Flash-Thinking-2601 е официално пуснат. Като обновен модел за разсъждение, изграден върху архитектура Mixture-of-Experts (MoE), той разполага с общо 560 милиарда параметри. Докато поддържа силна конкурентоспособност в традиционните бенчмаркове за разсъждение, той систематично подобрява способностите за разсъждение на ниво агент чрез мащабно обучение с подсилване в много среди. В сравнение с модела LongCat-Flash-Thinking, ключовите подобрения са следните: Екстремна устойчивост в шумни среди: Чрез систематично обучение в стил учебна програма, насочено към шум и несигурност в реални условия, моделът демонстрира изключителна производителност при извикване на инструменти от агенти, търсене на база агенти и интегрирано разсъждение с инструменти, със значително подобрена генерализация. Мощни способности на агентите: Чрез изграждане на плътно свързан граф на зависимости, обхващащ повече от 60 инструмента, и мащабиране на обучението чрез разширение в много среди и мащабно изследователско обучение, моделът значително подобрява способността си да се генерализира към сложни и извън разпределението реални сценарии. Разширен режим на дълбоко мислене: Разширява обхвата на разсъжденията чрез паралелно извеждане и задълбочава аналитичната способност чрез механизми за обобщение и абстракция, управлявани от обратна връзка, ефективно адресирайки силно предизвикателни проблеми.",
|
||||
"LongCat-Flash-Thinking.description": "За да осигурим най-високо качество на разсъждение, LongCat API обединява и обновява заявките към модела LongCat‑Flash‑Thinking. Всички заявки с `model=LongCat-Flash-Thinking` автоматично се насочват към последната версия – LongCat‑Flash‑Thinking‑2601, без нужда от промени в кода.",
|
||||
"M2-her.description": "Модел за текстови диалози, създаден за ролеви игри и многократни разговори, с възможност за персонализиране на героите и изразяване на емоции.",
|
||||
"Meta-Llama-3-3-70B-Instruct.description": "Llama 3.3 70B е универсален трансформерен модел за чат и генериране на текст.",
|
||||
"Meta-Llama-3.1-405B-Instruct.description": "Llama 3.1 е текстов модел, обучен с инструкции, оптимизиран за многоезичен чат, с отлични резултати на водещи индустриални бенчмаркове сред отворени и затворени модели.",
|
||||
@@ -187,27 +186,10 @@
|
||||
"Qwen2.5-Coder-14B-Instruct.description": "Qwen2.5-Coder-14B-Instruct е мащабен предварително обучен модел за програмиране с отлични способности за разбиране и генериране на код. Ефективно се справя с широк спектър от програмни задачи, идеален за интелигентно програмиране, автоматично генериране на скриптове и въпроси и отговори, свързани с програмиране.",
|
||||
"Qwen2.5-Coder-32B-Instruct.description": "Разширен LLM за генериране на код, логическо разсъждение и отстраняване на грешки на основните програмни езици.",
|
||||
"Qwen3-235B-A22B-Instruct-2507-FP8.description": "Qwen3 235B A22B Instruct 2507 е оптимизиран за напреднало разсъждение и следване на инструкции, използвайки MoE за ефективно мащабиране на разсъждението.",
|
||||
"Qwen3-235B.description": "Qwen3-235B-A22B е MoE модел, който въвежда хибриден режим на разсъждение, позволяващ на потребителите да превключват безпроблемно между мислещ и немислещ режим. Поддържа разбиране и разсъждение на 119 езика и диалекта и има силни възможности за извикване на инструменти, конкурирайки се с водещи модели като DeepSeek R1, OpenAI o1, o3-mini, Grok 3 и Google Gemini 2.5 Pro в бенчмаркове за общи способности, програмиране и математика, многоезичност и логическо разсъждение.",
|
||||
"Qwen3-32B.description": "Qwen3-32B е плътен модел, който въвежда хибриден режим на разсъждение, позволяващ на потребителите да превключват между мислещ и немислещ режим. С архитектурни подобрения, повече данни и по-добро обучение, той се представя наравно с Qwen2.5-72B.",
|
||||
"Qwen3.5-Plus.description": "Qwen3.5 Plus поддържа текст, изображения и видео. Представянето му при чисто текстови задачи е сравнимо с Qwen3 Max, но е по-ефективно и по-евтино. Мултимодалните му способности са значително подобрени спрямо серията Qwen3 VL.",
|
||||
"Ring-2.5-1T.description": "В сравнение с предишно издадения Ring-1T, Ring-2.5-1T постига значителни подобрения в три ключови измерения: ефективност на генериране, дълбочина на разсъждения и способност за изпълнение на задачи с дълъг хоризонт: **Ефективност на генериране**: Чрез използване на голям дял линейни механизми за внимание, Ring-2.5-1T намалява разходите за достъп до паметта с повече от 10×. При обработка на последователности, надвишаващи 32K токена, той осигурява над 3× по-висока производителност на генериране, което го прави особено подходящ за дълбоки разсъждения и изпълнение на задачи с дълъг хоризонт. **Дълбоки разсъждения**: Въз основа на RLVR, се въвежда плътен механизъм за награди, който предоставя обратна връзка за строгостта на процеса на разсъждение. Това позволява на Ring-2.5-1T да постигне златен медал в IMO 2025 и CMO 2025 (самооценка). **Изпълнение на задачи с дълъг хоризонт**: Чрез мащабно напълно асинхронно обучение с подсилване, базирано на агенти, моделът значително подобрява способността си да изпълнява сложни задачи автономно за продължителни периоди. Това позволява на Ring-2.5-1T да се интегрира безпроблемно с рамки за програмиране на агенти като Claude Code и OpenClaw лични AI асистенти.",
|
||||
"Ring-2.6-1T.description": "Ring-2.6-1T е модел за разсъждение с мащаб от трилион параметри, който активира приблизително 63B параметри на извод. Проектиран за работни процеси с агенти, той се фокусира върху способности на агенти, използване на инструменти и изпълнение на задачи с дълъг хоризонт, постигайки водещи резултати на бенчмаркове като PinchBench, ClawEval, TAU2-Bench и GAIA2-search. Моделът е оптимизиран по отношение на качество на изпълнение, латентност и разходи, което го прави подходящ за напреднали агенти за програмиране, сложни разсъждения и мащабни автономни системи.",
|
||||
"S2V-01.description": "Основният модел за преобразуване на референция във видео от серията 01.",
|
||||
"SenseChat-128K.description": "Базов модел V4 с контекст от 128K, силен в разбиране и генериране на дълги текстове.",
|
||||
"SenseChat-32K.description": "Базов модел V4 с контекст от 32K, гъвкав за различни сценарии.",
|
||||
"SenseChat-5-1202.description": "Най-новата версия, базирана на V5.5, с значителни подобрения в основни знания по китайски/английски, чат, STEM, хуманитарни науки, писане, математика/логика и контрол на дължината.",
|
||||
"SenseChat-5-Cantonese.description": "Проектиран за диалектни навици, жаргон и местни знания в Хонконг; надминава GPT-4 в разбирането на кантонски и съперничи на GPT-4 Turbo в знания, логика, математика и програмиране.",
|
||||
"SenseChat-5-beta.description": "Някои показатели надвишават тези на SenseChat-5-1202.",
|
||||
"SenseChat-5.description": "Най-новият V5.5 с контекст от 128K; значителни подобрения в математическо разсъждение, чат на английски, следване на инструкции и разбиране на дълги текстове, сравним с GPT-4o.",
|
||||
"SenseChat-Character-Pro.description": "Разширен модел за чат с персонажи с контекст от 32K, подобрени възможности и поддръжка на китайски/английски.",
|
||||
"SenseChat-Character.description": "Стандартен модел за чат с персонажи с контекст от 8K и висока скорост на отговор.",
|
||||
"SenseChat-Turbo-1202.description": "Най-новият лек модел, достигащ над 90% от възможностите на пълния модел с значително по-ниска цена за инференция.",
|
||||
"SenseChat-Turbo.description": "Подходящ за бързи въпроси и отговори и сценарии за фина настройка на модели.",
|
||||
"SenseChat-Vision.description": "Най-новият V5.5 с вход от множество изображения и широки основни подобрения в разпознаване на атрибути, пространствени отношения, действия/събития, разбиране на сцени, разпознаване на емоции, логическо разсъждение и разбиране/генериране на текст.",
|
||||
"SenseChat.description": "Базов модел V4 с контекст от 4K и силни общи възможности.",
|
||||
"SenseNova-V6-5-Pro.description": "Със значителни подобрения в мултимодалните, езиковите и логическите данни, както и с оптимизация на стратегията за обучение, новият модел значително подобрява мултимодалното разсъждение и следването на обобщени инструкции, поддържа контекстен прозорец до 128k и се отличава в задачи по OCR и разпознаване на културен и туристически IP.",
|
||||
"SenseNova-V6-5-Turbo.description": "Със значителни подобрения в мултимодалните, езиковите и логическите данни, както и с оптимизация на стратегията за обучение, новият модел значително подобрява мултимодалното разсъждение и следването на обобщени инструкции, поддържа контекстен прозорец до 128k и се отличава в задачи по OCR и разпознаване на културен и туристически IP.",
|
||||
"SenseNova-V6-Pro.description": "Нативно обединява изображение, текст и видео, преодолявайки традиционните мултимодални ограничения; заема водещи позиции в OpenCompass и SuperCLUE.",
|
||||
"SenseNova-V6-Reasoner.description": "Комбинира дълбоко разсъждение чрез зрение и език, поддържа бавно мислене и пълна верига на мисълта.",
|
||||
"SenseNova-V6-Turbo.description": "Нативно обединява изображение, текст и видео, преодолявайки традиционните мултимодални ограничения. Води в основните мултимодални и езикови възможности и заема челни позиции в множество оценки.",
|
||||
"Skylark2-lite-8k.description": "Модел от второ поколение Skylark. Skylark2-lite осигурява бързи отговори за реалновремеви, чувствителни към разходите сценарии с по-ниски изисквания за точност, с контекстен прозорец от 8K.",
|
||||
"Skylark2-pro-32k.description": "Модел от второ поколение Skylark. Skylark2-pro предлага по-висока точност за сложни задачи по генериране на текст като професионално копирайтинг, писане на романи и висококачествен превод, с контекстен прозорец от 32K.",
|
||||
"Skylark2-pro-4k.description": "Модел от второ поколение Skylark. Skylark2-pro предлага по-висока точност за сложни задачи по генериране на текст като професионално копирайтинг, писане на романи и висококачествен превод, с контекстен прозорец от 4K.",
|
||||
@@ -1197,6 +1179,8 @@
|
||||
"r1-1776.description": "R1-1776 е дообучен вариант на DeepSeek R1, създаден да предоставя неконфронтирана, обективна и фактическа информация.",
|
||||
"seedance-1-5-pro-251215.description": "Seedance 1.5 Pro от ByteDance поддържа текст-към-видео, изображение-към-видео (първи кадър, първи+последен кадър) и генериране на аудио, синхронизирано с визуализации.",
|
||||
"seedream-5-0-260128.description": "ByteDance-Seedream-5.0-lite от BytePlus предлага генериране, обогатено с уеб извличане за реална информация, подобрена интерпретация на сложни подканвания и подобрена консистентност на референциите за професионално визуално създаване.",
|
||||
"sensenova-6.7-flash-lite.description": "Лек мултимодален модел за агенти, проектиран за реални работни процеси, поддържащ както текстови разговори, така и разбиране на изображения. Лек и ефективен, балансиращ производителност, разходи и възможност за внедряване. Нативна мултимодална архитектура с поддръжка за разбиране на изображения, включително OCR и интерпретация на графики. Подобрен за офис и продуктивни сценарии, със стабилна поддръжка за сложни задачи с дълга верига. Подобрена ефективност на токените, позволяваща по-добър контрол на разходите за сложни работни натоварвания. Контекстна дължина от 256K токена (максимален вход: 252K, максимален изход: 64K).",
|
||||
"sensenova-u1-fast.description": "Ускорена версия, базирана на SenseNova U1, специално оптимизирана за генериране на инфографики.",
|
||||
"solar-mini-ja.description": "Solar Mini (Ja) разширява Solar Mini с фокус върху японски език, като запазва ефективността и силната производителност на английски и корейски.",
|
||||
"solar-mini.description": "Solar Mini е компактен LLM, който превъзхожда GPT-3.5, с мощни многоезични възможности, поддържащ английски и корейски, и предлага ефективно решение с малък отпечатък.",
|
||||
"solar-pro.description": "Solar Pro е интелигентен LLM от Upstage, фокусиран върху следване на инструкции на един GPU, с IFEval резултати над 80. Понастоящем поддържа английски; пълното издание е планирано за ноември 2024 с разширена езикова поддръжка и по-дълъг контекст.",
|
||||
|
||||
@@ -17,6 +17,8 @@
|
||||
"storage_overage_cap_reached_title": "Достигнат лимит за плащане според използваното хранилище",
|
||||
"video_generation_completed": "Вашето видео \"{{prompt}}\" е готово.",
|
||||
"video_generation_completed_title": "Генерирането на видеото завърши",
|
||||
"workspace_member_invited": "{{inviterLabel}} ви покани да се присъедините към работното пространство \"{{workspaceName}}\" като {{role}}.",
|
||||
"workspace_member_invited_title": "Покана за присъединяване към {{workspaceName}}",
|
||||
"workspace_member_joined": "{{memberLabel}} се присъедини към работното пространство \"{{workspaceName}}\" като {{role}}.",
|
||||
"workspace_member_joined_member": "{{memberLabel}} се присъедини към работното пространство \"{{workspaceName}}\" като Член.",
|
||||
"workspace_member_joined_member_title": "Нов член се присъедини към {{workspaceName}}",
|
||||
|
||||
@@ -1,6 +1,34 @@
|
||||
{
|
||||
"arguments.moreParams": "{{count}} параметъра общо",
|
||||
"arguments.title": "Аргументи",
|
||||
"builtins.codex.apiName.collab_tool_call": "Координиране на подагенти",
|
||||
"builtins.codex.apiName.command_execution": "Изпълни команда",
|
||||
"builtins.codex.apiName.file_change": "Редактиране на файлове",
|
||||
"builtins.codex.apiName.mcp_tool_call": "Извикване на MCP инструмент",
|
||||
"builtins.codex.apiName.todo_list": "Актуализиране на задачи",
|
||||
"builtins.codex.apiName.web_search": "Търсене в интернет",
|
||||
"builtins.codex.collabTool.agentCount_one": "{{count}} подагент",
|
||||
"builtins.codex.collabTool.agentCount_other": "{{count}} подагенти",
|
||||
"builtins.codex.collabTool.agentLabel": "Подагент {{index}}",
|
||||
"builtins.codex.collabTool.agents": "Подагенти",
|
||||
"builtins.codex.collabTool.closeAgent": "Затвори подагент",
|
||||
"builtins.codex.collabTool.instruction": "Инструкция",
|
||||
"builtins.codex.collabTool.sendInput": "Съобщение към подагент",
|
||||
"builtins.codex.collabTool.spawnAgent": "Създай подагент",
|
||||
"builtins.codex.collabTool.wait": "Изчакай подагентите",
|
||||
"builtins.codex.commandExecution.grep": "Търсене",
|
||||
"builtins.codex.commandExecution.noResults": "Няма резултати",
|
||||
"builtins.codex.commandExecution.readFile": "Прочети файл",
|
||||
"builtins.codex.fileChange.editedFiles_one": "Редактиран {{count}} файл",
|
||||
"builtins.codex.fileChange.editedFiles_other": "Редактирани {{count}} файла",
|
||||
"builtins.codex.fileChange.editing": "Редактиране на файлове",
|
||||
"builtins.codex.fileChange.noChanges": "Няма промени във файловете",
|
||||
"builtins.codex.fileChange.unknownFile": "Неизвестен файл",
|
||||
"builtins.codex.mcpTool.error": "Грешка",
|
||||
"builtins.codex.mcpTool.input": "Вход",
|
||||
"builtins.codex.mcpTool.result": "Резултат",
|
||||
"builtins.codex.mcpTool.unknownTool": "MCP инструмент",
|
||||
"builtins.codex.webSearch.query": "Запитване",
|
||||
"builtins.lobe-activator.apiName.activateTools": "Активиране на инструменти",
|
||||
"builtins.lobe-activator.inspector.activateTools.notFoundCount": "{{count}} не са намерени",
|
||||
"builtins.lobe-agent-builder.apiName.getAvailableModels": "Извличане на налични модели",
|
||||
@@ -429,6 +457,15 @@
|
||||
"dev.mcp.auth.desc": "Избери метод за удостоверяване за MCP сървъра",
|
||||
"dev.mcp.auth.label": "Тип удостоверяване",
|
||||
"dev.mcp.auth.none": "Без удостоверяване",
|
||||
"dev.mcp.auth.oauth": "OAuth",
|
||||
"dev.mcp.auth.oauth.authorize": "Упълномощи и свържи",
|
||||
"dev.mcp.auth.oauth.clientId.desc": "Оставете празно, за да регистрирате клиент автоматично (динамична регистрация на клиент)",
|
||||
"dev.mcp.auth.oauth.clientId.label": "OAuth клиентски ID",
|
||||
"dev.mcp.auth.oauth.clientId.placeholder": "По избор",
|
||||
"dev.mcp.auth.oauth.clientSecret.desc": "Необходимо само за конфиденциални OAuth клиенти",
|
||||
"dev.mcp.auth.oauth.clientSecret.label": "OAuth клиентска тайна",
|
||||
"dev.mcp.auth.oauth.clientSecret.placeholder": "По избор",
|
||||
"dev.mcp.auth.oauth.redirectHint": "URI за пренасочване, който да регистрирате с вашето OAuth приложение:",
|
||||
"dev.mcp.auth.placeholder": "Избери тип удостоверяване",
|
||||
"dev.mcp.auth.token.desc": "Въведи своя API ключ или Bearer токен",
|
||||
"dev.mcp.auth.token.label": "API ключ",
|
||||
|
||||
@@ -4,6 +4,7 @@
|
||||
"ai360.description": "360 AI е платформа за модели и услуги от 360, предлагаща NLP модели като 360GPT2 Pro, 360GPT Pro и 360GPT Turbo. Моделите съчетават мащабни параметри и мултимодални възможности за генериране на текст, семантично разбиране, чат и код, с гъвкаво ценообразуване за различни нужди.",
|
||||
"aihubmix.description": "AiHubMix предоставя достъп до множество AI модели чрез единен API.",
|
||||
"akashchat.description": "Akash е децентрализиран пазар за облачни ресурси с конкурентни цени спрямо традиционните облачни доставчици.",
|
||||
"antgroup.description": "Ant Ling е основната серия от модели на Ant Group за Инициативата за Изкуствен Общ Интелект (AGI), посветена на изграждането и предоставянето на авангардни възможности на основните модели. Вярваме, че развитието на интелигентността трябва да се движи към откритост, споделяне и мащабируемост—започвайки с малки, практични стъпки за насърчаване на устойчивата еволюция и реалното внедряване на AGI.",
|
||||
"anthropic.description": "Anthropic разработва усъвършенствани езикови модели като Claude 3.5 Sonnet, Claude 3 Sonnet, Claude 3 Opus и Claude 3 Haiku, балансирайки интелигентност, скорост и разходи за различни бизнес и бързи приложения.",
|
||||
"azure.description": "Azure предлага усъвършенствани AI модели, включително сериите GPT-3.5 и GPT-4, за разнообразни типове данни и сложни задачи с фокус върху безопасен, надежден и устойчив AI.",
|
||||
"azureai.description": "Azure предоставя усъвършенствани AI модели, включително сериите GPT-3.5 и GPT-4, за разнообразни типове данни и сложни задачи с акцент върху безопасен, надежден и устойчив AI.",
|
||||
|
||||
@@ -280,7 +280,33 @@
|
||||
"defaultAgent.title": "Настройки на агента по подразбиране",
|
||||
"devices.actions.edit": "Редактиране",
|
||||
"devices.actions.remove": "Премахване",
|
||||
"devices.capabilities.commands.desc": "Сигурно изпълнявайте терминални команди във вашата среда.",
|
||||
"devices.capabilities.commands.title": "Изпълнение на команди",
|
||||
"devices.capabilities.files.desc": "Позволете на агентите директен достъп и организиране на файловете на вашия компютър.",
|
||||
"devices.capabilities.files.title": "Четене и запис на локални файлове",
|
||||
"devices.capabilities.title": "Какво можете да правите след свързване",
|
||||
"devices.capabilities.tools.desc": "Свържете локални инструменти, за да разширите възможностите на агентите.",
|
||||
"devices.capabilities.tools.title": "Извикване на системни инструменти",
|
||||
"devices.channel.connected": "Свързан {{time}}",
|
||||
"devices.connectWizard.button": "Свържете устройство",
|
||||
"devices.connectWizard.cli.connectDesc": "Стартирайте фоновия демон, за да поддържате устройството онлайн и готово за отдалечени операции.",
|
||||
"devices.connectWizard.cli.connectTitle": "Стартиране на демона",
|
||||
"devices.connectWizard.cli.installDesc": "Инсталирайте LobeHub CLI глобално с предпочитания от вас пакетен мениджър, за да активирате свързаност и управление на устройството.",
|
||||
"devices.connectWizard.cli.installTitle": "Инсталирайте CLI",
|
||||
"devices.connectWizard.cli.loginDesc": "Завършете OAuth авторизацията в браузъра си, за да свържете CLI с вашия акаунт.",
|
||||
"devices.connectWizard.cli.loginTitle": "Вход",
|
||||
"devices.connectWizard.desktop.downloadLink": "Изтеглете LobeHub Desktop",
|
||||
"devices.connectWizard.desktop.step1": "Изтеглете десктоп приложението",
|
||||
"devices.connectWizard.desktop.step1Desc": "Посетете страницата за изтегляния на LobeHub и изтеглете приложението за вашата операционна система.",
|
||||
"devices.connectWizard.desktop.step2": "Влезте и отворете шлюза за устройства",
|
||||
"devices.connectWizard.desktop.step2Desc": "След като влезете, кликнете върху иконата на шлюза за устройства в горния десен ъгъл и потвърдете, че е включен.",
|
||||
"devices.connectWizard.desktop.step3": "Вашето устройство се появява автоматично",
|
||||
"devices.connectWizard.desktop.step3Desc": "Десктоп приложението се регистрира като устройство при стартиране — ще го видите в списъка след свързване.",
|
||||
"devices.connectWizard.footer": "Само метаданни за устройството се регистрират — вашите данни никога не се достъпват.",
|
||||
"devices.connectWizard.method.cli": "Чрез CLI",
|
||||
"devices.connectWizard.method.desktop": "Чрез десктоп",
|
||||
"devices.connectWizard.subtitle": "Изберете как да свържете компютъра си с LobeHub.",
|
||||
"devices.connectWizard.title": "Свържете устройство",
|
||||
"devices.currentBadge": "Това устройство",
|
||||
"devices.detail.addDir": "Добавяне на директория",
|
||||
"devices.detail.connections": "Връзки",
|
||||
@@ -294,7 +320,13 @@
|
||||
"devices.edit.friendlyNamePlaceholder": "Име за разпознаване на това устройство",
|
||||
"devices.edit.save": "Запазване",
|
||||
"devices.edit.title": "Редактиране на устройство",
|
||||
"devices.empty": "Все още няма устройства. Свържете едно с `lh connect` или чрез влизане в десктоп приложението.",
|
||||
"devices.empty.desc": "След свързване, агентите на LobeHub могат да четат/записват файлове, изпълняват команди и извикват системни инструменти директно на вашия компютър.",
|
||||
"devices.empty.methodCli.desc": "Инсталирайте CLI в терминала си — идеално за сървъри или машини без графичен интерфейс.",
|
||||
"devices.empty.methodCli.title": "Свързване чрез CLI",
|
||||
"devices.empty.methodDesktop.badge": "Препоръчително",
|
||||
"devices.empty.methodDesktop.desc": "Изтеглете десктоп приложението, влезте и устройството ви ще се свърже автоматично.",
|
||||
"devices.empty.methodDesktop.title": "Свързване чрез десктоп",
|
||||
"devices.empty.title": "Свържете първото си устройство",
|
||||
"devices.fallbackBadge": "Нестабилна идентичност",
|
||||
"devices.fallbackTooltip": "Това устройство не може да бъде идентифицирано чрез неговия машинен ID, така че преинсталирането на приложението може да създаде дублиран запис.",
|
||||
"devices.lastSeen": "Последно активно {{time}}",
|
||||
@@ -522,6 +554,7 @@
|
||||
"notification.item.image_generation_completed": "Генерирането на изображение завърши",
|
||||
"notification.item.storage_overage_cap_reached": "Достигнат лимит за допълнително съхранение",
|
||||
"notification.item.video_generation_completed": "Генерирането на видео завърши",
|
||||
"notification.item.workspace_member_invited": "Покана за работно пространство",
|
||||
"notification.item.workspace_member_joined": "Нов член се присъедини",
|
||||
"notification.item.workspace_member_removed": "Премахнат от работното пространство",
|
||||
"notification.item.workspace_payment_failed": "Неуспешно плащане за подновяване",
|
||||
@@ -1766,6 +1799,7 @@
|
||||
"workspace.members.invite.errors.alreadyMember": "{{email}} вече е член на това работно пространство.",
|
||||
"workspace.members.invite.failed": "Неуспешно изпращане на покана",
|
||||
"workspace.members.invite.limitReached": "Това работно пространство може да има до {{limit}} членове. Премахнете член преди да поканите повече.",
|
||||
"workspace.members.invite.modal.billIncrease": "Вашата сметка ще се увеличи с ${{amount}}/месец.",
|
||||
"workspace.members.invite.modal.cancel": "Отказ",
|
||||
"workspace.members.invite.modal.confirm": "Потвърждение",
|
||||
"workspace.members.invite.modal.description_one": "Вашият екип се разширява! С потвърждение ще поканите 1 нов член на екипа в това работно пространство.",
|
||||
@@ -1873,6 +1907,7 @@
|
||||
"workspace.upgradeModal.chargeDisclosure": "При щракване върху Надграждане, ще бъдете таксувани ${{fee}}, плюс всички приложими данъци и такси, незабавно и след това всеки месец, докато не отмените. Таксите за места и използване при поискване се уреждат в края на месеца; ако вашето използване надвиши прага за фактуриране по време на цикъл, вашият метод на плащане може да бъде таксуван преди края на цикъла.",
|
||||
"workspace.upgradeModal.continueCta": "Продължете",
|
||||
"workspace.upgradeModal.createTeam": "Създайте работно пространство",
|
||||
"workspace.upgradeModal.formDescription": "Прегледайте подробностите по-долу и потвърдете надграждането си.",
|
||||
"workspace.upgradeModal.formSubtitle": "Днес се таксува само платформената такса — таксите за места се уреждат в края на месеца.",
|
||||
"workspace.upgradeModal.formTitle": "Надградете {{name}} до Pro",
|
||||
"workspace.upgradeModal.heading": "Надградете работно пространство до Pro",
|
||||
|
||||
@@ -15,6 +15,8 @@
|
||||
"agentBuilder.installPlugin.retry": "Erneut versuchen",
|
||||
"agentBuilder.title": "Agenten-Builder",
|
||||
"agentBuilder.welcome": "Erzählen Sie mir von Ihrem Anwendungsfall.\n\nSchreiben, Programmieren oder Datenanalyse – alles ist möglich. Sie bestimmen Ziel und Standards; ich zerlege es in kollaborative, ausführbare Agenten.",
|
||||
"agentConfigError.retry": "Wiederholen",
|
||||
"agentConfigError.title": "Agenteneinstellungen konnten nicht geladen werden",
|
||||
"agentDefaultMessage": "Hallo, ich bin **{{name}}**. Ein Satz genügt.\n\nMöchten Sie, dass ich besser zu Ihrem Arbeitsablauf passe? Gehen Sie zu [Agenteneinstellungen]({{url}}) und füllen Sie das Agentenprofil aus (Sie können es jederzeit bearbeiten).",
|
||||
"agentDefaultMessageWithSystemRole": "Hallo, ich bin **{{name}}**. Ein Satz genügt – Sie haben die Kontrolle.",
|
||||
"agentDefaultMessageWithoutEdit": "Hallo, ich bin **{{name}}**. Ein Satz genügt – Sie haben die Kontrolle.",
|
||||
@@ -252,6 +254,10 @@
|
||||
"input.costEstimate.tooltip": "Geschätzt basierend auf aktuellem Kontext, Tools und Modellpreisen. Tatsächliche Kosten können abweichen.",
|
||||
"input.disclaimer": "Agenten können Fehler machen. Verwenden Sie Ihr Urteilsvermögen bei kritischen Informationen.",
|
||||
"input.errorMsg": "Senden fehlgeschlagen: {{errorMsg}}. Versuchen Sie es erneut oder später.",
|
||||
"input.inputCompletionError.desc": "Eingabevorschläge wurden nach einem Fehler gestoppt. Wiederholen Sie den Vorgang oder passen Sie das Vorschlagsmodell in den Einstellungen an.",
|
||||
"input.inputCompletionError.retry": "Wiederholen",
|
||||
"input.inputCompletionError.settings": "Einstellungen",
|
||||
"input.inputCompletionError.title": "Eingabevorschläge pausiert",
|
||||
"input.more": "Mehr",
|
||||
"input.send": "Senden",
|
||||
"input.sendWithCmdEnter": "Drücken Sie <key/>, um zu senden",
|
||||
@@ -915,6 +921,7 @@
|
||||
"workflow.toolDisplayName.addPreferenceMemory": "Gespeicherte Erinnerung",
|
||||
"workflow.toolDisplayName.calculate": "Berechnet",
|
||||
"workflow.toolDisplayName.callAgent": "Agent wurde aufgerufen",
|
||||
"workflow.toolDisplayName.callMcpTool": "MCP-Tool aufgerufen",
|
||||
"workflow.toolDisplayName.callSubAgent": "Ein Sub-Agent wurde gestartet",
|
||||
"workflow.toolDisplayName.clearTodos": "Todos gelöscht",
|
||||
"workflow.toolDisplayName.copyDocument": "Ein Dokument wurde kopiert",
|
||||
@@ -1005,7 +1012,9 @@
|
||||
"workingPanel.localFile.closeRight": "Rechts schließen",
|
||||
"workingPanel.localFile.error": "Diese Datei konnte nicht geladen werden",
|
||||
"workingPanel.localFile.preview.raw": "Rohdaten",
|
||||
"workingPanel.localFile.preview.reload": "Vorschau neu laden",
|
||||
"workingPanel.localFile.preview.render": "Vorschau",
|
||||
"workingPanel.localFile.preview.source": "Quelle",
|
||||
"workingPanel.localFile.truncated": "Dateivorschau auf {{limit}} Zeichen gekürzt",
|
||||
"workingPanel.progress": "Progress",
|
||||
"workingPanel.progress.allCompleted": "All tasks completed",
|
||||
|
||||
@@ -239,6 +239,7 @@
|
||||
"providerModels.item.modelConfig.extendParams.options.reasoningBudgetToken32k.hint": "Für GLM-5 und GLM-4.7; steuert das Token-Budget für das logische Denken (max. 32k).",
|
||||
"providerModels.item.modelConfig.extendParams.options.reasoningBudgetToken80k.hint": "Für die Qwen3-Serie; steuert das Token-Budget für das logische Denken (max. 80k).",
|
||||
"providerModels.item.modelConfig.extendParams.options.reasoningEffort.hint": "Für OpenAI und andere Modelle mit Denkfähigkeit; steuert den Denkaufwand.",
|
||||
"providerModels.item.modelConfig.extendParams.options.ring2_6ReasoningEffort.hint": "Für die Ring 2.6-Serie; steuert die Intensität des Denkprozesses.",
|
||||
"providerModels.item.modelConfig.extendParams.options.step3_5ReasoningEffort.hint": "Für die Step 3.5-Serie; steuert die Intensität der Argumentation.",
|
||||
"providerModels.item.modelConfig.extendParams.options.textVerbosity.hint": "Für die GPT-5+-Serie; steuert die Ausführlichkeit der Ausgabe.",
|
||||
"providerModels.item.modelConfig.extendParams.options.thinking.hint": "Für einige Doubao-Modelle; erlaubt dem Modell zu entscheiden, ob es tiefgründig denken soll.",
|
||||
|
||||
+12
-28
@@ -27,15 +27,15 @@
|
||||
"DeepSeek-OCR.description": "DeepSeek-OCR ist ein Vision-Language-Modell von DeepSeek AI, das sich auf OCR und „Context Optical Compression“ konzentriert. Es erforscht die Komprimierung von Kontext aus Bildern, verarbeitet Dokumente effizient und wandelt sie in strukturierten Text (z. B. Markdown) um. Es erkennt Text in Bildern präzise und eignet sich für die Dokumentendigitalisierung, Textextraktion und strukturierte Verarbeitung.",
|
||||
"DeepSeek-R1-Distill-Llama-70B.description": "DeepSeek R1, das größere und intelligentere Modell der DeepSeek-Reihe, wurde in die Llama-70B-Architektur destilliert. Benchmarks und menschliche Bewertungen zeigen, dass es intelligenter ist als das ursprüngliche Llama-70B, insbesondere bei Mathematik- und Faktenaufgaben.",
|
||||
"DeepSeek-R1-Distill-Qwen-1.5B.description": "Ein aus Qwen2.5-Math-1.5B destilliertes DeepSeek-R1-Modell. Verstärkendes Lernen und Cold-Start-Daten optimieren die Denkleistung und setzen neue Maßstäbe für offene Multitasking-Modelle.",
|
||||
"DeepSeek-R1-Distill-Qwen-14B.description": "DeepSeek-R1-Distill-Modelle sind feinabgestimmte Versionen quelloffener Modelle, die mit von DeepSeek-R1 generierten Beispieldaten trainiert wurden.",
|
||||
"DeepSeek-R1-Distill-Qwen-32B.description": "DeepSeek-R1-Distill-Modelle sind feinabgestimmte Versionen quelloffener Modelle, die mit von DeepSeek-R1 generierten Beispieldaten trainiert wurden.",
|
||||
"DeepSeek-R1-Distill-Qwen-14B.description": "Ein DeepSeek-R1 destilliertes Modell basierend auf Qwen2.5-14B. Verstärkungslernen und Cold-Start-Daten optimieren die Argumentationsleistung und setzen neue Multi-Task-Benchmarks für offene Modelle.",
|
||||
"DeepSeek-R1-Distill-Qwen-32B.description": "Die DeepSeek-R1-Serie verbessert die Argumentationsleistung durch Verstärkungslernen und Cold-Start-Daten, setzt neue Multi-Task-Benchmarks für offene Modelle und übertrifft OpenAI o1-mini.",
|
||||
"DeepSeek-R1-Distill-Qwen-7B.description": "Ein aus Qwen2.5-Math-7B destilliertes DeepSeek-R1-Modell. Verstärkendes Lernen und Cold-Start-Daten optimieren die Denkleistung und setzen neue Maßstäbe für offene Multitasking-Modelle.",
|
||||
"DeepSeek-R1.description": "DeepSeek-R1 nutzt großflächiges Reinforcement Learning in der Nachtrainingsphase, um das logische Denken mit sehr wenig beschrifteten Daten deutlich zu verbessern. Es erreicht vergleichbare Leistungen wie das OpenAI o1-Produktionsmodell bei Mathematik-, Programmier- und Sprachverständnisaufgaben.",
|
||||
"DeepSeek-R1.description": "Effizientes LLM auf dem neuesten Stand der Technik, stark in Argumentation, Mathematik und Programmierung.",
|
||||
"DeepSeek-V3-1.description": "DeepSeek V3.1 ist ein Modell der nächsten Generation für logisches Denken mit verbessertem komplexem Schlussfolgern und Gedankenkette, geeignet für tiefgreifende Analyseaufgaben.",
|
||||
"DeepSeek-V3-Fast.description": "Anbieter: sophnet. DeepSeek V3 Fast ist die Hoch-TPS-Version von DeepSeek V3 0324, in voller Präzision (nicht quantisiert) mit stärkerer Leistung bei Code und Mathematik sowie schnelleren Antworten.",
|
||||
"DeepSeek-V3.1-Think.description": "DeepSeek-V3.1 Denkmodus: Ein neues hybrides Denkmodell mit Denk- und Nicht-Denk-Modi, effizienter als DeepSeek-R1-0528. Nachtrainingsoptimierungen verbessern die Toolnutzung und Agentenleistung erheblich.",
|
||||
"DeepSeek-V3.2.description": "deepseek-v3.2 führt einen Sparse-Attention-Mechanismus ein, um die Trainings- und Inferenzeffizienz bei der Verarbeitung langer Texte zu verbessern und bietet gleichzeitig geringere Kosten als deepseek-v3.1.",
|
||||
"DeepSeek-V3.description": "DeepSeek-V3 ist ein MoE-Modell, das von DeepSeek entwickelt wurde. Es übertrifft andere offene Modelle wie Qwen2.5-72B und Llama-3.1-405B in vielen Benchmarks und ist konkurrenzfähig mit führenden geschlossenen Modellen wie GPT-4o und Claude 3.5 Sonnet.",
|
||||
"DeepSeek-V3.description": "Die offene Bereitstellung von ByteDance Volcengine ist derzeit die stabilste; empfohlen. Es wurde automatisch auf die neueste Version (250324) aktualisiert.",
|
||||
"Doubao-lite-128k.description": "Doubao-lite bietet ultraschnelle Antworten und ein hervorragendes Preis-Leistungs-Verhältnis mit flexiblen Optionen für verschiedene Szenarien. Unterstützt 128K Kontext für Inferenz und Feinabstimmung.",
|
||||
"Doubao-lite-32k.description": "Doubao-lite bietet ultraschnelle Antworten und ein hervorragendes Preis-Leistungs-Verhältnis mit flexiblen Optionen für verschiedene Szenarien. Unterstützt 32K Kontext für Inferenz und Feinabstimmung.",
|
||||
"Doubao-lite-4k.description": "Doubao-lite bietet ultraschnelle Antworten und ein hervorragendes Preis-Leistungs-Verhältnis mit flexiblen Optionen für verschiedene Szenarien. Unterstützt 4K Kontext für Inferenz und Feinabstimmung.",
|
||||
@@ -83,13 +83,12 @@
|
||||
"Kimi-K2.5.description": "Kimi K2.5 ist das leistungsfähigste Kimi-Modell und liefert Open-Source‑SOTA in Agent-Aufgaben, Codierung und visuellem Verständnis. Es unterstützt multimodale Eingaben sowie Thinking- und Non-Thinking-Modi.",
|
||||
"Kolors.description": "Kolors ist ein Text-zu-Bild-Modell, entwickelt vom Kuaishou-Kolors-Team. Mit Milliarden von Parametern trainiert, bietet es herausragende visuelle Qualität, starkes Verständnis chinesischer Semantik und präzise Textdarstellung.",
|
||||
"Kwai-Kolors/Kolors.description": "Kolors ist ein großskaliges Latent-Diffusion-Text-zu-Bild-Modell des Kuaishou-Kolors-Teams. Trainiert auf Milliarden Text-Bild-Paaren, überzeugt es durch visuelle Qualität, semantische Präzision und Textdarstellung in Chinesisch und Englisch. Es bietet starkes Verständnis und Generierung chinesischer Inhalte.",
|
||||
"Ling-2.5-1T.description": "Als neuestes Flaggschiff-Echtzeitmodell der Ling-Serie führt Ling-2.5-1T umfassende Verbesserungen in der Modellarchitektur, Token-Effizienz und Präferenzabstimmung ein, um die Qualität zugänglicher KI auf ein neues Niveau zu heben.",
|
||||
"Ling-2.6-1T.description": "Das neueste Flaggschiff-Großsprachmodell, das Unterstützung für ein Kontextfenster mit 1M-Token bietet und einen End-to-End-Workflow von logischer Argumentation bis zur Aufgabenbearbeitung ermöglicht.",
|
||||
"Ling-2.6-flash.description": "Ling-2.6-flash ist das neueste Hochleistungsmodell der Ling-Serie. Es verwendet eine Mixture-of-Experts (MoE)-Architektur mit einer Gesamtanzahl von 100B Parametern und 6,1B aktivierten Parametern pro Token, wodurch ein optimales Gleichgewicht zwischen Inferenzleistung und Rechenkosten erreicht wird.",
|
||||
"Llama-3.2-11B-Vision-Instruct.description": "Starkes Bildverständnis bei hochauflösenden Bildern, ideal für visuelle Analyseanwendungen.",
|
||||
"Llama-3.2-90B-Vision-Instruct\t.description": "Fortgeschrittenes Bildverständnis für visuelle Agentenanwendungen.",
|
||||
"Llama-3.2-90B-Vision-Instruct.description": "Fortgeschrittene Bildargumentation für Anwendungen mit visuellen Verständnisagenten.",
|
||||
"LongCat-2.0-Preview.description": "Die Kernfunktionen von LongCat-2.0-Preview sind: Für Agentenentwicklungs-Szenarien konzipiert, mit nativer Unterstützung für Tool-Nutzung, mehrstufiges Reasoning und Langkontext-Aufgaben; Hervorragend in Codegenerierung, automatisierten Workflows und komplexer Ausführung von Anweisungen; Tief integriert mit Produktivitätstools wie Claude Code, OpenClaw, OpenCode und Kilo Code.",
|
||||
"LongCat-Flash-Chat.description": "Das LongCat-Flash-Chat-Modell wurde auf eine neue Version aktualisiert. Dieses Update umfasst ausschließlich Verbesserungen der Modellfähigkeiten; der Modellname und die API-Aufrufmethode bleiben unverändert. Aufbauend auf den Markenzeichen „extreme Effizienz“ und „blitzschnelle Reaktion“ stärkt die neue Version das kontextuelle Verständnis und die Leistung bei realen Programmieraufgaben weiter: Deutlich verbesserte Codierungsfähigkeiten: Tief optimiert für entwicklerzentrierte Szenarien, bietet das Modell erhebliche Verbesserungen bei Codegenerierung, Debugging und Erklärung. Entwickler werden dringend ermutigt, diese Verbesserungen zu bewerten und zu testen. Unterstützung für 256K Ultra-Lange Kontexte: Das Kontextfenster wurde von der vorherigen Generation (128K) auf 256K verdoppelt, was eine effiziente Verarbeitung massiver Dokumente und langwieriger Aufgaben ermöglicht. Umfassend verbesserte mehrsprachige Leistung: Bietet starke Unterstützung für neun Sprachen, darunter Spanisch, Französisch, Arabisch, Portugiesisch, Russisch und Indonesisch. Leistungsstärkere Agentenfähigkeiten: Zeigt größere Robustheit und Effizienz bei komplexen Werkzeugaufrufen und mehrstufigen Aufgaben.",
|
||||
"LongCat-Flash-Lite.description": "Das LongCat-Flash-Lite-Modell wurde offiziell veröffentlicht. Es verwendet eine effiziente Mixture-of-Experts (MoE)-Architektur mit insgesamt 68,5 Milliarden Parametern und etwa 3 Milliarden aktivierten Parametern. Durch die Verwendung einer N-Gramm-Einbettungstabelle erreicht es eine hoch effiziente Parameter-Nutzung und ist tief optimiert für Inferenz-Effizienz und spezifische Anwendungsszenarien. Im Vergleich zu Modellen ähnlicher Größe sind seine Kernmerkmale wie folgt: Herausragende Inferenz-Effizienz: Durch die Nutzung der N-Gramm-Einbettungstabelle zur grundlegenden Entlastung des I/O-Engpasses, der MoE-Architekturen innewohnt, kombiniert mit dedizierten Caching-Mechanismen und Kernel-Level-Optimierungen, reduziert es die Inferenz-Latenz erheblich und verbessert die Gesamteffizienz. Starke Agenten- und Code-Leistung: Es zeigt hoch wettbewerbsfähige Fähigkeiten bei Werkzeugaufrufen und Softwareentwicklungsaufgaben und liefert außergewöhnliche Leistung im Verhältnis zu seiner Modellgröße.",
|
||||
"LongCat-Flash-Thinking-2601.description": "Das LongCat-Flash-Thinking-2601-Modell wurde offiziell veröffentlicht. Als ein verbessertes Modell für logisches Denken, das auf einer Mixture-of-Experts (MoE)-Architektur basiert, verfügt es über insgesamt 560 Milliarden Parameter. Während es seine starke Wettbewerbsfähigkeit bei traditionellen Benchmark-Tests für logisches Denken beibehält, verbessert es systematisch die Agenten-Fähigkeiten durch groß angelegtes Multi-Umgebungs-Verstärkungslernen. Im Vergleich zum LongCat-Flash-Thinking-Modell sind die wichtigsten Verbesserungen wie folgt: Extreme Robustheit in lauten Umgebungen: Durch systematisches Curriculum-Training, das auf Lärm und Unsicherheit in realen Szenarien abzielt, zeigt das Modell herausragende Leistung bei Werkzeugaufrufen durch Agenten, Agenten-basierter Suche und Werkzeug-integriertem logischen Denken mit deutlich verbesserter Generalisierung. Leistungsstarke Agenten-Fähigkeiten: Durch den Aufbau eines eng gekoppelten Abhängigkeitsgraphen, der mehr als 60 Werkzeuge umfasst, und die Skalierung des Trainings durch Multi-Umgebungs-Erweiterung und groß angelegtes exploratives Lernen verbessert das Modell seine Fähigkeit, auf komplexe und außerhalb der Verteilung liegende reale Szenarien zu generalisieren. Erweiterter Modus für tiefes Denken: Es erweitert die Breite des logischen Denkens durch parallele Inferenz und vertieft die analytische Fähigkeit durch rekursive, feedbackgesteuerte Zusammenfassungs- und Abstraktionsmechanismen, wodurch hoch anspruchsvolle Probleme effektiv gelöst werden.",
|
||||
"LongCat-Flash-Thinking.description": "Um erstklassige Reasoning-Leistung sicherzustellen, hat die LongCat API-Plattform die Aufrufe des Modells LongCat-Flash-Thinking vereinheitlicht und aktualisiert. Alle bestehenden Anfragen mit `model=LongCat-Flash-Thinking` werden automatisch zur neuesten Version, LongCat-Flash-Thinking-2601, weitergeleitet – ohne erforderliche Codeänderungen.",
|
||||
"M2-her.description": "Ein Textdialogmodell, das für Rollenspiele und mehrstufige Gespräche entwickelt wurde, mit Charakteranpassung und emotionalem Ausdruck.",
|
||||
"Meta-Llama-3-3-70B-Instruct.description": "Llama 3.3 70B ist ein vielseitiges Transformer-Modell für Konversation und Textgenerierung.",
|
||||
"Meta-Llama-3.1-405B-Instruct.description": "Llama 3.1 ist ein instruktionstaugliches Textmodell, optimiert für mehrsprachige Konversation. Es erzielt starke Ergebnisse in gängigen Benchmarks und übertrifft viele offene und geschlossene Chatmodelle.",
|
||||
@@ -187,27 +186,10 @@
|
||||
"Qwen2.5-Coder-14B-Instruct.description": "Qwen2.5-Coder-14B-Instruct ist ein großskaliges, vortrainiertes Modell für Programmieranweisungen mit starker Codeverständnis- und Generierungsfähigkeit. Es bewältigt effizient eine Vielzahl von Programmieraufgaben und eignet sich ideal für intelligentes Codieren, automatisierte Skripterstellung und Programmierfragen.",
|
||||
"Qwen2.5-Coder-32B-Instruct.description": "Fortschrittliches LLM für Codegenerierung, logisches Denken und Fehlerbehebung in gängigen Programmiersprachen.",
|
||||
"Qwen3-235B-A22B-Instruct-2507-FP8.description": "Qwen3 235B A22B Instruct 2507 ist für fortgeschrittenes logisches Denken und Befolgen von Anweisungen optimiert. Es nutzt MoE, um effizientes Denken im großen Maßstab zu ermöglichen.",
|
||||
"Qwen3-235B.description": "Qwen3-235B-A22B ist ein MoE-Modell mit einem hybriden Denkmodus, der es Nutzern ermöglicht, nahtlos zwischen Denk- und Nicht-Denk-Modus zu wechseln. Es unterstützt Verständnis und logisches Denken in 119 Sprachen und Dialekten und verfügt über starke Tool-Calling-Fähigkeiten. Es konkurriert mit führenden Modellen wie DeepSeek R1, OpenAI o1, o3-mini, Grok 3 und Google Gemini 2.5 Pro in Benchmarks zu allgemeinen Fähigkeiten, Programmierung, Mathematik, Mehrsprachigkeit und Wissensverarbeitung.",
|
||||
"Qwen3-32B.description": "Qwen3-32B ist ein dichtes Modell mit einem hybriden Denkmodus, der Nutzern erlaubt, zwischen Denk- und Nicht-Denk-Modus zu wechseln. Durch Verbesserungen in der Architektur, mehr Trainingsdaten und besseres Training erreicht es eine Leistung auf dem Niveau von Qwen2.5-72B.",
|
||||
"Qwen3.5-Plus.description": "Qwen3.5 Plus unterstützt Text-, Bild- und Videoeingaben. Die Leistung bei reinen Textaufgaben ist vergleichbar mit Qwen3 Max, jedoch mit besseren Ergebnissen und niedrigeren Kosten. Seine multimodalen Fähigkeiten sind deutlich verbessert gegenüber der Qwen3-VL-Serie.",
|
||||
"Ring-2.5-1T.description": "Im Vergleich zum zuvor veröffentlichten Ring-1T erzielt Ring-2.5-1T signifikante Verbesserungen in drei Schlüsselbereichen: Generierungseffizienz, Argumentationstiefe und Fähigkeit zur Ausführung von Langzeitaufgaben: **Generierungseffizienz**: Durch die Nutzung eines hohen Anteils linearer Aufmerksamkeitsmechanismen reduziert Ring-2.5-1T den Speicherzugriffsaufwand um mehr als das 10-fache. Beim Verarbeiten von Sequenzen, die 32K Tokens überschreiten, liefert es über 3× höhere Generierungsdurchsätze, was es besonders geeignet für tiefgehende Argumentation und Langzeitaufgaben macht. **Tiefe Argumentation**: Aufbauend auf RLVR wird ein dichtes Belohnungsmechanismus eingeführt, um Feedback zur Strenge des Argumentationsprozesses zu geben. Dies ermöglicht Ring-2.5-1T, Goldmedaillen-Leistungen sowohl bei IMO 2025 als auch CMO 2025 (selbstbewertet) zu erzielen. **Langzeitaufgaben-Ausführung**: Durch groß angelegtes vollständig asynchrones agentenbasiertes Verstärkungslernen verbessert das Modell seine Fähigkeit, komplexe Aufgaben über längere Zeiträume autonom auszuführen. Dies ermöglicht Ring-2.5-1T, nahtlos mit Agenten-Programmierframeworks wie Claude Code und OpenClaw persönlichen KI-Assistenten zu integrieren.",
|
||||
"Ring-2.6-1T.description": "Ring-2.6-1T ist ein Modell im Billionen-Parameter-Maßstab, das etwa 63B Parameter pro Inferenz aktiviert. Entwickelt für Agenten-Workflows, konzentriert es sich auf Agentenfähigkeiten, Werkzeugnutzung und Langzeitaufgaben-Ausführung und erzielt führende Leistungen bei Benchmarks wie PinchBench, ClawEval, TAU2-Bench und GAIA2-Suche. Das Modell ist optimiert hinsichtlich Ausführungsqualität, Latenz und Kosten und eignet sich hervorragend für fortgeschrittene Programmieragenten, komplexe Argumentationspipelines und groß angelegte autonome Systeme.",
|
||||
"S2V-01.description": "Das grundlegende Referenz-zu-Video-Modell der 01-Serie.",
|
||||
"SenseChat-128K.description": "Basisversion V4 mit 128K Kontext, stark im Verständnis und der Generierung von Langtexten.",
|
||||
"SenseChat-32K.description": "Basisversion V4 mit 32K Kontext, flexibel einsetzbar in vielen Szenarien.",
|
||||
"SenseChat-5-1202.description": "Neueste Version basierend auf V5.5 mit deutlichen Verbesserungen in chinesischen/englischen Grundlagen, Konversation, MINT-Wissen, Geisteswissenschaften, Schreiben, Mathematik/Logik und Längenkontrolle.",
|
||||
"SenseChat-5-Cantonese.description": "Entwickelt für den Dialogstil, Slang und das lokale Wissen Hongkongs; übertrifft GPT-4 im Kantonesisch-Verständnis und erreicht GPT-4 Turbo-Niveau in Wissen, logischem Denken, Mathematik und Programmierung.",
|
||||
"SenseChat-5-beta.description": "Teilweise bessere Leistung als SenseChat-5-1202.",
|
||||
"SenseChat-5.description": "Neueste Version V5.5 mit 128K Kontext; große Fortschritte im mathematischen Denken, englischer Konversation, Befolgen von Anweisungen und Langtextverständnis, vergleichbar mit GPT-4o.",
|
||||
"SenseChat-Character-Pro.description": "Fortschrittliches Charakter-Chat-Modell mit 32K Kontext, verbesserter Leistung und Unterstützung für Chinesisch/Englisch.",
|
||||
"SenseChat-Character.description": "Standard-Charakter-Chat-Modell mit 8K Kontext und hoher Antwortgeschwindigkeit.",
|
||||
"SenseChat-Turbo-1202.description": "Neuestes Leichtgewichtsmodell mit über 90 % der Leistung des Vollmodells bei deutlich geringeren Inferenzkosten.",
|
||||
"SenseChat-Turbo.description": "Geeignet für schnelle Frage-Antwort-Szenarien und Modell-Feinabstimmung.",
|
||||
"SenseChat-Vision.description": "Neueste Version V5.5 mit Multi-Image-Eingabe und umfassenden Verbesserungen in Attributerkennung, räumlichen Beziehungen, Aktions-/Ereigniserkennung, Szenenverständnis, Emotionserkennung, Alltagslogik und Textverständnis/-generierung.",
|
||||
"SenseChat.description": "Basisversion V4 mit 4K Kontext und starker allgemeiner Leistungsfähigkeit.",
|
||||
"SenseNova-V6-5-Pro.description": "Mit umfassenden Updates in multimodalen, sprachlichen und logischen Daten sowie optimierter Trainingsstrategie verbessert das neue Modell das multimodale Denken und das allgemeine Befolgen von Anweisungen erheblich. Es unterstützt ein Kontextfenster von bis zu 128k und glänzt bei OCR- und Kultur-/Tourismus-IP-Erkennungsaufgaben.",
|
||||
"SenseNova-V6-5-Turbo.description": "Mit umfassenden Updates in multimodalen, sprachlichen und logischen Daten sowie optimierter Trainingsstrategie verbessert das neue Modell das multimodale Denken und das allgemeine Befolgen von Anweisungen erheblich. Es unterstützt ein Kontextfenster von bis zu 128k und glänzt bei OCR- und Kultur-/Tourismus-IP-Erkennungsaufgaben.",
|
||||
"SenseNova-V6-Pro.description": "Vereint Bild-, Text- und Videodaten nativ und überwindet traditionelle multimodale Grenzen; belegt Spitzenplätze bei OpenCompass und SuperCLUE.",
|
||||
"SenseNova-V6-Reasoner.description": "Kombiniert tiefes logisches Denken in Bild und Sprache, unterstützt langsames Denken und vollständige Gedankengänge.",
|
||||
"SenseNova-V6-Turbo.description": "Vereint Bild-, Text- und Videodaten nativ und überwindet traditionelle multimodale Grenzen. Führend in zentralen multimodalen und sprachlichen Fähigkeiten und rangiert in mehreren Bewertungen in der Spitzengruppe.",
|
||||
"Skylark2-lite-8k.description": "Skylark Modell der 2. Generation. Skylark2-lite bietet schnelle Antworten für Echtzeit- und kostensensitive Szenarien mit geringeren Genauigkeitsanforderungen und einem 8K-Kontextfenster.",
|
||||
"Skylark2-pro-32k.description": "Skylark Modell der 2. Generation. Skylark2-pro bietet höhere Genauigkeit für komplexe Textgenerierung wie professionelle Werbetexte, Romanerstellung und hochwertige Übersetzungen mit einem 32K-Kontextfenster.",
|
||||
"Skylark2-pro-4k.description": "Skylark Modell der 2. Generation. Skylark2-pro bietet höhere Genauigkeit für komplexe Textgenerierung wie professionelle Werbetexte, Romanerstellung und hochwertige Übersetzungen mit einem 4K-Kontextfenster.",
|
||||
@@ -1197,6 +1179,8 @@
|
||||
"r1-1776.description": "R1-1776 ist eine nachtrainierte Variante von DeepSeek R1, die darauf ausgelegt ist, unzensierte, objektive und faktenbasierte Informationen bereitzustellen.",
|
||||
"seedance-1-5-pro-251215.description": "Seedance 1.5 Pro von ByteDance unterstützt Text-zu-Video, Bild-zu-Video (erstes Bild, erstes+letztes Bild) und Audioerzeugung, die mit visuellen Inhalten synchronisiert ist.",
|
||||
"seedream-5-0-260128.description": "ByteDance-Seedream-5.0-lite von BytePlus bietet webgestützte Generierung für Echtzeitinformationen, verbesserte Interpretation komplexer Eingaben und verbesserte Konsistenz von Referenzen für professionelle visuelle Kreationen.",
|
||||
"sensenova-6.7-flash-lite.description": "Ein leichtgewichtiges multimodales Agentenmodell, das für reale Workflows entwickelt wurde und sowohl textbasierte Konversationen als auch Bildverständnis unterstützt. Leicht und effizient, mit einem ausgewogenen Verhältnis von Leistung, Kosten und Einsatzfähigkeit. Native multimodale Architektur mit Unterstützung für Bildverständnis, einschließlich OCR und Diagramminterpretation. Optimiert für Büro- und Produktivitätsszenarien, mit stabiler Unterstützung für komplexe Langzeitaufgaben. Verbesserte Token-Effizienz, die eine bessere Kostenkontrolle für komplexe Workloads ermöglicht. Kontextlänge von 256K Tokens (maximale Eingabe: 252K, maximale Ausgabe: 64K).",
|
||||
"sensenova-u1-fast.description": "Eine beschleunigte Version basierend auf SenseNova U1, speziell optimiert für die Erstellung von Infografiken.",
|
||||
"solar-mini-ja.description": "Solar Mini (Ja) erweitert Solar Mini mit einem Fokus auf Japanisch und behält dabei eine effiziente und starke Leistung in Englisch und Koreanisch bei.",
|
||||
"solar-mini.description": "Solar Mini ist ein kompaktes LLM, das GPT-3.5 übertrifft. Es bietet starke mehrsprachige Fähigkeiten in Englisch und Koreanisch und ist eine effiziente Lösung mit kleinem Ressourcenbedarf.",
|
||||
"solar-pro.description": "Solar Pro ist ein hochintelligentes LLM von Upstage, das auf Befolgen von Anweisungen auf einer einzelnen GPU ausgelegt ist und IFEval-Werte über 80 erreicht. Derzeit wird Englisch unterstützt; die vollständige Veröffentlichung mit erweitertem Sprachsupport und längeren Kontexten war für November 2024 geplant.",
|
||||
|
||||
@@ -17,6 +17,8 @@
|
||||
"storage_overage_cap_reached_title": "Speicher-Limit für nutzungsbasierte Abrechnung erreicht",
|
||||
"video_generation_completed": "Ihr Video „{{prompt}}“ ist fertig.",
|
||||
"video_generation_completed_title": "Videoerstellung abgeschlossen",
|
||||
"workspace_member_invited": "{{inviterLabel}} hat Sie eingeladen, dem Arbeitsbereich \"{{workspaceName}}\" als {{role}} beizutreten.",
|
||||
"workspace_member_invited_title": "Einladung zum Beitritt zu {{workspaceName}}",
|
||||
"workspace_member_joined": "{{memberLabel}} ist dem Arbeitsbereich \"{{workspaceName}}\" als {{role}} beigetreten.",
|
||||
"workspace_member_joined_member": "{{memberLabel}} ist dem Arbeitsbereich \"{{workspaceName}}\" als Mitglied beigetreten.",
|
||||
"workspace_member_joined_member_title": "Neues Mitglied ist {{workspaceName}} beigetreten",
|
||||
|
||||
@@ -1,6 +1,34 @@
|
||||
{
|
||||
"arguments.moreParams": "{{count}} Parameter insgesamt",
|
||||
"arguments.title": "Argumente",
|
||||
"builtins.codex.apiName.collab_tool_call": "Subagenten koordinieren",
|
||||
"builtins.codex.apiName.command_execution": "Befehl ausführen",
|
||||
"builtins.codex.apiName.file_change": "Dateien bearbeiten",
|
||||
"builtins.codex.apiName.mcp_tool_call": "MCP-Tool aufrufen",
|
||||
"builtins.codex.apiName.todo_list": "Aufgaben aktualisieren",
|
||||
"builtins.codex.apiName.web_search": "Im Web suchen",
|
||||
"builtins.codex.collabTool.agentCount_one": "{{count}} Subagent",
|
||||
"builtins.codex.collabTool.agentCount_other": "{{count}} Subagenten",
|
||||
"builtins.codex.collabTool.agentLabel": "Subagent {{index}}",
|
||||
"builtins.codex.collabTool.agents": "Subagenten",
|
||||
"builtins.codex.collabTool.closeAgent": "Subagent schließen",
|
||||
"builtins.codex.collabTool.instruction": "Anweisung",
|
||||
"builtins.codex.collabTool.sendInput": "Subagenten benachrichtigen",
|
||||
"builtins.codex.collabTool.spawnAgent": "Subagent erstellen",
|
||||
"builtins.codex.collabTool.wait": "Auf Subagenten warten",
|
||||
"builtins.codex.commandExecution.grep": "Suchen",
|
||||
"builtins.codex.commandExecution.noResults": "Keine Ergebnisse",
|
||||
"builtins.codex.commandExecution.readFile": "Datei lesen",
|
||||
"builtins.codex.fileChange.editedFiles_one": "{{count}} Datei bearbeitet",
|
||||
"builtins.codex.fileChange.editedFiles_other": "{{count}} Dateien bearbeitet",
|
||||
"builtins.codex.fileChange.editing": "Dateien bearbeiten",
|
||||
"builtins.codex.fileChange.noChanges": "Keine Dateiänderungen",
|
||||
"builtins.codex.fileChange.unknownFile": "Unbekannte Datei",
|
||||
"builtins.codex.mcpTool.error": "Fehler",
|
||||
"builtins.codex.mcpTool.input": "Eingabe",
|
||||
"builtins.codex.mcpTool.result": "Ergebnis",
|
||||
"builtins.codex.mcpTool.unknownTool": "MCP-Tool",
|
||||
"builtins.codex.webSearch.query": "Abfrage",
|
||||
"builtins.lobe-activator.apiName.activateTools": "Werkzeuge aktivieren",
|
||||
"builtins.lobe-activator.inspector.activateTools.notFoundCount": "{{count}} nicht gefunden",
|
||||
"builtins.lobe-agent-builder.apiName.getAvailableModels": "Verfügbare Modelle abrufen",
|
||||
@@ -429,6 +457,15 @@
|
||||
"dev.mcp.auth.desc": "Authentifizierungsmethode für MCP-Server auswählen",
|
||||
"dev.mcp.auth.label": "Auth-Typ",
|
||||
"dev.mcp.auth.none": "Keine Authentifizierung",
|
||||
"dev.mcp.auth.oauth": "OAuth",
|
||||
"dev.mcp.auth.oauth.authorize": "Autorisieren & Verbinden",
|
||||
"dev.mcp.auth.oauth.clientId.desc": "Leer lassen, um einen Client automatisch zu registrieren (dynamische Client-Registrierung)",
|
||||
"dev.mcp.auth.oauth.clientId.label": "OAuth-Client-ID",
|
||||
"dev.mcp.auth.oauth.clientId.placeholder": "Optional",
|
||||
"dev.mcp.auth.oauth.clientSecret.desc": "Nur erforderlich für vertrauliche OAuth-Clients",
|
||||
"dev.mcp.auth.oauth.clientSecret.label": "OAuth-Client-Geheimnis",
|
||||
"dev.mcp.auth.oauth.clientSecret.placeholder": "Optional",
|
||||
"dev.mcp.auth.oauth.redirectHint": "Weiterleitungs-URI zur Registrierung bei Ihrer OAuth-App:",
|
||||
"dev.mcp.auth.placeholder": "Auth-Typ auswählen",
|
||||
"dev.mcp.auth.token.desc": "API-Schlüssel oder Bearer-Token eingeben",
|
||||
"dev.mcp.auth.token.label": "API-Schlüssel",
|
||||
|
||||
@@ -4,6 +4,7 @@
|
||||
"ai360.description": "360 AI ist eine Modell- und Serviceplattform von 360, die NLP-Modelle wie 360GPT2 Pro, 360GPT Pro und 360GPT Turbo anbietet. Die Modelle kombinieren großskalige Parameter mit multimodalen Fähigkeiten für Textgenerierung, semantisches Verständnis, Chat und Code – mit flexibler Preisgestaltung für unterschiedliche Anforderungen.",
|
||||
"aihubmix.description": "AiHubMix bietet über eine einheitliche API Zugriff auf mehrere KI-Modelle.",
|
||||
"akashchat.description": "Akash ist ein dezentraler Cloud-Marktplatz mit wettbewerbsfähigen Preisen im Vergleich zu traditionellen Cloud-Anbietern.",
|
||||
"antgroup.description": "Ant Ling ist die Kernmodellreihe der Ant Group-Initiative für Allgemeine Künstliche Intelligenz (AGI), die sich der Entwicklung und Bereitstellung modernster Grundmodellfähigkeiten widmet. Wir glauben, dass die Entwicklung von Intelligenz in Richtung Offenheit, Teilen und Skalierbarkeit gehen muss – beginnend mit kleinen, praktischen Schritten, um die stetige Weiterentwicklung und den realen Einsatz von AGI voranzutreiben.",
|
||||
"anthropic.description": "Anthropic entwickelt fortschrittliche Sprachmodelle wie Claude 3.5 Sonnet, Claude 3 Sonnet, Claude 3 Opus und Claude 3 Haiku, die Intelligenz, Geschwindigkeit und Kosten für Unternehmens- und Echtzeitanwendungen ausbalancieren.",
|
||||
"azure.description": "Azure bietet fortschrittliche KI-Modelle, darunter die GPT-3.5- und GPT-4-Serien, für vielfältige Datentypen und komplexe Aufgaben mit Fokus auf sichere, zuverlässige und nachhaltige KI.",
|
||||
"azureai.description": "Azure stellt fortschrittliche KI-Modelle wie GPT-3.5 und GPT-4 für verschiedenste Datentypen und komplexe Aufgaben bereit – mit Fokus auf Sicherheit, Zuverlässigkeit und Nachhaltigkeit.",
|
||||
|
||||
@@ -280,7 +280,33 @@
|
||||
"defaultAgent.title": "Standard-Agenteneinstellungen",
|
||||
"devices.actions.edit": "Bearbeiten",
|
||||
"devices.actions.remove": "Entfernen",
|
||||
"devices.capabilities.commands.desc": "Führen Sie Terminalbefehle sicher in Ihrer Umgebung aus.",
|
||||
"devices.capabilities.commands.title": "Befehle ausführen",
|
||||
"devices.capabilities.files.desc": "Ermöglichen Sie Agenten direkten Zugriff auf die Dateien auf Ihrem Computer und deren Organisation.",
|
||||
"devices.capabilities.files.title": "Lokale Dateien lesen & schreiben",
|
||||
"devices.capabilities.title": "Was Sie nach der Verbindung tun können",
|
||||
"devices.capabilities.tools.desc": "Verbinden Sie lokale Tools, um die Möglichkeiten der Agenten zu erweitern.",
|
||||
"devices.capabilities.tools.title": "Systemtools aufrufen",
|
||||
"devices.channel.connected": "Verbunden {{time}}",
|
||||
"devices.connectWizard.button": "Gerät verbinden",
|
||||
"devices.connectWizard.cli.connectDesc": "Starten Sie den Hintergrunddienst, um das Gerät online zu halten und für Remote-Operationen bereitzustellen.",
|
||||
"devices.connectWizard.cli.connectTitle": "Dienst starten",
|
||||
"devices.connectWizard.cli.installDesc": "Installieren Sie die LobeHub CLI global mit Ihrem bevorzugten Paketmanager, um Geräteverbindung und -verwaltung zu ermöglichen.",
|
||||
"devices.connectWizard.cli.installTitle": "CLI installieren",
|
||||
"devices.connectWizard.cli.loginDesc": "Schließen Sie die OAuth-Autorisierung in Ihrem Browser ab, um die CLI mit Ihrem Konto zu verknüpfen.",
|
||||
"devices.connectWizard.cli.loginTitle": "Anmelden",
|
||||
"devices.connectWizard.desktop.downloadLink": "LobeHub Desktop herunterladen",
|
||||
"devices.connectWizard.desktop.step1": "Desktop-App herunterladen",
|
||||
"devices.connectWizard.desktop.step1Desc": "Besuchen Sie die LobeHub-Downloadseite und laden Sie die App für Ihr Betriebssystem herunter.",
|
||||
"devices.connectWizard.desktop.step2": "Anmelden und das Geräte-Gateway öffnen",
|
||||
"devices.connectWizard.desktop.step2Desc": "Nach der Anmeldung klicken Sie auf das Geräte-Gateway-Symbol oben rechts und bestätigen, dass es eingeschaltet ist.",
|
||||
"devices.connectWizard.desktop.step3": "Ihr Gerät erscheint automatisch",
|
||||
"devices.connectWizard.desktop.step3Desc": "Die Desktop-App registriert sich beim Start automatisch als Gerät – Sie sehen es in der Liste, sobald es verbunden ist.",
|
||||
"devices.connectWizard.footer": "Es werden nur Gerätedaten registriert – Ihre Daten werden niemals abgerufen.",
|
||||
"devices.connectWizard.method.cli": "Über CLI",
|
||||
"devices.connectWizard.method.desktop": "Über Desktop",
|
||||
"devices.connectWizard.subtitle": "Wählen Sie aus, wie Sie Ihren Computer mit LobeHub verbinden möchten.",
|
||||
"devices.connectWizard.title": "Gerät verbinden",
|
||||
"devices.currentBadge": "Dieses Gerät",
|
||||
"devices.detail.addDir": "Verzeichnis hinzufügen",
|
||||
"devices.detail.connections": "Verbindungen",
|
||||
@@ -294,7 +320,13 @@
|
||||
"devices.edit.friendlyNamePlaceholder": "Ein Name zur Erkennung dieses Geräts",
|
||||
"devices.edit.save": "Speichern",
|
||||
"devices.edit.title": "Gerät bearbeiten",
|
||||
"devices.empty": "Noch keine Geräte. Verbinden Sie eines mit `lh connect` oder durch Anmeldung in der Desktop-App.",
|
||||
"devices.empty.desc": "Nach der Verbindung können LobeHub-Agenten Dateien lesen/schreiben, Befehle ausführen und direkt auf Ihrem Computer Systemtools aufrufen.",
|
||||
"devices.empty.methodCli.desc": "Installieren Sie die CLI in Ihrem Terminal – ideal für Server oder headless Maschinen.",
|
||||
"devices.empty.methodCli.title": "Über CLI verbinden",
|
||||
"devices.empty.methodDesktop.badge": "Empfohlen",
|
||||
"devices.empty.methodDesktop.desc": "Laden Sie die Desktop-App herunter, melden Sie sich an, und Ihr Gerät wird automatisch verbunden.",
|
||||
"devices.empty.methodDesktop.title": "Über Desktop verbinden",
|
||||
"devices.empty.title": "Verbinden Sie Ihr erstes Gerät",
|
||||
"devices.fallbackBadge": "Instabile Identität",
|
||||
"devices.fallbackTooltip": "Dieses Gerät konnte nicht anhand seiner Maschinen-ID identifiziert werden, daher kann eine Neuinstallation der App einen doppelten Eintrag erstellen.",
|
||||
"devices.lastSeen": "Zuletzt aktiv {{time}}",
|
||||
@@ -522,6 +554,7 @@
|
||||
"notification.item.image_generation_completed": "Bilderstellung abgeschlossen",
|
||||
"notification.item.storage_overage_cap_reached": "Speicher-Pay-as-you-go-Limit erreicht",
|
||||
"notification.item.video_generation_completed": "Videoerstellung abgeschlossen",
|
||||
"notification.item.workspace_member_invited": "Arbeitsbereichseinladung",
|
||||
"notification.item.workspace_member_joined": "Neues Mitglied beigetreten",
|
||||
"notification.item.workspace_member_removed": "Aus Arbeitsbereich entfernt",
|
||||
"notification.item.workspace_payment_failed": "Erneuerungszahlung fehlgeschlagen",
|
||||
@@ -1766,6 +1799,7 @@
|
||||
"workspace.members.invite.errors.alreadyMember": "{{email}} ist bereits Mitglied dieses Arbeitsbereichs.",
|
||||
"workspace.members.invite.failed": "Einladung konnte nicht gesendet werden",
|
||||
"workspace.members.invite.limitReached": "Dieser Arbeitsbereich kann bis zu {{limit}} Mitglieder haben. Entfernen Sie ein Mitglied, bevor Sie weitere einladen.",
|
||||
"workspace.members.invite.modal.billIncrease": "Ihre Rechnung wird um ${{amount}}/Monat steigen.",
|
||||
"workspace.members.invite.modal.cancel": "Abbrechen",
|
||||
"workspace.members.invite.modal.confirm": "Bestätigen",
|
||||
"workspace.members.invite.modal.description_one": "Ihr Team wächst! Durch Bestätigen laden Sie 1 neues Teammitglied in diesen Arbeitsbereich ein.",
|
||||
@@ -1873,6 +1907,7 @@
|
||||
"workspace.upgradeModal.chargeDisclosure": "Beim Klicken auf Upgrade wird Ihnen sofort ${{fee}} zuzüglich aller anfallenden Steuern und Gebühren berechnet und dann jeden Monat, bis Sie kündigen. Sitzplatzgebühren und nutzungsabhängige Kosten werden am Monatsende abgerechnet; wenn Ihre Nutzung während eines Zyklus eine Abrechnungsschwelle überschreitet, kann Ihre hinterlegte Zahlungsmethode vor Ende des Zyklus belastet werden.",
|
||||
"workspace.upgradeModal.continueCta": "Weiter",
|
||||
"workspace.upgradeModal.createTeam": "Workspace erstellen",
|
||||
"workspace.upgradeModal.formDescription": "Überprüfen Sie die unten stehenden Details und bestätigen Sie Ihr Upgrade.",
|
||||
"workspace.upgradeModal.formSubtitle": "Nur die Plattformgebühr wird heute berechnet – Sitzplatzgebühren werden am Monatsende abgerechnet.",
|
||||
"workspace.upgradeModal.formTitle": "Upgrade {{name}} auf Pro",
|
||||
"workspace.upgradeModal.heading": "Workspace auf Pro upgraden",
|
||||
|
||||
@@ -370,6 +370,14 @@
|
||||
"noMatchingAgents": "No matching members found",
|
||||
"noMembersYet": "This group doesn't have any members yet. Click the + button to invite agents.",
|
||||
"noSelectedAgents": "No members selected yet",
|
||||
"opStatusTray.status.compressing": "Compressing context",
|
||||
"opStatusTray.status.generating": "Generating",
|
||||
"opStatusTray.status.reasoning": "Thinking",
|
||||
"opStatusTray.status.searching": "Searching",
|
||||
"opStatusTray.status.toolCalling": "Calling tools",
|
||||
"opStatusTray.cost": "cost",
|
||||
"opStatusTray.steps": "steps",
|
||||
"opStatusTray.tokens": "tokens",
|
||||
"openInNewWindow": "Open in New Window",
|
||||
"operation.contextCompression": "Context too long, compressing history...",
|
||||
"operation.execAgentRuntime": "Preparing response",
|
||||
|
||||
@@ -480,9 +480,6 @@
|
||||
"userPanel.setting": "Settings",
|
||||
"userPanel.upgradePlan": "Upgrade Plan",
|
||||
"userPanel.usages": "Usage",
|
||||
"userPanel.workspaceCredits": "Workspace Credits",
|
||||
"userPanel.workspaceSetting": "Workspace Settings",
|
||||
"userPanel.workspaceUsages": "Workspace Usage",
|
||||
"version": "Version",
|
||||
"zoom": "Zoom"
|
||||
}
|
||||
|
||||
+12
-28
@@ -27,15 +27,15 @@
|
||||
"DeepSeek-OCR.description": "DeepSeek-OCR is a vision-language model from DeepSeek AI focused on OCR and \"context optical compression.\" It explores compressing context from images, efficiently processes documents, and converts them to structured text (e.g., Markdown). It accurately recognizes text in images, suited for document digitization, text extraction, and structured processing.",
|
||||
"DeepSeek-R1-Distill-Llama-70B.description": "DeepSeek R1, the larger and smarter model in the DeepSeek suite, is distilled into the Llama 70B architecture. Benchmarks and human evals show it is smarter than the base Llama 70B, especially on math and fact-precision tasks.",
|
||||
"DeepSeek-R1-Distill-Qwen-1.5B.description": "A DeepSeek-R1 distilled model based on Qwen2.5-Math-1.5B. Reinforcement learning and cold-start data optimize reasoning performance, setting new multi-task benchmarks for open models.",
|
||||
"DeepSeek-R1-Distill-Qwen-14B.description": "DeepSeek-R1-Distill models are fine-tuned from open-source models using sample data generated by DeepSeek-R1.",
|
||||
"DeepSeek-R1-Distill-Qwen-32B.description": "DeepSeek-R1-Distill models are fine-tuned from open-source models using sample data generated by DeepSeek-R1.",
|
||||
"DeepSeek-R1-Distill-Qwen-14B.description": "A DeepSeek-R1 distilled model based on Qwen2.5-14B. Reinforcement learning and cold-start data optimize reasoning performance, setting new multi-task benchmarks for open models.",
|
||||
"DeepSeek-R1-Distill-Qwen-32B.description": "The DeepSeek-R1 series improves reasoning performance with reinforcement learning and cold-start data, setting new multi-task benchmarks for open models and surpassing OpenAI o1-mini.",
|
||||
"DeepSeek-R1-Distill-Qwen-7B.description": "A DeepSeek-R1 distilled model based on Qwen2.5-Math-7B. Reinforcement learning and cold-start data optimize reasoning performance, setting new multi-task benchmarks for open models.",
|
||||
"DeepSeek-R1.description": "DeepSeek-R1 applies large-scale reinforcement learning during post-training, greatly boosting reasoning with very little labeled data. It matches the OpenAI o1 production model on math, code, and natural language reasoning tasks.",
|
||||
"DeepSeek-R1.description": "State-of-the-art efficient LLM, strong at reasoning, math, and coding.",
|
||||
"DeepSeek-V3-1.description": "DeepSeek V3.1 is a next-gen reasoning model with improved complex reasoning and chain-of-thought, suited for deep analysis tasks.",
|
||||
"DeepSeek-V3-Fast.description": "Provider: sophnet. DeepSeek V3 Fast is the high-TPS version of DeepSeek V3 0324, full-precision (non-quantized) with stronger code and math and faster responses.",
|
||||
"DeepSeek-V3.1-Think.description": "DeepSeek-V3.1 thinking mode: a new hybrid reasoning model with thinking and non-thinking modes, more efficient than DeepSeek-R1-0528. Post-training optimizations significantly improve agent tool use and agent task performance.",
|
||||
"DeepSeek-V3.2.description": "deepseek-v3.2 introduces sparse attention mechanism, aiming to improve training and inference efficiency when processing long texts, priced lower than deepseek-v3.1.",
|
||||
"DeepSeek-V3.description": "DeepSeek-V3 is a MoE model developed by DeepSeek. It surpasses other open models like Qwen2.5-72B and Llama-3.1-405B on many benchmarks and is competitive with leading closed models such as GPT-4o and Claude 3.5 Sonnet.",
|
||||
"DeepSeek-V3.description": "ByteDance Volcengine’s open deployment is currently the most stable; recommended. It has been auto-upgraded to the latest release (250324).",
|
||||
"Doubao-lite-128k.description": "Doubao-lite offers ultra-fast responses and better value, with flexible options across scenarios. Supports 128K context for inference and fine-tuning.",
|
||||
"Doubao-lite-32k.description": "Doubao-lite offers ultra-fast responses and better value, with flexible options across scenarios. Supports 32K context for inference and fine-tuning.",
|
||||
"Doubao-lite-4k.description": "Doubao-lite offers ultra-fast responses and better value, with flexible options across scenarios. Supports 4K context for inference and fine-tuning.",
|
||||
@@ -83,13 +83,12 @@
|
||||
"Kimi-K2.5.description": "Kimi K2.5 is the most capable Kimi model, delivering open-source SOTA in agent tasks, coding, and vision understanding. It supports multimodal inputs and both thinking and non-thinking modes.",
|
||||
"Kolors.description": "Kolors is a text-to-image model developed by the Kuaishou Kolors team. Trained with billions of parameters, it has notable advantages in visual quality, Chinese semantic understanding, and text rendering.",
|
||||
"Kwai-Kolors/Kolors.description": "Kolors is a large-scale latent-diffusion text-to-image model by the Kuaishou Kolors team. Trained on billions of text-image pairs, it excels in visual quality, complex semantic accuracy, and Chinese/English text rendering, with strong Chinese content understanding and generation.",
|
||||
"Ling-2.5-1T.description": "As the latest flagship real-time model in the Ling series, Ling-2.5-1T introduces comprehensive upgrades in model architecture, token efficiency, and preference alignment, aiming to elevate the quality of accessible AI to a new level.",
|
||||
"Ling-2.6-1T.description": "The latest flagship large language model, featuring support for a 1M-token context window and enabling an end-to-end workflow from logical reasoning to task execution.",
|
||||
"Ling-2.6-flash.description": "Ling-2.6-flash is the latest generation high cost-performance model in the Ling series. It adopts a Mixture-of-Experts (MoE) architecture, with a total parameter count of 100B and 6.1B activated parameters per token, achieving an optimal balance between inference performance and computational cost.",
|
||||
"Llama-3.2-11B-Vision-Instruct.description": "Strong image reasoning on high-resolution images, suited for visual understanding applications.",
|
||||
"Llama-3.2-90B-Vision-Instruct\t.description": "Advanced image reasoning for visual-understanding agent applications.",
|
||||
"Llama-3.2-90B-Vision-Instruct.description": "Advanced image reasoning for visual-understanding agent applications.",
|
||||
"LongCat-2.0-Preview.description": "The core features of LongCat-2.0-Preview are as follows: Designed for agent development scenarios, with native support for tool use, multi-step reasoning, and long-context tasks; Excels in code generation, automated workflows, and complex instruction execution; Deeply integrated with productivity tools such as Claude Code, OpenClaw, OpenCode, and Kilo Code.",
|
||||
"LongCat-Flash-Chat.description": "The LongCat-Flash-Chat model has been upgraded to a new version. This update involves enhancements to model capabilities only; the model name and API invocation method remain unchanged. Building upon its hallmark “extreme efficiency” and “lightning-fast response,” the new version further strengthens contextual understanding and real-world programming performance: Significantly Enhanced Coding Capabilities: Deeply optimized for developer-centric scenarios, the model delivers substantial improvements in code generation, debugging, and explanation tasks. Developers are strongly encouraged to evaluate and benchmark these enhancements. Support for 256K Ultra-Long Context: The context window has doubled from the previous generation (128K) to 256K, enabling efficient processing of massive documents and long-sequence tasks. Comprehensively Improved Multilingual Performance: Provides strong support for nine languages, including Spanish, French, Arabic, Portuguese, Russian, and Indonesian. More Powerful Agent Capabilities: Demonstrates greater robustness and efficiency in complex tool invocation and multi-step task execution.",
|
||||
"LongCat-Flash-Lite.description": "The LongCat-Flash-Lite model has been officially released. It adopts an efficient Mixture-of-Experts (MoE) architecture, with 68.5 billion total parameters and approximately 3 billion activated parameters. Through the use of an N-gram embedding table, it achieves highly efficient parameter utilization, and it is deeply optimized for inference efficiency and specific application scenarios. Compared to models of a similar scale, its core features are as follows:Outstanding Inference Efficiency: By leveraging the N-gram embedding table to fundamentally alleviate the I/O bottleneck inherent in MoE architectures, combined with dedicated caching mechanisms and kernel-level optimizations, it significantly reduces inference latency and improves overall efficiency. Strong Agent and Code Performance: It demonstrates highly competitive capabilities in tool invocation and software development tasks, delivering exceptional performance relative to its model size.",
|
||||
"LongCat-Flash-Thinking-2601.description": "The LongCat-Flash-Thinking-2601 model has been officially released. As an upgraded reasoning model built on a Mixture-of-Experts (MoE) architecture, it features a total of 560 billion parameters. While maintaining strong competitiveness across traditional reasoning benchmarks, it systematically enhances Agent-level reasoning capabilities through large-scale multi-environment reinforcement learning. Compared to the LongCat-Flash-Thinking model, the key upgrades are as follows: Extreme Robustness in Noisy Environments: Through systematic curriculum-style training targeting noise and uncertainty in real-world settings, the model demonstrates outstanding performance in Agent tool invocation, Agent-based search, and tool-integrated reasoning, with significantly improved generalization. Powerful Agent Capabilities: By constructing a tightly coupled dependency graph encompassing more than 60 tools, and scaling training through multi-environment expansion and large-scale exploratory learning, the model markedly improves its ability to generalize to complex and out-of-distribution real-world scenarios. Advanced Deep Thinking Mode: It expands the breadth of reasoning via parallel inference and deepens analytical capability through recursive feedback-driven summarization and abstraction mechanisms, effectively addressing highly challenging problems.",
|
||||
"LongCat-Flash-Thinking.description": "To ensure you receive top-tier reasoning performance, the LongCat API platform has unified and upgraded calls to the LongCat-Flash-Thinking model. All existing requests using `model=LongCat-Flash-Thinking` will be automatically routed to the latest version, LongCat-Flash-Thinking-2601, with no code changes required.",
|
||||
"M2-her.description": "A text dialogue model designed for role-playing and multi-turn conversations, with character customization and emotional expression.",
|
||||
"Meta-Llama-3-3-70B-Instruct.description": "Llama 3.3 70B is a versatile Transformer model for chat and generation tasks.",
|
||||
"Meta-Llama-3.1-405B-Instruct.description": "Llama 3.1 instruction-tuned text model optimized for multilingual chat, performing strongly on common industry benchmarks among open and closed chat models.",
|
||||
@@ -187,27 +186,10 @@
|
||||
"Qwen2.5-Coder-14B-Instruct.description": "Qwen2.5-Coder-14B-Instruct is a large-scale pre-trained coding instruction model with strong code understanding and generation. It efficiently handles a wide range of programming tasks, ideal for smart coding, automated script generation, and programming Q&A.",
|
||||
"Qwen2.5-Coder-32B-Instruct.description": "Advanced LLM for code generation, reasoning, and bug fixing across major programming languages.",
|
||||
"Qwen3-235B-A22B-Instruct-2507-FP8.description": "Qwen3 235B A22B Instruct 2507 is optimized for advanced reasoning and instruction-following, using MoE to keep reasoning efficient at scale.",
|
||||
"Qwen3-235B.description": "Qwen3-235B-A22B is a MoE model that introduces a hybrid reasoning mode, letting users switch seamlessly between thinking and non-thinking. It supports understanding and reasoning across 119 languages and dialects and has strong tool-calling capabilities, competing with mainstream models like DeepSeek R1, OpenAI o1, o3-mini, Grok 3, and Google Gemini 2.5 Pro across benchmarks in general ability, code and math, multilingual capability, and knowledge reasoning.",
|
||||
"Qwen3-32B.description": "Qwen3-32B is a dense model that introduces a hybrid reasoning mode, letting users switch between thinking and non-thinking. With architecture improvements, more data, and better training, it performs on par with Qwen2.5-72B.",
|
||||
"Qwen3.5-Plus.description": "Qwen3.5 Plus supports text, image, and video input. Its performance on pure text tasks is comparable to Qwen3 Max, with better performance and lower cost. Its multimodal capabilities are significantly improved compared to the Qwen3 VL series.",
|
||||
"Ring-2.5-1T.description": "Compared to the previously released Ring-1T, Ring-2.5-1T achieves significant improvements across three key dimensions: generation efficiency, reasoning depth, and long-horizon task execution capability: Generation Efficiency**: By leveraging a high proportion of linear attention mechanisms, Ring-2.5-1T reduces memory access overhead by more than 10×. When processing sequences exceeding 32K tokens, it delivers over 3× higher generation throughput, making it particularly well-suited for deep reasoning and long-horizon task execution. Deep Reasoning**: Building on RLVR, a dense reward mechanism is introduced to provide feedback on the rigor of the reasoning process. This enables Ring-2.5-1T to achieve gold-medal-level performance in both IMO 2025 and CMO 2025 (self-evaluated). Long-Horizon Task Execution**: Through large-scale fully asynchronous agent-based reinforcement learning training, the model significantly enhances its ability to autonomously execute complex tasks over extended periods. This allows Ring-2.5-1T to seamlessly integrate with agent programming frameworks such as Claude Code and OpenClaw personal AI assistants.",
|
||||
"Ring-2.6-1T.description": "Ring-2.6-1T is a trillion-parameter-scale reasoning model that activates approximately 63B parameters per inference. Designed for Agent workflows, it focuses on agent capabilities, tool use, and long-horizon task execution, achieving leading performance on benchmarks such as PinchBench, ClawEval, TAU2-Bench, and GAIA2-search. The model is optimized across execution quality, latency, and cost, making it well suited for advanced coding agents, complex reasoning pipelines, and large-scale autonomous systems.",
|
||||
"S2V-01.description": "The foundational reference-to-video model of the 01 series.",
|
||||
"SenseChat-128K.description": "Base V4 with 128K context, strong in long-text understanding and generation.",
|
||||
"SenseChat-32K.description": "Base V4 with 32K context, flexible for many scenarios.",
|
||||
"SenseChat-5-1202.description": "Latest version based on V5.5, with significant gains in Chinese/English fundamentals, chat, STEM knowledge, humanities knowledge, writing, math/logic, and length control.",
|
||||
"SenseChat-5-Cantonese.description": "Designed for Hong Kong dialogue habits, slang, and local knowledge; surpasses GPT-4 in Cantonese understanding and rivals GPT-4 Turbo in knowledge, reasoning, math, and coding.",
|
||||
"SenseChat-5-beta.description": "Some performance exceeds SenseChat-5-1202.",
|
||||
"SenseChat-5.description": "Latest V5.5 with 128K context; major gains in math reasoning, English chat, instruction following, and long-text understanding, comparable to GPT-4o.",
|
||||
"SenseChat-Character-Pro.description": "Advanced character chat model with 32K context, improved capability, and Chinese/English support.",
|
||||
"SenseChat-Character.description": "Standard character chat model with 8K context and high response speed.",
|
||||
"SenseChat-Turbo-1202.description": "Latest lightweight model reaching 90%+ of full-model capability with significantly lower inference cost.",
|
||||
"SenseChat-Turbo.description": "Suitable for fast Q&A and model fine-tuning scenarios.",
|
||||
"SenseChat-Vision.description": "Latest V5.5 with multi-image input and broad core improvements in attribute recognition, spatial relations, action/event detection, scene understanding, emotion recognition, commonsense reasoning, and text understanding/generation.",
|
||||
"SenseChat.description": "Base V4 with 4K context and strong general capability.",
|
||||
"SenseNova-V6-5-Pro.description": "With comprehensive updates to multimodal, language, and reasoning data plus training strategy optimization, the new model significantly improves multimodal reasoning and generalized instruction following, supports up to a 128k context window, and excels in OCR and cultural tourism IP recognition tasks.",
|
||||
"SenseNova-V6-5-Turbo.description": "With comprehensive updates to multimodal, language, and reasoning data plus training strategy optimization, the new model significantly improves multimodal reasoning and generalized instruction following, supports up to a 128k context window, and excels in OCR and cultural tourism IP recognition tasks.",
|
||||
"SenseNova-V6-Pro.description": "Natively unifies image, text, and video, breaking traditional multimodal silos; wins top spots on OpenCompass and SuperCLUE.",
|
||||
"SenseNova-V6-Reasoner.description": "Combines vision and language deep reasoning, supporting slow thinking and full chain-of-thought.",
|
||||
"SenseNova-V6-Turbo.description": "Natively unifies image, text, and video, breaking traditional multimodal silos. It leads across core multimodal and language capabilities and ranks top-tier in multiple evaluations.",
|
||||
"Skylark2-lite-8k.description": "Skylark 2nd-gen model. Skylark2-lite has fast responses for real-time, cost-sensitive scenarios with lower accuracy needs, with an 8K context window.",
|
||||
"Skylark2-pro-32k.description": "Skylark 2nd-gen model. Skylark2-pro offers higher accuracy for complex text generation such as professional copywriting, novel writing, and high-quality translation, with a 32K context window.",
|
||||
"Skylark2-pro-4k.description": "Skylark 2nd-gen model. Skylark2-pro offers higher accuracy for complex text generation such as professional copywriting, novel writing, and high-quality translation, with a 4K context window.",
|
||||
@@ -1197,6 +1179,8 @@
|
||||
"r1-1776.description": "R1-1776 is a post-trained variant of DeepSeek R1 designed to provide uncensored, unbiased factual information.",
|
||||
"seedance-1-5-pro-251215.description": "Seedance 1.5 Pro by ByteDance supports text-to-video, image-to-video (first frame, first+last frame), and audio generation synchronized with visuals.",
|
||||
"seedream-5-0-260128.description": "ByteDance-Seedream-5.0-lite by BytePlus features web-retrieval-augmented generation for real-time information, enhanced complex prompt interpretation, and improved reference consistency for professional visual creation.",
|
||||
"sensenova-6.7-flash-lite.description": "A lightweight multimodal agent model designed for real-world workflows, supporting both text-based conversations and image understanding. Lightweight and efficient, balancing performance, cost, and deployability. Native multimodal architecture with support for image understanding, including OCR and chart interpretation. Enhanced for office and productivity scenarios, with stable support for complex long-chain tasks. Improved token efficiency, enabling better cost control for complex workloads. Context length of 256K tokens (maximum input: 252K, maximum output: 64K)",
|
||||
"sensenova-u1-fast.description": "An accelerated version based on SenseNova U1, specifically optimized for infographic generation.",
|
||||
"solar-mini-ja.description": "Solar Mini (Ja) extends Solar Mini with a focus on Japanese while maintaining efficient, strong performance in English and Korean.",
|
||||
"solar-mini.description": "Solar Mini is a compact LLM that outperforms GPT-3.5, with strong multilingual capability supporting English and Korean, offering an efficient small-footprint solution.",
|
||||
"solar-pro.description": "Solar Pro is a high-intelligence LLM from Upstage, focused on instruction following on a single GPU, with IFEval scores above 80. It currently supports English; the full release was planned for November 2024 with expanded language support and longer context.",
|
||||
|
||||
@@ -17,6 +17,8 @@
|
||||
"storage_overage_cap_reached_title": "Storage pay-as-you-go cap reached",
|
||||
"video_generation_completed": "Your video \"{{prompt}}\" is ready.",
|
||||
"video_generation_completed_title": "Video generation completed",
|
||||
"workspace_member_invited": "{{inviterLabel}} invited you to join workspace \"{{workspaceName}}\" as a {{role}}.",
|
||||
"workspace_member_invited_title": "Invitation to join {{workspaceName}}",
|
||||
"workspace_member_joined": "{{memberLabel}} joined workspace \"{{workspaceName}}\" as a {{role}}.",
|
||||
"workspace_member_joined_member": "{{memberLabel}} joined workspace \"{{workspaceName}}\" as a Member.",
|
||||
"workspace_member_joined_member_title": "New member joined {{workspaceName}}",
|
||||
|
||||
@@ -0,0 +1,34 @@
|
||||
{
|
||||
"generatingPhrases": [
|
||||
"Working",
|
||||
"Drafting",
|
||||
"Thinking",
|
||||
"Computing",
|
||||
"Brewing",
|
||||
"Synthesizing",
|
||||
"Crunching",
|
||||
"Architecting",
|
||||
"Composing",
|
||||
"Orchestrating",
|
||||
"Sketching",
|
||||
"Noodling",
|
||||
"Pondering",
|
||||
"Crafting",
|
||||
"Flambéing",
|
||||
"Simmering",
|
||||
"Whirring",
|
||||
"Wrangling",
|
||||
"Polishing",
|
||||
"Preparing the answer",
|
||||
"Baking",
|
||||
"Channeling",
|
||||
"Coalescing",
|
||||
"Deciphering",
|
||||
"Forging",
|
||||
"Harmonizing",
|
||||
"Improvising",
|
||||
"Inferring",
|
||||
"Tinkering",
|
||||
"Zigzagging"
|
||||
]
|
||||
}
|
||||
@@ -554,6 +554,7 @@
|
||||
"notification.item.image_generation_completed": "Image generation completed",
|
||||
"notification.item.storage_overage_cap_reached": "Storage pay-as-you-go cap reached",
|
||||
"notification.item.video_generation_completed": "Video generation completed",
|
||||
"notification.item.workspace_member_invited": "Workspace invitation",
|
||||
"notification.item.workspace_member_joined": "New member joined",
|
||||
"notification.item.workspace_member_removed": "Removed from workspace",
|
||||
"notification.item.workspace_payment_failed": "Renewal payment failed",
|
||||
@@ -1178,6 +1179,9 @@
|
||||
"tools.klavis.disconnect": "Disconnect",
|
||||
"tools.klavis.disconnected": "Disconnected",
|
||||
"tools.klavis.error": "Error",
|
||||
"tools.klavis.remove": "Remove",
|
||||
"tools.klavis.removeConfirm.desc": "{{name}} will be permanently removed from your connected services. This action cannot be undone.",
|
||||
"tools.klavis.removeConfirm.title": "Remove {{name}}?",
|
||||
"tools.klavis.groupName": "Klavis Tools",
|
||||
"tools.klavis.manage": "Manage Klavis",
|
||||
"tools.klavis.manageTitle": "Manage Klavis Integration",
|
||||
@@ -1492,7 +1496,7 @@
|
||||
"workspace.billingPage.plans.modelsHint": "Estimated messages from the shared pool",
|
||||
"workspace.billingPage.plans.modelsTitle": "Featured models",
|
||||
"workspace.billingPage.plans.perMonth": "/ month",
|
||||
"workspace.billingPage.plans.popularTag": "Popular",
|
||||
"workspace.billingPage.plans.popularTag": "Recommended",
|
||||
"workspace.billingPage.plans.priceProCaption": "Platform fee · billed monthly",
|
||||
"workspace.billingPage.plans.priceProHeadline": "${{fee}} / mo",
|
||||
"workspace.billingPage.plans.pricingBannerCta": "View pricing",
|
||||
@@ -1798,6 +1802,7 @@
|
||||
"workspace.members.invite.errors.alreadyMember": "{{email}} is already a member of this workspace.",
|
||||
"workspace.members.invite.failed": "Failed to send invitation",
|
||||
"workspace.members.invite.limitReached": "This workspace can have up to {{limit}} members. Remove a member before inviting more.",
|
||||
"workspace.members.invite.modal.billIncrease": " Your bill will increase by ${{amount}}/mo.",
|
||||
"workspace.members.invite.modal.cancel": "Cancel",
|
||||
"workspace.members.invite.modal.confirm": "Confirm",
|
||||
"workspace.members.invite.modal.description_one": "Your team is expanding! By confirming, you will invite 1 new team member to this workspace.",
|
||||
@@ -1902,9 +1907,10 @@
|
||||
"workspace.switchWorkspace": "Switch workspace",
|
||||
"workspace.upgradeModal.alreadyUpgraded": "Already upgraded",
|
||||
"workspace.upgradeModal.changeWorkspace": "Back",
|
||||
"workspace.upgradeModal.chargeDisclosure": "Upon clicking Upgrade, you will be charged ${{fee}}, plus any applicable taxes and fees, immediately and then every month, until you cancel. Seat fees and on-demand usage are settled at month-end; if your usage exceeds a billing threshold during a cycle, your payment method on file may be charged before the cycle ends.",
|
||||
"workspace.upgradeModal.chargeDisclosure": "Clicking Upgrade charges ${{fee}} now, plus any applicable taxes. The subscription renews monthly until you cancel. Seats and on-demand usage are billed at month-end.",
|
||||
"workspace.upgradeModal.continueCta": "Continue",
|
||||
"workspace.upgradeModal.createTeam": "Create workspace",
|
||||
"workspace.upgradeModal.formDescription": "Review the details below and confirm your upgrade.",
|
||||
"workspace.upgradeModal.formSubtitle": "Only the platform fee is charged today — seat fees are settled at month-end.",
|
||||
"workspace.upgradeModal.formTitle": "Upgrade {{name}} to Pro",
|
||||
"workspace.upgradeModal.heading": "Upgrade a workspace to Pro",
|
||||
@@ -1995,13 +2001,13 @@
|
||||
"workspace.wizard.step2.createdToast": "Workspace {{name}} created.",
|
||||
"workspace.wizard.step2.details.description": "See what's included in your selected plan.",
|
||||
"workspace.wizard.step2.details.title": "Plan Details",
|
||||
"workspace.wizard.step2.features.hobby.onDemand": "On-demand usage · AutoTopUp (${{price}}/M)",
|
||||
"workspace.wizard.step2.features.hobby.onDemand": "On-demand usage · Auto top-up (${{price}} / 1M credits)",
|
||||
"workspace.wizard.step2.features.hobby.share": "Single-owner workspace",
|
||||
"workspace.wizard.step2.features.hobby.solo": "Solo workspace, no member seats",
|
||||
"workspace.wizard.step2.features.hobby.upgradable": "Upgrade anytime to invite members",
|
||||
"workspace.wizard.step2.features.pro.adminControls": "Centralized billing, roles, and audit logs",
|
||||
"workspace.wizard.step2.features.pro.collaboration": "Invite members · share agents and files",
|
||||
"workspace.wizard.step2.features.pro.onDemand": "On-demand usage · AutoTopUp (${{price}}/M)",
|
||||
"workspace.wizard.step2.features.pro.onDemand": "On-demand usage · Auto top-up (${{price}} / 1M credits)",
|
||||
"workspace.wizard.step2.features.pro.priorityModels": "Priority premium models",
|
||||
"workspace.wizard.step2.features.pro.support": "Priority email support",
|
||||
"workspace.wizard.step2.freeLimitReached": "You've reached the free workspace limit ({{limit}}). Upgrade to Pro to create more.",
|
||||
|
||||
@@ -135,6 +135,12 @@
|
||||
"management.view.card": "Card",
|
||||
"management.view.list": "List",
|
||||
"newTopic": "New Topic",
|
||||
"projectStatus.failed_one": "{{count}} failed topic",
|
||||
"projectStatus.failed_other": "{{count}} failed topics",
|
||||
"projectStatus.loading_one": "{{count}} loading topic",
|
||||
"projectStatus.loading_other": "{{count}} loading topics",
|
||||
"projectStatus.waitingForHuman_one": "{{count}} topic awaiting input",
|
||||
"projectStatus.waitingForHuman_other": "{{count}} topics awaiting input",
|
||||
"renameModal.description": "Keep it short and easy to recognize.",
|
||||
"renameModal.title": "Rename Topic",
|
||||
"searchPlaceholder": "Search Topics...",
|
||||
|
||||
@@ -15,6 +15,8 @@
|
||||
"agentBuilder.installPlugin.retry": "Reintentar",
|
||||
"agentBuilder.title": "Constructor de Agentes",
|
||||
"agentBuilder.welcome": "Cuéntame tu caso de uso.\n\nEscritura, programación o análisis de datos—todo vale. Tú defines el objetivo y los estándares; yo lo desgloso en Agentes colaborativos y ejecutables.",
|
||||
"agentConfigError.retry": "Reintentar",
|
||||
"agentConfigError.title": "Error al cargar la configuración del agente",
|
||||
"agentDefaultMessage": "Hola, soy **{{name}}**. Una frase es suficiente.\n\n¿Quieres que me adapte mejor a tu flujo de trabajo? Ve a [Configuración del Agente]({{url}}) y completa el Perfil del Agente (puedes editarlo en cualquier momento).",
|
||||
"agentDefaultMessageWithSystemRole": "Hola, soy **{{name}}**. Una frase es suficiente—tú tienes el control.",
|
||||
"agentDefaultMessageWithoutEdit": "Hola, soy **{{name}}**. Una frase es suficiente—tú tienes el control.",
|
||||
@@ -252,6 +254,10 @@
|
||||
"input.costEstimate.tooltip": "Estimado a partir del contexto actual, herramientas y precios del modelo. El costo real puede variar.",
|
||||
"input.disclaimer": "Los agentes pueden cometer errores. Usa tu criterio para información crítica.",
|
||||
"input.errorMsg": "Error al enviar: {{errorMsg}}. Intenta de nuevo más tarde.",
|
||||
"input.inputCompletionError.desc": "Las sugerencias de entrada se detuvieron debido a un error. Reintenta o ajusta el modelo de sugerencias en Configuración.",
|
||||
"input.inputCompletionError.retry": "Reintentar",
|
||||
"input.inputCompletionError.settings": "Configuración",
|
||||
"input.inputCompletionError.title": "Sugerencias de entrada pausadas",
|
||||
"input.more": "Más",
|
||||
"input.send": "Enviar",
|
||||
"input.sendWithCmdEnter": "Presiona <key/> para enviar",
|
||||
@@ -915,6 +921,7 @@
|
||||
"workflow.toolDisplayName.addPreferenceMemory": "Memoria guardada",
|
||||
"workflow.toolDisplayName.calculate": "Calculado",
|
||||
"workflow.toolDisplayName.callAgent": "Agente llamado",
|
||||
"workflow.toolDisplayName.callMcpTool": "Herramienta MCP llamada",
|
||||
"workflow.toolDisplayName.callSubAgent": "Subagente despachado",
|
||||
"workflow.toolDisplayName.clearTodos": "Tareas borradas",
|
||||
"workflow.toolDisplayName.copyDocument": "Copió un documento",
|
||||
@@ -1005,7 +1012,9 @@
|
||||
"workingPanel.localFile.closeRight": "Cerrar a la Derecha",
|
||||
"workingPanel.localFile.error": "No se pudo cargar este archivo",
|
||||
"workingPanel.localFile.preview.raw": "Sin procesar",
|
||||
"workingPanel.localFile.preview.reload": "Recargar vista previa",
|
||||
"workingPanel.localFile.preview.render": "Vista previa",
|
||||
"workingPanel.localFile.preview.source": "Fuente",
|
||||
"workingPanel.localFile.truncated": "Vista previa del archivo truncada a {{limit}} caracteres",
|
||||
"workingPanel.progress": "Progress",
|
||||
"workingPanel.progress.allCompleted": "All tasks completed",
|
||||
|
||||
@@ -239,6 +239,7 @@
|
||||
"providerModels.item.modelConfig.extendParams.options.reasoningBudgetToken32k.hint": "Para GLM-5 y GLM-4.7; controla el presupuesto de tokens para razonamiento (máximo 32k).",
|
||||
"providerModels.item.modelConfig.extendParams.options.reasoningBudgetToken80k.hint": "Para la serie Qwen3; controla el presupuesto de tokens para razonamiento (máximo 80k).",
|
||||
"providerModels.item.modelConfig.extendParams.options.reasoningEffort.hint": "Para OpenAI y otros modelos con capacidad de razonamiento; controla el esfuerzo de razonamiento.",
|
||||
"providerModels.item.modelConfig.extendParams.options.ring2_6ReasoningEffort.hint": "Para la serie Ring 2.6; controla la intensidad del razonamiento.",
|
||||
"providerModels.item.modelConfig.extendParams.options.step3_5ReasoningEffort.hint": "Para la serie Step 3.5; controla la intensidad del razonamiento.",
|
||||
"providerModels.item.modelConfig.extendParams.options.textVerbosity.hint": "Para la serie GPT-5+; controla la verbosidad del resultado.",
|
||||
"providerModels.item.modelConfig.extendParams.options.thinking.hint": "Para algunos modelos Doubao; permite que el modelo decida si debe pensar en profundidad.",
|
||||
|
||||
+12
-28
@@ -27,15 +27,15 @@
|
||||
"DeepSeek-OCR.description": "DeepSeek-OCR es un modelo visión‑lenguaje de DeepSeek AI centrado en OCR y en la “compresión óptica de contexto”. Explora la compresión de contexto a partir de imágenes, procesa documentos de forma eficiente y los convierte en texto estructurado (por ejemplo, Markdown). Reconoce texto en imágenes con alta precisión, ideal para la digitalización de documentos, extracción de texto y procesamiento estructurado.",
|
||||
"DeepSeek-R1-Distill-Llama-70B.description": "DeepSeek R1, el modelo más grande e inteligente de la suite DeepSeek, ha sido destilado en la arquitectura Llama 70B. Las pruebas de referencia y evaluaciones humanas muestran que es más inteligente que el Llama 70B base, especialmente en tareas de matemáticas y precisión factual.",
|
||||
"DeepSeek-R1-Distill-Qwen-1.5B.description": "Modelo destilado de DeepSeek-R1 basado en Qwen2.5-Math-1.5B. El aprendizaje por refuerzo y los datos de arranque en frío optimizan el rendimiento en razonamiento, estableciendo nuevos estándares de referencia multitarea para modelos abiertos.",
|
||||
"DeepSeek-R1-Distill-Qwen-14B.description": "Los modelos DeepSeek-R1-Distill están ajustados a partir de modelos de código abierto utilizando datos de muestra generados por DeepSeek-R1.",
|
||||
"DeepSeek-R1-Distill-Qwen-32B.description": "Los modelos DeepSeek-R1-Distill están ajustados a partir de modelos de código abierto utilizando datos de muestra generados por DeepSeek-R1.",
|
||||
"DeepSeek-R1-Distill-Qwen-14B.description": "Un modelo destilado DeepSeek-R1 basado en Qwen2.5-14B. El aprendizaje por refuerzo y los datos de inicio en frío optimizan el rendimiento en razonamiento, estableciendo nuevos estándares de referencia multitarea para modelos abiertos.",
|
||||
"DeepSeek-R1-Distill-Qwen-32B.description": "La serie DeepSeek-R1 mejora el rendimiento en razonamiento con aprendizaje por refuerzo y datos de inicio en frío, estableciendo nuevos estándares de referencia multitarea para modelos abiertos y superando a OpenAI o1-mini.",
|
||||
"DeepSeek-R1-Distill-Qwen-7B.description": "Modelo destilado de DeepSeek-R1 basado en Qwen2.5-Math-7B. El aprendizaje por refuerzo y los datos de arranque en frío optimizan el rendimiento en razonamiento, estableciendo nuevos estándares de referencia multitarea para modelos abiertos.",
|
||||
"DeepSeek-R1.description": "DeepSeek-R1 aplica aprendizaje por refuerzo a gran escala durante el postentrenamiento, mejorando significativamente el razonamiento con muy pocos datos etiquetados. Alcanza el nivel del modelo de producción OpenAI o1 en tareas de matemáticas, programación y razonamiento en lenguaje natural.",
|
||||
"DeepSeek-R1.description": "Modelo eficiente de última generación, destacado en razonamiento, matemáticas y programación.",
|
||||
"DeepSeek-V3-1.description": "DeepSeek V3.1 es un modelo de razonamiento de nueva generación con mejoras en razonamiento complejo y cadenas de pensamiento, adecuado para tareas de análisis profundo.",
|
||||
"DeepSeek-V3-Fast.description": "Proveedor: sophnet. DeepSeek V3 Fast es la versión de alta velocidad de DeepSeek V3 0324, de precisión completa (sin cuantización), con mejor rendimiento en código y matemáticas y respuestas más rápidas.",
|
||||
"DeepSeek-V3.1-Think.description": "Modo de pensamiento de DeepSeek-V3.1: un nuevo modelo de razonamiento híbrido con modos de pensamiento y no pensamiento, más eficiente que DeepSeek-R1-0528. Las optimizaciones posteriores al entrenamiento mejoran significativamente el uso de herramientas de agente y el rendimiento en tareas de agente.",
|
||||
"DeepSeek-V3.2.description": "deepseek-v3.2 incorpora un mecanismo de atención dispersa para mejorar la eficiencia de entrenamiento e inferencia al procesar textos largos, con un precio inferior al de deepseek-v3.1.",
|
||||
"DeepSeek-V3.description": "DeepSeek-V3 es un modelo MoE desarrollado por DeepSeek. Supera a otros modelos abiertos como Qwen2.5-72B y Llama-3.1-405B en muchas pruebas de referencia y compite con modelos cerrados líderes como GPT-4o y Claude 3.5 Sonnet.",
|
||||
"DeepSeek-V3.description": "El despliegue abierto de Volcengine de ByteDance es actualmente el más estable; recomendado. Ha sido actualizado automáticamente a la última versión (250324).",
|
||||
"Doubao-lite-128k.description": "Doubao-lite ofrece respuestas ultra rápidas y mejor relación calidad-precio, con opciones flexibles para distintos escenarios. Admite contexto de 128K para inferencia y ajuste fino.",
|
||||
"Doubao-lite-32k.description": "Doubao-lite ofrece respuestas ultra rápidas y mejor relación calidad-precio, con opciones flexibles para distintos escenarios. Admite contexto de 32K para inferencia y ajuste fino.",
|
||||
"Doubao-lite-4k.description": "Doubao-lite ofrece respuestas ultra rápidas y mejor relación calidad-precio, con opciones flexibles para distintos escenarios. Admite contexto de 4K para inferencia y ajuste fino.",
|
||||
@@ -83,13 +83,12 @@
|
||||
"Kimi-K2.5.description": "Kimi K2.5 es el modelo más potente de Kimi, con rendimiento SOTA de código abierto en tareas agentivas, programación y comprensión visual. Soporta entradas multimodales y modos con y sin razonamiento.",
|
||||
"Kolors.description": "Kolors es un modelo de texto a imagen desarrollado por el equipo Kolors de Kuaishou. Entrenado con miles de millones de parámetros, destaca por su calidad visual, comprensión semántica en chino y renderizado de texto.",
|
||||
"Kwai-Kolors/Kolors.description": "Kolors es un modelo de difusión latente a gran escala de texto a imagen del equipo Kolors de Kuaishou. Entrenado con miles de millones de pares texto-imagen, sobresale en calidad visual, precisión semántica compleja y renderizado de texto en chino/inglés, con sólida comprensión y generación de contenido en chino.",
|
||||
"Ling-2.5-1T.description": "Como el último modelo insignia en tiempo real de la serie Ling, Ling-2.5-1T introduce mejoras integrales en la arquitectura del modelo, eficiencia de tokens y alineación de preferencias, con el objetivo de elevar la calidad de la IA accesible a un nuevo nivel.",
|
||||
"Ling-2.6-1T.description": "El último modelo insignia de lenguaje a gran escala, con soporte para una ventana de contexto de 1M tokens, que permite un flujo de trabajo completo desde el razonamiento lógico hasta la ejecución de tareas.",
|
||||
"Ling-2.6-flash.description": "Ling-2.6-flash es el modelo de última generación con alta relación costo-rendimiento de la serie Ling. Adopta una arquitectura de Mixture-of-Experts (MoE), con un total de 100B parámetros y 6.1B parámetros activados por token, logrando un equilibrio óptimo entre rendimiento de inferencia y costo computacional.",
|
||||
"Llama-3.2-11B-Vision-Instruct.description": "Razonamiento visual sólido en imágenes de alta resolución, ideal para aplicaciones de comprensión visual.",
|
||||
"Llama-3.2-90B-Vision-Instruct\t.description": "Razonamiento visual avanzado para aplicaciones de agentes con comprensión visual.",
|
||||
"Llama-3.2-90B-Vision-Instruct.description": "Razonamiento avanzado de imágenes para aplicaciones de agentes de comprensión visual.",
|
||||
"LongCat-2.0-Preview.description": "Las funciones principales de LongCat‑2.0‑Preview son las siguientes: diseñado para escenarios de desarrollo de agentes, con compatibilidad nativa para el uso de herramientas, razonamiento de varios pasos y tareas de contexto largo; destaca en generación de código, flujos de trabajo automatizados y ejecución de instrucciones complejas; profundamente integrado con herramientas de productividad como Claude Code, OpenClaw, OpenCode y Kilo Code.",
|
||||
"LongCat-Flash-Chat.description": "El modelo LongCat-Flash-Chat ha sido actualizado a una nueva versión. Esta actualización incluye mejoras únicamente en las capacidades del modelo; el nombre del modelo y el método de invocación de la API permanecen sin cambios. Basándose en su característica distintiva de \"eficiencia extrema\" y \"respuesta ultrarrápida\", la nueva versión refuerza aún más la comprensión contextual y el rendimiento en programación del mundo real: Capacidades de codificación significativamente mejoradas: Optimizado profundamente para escenarios centrados en desarrolladores, el modelo ofrece mejoras sustanciales en generación de código, depuración y tareas de explicación. Se anima encarecidamente a los desarrolladores a evaluar y comparar estas mejoras. Soporte para contexto ultra largo de 256K: La ventana de contexto se ha duplicado respecto a la generación anterior (128K) a 256K, permitiendo un procesamiento eficiente de documentos masivos y tareas de secuencia larga. Rendimiento multilingüe mejorado integralmente: Ofrece un sólido soporte para nueve idiomas, incluidos español, francés, árabe, portugués, ruso e indonesio. Capacidades de agente más poderosas: Demuestra mayor robustez y eficiencia en la invocación de herramientas complejas y la ejecución de tareas de múltiples pasos.",
|
||||
"LongCat-Flash-Lite.description": "El modelo LongCat-Flash-Lite ha sido lanzado oficialmente. Adopta una arquitectura eficiente de Mezcla de Expertos (MoE), con un total de 68.5 mil millones de parámetros y aproximadamente 3 mil millones de parámetros activados. A través del uso de una tabla de incrustación N-gram, logra una utilización altamente eficiente de parámetros y está profundamente optimizado para la eficiencia de inferencia y escenarios de aplicación específicos. En comparación con modelos de escala similar, sus características principales son las siguientes: Eficiencia de inferencia sobresaliente: Aprovechando la tabla de incrustación N-gram para aliviar fundamentalmente el cuello de botella de E/S inherente a las arquitecturas MoE, combinado con mecanismos de almacenamiento en caché dedicados y optimizaciones a nivel de núcleo, reduce significativamente la latencia de inferencia y mejora la eficiencia general. Rendimiento fuerte en agentes y codificación: Demuestra capacidades altamente competitivas en la invocación de herramientas y tareas de desarrollo de software, ofreciendo un rendimiento excepcional en relación con su tamaño de modelo.",
|
||||
"LongCat-Flash-Thinking-2601.description": "El modelo LongCat-Flash-Thinking-2601 ha sido lanzado oficialmente. Como un modelo de razonamiento mejorado basado en una arquitectura de Mezcla de Expertos (MoE), cuenta con un total de 560 mil millones de parámetros. Mientras mantiene una fuerte competitividad en los puntos de referencia tradicionales de razonamiento, mejora sistemáticamente las capacidades de razonamiento a nivel de agente a través de aprendizaje por refuerzo en múltiples entornos a gran escala. En comparación con el modelo LongCat-Flash-Thinking, las actualizaciones clave son las siguientes: Robustez extrema en entornos ruidosos: A través de un entrenamiento sistemático estilo currículo dirigido al ruido y la incertidumbre en entornos del mundo real, el modelo demuestra un rendimiento sobresaliente en la invocación de herramientas de agente, búsqueda basada en agentes y razonamiento integrado con herramientas, con una generalización significativamente mejorada. Capacidades de agente poderosas: Construyendo un gráfico de dependencia estrechamente acoplado que abarca más de 60 herramientas y escalando el entrenamiento mediante expansión en múltiples entornos y aprendizaje exploratorio a gran escala, el modelo mejora notablemente su capacidad para generalizar a escenarios complejos y fuera de distribución en el mundo real. Modo de pensamiento profundo avanzado: Expande la amplitud del razonamiento mediante inferencia paralela y profundiza la capacidad analítica a través de mecanismos de resumen y abstracción impulsados por retroalimentación recursiva, abordando eficazmente problemas altamente desafiantes.",
|
||||
"LongCat-Flash-Thinking.description": "Para garantizar un rendimiento de razonamiento de primera categoría, la plataforma LongCat API ha unificado y actualizado las llamadas al modelo LongCat‑Flash‑Thinking. Todas las solicitudes existentes que utilicen `model=LongCat-Flash-Thinking` se redirigirán automáticamente a la versión más reciente, LongCat‑Flash‑Thinking‑2601, sin necesidad de cambiar el código.",
|
||||
"M2-her.description": "Un modelo de diálogo de texto diseñado para juegos de rol y conversaciones de múltiples turnos, con personalización de personajes y expresión emocional.",
|
||||
"Meta-Llama-3-3-70B-Instruct.description": "Llama 3.3 70B es un modelo Transformer versátil para tareas de chat y generación.",
|
||||
"Meta-Llama-3.1-405B-Instruct.description": "Modelo de texto ajustado por instrucciones Llama 3.1, optimizado para chat multilingüe. Destaca en los principales benchmarks de la industria entre modelos abiertos y cerrados.",
|
||||
@@ -187,27 +186,10 @@
|
||||
"Qwen2.5-Coder-14B-Instruct.description": "Qwen2.5-Coder-14B-Instruct es un modelo de instrucciones de codificación preentrenado a gran escala con sólida comprensión y generación de código. Maneja eficientemente una amplia gama de tareas de programación, ideal para codificación inteligente, generación automática de scripts y preguntas y respuestas sobre programación.",
|
||||
"Qwen2.5-Coder-32B-Instruct.description": "LLM avanzado para generación de código, razonamiento y corrección de errores en los principales lenguajes de programación.",
|
||||
"Qwen3-235B-A22B-Instruct-2507-FP8.description": "Qwen3 235B A22B Instruct 2507 está optimizado para razonamiento avanzado y seguimiento de instrucciones, utilizando MoE para mantener la eficiencia del razonamiento a gran escala.",
|
||||
"Qwen3-235B.description": "Qwen3-235B-A22B es un modelo MoE que introduce un modo de razonamiento híbrido, permitiendo a los usuarios cambiar sin problemas entre pensamiento y no pensamiento. Admite comprensión y razonamiento en 119 idiomas y dialectos, y tiene sólidas capacidades de llamada a herramientas, compitiendo con modelos como DeepSeek R1, OpenAI o1, o3-mini, Grok 3 y Google Gemini 2.5 Pro en benchmarks de capacidad general, código y matemáticas, capacidad multilingüe y razonamiento de conocimiento.",
|
||||
"Qwen3-32B.description": "Qwen3-32B es un modelo denso que introduce un modo de razonamiento híbrido, permitiendo a los usuarios cambiar entre pensamiento y no pensamiento. Con mejoras en la arquitectura, más datos y mejor entrenamiento, su rendimiento es comparable al de Qwen2.5-72B.",
|
||||
"Qwen3.5-Plus.description": "Qwen3.5 Plus soporta entrada de texto, imagen y video. Su rendimiento en tareas de solo texto es comparable al de Qwen3 Max, con mejor rendimiento y menor costo. Sus capacidades multimodales mejoran significativamente frente a la serie Qwen3 VL.",
|
||||
"Ring-2.5-1T.description": "En comparación con el Ring-1T previamente lanzado, Ring-2.5-1T logra mejoras significativas en tres dimensiones clave: Eficiencia de Generación**: Al aprovechar una alta proporción de mecanismos de atención lineal, Ring-2.5-1T reduce la sobrecarga de acceso a memoria en más de 10×. Al procesar secuencias que superan los 32K tokens, ofrece más de 3× mayor rendimiento de generación, lo que lo hace particularmente adecuado para razonamiento profundo y ejecución de tareas de largo alcance. Razonamiento Profundo**: Basándose en RLVR, se introduce un mecanismo de recompensa densa para proporcionar retroalimentación sobre el rigor del proceso de razonamiento. Esto permite que Ring-2.5-1T alcance un rendimiento de nivel medalla de oro tanto en IMO 2025 como en CMO 2025 (autoevaluado). Ejecución de Tareas de Largo Alcance**: A través de entrenamiento de aprendizaje por refuerzo basado en agentes completamente asincrónico a gran escala, el modelo mejora significativamente su capacidad para ejecutar tareas complejas de manera autónoma durante períodos prolongados. Esto permite que Ring-2.5-1T se integre perfectamente con marcos de programación de agentes como Claude Code y asistentes personales de IA OpenClaw.",
|
||||
"Ring-2.6-1T.description": "Ring-2.6-1T es un modelo de razonamiento a escala de un billón de parámetros que activa aproximadamente 63B parámetros por inferencia. Diseñado para flujos de trabajo de agentes, se centra en capacidades de agentes, uso de herramientas y ejecución de tareas de largo alcance, logrando un rendimiento líder en estándares como PinchBench, ClawEval, TAU2-Bench y GAIA2-search. El modelo está optimizado en calidad de ejecución, latencia y costo, lo que lo hace ideal para agentes avanzados de programación, tuberías de razonamiento complejo y sistemas autónomos a gran escala.",
|
||||
"S2V-01.description": "El modelo base de referencia a video de la serie 01.",
|
||||
"SenseChat-128K.description": "Base V4 con contexto de 128K, excelente en comprensión y generación de textos largos.",
|
||||
"SenseChat-32K.description": "Base V4 con contexto de 32K, flexible para múltiples escenarios.",
|
||||
"SenseChat-5-1202.description": "Versión más reciente basada en V5.5, con mejoras significativas en fundamentos de chino/inglés, conversación, conocimientos STEM, humanidades, redacción, matemáticas/lógica y control de longitud.",
|
||||
"SenseChat-5-Cantonese.description": "Diseñado para los hábitos de conversación, jerga y conocimientos locales de Hong Kong; supera a GPT-4 en comprensión del cantonés y rivaliza con GPT-4 Turbo en conocimientos, razonamiento, matemáticas y programación.",
|
||||
"SenseChat-5-beta.description": "En algunos aspectos, su rendimiento supera al de SenseChat-5-1202.",
|
||||
"SenseChat-5.description": "Última versión V5.5 con contexto de 128K; grandes avances en razonamiento matemático, conversación en inglés, seguimiento de instrucciones y comprensión de textos largos, comparable a GPT-4o.",
|
||||
"SenseChat-Character-Pro.description": "Modelo avanzado de conversación con personajes, con contexto de 32K, mayor capacidad y soporte en chino/inglés.",
|
||||
"SenseChat-Character.description": "Modelo estándar de conversación con personajes, con contexto de 8K y alta velocidad de respuesta.",
|
||||
"SenseChat-Turbo-1202.description": "Último modelo liviano que alcanza más del 90% de la capacidad del modelo completo con un costo de inferencia significativamente menor.",
|
||||
"SenseChat-Turbo.description": "Adecuado para preguntas y respuestas rápidas y escenarios de ajuste fino del modelo.",
|
||||
"SenseChat-Vision.description": "Última versión V5.5 con entrada de múltiples imágenes y amplias mejoras en reconocimiento de atributos, relaciones espaciales, detección de acciones/eventos, comprensión de escenas, reconocimiento de emociones, razonamiento de sentido común y comprensión/generación de texto.",
|
||||
"SenseChat.description": "Base V4 con contexto de 4K y gran capacidad general.",
|
||||
"SenseNova-V6-5-Pro.description": "Con actualizaciones integrales en datos multimodales, lingüísticos y de razonamiento, además de optimización de estrategias de entrenamiento, el nuevo modelo mejora significativamente el razonamiento multimodal y el seguimiento de instrucciones generalizadas, admite hasta 128K de contexto y destaca en tareas de OCR y reconocimiento de IP de turismo cultural.",
|
||||
"SenseNova-V6-5-Turbo.description": "Con actualizaciones integrales en datos multimodales, lingüísticos y de razonamiento, además de optimización de estrategias de entrenamiento, el nuevo modelo mejora significativamente el razonamiento multimodal y el seguimiento de instrucciones generalizadas, admite hasta 128K de contexto y destaca en tareas de OCR y reconocimiento de IP de turismo cultural.",
|
||||
"SenseNova-V6-Pro.description": "Unifica de forma nativa imagen, texto y video, rompiendo los silos multimodales tradicionales; lidera en OpenCompass y SuperCLUE.",
|
||||
"SenseNova-V6-Reasoner.description": "Combina visión y lenguaje con razonamiento profundo, compatible con pensamiento lento y cadena completa de razonamiento.",
|
||||
"SenseNova-V6-Turbo.description": "Unifica de forma nativa imagen, texto y video, rompiendo los silos multimodales tradicionales. Lidera en capacidades lingüísticas y multimodales clave, y se ubica en el nivel superior en múltiples evaluaciones.",
|
||||
"Skylark2-lite-8k.description": "Modelo Skylark de segunda generación. Skylark2-lite ofrece respuestas rápidas para escenarios en tiempo real y sensibles al costo, con menores requisitos de precisión y una ventana de contexto de 8K.",
|
||||
"Skylark2-pro-32k.description": "Modelo Skylark de segunda generación. Skylark2-pro ofrece mayor precisión para generación de texto compleja como redacción profesional, escritura de novelas y traducción de alta calidad, con una ventana de contexto de 32K.",
|
||||
"Skylark2-pro-4k.description": "Modelo Skylark de segunda generación. Skylark2-pro ofrece mayor precisión para generación de texto compleja como redacción profesional, escritura de novelas y traducción de alta calidad, con una ventana de contexto de 4K.",
|
||||
@@ -1197,6 +1179,8 @@
|
||||
"r1-1776.description": "R1-1776 es una variante postentrenada de DeepSeek R1 diseñada para proporcionar información factual sin censura ni sesgo.",
|
||||
"seedance-1-5-pro-251215.description": "Seedance 1.5 Pro de ByteDance soporta texto a video, imagen a video (primer cuadro, primer+último cuadro) y generación de audio sincronizado con visuales.",
|
||||
"seedream-5-0-260128.description": "ByteDance-Seedream-5.0-lite de BytePlus presenta generación aumentada con recuperación web para información en tiempo real, interpretación mejorada de indicaciones complejas y mayor consistencia de referencia para creación visual profesional.",
|
||||
"sensenova-6.7-flash-lite.description": "Un modelo de agente multimodal ligero diseñado para flujos de trabajo del mundo real, que admite tanto conversaciones basadas en texto como comprensión de imágenes. Ligero y eficiente, equilibrando rendimiento, costo y capacidad de implementación. Arquitectura multimodal nativa con soporte para comprensión de imágenes, incluyendo OCR e interpretación de gráficos. Mejorado para escenarios de oficina y productividad, con soporte estable para tareas complejas de cadena larga. Eficiencia mejorada de tokens, permitiendo un mejor control de costos para cargas de trabajo complejas. Longitud de contexto de 256K tokens (entrada máxima: 252K, salida máxima: 64K).",
|
||||
"sensenova-u1-fast.description": "Una versión acelerada basada en SenseNova U1, específicamente optimizada para la generación de infografías.",
|
||||
"solar-mini-ja.description": "Solar Mini (Ja) amplía Solar Mini con un enfoque en japonés, manteniendo un rendimiento eficiente y sólido en inglés y coreano.",
|
||||
"solar-mini.description": "Solar Mini es un modelo LLM compacto que supera a GPT-3.5, con una sólida capacidad multilingüe compatible con inglés y coreano, ofreciendo una solución eficiente de bajo consumo.",
|
||||
"solar-pro.description": "Solar Pro es un LLM de alta inteligencia de Upstage, enfocado en el seguimiento de instrucciones en una sola GPU, con puntuaciones IFEval superiores a 80. Actualmente admite inglés; el lanzamiento completo estaba previsto para noviembre de 2024 con soporte de idiomas ampliado y contexto más largo.",
|
||||
|
||||
@@ -17,6 +17,8 @@
|
||||
"storage_overage_cap_reached_title": "Límite de pago por uso de almacenamiento alcanzado",
|
||||
"video_generation_completed": "Tu video \"{{prompt}}\" está listo.",
|
||||
"video_generation_completed_title": "Generación de video completada",
|
||||
"workspace_member_invited": "{{inviterLabel}} te ha invitado a unirte al espacio de trabajo \"{{workspaceName}}\" como {{role}}.",
|
||||
"workspace_member_invited_title": "Invitación para unirte a {{workspaceName}}",
|
||||
"workspace_member_joined": "{{memberLabel}} se unió al espacio de trabajo \"{{workspaceName}}\" como {{role}}.",
|
||||
"workspace_member_joined_member": "{{memberLabel}} se unió al espacio de trabajo \"{{workspaceName}}\" como Miembro.",
|
||||
"workspace_member_joined_member_title": "Nuevo miembro se unió a {{workspaceName}}",
|
||||
|
||||
@@ -1,6 +1,34 @@
|
||||
{
|
||||
"arguments.moreParams": "{{count}} parámetros en total",
|
||||
"arguments.title": "Argumentos",
|
||||
"builtins.codex.apiName.collab_tool_call": "Coordinar subagentes",
|
||||
"builtins.codex.apiName.command_execution": "Ejecutar comando",
|
||||
"builtins.codex.apiName.file_change": "Editar archivos",
|
||||
"builtins.codex.apiName.mcp_tool_call": "Llamar herramienta MCP",
|
||||
"builtins.codex.apiName.todo_list": "Actualizar tareas",
|
||||
"builtins.codex.apiName.web_search": "Buscar en la web",
|
||||
"builtins.codex.collabTool.agentCount_one": "{{count}} subagente",
|
||||
"builtins.codex.collabTool.agentCount_other": "{{count}} subagentes",
|
||||
"builtins.codex.collabTool.agentLabel": "Subagente {{index}}",
|
||||
"builtins.codex.collabTool.agents": "Subagentes",
|
||||
"builtins.codex.collabTool.closeAgent": "Cerrar subagente",
|
||||
"builtins.codex.collabTool.instruction": "Instrucción",
|
||||
"builtins.codex.collabTool.sendInput": "Enviar mensaje al subagente",
|
||||
"builtins.codex.collabTool.spawnAgent": "Generar subagente",
|
||||
"builtins.codex.collabTool.wait": "Esperar a los subagentes",
|
||||
"builtins.codex.commandExecution.grep": "Buscar",
|
||||
"builtins.codex.commandExecution.noResults": "Sin resultados",
|
||||
"builtins.codex.commandExecution.readFile": "Leer archivo",
|
||||
"builtins.codex.fileChange.editedFiles_one": "Editado {{count}} archivo",
|
||||
"builtins.codex.fileChange.editedFiles_other": "Editados {{count}} archivos",
|
||||
"builtins.codex.fileChange.editing": "Editando archivos",
|
||||
"builtins.codex.fileChange.noChanges": "Sin cambios en los archivos",
|
||||
"builtins.codex.fileChange.unknownFile": "Archivo desconocido",
|
||||
"builtins.codex.mcpTool.error": "Error",
|
||||
"builtins.codex.mcpTool.input": "Entrada",
|
||||
"builtins.codex.mcpTool.result": "Resultado",
|
||||
"builtins.codex.mcpTool.unknownTool": "Herramienta MCP",
|
||||
"builtins.codex.webSearch.query": "Consulta",
|
||||
"builtins.lobe-activator.apiName.activateTools": "Activar Herramientas",
|
||||
"builtins.lobe-activator.inspector.activateTools.notFoundCount": "{{count}} no encontrado",
|
||||
"builtins.lobe-agent-builder.apiName.getAvailableModels": "Obtener modelos disponibles",
|
||||
@@ -429,6 +457,15 @@
|
||||
"dev.mcp.auth.desc": "Selecciona el método de autenticación para el servidor MCP",
|
||||
"dev.mcp.auth.label": "Tipo de autenticación",
|
||||
"dev.mcp.auth.none": "Sin autenticación",
|
||||
"dev.mcp.auth.oauth": "OAuth",
|
||||
"dev.mcp.auth.oauth.authorize": "Autorizar y Conectar",
|
||||
"dev.mcp.auth.oauth.clientId.desc": "Déjelo vacío para registrar un cliente automáticamente (registro dinámico de clientes)",
|
||||
"dev.mcp.auth.oauth.clientId.label": "ID de Cliente OAuth",
|
||||
"dev.mcp.auth.oauth.clientId.placeholder": "Opcional",
|
||||
"dev.mcp.auth.oauth.clientSecret.desc": "Solo requerido para clientes OAuth confidenciales",
|
||||
"dev.mcp.auth.oauth.clientSecret.label": "Secreto de Cliente OAuth",
|
||||
"dev.mcp.auth.oauth.clientSecret.placeholder": "Opcional",
|
||||
"dev.mcp.auth.oauth.redirectHint": "URI de redirección para registrar con su aplicación OAuth:",
|
||||
"dev.mcp.auth.placeholder": "Selecciona tipo de autenticación",
|
||||
"dev.mcp.auth.token.desc": "Introduce tu clave API o token Bearer",
|
||||
"dev.mcp.auth.token.label": "Clave API",
|
||||
|
||||
@@ -4,6 +4,7 @@
|
||||
"ai360.description": "360 AI es una plataforma de modelos y servicios de 360, que ofrece modelos de PLN como 360GPT2 Pro, 360GPT Pro y 360GPT Turbo. Estos modelos combinan parámetros a gran escala y capacidades multimodales para generación de texto, comprensión semántica, chat y código, con precios flexibles para diversas necesidades.",
|
||||
"aihubmix.description": "AiHubMix proporciona acceso a múltiples modelos de IA a través de una API unificada.",
|
||||
"akashchat.description": "Akash es un mercado de recursos en la nube sin permisos, con precios competitivos frente a los proveedores tradicionales.",
|
||||
"antgroup.description": "Ant Ling es la serie de modelos fundamentales del núcleo de la iniciativa de Inteligencia General Artificial (AGI) de Ant Group, dedicada a construir y abrir capacidades avanzadas de modelos fundamentales. Creemos que el desarrollo de la inteligencia debe avanzar hacia la apertura, el intercambio y la escalabilidad, comenzando con pequeños pasos prácticos para impulsar la evolución constante y la implementación en el mundo real de la AGI.",
|
||||
"anthropic.description": "Anthropic desarrolla modelos de lenguaje avanzados como Claude 3.5 Sonnet, Claude 3 Sonnet, Claude 3 Opus y Claude 3 Haiku, equilibrando inteligencia, velocidad y costo para cargas de trabajo empresariales y de respuesta rápida.",
|
||||
"azure.description": "Azure ofrece modelos de IA avanzados, incluyendo las series GPT-3.5 y GPT-4, para diversos tipos de datos y tareas complejas, con un enfoque en IA segura, confiable y sostenible.",
|
||||
"azureai.description": "Azure proporciona modelos de IA avanzados, incluyendo las series GPT-3.5 y GPT-4, para diversos tipos de datos y tareas complejas, con un enfoque en IA segura, confiable y sostenible.",
|
||||
|
||||
@@ -280,7 +280,33 @@
|
||||
"defaultAgent.title": "Configuración Predeterminada del Agente",
|
||||
"devices.actions.edit": "Editar",
|
||||
"devices.actions.remove": "Eliminar",
|
||||
"devices.capabilities.commands.desc": "Ejecuta comandos de terminal de forma segura en tu entorno.",
|
||||
"devices.capabilities.commands.title": "Ejecutar comandos",
|
||||
"devices.capabilities.files.desc": "Permite que los agentes accedan y organicen directamente los archivos en tu computadora.",
|
||||
"devices.capabilities.files.title": "Leer y escribir archivos locales",
|
||||
"devices.capabilities.title": "Lo que puedes hacer una vez conectado",
|
||||
"devices.capabilities.tools.desc": "Conecta herramientas locales para ampliar lo que los agentes pueden hacer.",
|
||||
"devices.capabilities.tools.title": "Usar herramientas del sistema",
|
||||
"devices.channel.connected": "Conectado {{time}}",
|
||||
"devices.connectWizard.button": "Conectar dispositivo",
|
||||
"devices.connectWizard.cli.connectDesc": "Inicia el demonio en segundo plano para mantener el dispositivo en línea y disponible para operaciones remotas.",
|
||||
"devices.connectWizard.cli.connectTitle": "Iniciar el demonio",
|
||||
"devices.connectWizard.cli.installDesc": "Instala el CLI de LobeHub globalmente con tu gestor de paquetes preferido para habilitar la conectividad y gestión del dispositivo.",
|
||||
"devices.connectWizard.cli.installTitle": "Instalar el CLI",
|
||||
"devices.connectWizard.cli.loginDesc": "Completa la autorización OAuth en tu navegador para vincular el CLI con tu cuenta.",
|
||||
"devices.connectWizard.cli.loginTitle": "Iniciar sesión",
|
||||
"devices.connectWizard.desktop.downloadLink": "Descargar LobeHub Desktop",
|
||||
"devices.connectWizard.desktop.step1": "Descarga la aplicación de escritorio",
|
||||
"devices.connectWizard.desktop.step1Desc": "Visita la página de descargas de LobeHub y obtén la aplicación para tu sistema operativo.",
|
||||
"devices.connectWizard.desktop.step2": "Inicia sesión y abre el portal de dispositivos",
|
||||
"devices.connectWizard.desktop.step2Desc": "Después de iniciar sesión, haz clic en el ícono del portal de dispositivos en la esquina superior derecha y confirma que está activado.",
|
||||
"devices.connectWizard.desktop.step3": "Tu dispositivo aparece automáticamente",
|
||||
"devices.connectWizard.desktop.step3Desc": "La aplicación de escritorio se registra como un dispositivo al iniciarse — lo verás en la lista una vez conectado.",
|
||||
"devices.connectWizard.footer": "Solo se registra la metadata del dispositivo — tus datos nunca son accesados.",
|
||||
"devices.connectWizard.method.cli": "A través del CLI",
|
||||
"devices.connectWizard.method.desktop": "A través de la aplicación de escritorio",
|
||||
"devices.connectWizard.subtitle": "Elige cómo conectar tu computadora a LobeHub.",
|
||||
"devices.connectWizard.title": "Conectar dispositivo",
|
||||
"devices.currentBadge": "Este dispositivo",
|
||||
"devices.detail.addDir": "Agregar directorio",
|
||||
"devices.detail.connections": "Conexiones",
|
||||
@@ -294,7 +320,13 @@
|
||||
"devices.edit.friendlyNamePlaceholder": "Un nombre para reconocer este dispositivo",
|
||||
"devices.edit.save": "Guardar",
|
||||
"devices.edit.title": "Editar dispositivo",
|
||||
"devices.empty": "Aún no hay dispositivos. Conecta uno con `lh connect` o iniciando sesión en la aplicación de escritorio.",
|
||||
"devices.empty.desc": "Una vez conectado, los agentes de LobeHub pueden leer/escribir archivos, ejecutar comandos y usar herramientas del sistema directamente en tu computadora.",
|
||||
"devices.empty.methodCli.desc": "Instala el CLI en tu terminal — ideal para servidores o máquinas sin interfaz gráfica.",
|
||||
"devices.empty.methodCli.title": "Conectar a través del CLI",
|
||||
"devices.empty.methodDesktop.badge": "Recomendado",
|
||||
"devices.empty.methodDesktop.desc": "Descarga la aplicación de escritorio, inicia sesión y tu dispositivo se conecta automáticamente.",
|
||||
"devices.empty.methodDesktop.title": "Conectar a través de la aplicación de escritorio",
|
||||
"devices.empty.title": "Conecta tu primer dispositivo",
|
||||
"devices.fallbackBadge": "Identidad inestable",
|
||||
"devices.fallbackTooltip": "Este dispositivo no pudo ser identificado por su ID de máquina, por lo que reinstalar la aplicación puede crear una entrada duplicada.",
|
||||
"devices.lastSeen": "Última actividad {{time}}",
|
||||
@@ -522,6 +554,7 @@
|
||||
"notification.item.image_generation_completed": "Generación de imagen completada",
|
||||
"notification.item.storage_overage_cap_reached": "Se alcanzó el límite de almacenamiento por uso adicional",
|
||||
"notification.item.video_generation_completed": "Generación de vídeo completada",
|
||||
"notification.item.workspace_member_invited": "Invitación al espacio de trabajo",
|
||||
"notification.item.workspace_member_joined": "Nuevo miembro se unió",
|
||||
"notification.item.workspace_member_removed": "Eliminado del espacio de trabajo",
|
||||
"notification.item.workspace_payment_failed": "Error en el pago de renovación",
|
||||
@@ -1766,6 +1799,7 @@
|
||||
"workspace.members.invite.errors.alreadyMember": "{{email}} ya es miembro de este espacio de trabajo.",
|
||||
"workspace.members.invite.failed": "Error al enviar la invitación",
|
||||
"workspace.members.invite.limitReached": "Este espacio de trabajo puede tener hasta {{limit}} miembros. Elimina un miembro antes de invitar a más.",
|
||||
"workspace.members.invite.modal.billIncrease": "Tu factura aumentará en ${{amount}}/mes.",
|
||||
"workspace.members.invite.modal.cancel": "Cancelar",
|
||||
"workspace.members.invite.modal.confirm": "Confirmar",
|
||||
"workspace.members.invite.modal.description_one": "¡Tu equipo está creciendo! Al confirmar, invitarás a 1 nuevo miembro del equipo a este espacio de trabajo.",
|
||||
@@ -1873,6 +1907,7 @@
|
||||
"workspace.upgradeModal.chargeDisclosure": "Al hacer clic en Actualizar, se te cobrará ${{fee}}, más cualquier impuesto y tarifa aplicable, inmediatamente y luego cada mes, hasta que canceles. Las tarifas de asiento y el uso bajo demanda se liquidan al final del mes; si tu uso excede un umbral de facturación durante un ciclo, el método de pago registrado puede ser cargado antes de que termine el ciclo.",
|
||||
"workspace.upgradeModal.continueCta": "Continuar",
|
||||
"workspace.upgradeModal.createTeam": "Crear espacio de trabajo",
|
||||
"workspace.upgradeModal.formDescription": "Revisa los detalles a continuación y confirma tu actualización.",
|
||||
"workspace.upgradeModal.formSubtitle": "Solo se cobra la tarifa de plataforma hoy — las tarifas de asiento se liquidan al final del mes.",
|
||||
"workspace.upgradeModal.formTitle": "Actualizar {{name}} a Pro",
|
||||
"workspace.upgradeModal.heading": "Actualizar un espacio de trabajo a Pro",
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user