mirror of
https://github.com/lobehub/lobe-chat.git
synced 2026-06-14 03:30:19 +00:00
Compare commits
16 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
5f157dab7a | ||
|
|
976f38592f | ||
|
|
c08ec498cf | ||
|
|
f33f7e6311 | ||
|
|
679dbb076a | ||
|
|
bba6bbf507 | ||
|
|
7fa4c0152e | ||
|
|
68f2062dae | ||
|
|
431153e6f5 | ||
|
|
81326f12cb | ||
|
|
5a8db1a696 | ||
|
|
eb34aef05a | ||
|
|
3d9e037b21 | ||
|
|
f41cca5825 | ||
|
|
d6d9fc3324 | ||
|
|
75ddd06474 |
@@ -0,0 +1,552 @@
|
||||
import { mkdtemp, writeFile } from 'node:fs/promises';
|
||||
import { tmpdir } from 'node:os';
|
||||
import path from 'node:path';
|
||||
|
||||
import { Command } from 'commander';
|
||||
import { afterEach, beforeEach, describe, expect, it, vi } from 'vitest';
|
||||
|
||||
import { registerBotMessageCommands } from './botMessage';
|
||||
|
||||
const { mockTrpcClient } = vi.hoisted(() => ({
|
||||
mockTrpcClient: {
|
||||
botMessage: {
|
||||
listOutboundChannels: { query: vi.fn() },
|
||||
replyToThread: { mutate: vi.fn() },
|
||||
sendDirectMessage: { mutate: vi.fn() },
|
||||
sendMessage: { mutate: vi.fn() },
|
||||
},
|
||||
},
|
||||
}));
|
||||
|
||||
const { getTrpcClient: mockGetTrpcClient } = vi.hoisted(() => ({
|
||||
getTrpcClient: vi.fn(),
|
||||
}));
|
||||
|
||||
vi.mock('../api/client', () => ({ getTrpcClient: mockGetTrpcClient }));
|
||||
vi.mock('../utils/logger', () => ({
|
||||
log: { debug: vi.fn(), error: vi.fn(), info: vi.fn(), warn: vi.fn() },
|
||||
setVerbose: vi.fn(),
|
||||
}));
|
||||
|
||||
describe('bot message send --attachment', () => {
|
||||
let exitSpy: ReturnType<typeof vi.spyOn>;
|
||||
let consoleSpy: ReturnType<typeof vi.spyOn>;
|
||||
|
||||
beforeEach(() => {
|
||||
exitSpy = vi.spyOn(process, 'exit').mockImplementation((() => {}) as any);
|
||||
consoleSpy = vi.spyOn(console, 'log').mockImplementation(() => {});
|
||||
mockGetTrpcClient.mockResolvedValue(mockTrpcClient);
|
||||
mockTrpcClient.botMessage.sendMessage.mutate.mockReset();
|
||||
mockTrpcClient.botMessage.sendMessage.mutate.mockResolvedValue({ messageId: 'm-1' });
|
||||
mockTrpcClient.botMessage.sendDirectMessage.mutate.mockReset();
|
||||
mockTrpcClient.botMessage.sendDirectMessage.mutate.mockResolvedValue({
|
||||
channelId: 'dm-1',
|
||||
messageId: 'm-dm-1',
|
||||
});
|
||||
mockTrpcClient.botMessage.replyToThread.mutate.mockReset();
|
||||
mockTrpcClient.botMessage.replyToThread.mutate.mockResolvedValue({ messageId: 'm-tr-1' });
|
||||
});
|
||||
|
||||
afterEach(() => {
|
||||
exitSpy.mockRestore();
|
||||
consoleSpy.mockRestore();
|
||||
});
|
||||
|
||||
function createProgram() {
|
||||
const program = new Command();
|
||||
program.exitOverride();
|
||||
const bot = program.command('bot');
|
||||
registerBotMessageCommands(bot);
|
||||
return program;
|
||||
}
|
||||
|
||||
it('passes a remote URL through as fetchUrl', async () => {
|
||||
const program = createProgram();
|
||||
await program.parseAsync([
|
||||
'node',
|
||||
'test',
|
||||
'bot',
|
||||
'message',
|
||||
'send',
|
||||
'bot-1',
|
||||
'--target',
|
||||
'ch-1',
|
||||
'--message',
|
||||
'hi',
|
||||
'--attachment',
|
||||
'https://cdn.example.com/foo.png',
|
||||
]);
|
||||
|
||||
expect(mockTrpcClient.botMessage.sendMessage.mutate).toHaveBeenCalledWith(
|
||||
expect.objectContaining({
|
||||
attachments: [
|
||||
expect.objectContaining({
|
||||
fetchUrl: 'https://cdn.example.com/foo.png',
|
||||
mimeType: 'image/png',
|
||||
name: 'foo.png',
|
||||
type: 'image',
|
||||
}),
|
||||
],
|
||||
botId: 'bot-1',
|
||||
channelId: 'ch-1',
|
||||
content: 'hi',
|
||||
}),
|
||||
);
|
||||
});
|
||||
|
||||
it('base64-encodes a local file path', async () => {
|
||||
const dir = await mkdtemp(path.join(tmpdir(), 'lh-cli-attach-'));
|
||||
const filePath = path.join(dir, 'tiny.txt');
|
||||
await writeFile(filePath, 'hello');
|
||||
|
||||
const program = createProgram();
|
||||
await program.parseAsync([
|
||||
'node',
|
||||
'test',
|
||||
'bot',
|
||||
'message',
|
||||
'send',
|
||||
'bot-1',
|
||||
'--target',
|
||||
'ch-1',
|
||||
'--message',
|
||||
'm',
|
||||
'--attachment',
|
||||
filePath,
|
||||
]);
|
||||
|
||||
const call = mockTrpcClient.botMessage.sendMessage.mutate.mock.calls[0][0];
|
||||
expect(call.attachments).toHaveLength(1);
|
||||
expect(call.attachments[0]).toMatchObject({
|
||||
mimeType: 'text/plain',
|
||||
name: 'tiny.txt',
|
||||
type: 'file',
|
||||
});
|
||||
expect(call.attachments[0].data).toBe(Buffer.from('hello').toString('base64'));
|
||||
expect(call.attachments[0].fetchUrl).toBeUndefined();
|
||||
});
|
||||
|
||||
it('accepts multiple --attachment flags', async () => {
|
||||
const program = createProgram();
|
||||
await program.parseAsync([
|
||||
'node',
|
||||
'test',
|
||||
'bot',
|
||||
'message',
|
||||
'send',
|
||||
'bot-1',
|
||||
'--target',
|
||||
'ch-1',
|
||||
'--message',
|
||||
'm',
|
||||
'--attachment',
|
||||
'https://cdn.example.com/a.png',
|
||||
'--attachment',
|
||||
'https://cdn.example.com/b.pdf',
|
||||
]);
|
||||
|
||||
const call = mockTrpcClient.botMessage.sendMessage.mutate.mock.calls[0][0];
|
||||
expect(call.attachments).toHaveLength(2);
|
||||
expect(call.attachments[0]).toMatchObject({ type: 'image', name: 'a.png' });
|
||||
expect(call.attachments[1]).toMatchObject({ type: 'file', name: 'b.pdf' });
|
||||
});
|
||||
|
||||
it('omits attachments field when no flag is given', async () => {
|
||||
const program = createProgram();
|
||||
await program.parseAsync([
|
||||
'node',
|
||||
'test',
|
||||
'bot',
|
||||
'message',
|
||||
'send',
|
||||
'bot-1',
|
||||
'--target',
|
||||
'ch-1',
|
||||
'--message',
|
||||
'm',
|
||||
]);
|
||||
|
||||
const call = mockTrpcClient.botMessage.sendMessage.mutate.mock.calls[0][0];
|
||||
expect(call.attachments).toBeUndefined();
|
||||
});
|
||||
});
|
||||
|
||||
describe('bot message dm --attachment', () => {
|
||||
let exitSpy: ReturnType<typeof vi.spyOn>;
|
||||
let consoleSpy: ReturnType<typeof vi.spyOn>;
|
||||
|
||||
beforeEach(() => {
|
||||
exitSpy = vi.spyOn(process, 'exit').mockImplementation((() => {}) as any);
|
||||
consoleSpy = vi.spyOn(console, 'log').mockImplementation(() => {});
|
||||
mockGetTrpcClient.mockResolvedValue(mockTrpcClient);
|
||||
mockTrpcClient.botMessage.sendDirectMessage.mutate.mockReset();
|
||||
mockTrpcClient.botMessage.sendDirectMessage.mutate.mockResolvedValue({
|
||||
channelId: 'dm-1',
|
||||
messageId: 'm-dm-1',
|
||||
});
|
||||
});
|
||||
|
||||
afterEach(() => {
|
||||
exitSpy.mockRestore();
|
||||
consoleSpy.mockRestore();
|
||||
});
|
||||
|
||||
function createProgram() {
|
||||
const program = new Command();
|
||||
program.exitOverride();
|
||||
const bot = program.command('bot');
|
||||
registerBotMessageCommands(bot);
|
||||
return program;
|
||||
}
|
||||
|
||||
it('sends a DM with a remote-URL attachment', async () => {
|
||||
const program = createProgram();
|
||||
await program.parseAsync([
|
||||
'node',
|
||||
'test',
|
||||
'bot',
|
||||
'message',
|
||||
'dm',
|
||||
'bot-1',
|
||||
'--user-id',
|
||||
'u-1',
|
||||
'--message',
|
||||
'hi',
|
||||
'--attachment',
|
||||
'https://cdn.example.com/foo.png',
|
||||
]);
|
||||
|
||||
expect(mockTrpcClient.botMessage.sendDirectMessage.mutate).toHaveBeenCalledWith(
|
||||
expect.objectContaining({
|
||||
attachments: [
|
||||
expect.objectContaining({
|
||||
fetchUrl: 'https://cdn.example.com/foo.png',
|
||||
type: 'image',
|
||||
}),
|
||||
],
|
||||
botId: 'bot-1',
|
||||
content: 'hi',
|
||||
userId: 'u-1',
|
||||
}),
|
||||
);
|
||||
});
|
||||
|
||||
it('omits attachments when no flag is given', async () => {
|
||||
const program = createProgram();
|
||||
await program.parseAsync([
|
||||
'node',
|
||||
'test',
|
||||
'bot',
|
||||
'message',
|
||||
'dm',
|
||||
'bot-1',
|
||||
'--user-id',
|
||||
'u-1',
|
||||
'--message',
|
||||
'plain',
|
||||
]);
|
||||
const call = mockTrpcClient.botMessage.sendDirectMessage.mutate.mock.calls[0][0];
|
||||
expect(call.attachments).toBeUndefined();
|
||||
});
|
||||
});
|
||||
|
||||
describe('bot message thread reply --attachment', () => {
|
||||
let exitSpy: ReturnType<typeof vi.spyOn>;
|
||||
let consoleSpy: ReturnType<typeof vi.spyOn>;
|
||||
|
||||
beforeEach(() => {
|
||||
exitSpy = vi.spyOn(process, 'exit').mockImplementation((() => {}) as any);
|
||||
consoleSpy = vi.spyOn(console, 'log').mockImplementation(() => {});
|
||||
mockGetTrpcClient.mockResolvedValue(mockTrpcClient);
|
||||
mockTrpcClient.botMessage.replyToThread.mutate.mockReset();
|
||||
mockTrpcClient.botMessage.replyToThread.mutate.mockResolvedValue({ messageId: 'm-tr-1' });
|
||||
});
|
||||
|
||||
afterEach(() => {
|
||||
exitSpy.mockRestore();
|
||||
consoleSpy.mockRestore();
|
||||
});
|
||||
|
||||
function createProgram() {
|
||||
const program = new Command();
|
||||
program.exitOverride();
|
||||
const bot = program.command('bot');
|
||||
registerBotMessageCommands(bot);
|
||||
return program;
|
||||
}
|
||||
|
||||
it('replies to a thread with attachments', async () => {
|
||||
const program = createProgram();
|
||||
await program.parseAsync([
|
||||
'node',
|
||||
'test',
|
||||
'bot',
|
||||
'message',
|
||||
'thread',
|
||||
'reply',
|
||||
'bot-1',
|
||||
'--thread-id',
|
||||
'th-1',
|
||||
'--message',
|
||||
'reply',
|
||||
'--attachment',
|
||||
'https://cdn.example.com/a.png',
|
||||
]);
|
||||
|
||||
expect(mockTrpcClient.botMessage.replyToThread.mutate).toHaveBeenCalledWith(
|
||||
expect.objectContaining({
|
||||
attachments: [
|
||||
expect.objectContaining({
|
||||
fetchUrl: 'https://cdn.example.com/a.png',
|
||||
type: 'image',
|
||||
}),
|
||||
],
|
||||
botId: 'bot-1',
|
||||
content: 'reply',
|
||||
threadId: 'th-1',
|
||||
}),
|
||||
);
|
||||
});
|
||||
});
|
||||
|
||||
describe('bot message send via System Bot messenger install (@id)', () => {
|
||||
let exitSpy: ReturnType<typeof vi.spyOn>;
|
||||
let consoleSpy: ReturnType<typeof vi.spyOn>;
|
||||
|
||||
beforeEach(() => {
|
||||
exitSpy = vi.spyOn(process, 'exit').mockImplementation((() => {}) as any);
|
||||
consoleSpy = vi.spyOn(console, 'log').mockImplementation(() => {});
|
||||
mockGetTrpcClient.mockResolvedValue(mockTrpcClient);
|
||||
mockTrpcClient.botMessage.sendMessage.mutate.mockReset();
|
||||
mockTrpcClient.botMessage.sendMessage.mutate.mockResolvedValue({ messageId: 'm-mi-1' });
|
||||
mockTrpcClient.botMessage.sendDirectMessage.mutate.mockReset();
|
||||
mockTrpcClient.botMessage.sendDirectMessage.mutate.mockResolvedValue({ messageId: 'm-mi-2' });
|
||||
mockTrpcClient.botMessage.replyToThread.mutate.mockReset();
|
||||
mockTrpcClient.botMessage.replyToThread.mutate.mockResolvedValue({ messageId: 'm-mi-3' });
|
||||
});
|
||||
|
||||
afterEach(() => {
|
||||
exitSpy.mockRestore();
|
||||
consoleSpy.mockRestore();
|
||||
});
|
||||
|
||||
function createProgram() {
|
||||
const program = new Command();
|
||||
program.exitOverride();
|
||||
const bot = program.command('bot');
|
||||
registerBotMessageCommands(bot);
|
||||
return program;
|
||||
}
|
||||
|
||||
it('@-prefixed positional arg routes to messengerInstallationId on send', async () => {
|
||||
const program = createProgram();
|
||||
await program.parseAsync([
|
||||
'node',
|
||||
'test',
|
||||
'bot',
|
||||
'message',
|
||||
'send',
|
||||
'@inst_abc',
|
||||
'--target',
|
||||
'C1',
|
||||
'--message',
|
||||
'hi',
|
||||
]);
|
||||
|
||||
const call = mockTrpcClient.botMessage.sendMessage.mutate.mock.calls[0][0];
|
||||
expect(call.messengerInstallationId).toBe('inst_abc');
|
||||
expect(call.botId).toBeUndefined();
|
||||
expect(call.channelId).toBe('C1');
|
||||
});
|
||||
|
||||
it('@-prefixed routes on dm', async () => {
|
||||
const program = createProgram();
|
||||
await program.parseAsync([
|
||||
'node',
|
||||
'test',
|
||||
'bot',
|
||||
'message',
|
||||
'dm',
|
||||
'@inst_xyz',
|
||||
'--user-id',
|
||||
'U1',
|
||||
'--message',
|
||||
'hi',
|
||||
]);
|
||||
const call = mockTrpcClient.botMessage.sendDirectMessage.mutate.mock.calls[0][0];
|
||||
expect(call.messengerInstallationId).toBe('inst_xyz');
|
||||
expect(call.botId).toBeUndefined();
|
||||
});
|
||||
|
||||
it('@-prefixed routes on thread reply', async () => {
|
||||
const program = createProgram();
|
||||
await program.parseAsync([
|
||||
'node',
|
||||
'test',
|
||||
'bot',
|
||||
'message',
|
||||
'thread',
|
||||
'reply',
|
||||
'@inst_thr',
|
||||
'--thread-id',
|
||||
'T1',
|
||||
'--message',
|
||||
'r',
|
||||
]);
|
||||
const call = mockTrpcClient.botMessage.replyToThread.mutate.mock.calls[0][0];
|
||||
expect(call.messengerInstallationId).toBe('inst_thr');
|
||||
});
|
||||
|
||||
it('plain (non-@) positional stays as botId', async () => {
|
||||
const program = createProgram();
|
||||
await program.parseAsync([
|
||||
'node',
|
||||
'test',
|
||||
'bot',
|
||||
'message',
|
||||
'send',
|
||||
'uuid-bot-id',
|
||||
'--target',
|
||||
'C1',
|
||||
'--message',
|
||||
'hi',
|
||||
]);
|
||||
const call = mockTrpcClient.botMessage.sendMessage.mutate.mock.calls[0][0];
|
||||
expect(call.botId).toBe('uuid-bot-id');
|
||||
expect(call.messengerInstallationId).toBeUndefined();
|
||||
});
|
||||
});
|
||||
|
||||
describe('bot channels list', () => {
|
||||
let exitSpy: ReturnType<typeof vi.spyOn>;
|
||||
let consoleSpy: ReturnType<typeof vi.spyOn>;
|
||||
|
||||
beforeEach(() => {
|
||||
exitSpy = vi.spyOn(process, 'exit').mockImplementation((() => {}) as any);
|
||||
consoleSpy = vi.spyOn(console, 'log').mockImplementation(() => {});
|
||||
mockGetTrpcClient.mockResolvedValue(mockTrpcClient);
|
||||
mockTrpcClient.botMessage.listOutboundChannels.query.mockReset();
|
||||
});
|
||||
|
||||
afterEach(() => {
|
||||
exitSpy.mockRestore();
|
||||
consoleSpy.mockRestore();
|
||||
});
|
||||
|
||||
function createProgram() {
|
||||
const program = new Command();
|
||||
program.exitOverride();
|
||||
const bot = program.command('bot');
|
||||
registerBotMessageCommands(bot);
|
||||
return program;
|
||||
}
|
||||
|
||||
it('renders the ranked outbound channels table', async () => {
|
||||
mockTrpcClient.botMessage.listOutboundChannels.query.mockResolvedValueOnce([
|
||||
{
|
||||
agentId: 'agent_1',
|
||||
applicationId: 'A1',
|
||||
botId: 'bot_abc',
|
||||
platform: 'discord',
|
||||
recommended: true,
|
||||
source: 'agent_bot',
|
||||
},
|
||||
{
|
||||
applicationId: 'A2',
|
||||
messengerInstallationId: 'inst_xyz',
|
||||
platform: 'discord',
|
||||
recommended: false,
|
||||
source: 'system_messenger',
|
||||
tenantId: 'T1',
|
||||
tenantName: 'Acme Corp',
|
||||
},
|
||||
{
|
||||
applicationId: 'A3',
|
||||
messengerInstallationId: 'inst_slk',
|
||||
platform: 'slack',
|
||||
recommended: true,
|
||||
source: 'system_messenger',
|
||||
tenantId: 'T2',
|
||||
tenantName: 'Other WS',
|
||||
},
|
||||
]);
|
||||
|
||||
const program = createProgram();
|
||||
await program.parseAsync(['node', 'test', 'bot', 'channels', 'list']);
|
||||
expect(mockTrpcClient.botMessage.listOutboundChannels.query).toHaveBeenCalled();
|
||||
|
||||
// Sanity check the rendered table includes the SEND ARG values verbatim
|
||||
// so users can copy-paste them — per-agent stays raw, system bot gets the
|
||||
// `@` prefix that `resolveSendTargetArg` parses back.
|
||||
const rendered = consoleSpy.mock.calls.map((c) => String(c[0])).join('\n');
|
||||
expect(rendered).toContain('bot_abc');
|
||||
expect(rendered).toContain('@inst_xyz');
|
||||
expect(rendered).toContain('@inst_slk');
|
||||
});
|
||||
|
||||
it('reports empty state with installation guidance', async () => {
|
||||
mockTrpcClient.botMessage.listOutboundChannels.query.mockResolvedValueOnce([]);
|
||||
const program = createProgram();
|
||||
await program.parseAsync(['node', 'test', 'bot', 'channels', 'list']);
|
||||
const rendered = consoleSpy.mock.calls.map((c) => String(c[0])).join('\n');
|
||||
expect(rendered).toContain('No outbound channels');
|
||||
expect(rendered).toMatch(/Settings → Messenger|per-agent bot/);
|
||||
});
|
||||
|
||||
it('--json emits the raw payload', async () => {
|
||||
const payload = [
|
||||
{
|
||||
applicationId: 'A1',
|
||||
botId: 'bot_only',
|
||||
platform: 'telegram',
|
||||
recommended: true,
|
||||
source: 'agent_bot',
|
||||
},
|
||||
];
|
||||
mockTrpcClient.botMessage.listOutboundChannels.query.mockResolvedValueOnce(payload);
|
||||
const program = createProgram();
|
||||
await program.parseAsync(['node', 'test', 'bot', 'channels', 'list', '--json']);
|
||||
const rendered = consoleSpy.mock.calls.map((c) => String(c[0])).join('\n');
|
||||
expect(rendered).toContain('"botId": "bot_only"');
|
||||
});
|
||||
|
||||
it('--platform filters case-insensitively', async () => {
|
||||
mockTrpcClient.botMessage.listOutboundChannels.query.mockResolvedValueOnce([
|
||||
{ botId: 'bot_d', platform: 'discord', recommended: true, source: 'agent_bot' },
|
||||
{
|
||||
messengerInstallationId: 'inst_s',
|
||||
platform: 'slack',
|
||||
recommended: true,
|
||||
source: 'system_messenger',
|
||||
tenantName: 'Acme',
|
||||
},
|
||||
]);
|
||||
|
||||
const program = createProgram();
|
||||
await program.parseAsync([
|
||||
'node',
|
||||
'test',
|
||||
'bot',
|
||||
'channels',
|
||||
'list',
|
||||
'--platform',
|
||||
'DISCORD',
|
||||
'--json',
|
||||
]);
|
||||
const rendered = consoleSpy.mock.calls.map((c) => String(c[0])).join('\n');
|
||||
expect(rendered).toContain('"botId": "bot_d"');
|
||||
expect(rendered).not.toContain('inst_s');
|
||||
});
|
||||
|
||||
it('--platform with no matches surfaces platform-specific guidance', async () => {
|
||||
mockTrpcClient.botMessage.listOutboundChannels.query.mockResolvedValueOnce([
|
||||
{ botId: 'bot_d', platform: 'discord', recommended: true, source: 'agent_bot' },
|
||||
]);
|
||||
|
||||
const program = createProgram();
|
||||
await program.parseAsync(['node', 'test', 'bot', 'channels', 'list', '--platform', 'slack']);
|
||||
const rendered = consoleSpy.mock.calls.map((c) => String(c[0])).join('\n');
|
||||
expect(rendered).toContain("for platform 'slack'");
|
||||
expect(rendered).toContain('Settings → Messenger');
|
||||
});
|
||||
});
|
||||
@@ -1,3 +1,6 @@
|
||||
import { readFile } from 'node:fs/promises';
|
||||
import { basename, extname } from 'node:path';
|
||||
|
||||
import { DEFAULT_BOT_HISTORY_LIMIT } from '@lobechat/const';
|
||||
import type { Command } from 'commander';
|
||||
import pc from 'picocolors';
|
||||
@@ -6,6 +9,111 @@ import { getTrpcClient } from '../api/client';
|
||||
import { confirm, outputJson, printTable, truncate } from '../utils/format';
|
||||
import { log } from '../utils/logger';
|
||||
|
||||
type AttachmentInput = {
|
||||
data?: string;
|
||||
fetchUrl?: string;
|
||||
mimeType?: string;
|
||||
name?: string;
|
||||
type: 'image' | 'file' | 'video' | 'audio';
|
||||
};
|
||||
|
||||
const MIME_EXT_MAP: Record<string, string> = {
|
||||
'.bmp': 'image/bmp',
|
||||
'.gif': 'image/gif',
|
||||
'.jpeg': 'image/jpeg',
|
||||
'.jpg': 'image/jpeg',
|
||||
'.m4a': 'audio/mp4',
|
||||
'.mp3': 'audio/mpeg',
|
||||
'.mp4': 'video/mp4',
|
||||
'.ogg': 'audio/ogg',
|
||||
'.pdf': 'application/pdf',
|
||||
'.png': 'image/png',
|
||||
'.svg': 'image/svg+xml',
|
||||
'.txt': 'text/plain',
|
||||
'.wav': 'audio/wav',
|
||||
'.webm': 'video/webm',
|
||||
'.webp': 'image/webp',
|
||||
};
|
||||
|
||||
const inferMime = (path: string): string | undefined => MIME_EXT_MAP[extname(path).toLowerCase()];
|
||||
|
||||
const inferAttachmentType = (mimeType?: string): AttachmentInput['type'] => {
|
||||
if (!mimeType) return 'file';
|
||||
if (mimeType.startsWith('image/')) return 'image';
|
||||
if (mimeType.startsWith('video/')) return 'video';
|
||||
if (mimeType.startsWith('audio/')) return 'audio';
|
||||
return 'file';
|
||||
};
|
||||
|
||||
/**
|
||||
* Resolve a list of `--attachment` flag values into `AttachmentInput[]`. Each
|
||||
* entry is either a URL or a local file path. Returns `undefined` when no
|
||||
* flags were passed so callers can omit the field on the wire entirely (the
|
||||
* TRPC schema treats absent vs empty differently). Bails the process on
|
||||
* load failures — a silently-dropped attachment would be worse than a
|
||||
* loud error here.
|
||||
*/
|
||||
const resolveAttachmentFlags = async (flags: string[]): Promise<AttachmentInput[] | undefined> => {
|
||||
if (flags.length === 0) return undefined;
|
||||
const out: AttachmentInput[] = [];
|
||||
for (const raw of flags) {
|
||||
try {
|
||||
out.push(await parseAttachmentArg(raw));
|
||||
} catch (error) {
|
||||
log.error(`Failed to load attachment "${raw}": ${(error as Error).message}`);
|
||||
process.exit(1);
|
||||
}
|
||||
}
|
||||
return out;
|
||||
};
|
||||
|
||||
/**
|
||||
* Parse a single `--attachment <value>` argument. Accepted forms:
|
||||
* - `https://…` / `http://…` → fetchUrl, type inferred from extension
|
||||
* - any other string → treated as a local file path;
|
||||
* bytes are read + base64-encoded
|
||||
*/
|
||||
const parseAttachmentArg = async (raw: string): Promise<AttachmentInput> => {
|
||||
if (/^https?:\/\//.test(raw)) {
|
||||
const pathname = new URL(raw).pathname;
|
||||
const mimeType = inferMime(pathname);
|
||||
return {
|
||||
fetchUrl: raw,
|
||||
mimeType,
|
||||
name: basename(pathname) || undefined,
|
||||
type: inferAttachmentType(mimeType),
|
||||
};
|
||||
}
|
||||
const bytes = await readFile(raw);
|
||||
const mimeType = inferMime(raw);
|
||||
return {
|
||||
data: bytes.toString('base64'),
|
||||
mimeType,
|
||||
name: basename(raw),
|
||||
type: inferAttachmentType(mimeType),
|
||||
};
|
||||
};
|
||||
|
||||
/**
|
||||
* Resolve the `<botIdOrAtKey>` positional argument into a `{ botId? |
|
||||
* messengerInstallationId? }` shape that matches the TRPC send procedures'
|
||||
* `exactly-one-of` constraint.
|
||||
*
|
||||
* Convention: a value prefixed with `@` is treated as a System Bot
|
||||
* messenger installation id (e.g. `@inst_abc123`); anything else is a
|
||||
* per-agent bot id. The `@` was chosen because `agent_bot_providers`.id is
|
||||
* always a UUID — no UUID starts with `@`, so the prefix unambiguously
|
||||
* disambiguates without breaking the existing UUID-only call sites.
|
||||
*/
|
||||
const resolveSendTargetArg = (
|
||||
value: string,
|
||||
): { botId?: string; messengerInstallationId?: string } => {
|
||||
if (value.startsWith('@')) {
|
||||
return { messengerInstallationId: value.slice(1) };
|
||||
}
|
||||
return { botId: value };
|
||||
};
|
||||
|
||||
export function registerBotMessageCommands(bot: Command) {
|
||||
const message = bot
|
||||
.command('message')
|
||||
@@ -14,20 +122,40 @@ export function registerBotMessageCommands(bot: Command) {
|
||||
// ── send ────────────────────────────────────────────────
|
||||
|
||||
message
|
||||
.command('send <botId>')
|
||||
.description('Send a message to a channel')
|
||||
.command('send <botIdOrAtKey>')
|
||||
.description(
|
||||
'Send a message to a channel. Pass a per-agent bot id, or "@<messenger-install-id>" ' +
|
||||
'to send through a System Bot messenger installation (see `lh bot messenger list`).',
|
||||
)
|
||||
.requiredOption('--target <channelId>', 'Target channel / conversation ID')
|
||||
.requiredOption('--message <text>', 'Message content')
|
||||
.option(
|
||||
'--attachment <pathOrUrl>',
|
||||
'Attach a file by local path or remote URL (repeatable). ' +
|
||||
'Local paths are base64-encoded; http(s) URLs are passed as fetchUrl.',
|
||||
collectOptions,
|
||||
[],
|
||||
)
|
||||
.option('--reply-to <messageId>', 'Reply to a specific message')
|
||||
.option('--json', 'Output JSON')
|
||||
.action(
|
||||
async (
|
||||
botId: string,
|
||||
options: { json?: boolean; message: string; replyTo?: string; target: string },
|
||||
botIdOrAtKey: string,
|
||||
options: {
|
||||
attachment: string[];
|
||||
json?: boolean;
|
||||
message: string;
|
||||
replyTo?: string;
|
||||
target: string;
|
||||
},
|
||||
) => {
|
||||
const attachments = await resolveAttachmentFlags(options.attachment);
|
||||
const target = resolveSendTargetArg(botIdOrAtKey);
|
||||
|
||||
const client = await getTrpcClient();
|
||||
const result = await client.botMessage.sendMessage.mutate({
|
||||
botId,
|
||||
...target,
|
||||
attachments,
|
||||
channelId: options.target,
|
||||
content: options.message,
|
||||
replyTo: options.replyTo,
|
||||
@@ -39,8 +167,135 @@ export function registerBotMessageCommands(bot: Command) {
|
||||
}
|
||||
|
||||
const r = result as any;
|
||||
const suffix = attachments?.length ? ` with ${attachments.length} attachment(s)` : '';
|
||||
console.log(
|
||||
`${pc.green('✓')} Message sent${r.messageId ? ` (${pc.dim(r.messageId)})` : ''}`,
|
||||
`${pc.green('✓')} Message sent${r.messageId ? ` (${pc.dim(r.messageId)})` : ''}${suffix}`,
|
||||
);
|
||||
},
|
||||
);
|
||||
|
||||
// ── outbound channels (per-agent bots + system bot installs) ───────────
|
||||
|
||||
const channels = bot
|
||||
.command('channels')
|
||||
.description('Unified outbound channel discovery (per-agent bots + System Bot installs)');
|
||||
|
||||
channels
|
||||
.command('list')
|
||||
.description(
|
||||
'List every outbound channel the current user can send through — both ' +
|
||||
'per-agent bots (`createBot`) and System Bot messenger installs ' +
|
||||
'(Settings → Messenger). For each platform the first entry is the ' +
|
||||
'recommended pick (per-agent bot wins; system bot is the fallback). ' +
|
||||
'Copy the SEND ARG column verbatim into `lh bot message send/dm/thread reply`.',
|
||||
)
|
||||
.option(
|
||||
'--platform <name>',
|
||||
'Filter to one platform (discord | slack | telegram | feishu | lark | qq | wechat). ' +
|
||||
'Applied client-side after fetch; matches `platform` field case-insensitively.',
|
||||
)
|
||||
.option('--json', 'Output JSON')
|
||||
.action(async (options: { json?: boolean; platform?: string }) => {
|
||||
const client = await getTrpcClient();
|
||||
const all = await client.botMessage.listOutboundChannels.query();
|
||||
// Filter is applied locally because the server-side list is small
|
||||
// (a handful of rows per user) and we want the LLM-tool path to keep
|
||||
// sharing the same no-arg interface — keeps the server contract lean.
|
||||
const result = options.platform
|
||||
? all.filter((c: any) => c.platform?.toLowerCase() === options.platform!.toLowerCase())
|
||||
: all;
|
||||
|
||||
if (options.json) {
|
||||
outputJson(result);
|
||||
return;
|
||||
}
|
||||
|
||||
if (result.length === 0) {
|
||||
if (options.platform) {
|
||||
console.log(`No outbound channels available for platform '${options.platform}'.`);
|
||||
console.log(
|
||||
`\nEither install the LobeHub System Bot for ${options.platform} via ` +
|
||||
`${pc.dim('Settings → Messenger')}, or provision a per-agent bot.`,
|
||||
);
|
||||
return;
|
||||
}
|
||||
console.log('No outbound channels available.');
|
||||
console.log(
|
||||
`\nEither install the LobeHub System Bot via ${pc.dim('Settings → Messenger')}, ` +
|
||||
`or provision a per-agent bot for an agent.`,
|
||||
);
|
||||
return;
|
||||
}
|
||||
|
||||
// SEND ARG renders the exact string to paste into send/dm/thread reply:
|
||||
// per-agent bots keep their raw uuid; system bot installs use the `@<id>`
|
||||
// prefix that `resolveSendTargetArg` already understands.
|
||||
const rows = result.map((c: any) => {
|
||||
const isAgent = c.source === 'agent_bot';
|
||||
const sendArg = isAgent ? c.botId : `@${c.messengerInstallationId}`;
|
||||
const owner = isAgent
|
||||
? c.agentId
|
||||
? `agent ${c.agentId}`
|
||||
: 'agent (unknown)'
|
||||
: c.tenantName || c.tenantId || '(global)';
|
||||
return [
|
||||
c.platform || '',
|
||||
isAgent ? 'per-agent bot' : 'system bot',
|
||||
sendArg,
|
||||
owner,
|
||||
c.recommended ? pc.green('★') : '',
|
||||
];
|
||||
});
|
||||
printTable(rows, ['PLATFORM', 'TYPE', 'SEND ARG', 'OWNER', 'PICK']);
|
||||
console.log(
|
||||
`\n${pc.green('★')} marks the recommended pick per platform. ` +
|
||||
`Paste SEND ARG into ${pc.dim('lh bot message send <SEND_ARG> --target … --message …')}.`,
|
||||
);
|
||||
});
|
||||
|
||||
// ── dm (direct message) ─────────────────────────────────
|
||||
|
||||
message
|
||||
.command('dm <botIdOrAtKey>')
|
||||
.description(
|
||||
'Send a direct message to a platform user. Pass a per-agent bot id, or ' +
|
||||
'"@<messenger-install-id>" for a System Bot install.',
|
||||
)
|
||||
.requiredOption('--user-id <id>', 'Target user ID on the platform')
|
||||
.requiredOption('--message <text>', 'Message content')
|
||||
.option(
|
||||
'--attachment <pathOrUrl>',
|
||||
'Attach a file by local path or remote URL (repeatable). ' +
|
||||
'Local paths are base64-encoded; http(s) URLs are passed as fetchUrl.',
|
||||
collectOptions,
|
||||
[],
|
||||
)
|
||||
.option('--json', 'Output JSON')
|
||||
.action(
|
||||
async (
|
||||
botIdOrAtKey: string,
|
||||
options: { attachment: string[]; json?: boolean; message: string; userId: string },
|
||||
) => {
|
||||
const attachments = await resolveAttachmentFlags(options.attachment);
|
||||
const target = resolveSendTargetArg(botIdOrAtKey);
|
||||
|
||||
const client = await getTrpcClient();
|
||||
const result = await client.botMessage.sendDirectMessage.mutate({
|
||||
...target,
|
||||
attachments,
|
||||
content: options.message,
|
||||
userId: options.userId,
|
||||
});
|
||||
|
||||
if (options.json) {
|
||||
outputJson(result);
|
||||
return;
|
||||
}
|
||||
|
||||
const r = result as any;
|
||||
const suffix = attachments?.length ? ` with ${attachments.length} attachment(s)` : '';
|
||||
console.log(
|
||||
`${pc.green('✓')} DM sent${r.messageId ? ` (${pc.dim(r.messageId)})` : ''}${suffix}`,
|
||||
);
|
||||
},
|
||||
);
|
||||
@@ -450,21 +705,43 @@ export function registerBotMessageCommands(bot: Command) {
|
||||
});
|
||||
|
||||
thread
|
||||
.command('reply <botId>')
|
||||
.description('Reply to a thread')
|
||||
.command('reply <botIdOrAtKey>')
|
||||
.description(
|
||||
'Reply to a thread. Pass a per-agent bot id, or "@<messenger-install-id>" ' +
|
||||
'for a System Bot install.',
|
||||
)
|
||||
.requiredOption('--thread-id <id>', 'Thread ID')
|
||||
.requiredOption('--message <text>', 'Reply content')
|
||||
.action(async (botId: string, options: { message: string; threadId: string }) => {
|
||||
const client = await getTrpcClient();
|
||||
const result = await client.botMessage.replyToThread.mutate({
|
||||
botId,
|
||||
content: options.message,
|
||||
threadId: options.threadId,
|
||||
});
|
||||
.option(
|
||||
'--attachment <pathOrUrl>',
|
||||
'Attach a file by local path or remote URL (repeatable). ' +
|
||||
'Local paths are base64-encoded; http(s) URLs are passed as fetchUrl.',
|
||||
collectOptions,
|
||||
[],
|
||||
)
|
||||
.action(
|
||||
async (
|
||||
botIdOrAtKey: string,
|
||||
options: { attachment: string[]; message: string; threadId: string },
|
||||
) => {
|
||||
const attachments = await resolveAttachmentFlags(options.attachment);
|
||||
const target = resolveSendTargetArg(botIdOrAtKey);
|
||||
|
||||
const r = result as any;
|
||||
console.log(`${pc.green('✓')} Reply sent${r.messageId ? ` (${pc.dim(r.messageId)})` : ''}`);
|
||||
});
|
||||
const client = await getTrpcClient();
|
||||
const result = await client.botMessage.replyToThread.mutate({
|
||||
...target,
|
||||
attachments,
|
||||
content: options.message,
|
||||
threadId: options.threadId,
|
||||
});
|
||||
|
||||
const r = result as any;
|
||||
const suffix = attachments?.length ? ` with ${attachments.length} attachment(s)` : '';
|
||||
console.log(
|
||||
`${pc.green('✓')} Reply sent${r.messageId ? ` (${pc.dim(r.messageId)})` : ''}${suffix}`,
|
||||
);
|
||||
},
|
||||
);
|
||||
|
||||
// ── channel (subcommand group) ──────────────────────────
|
||||
|
||||
|
||||
@@ -117,6 +117,8 @@ By connecting a Discord channel to your LobeHub agent, users can interact with t
|
||||
|
||||
|
||||
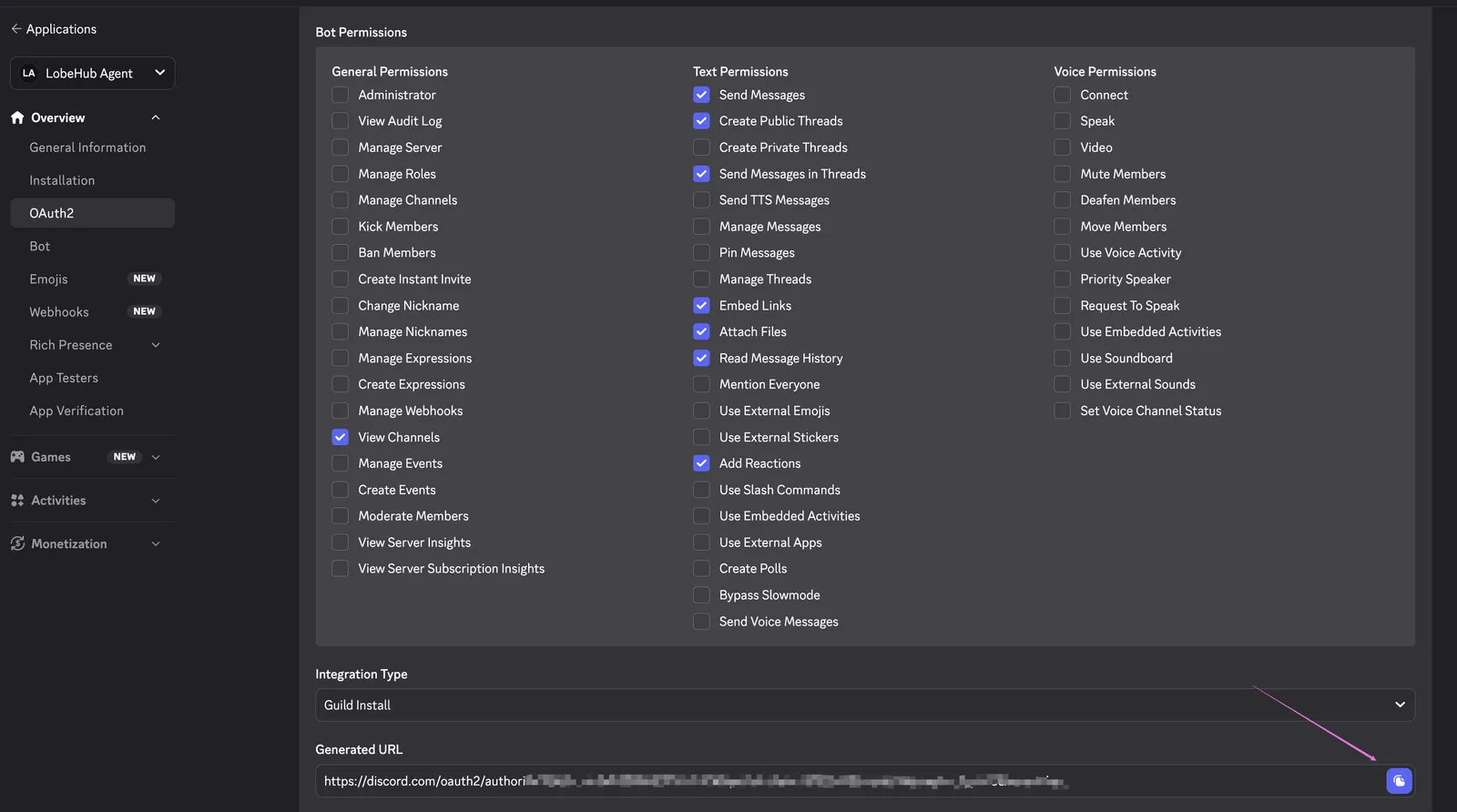
Copy the generated URL, open it in your browser, select the server you want to add the bot to, and click **Authorize**.
|
||||
|
||||
> **Private channels need explicit access.** Server-level authorization only grants the bot category/server defaults. If a channel is marked **Private Channel**, Discord ignores the bot's server-wide role and the bot won't receive any events there — including @mentions — until you open the channel's **Settings → Permissions** and add the bot (or a role it has) under **Members and roles**. You can also click **Sync Now** to make the channel inherit its category's permissions.
|
||||
</Steps>
|
||||
|
||||
## Step 4: Test the Connection
|
||||
@@ -191,5 +193,6 @@ See the [Channels overview](/docs/usage/channels/overview#direct-message-policy)
|
||||
## Troubleshooting
|
||||
|
||||
- **Bot not responding in server:** Confirm the bot has been invited to the server with the correct permissions, and Message Content Intent is enabled. If **Group Policy** is `Disabled` or `Allowlist`, double-check the channel is in **Allowed Channel IDs**. If **Allowed User IDs** is set, the sender's user ID must be in it.
|
||||
- **@mention doesn't reach the bot in one specific channel:** The channel is likely a **Private Channel**. Discord drops every event for users/bots not explicitly listed in that channel's permissions, no matter what server-wide role they have. Open the channel's **Settings → Permissions**, click **Add members or roles**, and add the bot (or a role it has). Alternatively click **Sync Now** to inherit the parent category's permissions. A quick visual check: if the bot's name renders without an underline/link styling when you type `@<botname>`, Discord thinks it has no access to that channel.
|
||||
- **Bot not responding to DMs:** Open **Advanced Settings** and confirm **DM Policy** is not set to `Disabled`. If **Allowed User IDs** is set, make sure the sender's Discord user ID is in it.
|
||||
- **Test Connection failed:** Double-check the Application ID, Bot Token, and Public Key are correct.
|
||||
|
||||
@@ -116,6 +116,8 @@ tags:
|
||||
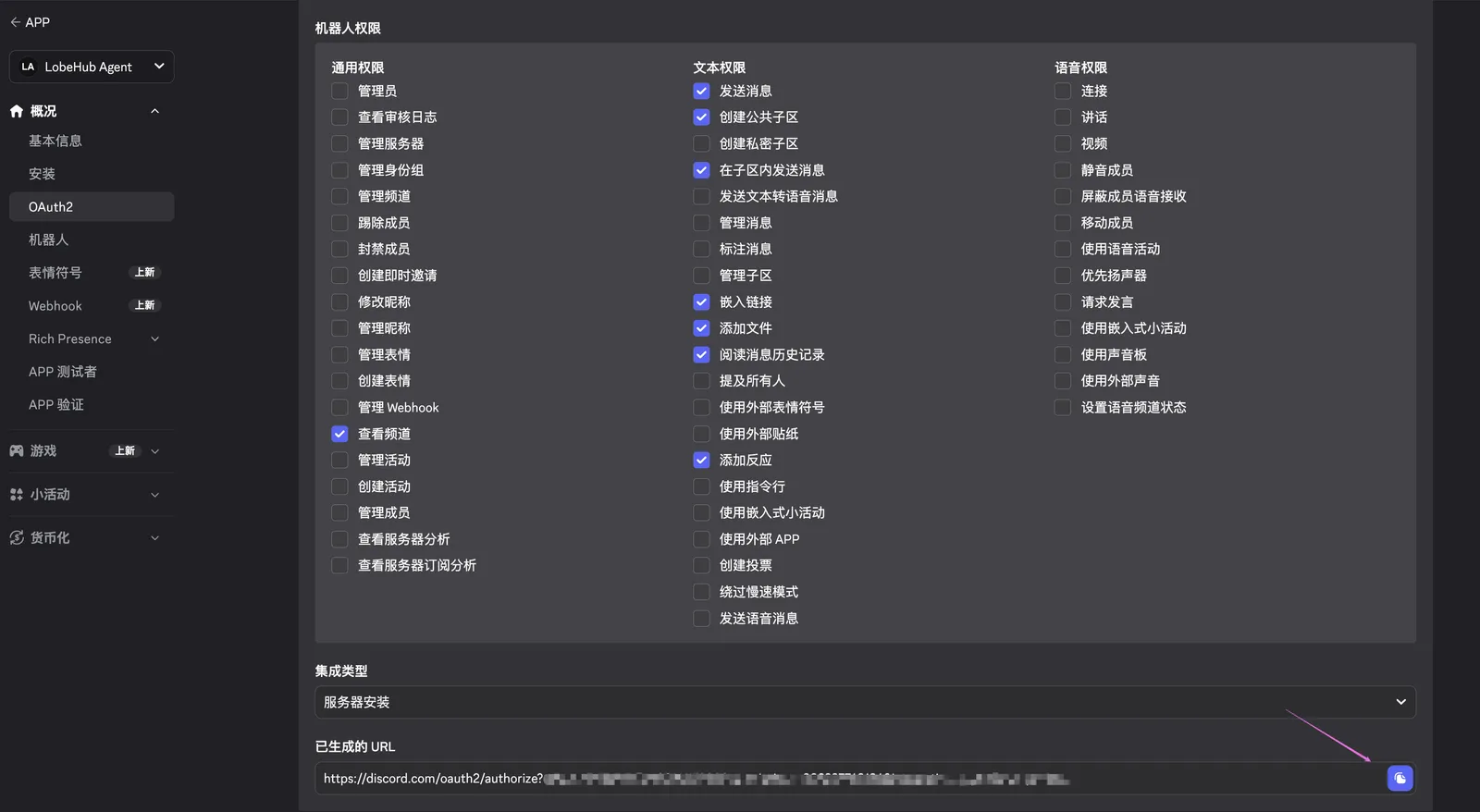
|
||||
|
||||
复制生成的链接,在浏览器中打开,选择您希望添加机器人的服务器,然后点击 **授权**。
|
||||
|
||||
> **私有频道需要单独授权。** 服务器层级的授权只会给机器人分类 / 服务器的默认权限。如果某个频道开启了 **Private Channel(私有频道)**,Discord 会忽略机器人在服务器层级的角色,机器人在该频道收不到任何事件(包括 @提及),直到你在频道的 **设置 → Permissions(权限)** 中点击 **Add members or roles**,把机器人本身或它持有的角色加进来。也可以直接点 **Sync Now** 让频道继承分类的权限。
|
||||
</Steps>
|
||||
|
||||
## 第四步:测试连接
|
||||
@@ -190,5 +192,6 @@ LobeHub 通过三层叠加配置控制入站消息,全部位于 **高级设置
|
||||
## 故障排除
|
||||
|
||||
- **机器人未在服务器中响应:** 确认机器人已被邀请到服务器并拥有正确的权限,同时启用了消息内容意图。如果 **群组策略** 是 `Disabled` 或 `Allowlist`,确认目标频道在 **允许的频道 ID** 列表里。如果 **允许的用户 ID** 已填,发送者的用户 ID 必须在列表里。
|
||||
- **某个频道里 @不到机器人:** 通常是因为该频道是 **Private Channel(私有频道)**。Discord 会丢弃所有未被显式加入频道权限列表的用户 / 机器人的事件,无论他们在服务器层级是什么角色。打开该频道的 **设置 → Permissions(权限)**,点击 **Add members or roles**,把机器人或它持有的角色加进来;或者点 **Sync Now** 让频道继承父分类的权限。一个快速肉眼判断:输入 `@<机器人名>` 时如果出现的机器人名字没有下划线 / 链接样式,说明 Discord 认为它无权访问该频道。
|
||||
- **机器人不回私信:** 打开 **高级设置**,确认 **私信策略** 不是 `Disabled`。如果 **允许的用户 ID** 已填,确认发起方的 Discord 用户 ID 在列表里。
|
||||
- **测试连接失败:** 仔细检查应用程序 ID、机器人令牌和公钥是否正确。
|
||||
|
||||
@@ -27,8 +27,6 @@ By connecting a Telegram channel to your LobeHub agent, users can interact with
|
||||
|
||||
Open Telegram and search for **@BotFather** — the official Telegram bot for managing bots. Start a conversation and send the `/newbot` command.
|
||||
|
||||

|
||||
|
||||
### Set Bot Name and Username
|
||||
|
||||
BotFather will ask you to:
|
||||
@@ -36,14 +34,10 @@ By connecting a Telegram channel to your LobeHub agent, users can interact with
|
||||
1. Choose a **display name** for your bot (e.g., "LobeHub Assistant")
|
||||
2. Choose a **username** — it must end with `bot` (e.g., `lobehub_assistant_bot`)
|
||||
|
||||

|
||||
|
||||
### Copy the Bot Token
|
||||
|
||||
After creating the bot, BotFather will send you an **API token** (format: `123456789:ABCdefGhIjKlmNoPQRsTuVwXyZ`). Copy and save this token.
|
||||
|
||||

|
||||
|
||||
> **Important:** Your bot token is a secret credential. Never share it publicly.
|
||||
</Steps>
|
||||
|
||||
@@ -60,8 +54,6 @@ By connecting a Telegram channel to your LobeHub agent, users can interact with
|
||||
|
||||
The **Bot User ID** will be automatically derived from your token — no need to enter it manually.
|
||||
|
||||

|
||||
|
||||
### Optional: Set a Webhook Secret
|
||||
|
||||
You can optionally enter a **Webhook Secret Token** for additional security. This is used to verify that incoming webhook requests originate from Telegram.
|
||||
@@ -77,8 +69,6 @@ By connecting a Telegram channel to your LobeHub agent, users can interact with
|
||||
|
||||
Click **Test Connection** in LobeHub's channel settings to verify the integration. Then open Telegram, find your bot by searching its username, and send a message. The bot should respond through your LobeHub agent.
|
||||
|
||||

|
||||
|
||||
## Set Your Platform Identity (Recommended)
|
||||
|
||||
One optional field under **Advanced Settings** carries a lot of weight in day-to-day use — fill it in once and most surprises go away.
|
||||
@@ -103,8 +93,6 @@ To use the bot in Telegram groups:
|
||||
2. By default, the bot responds when mentioned with `@your_bot_username`
|
||||
3. Send a message mentioning the bot to start interacting
|
||||
|
||||

|
||||
|
||||
<Callout type={'warning'}>
|
||||
**About Group Privacy Mode:** Telegram bots have privacy mode enabled by default, which means they only receive messages that @mention the bot, reply to the bot, or contain /commands. If you change the privacy mode setting after creating the bot, you **must remove and re-add the bot to the group** for the new setting to take effect in that group.
|
||||
</Callout>
|
||||
|
||||
@@ -26,8 +26,6 @@ tags:
|
||||
|
||||
打开 Telegram 并搜索 **@BotFather** —— 这是用于管理机器人的官方 Telegram 机器人。开始对话并发送 `/newbot` 命令。
|
||||
|
||||

|
||||
|
||||
### 设置机器人名称和用户名
|
||||
|
||||
BotFather 会要求您:
|
||||
@@ -35,14 +33,10 @@ tags:
|
||||
1. 为您的机器人选择一个 **显示名称**(例如,“LobeHub 助手”)
|
||||
2. 选择一个 **用户名** —— 必须以 `bot` 结尾(例如,`lobehub_assistant_bot`)
|
||||
|
||||

|
||||
|
||||
### 复制机器人令牌
|
||||
|
||||
创建机器人后,BotFather 会发送给您一个 **API 令牌**(格式:`123456789:ABCdefGhIjKlmNoPQRsTuVwXyZ`)。复制并保存此令牌。
|
||||
|
||||

|
||||
|
||||
> **重要提示:** 您的机器人令牌是一个机密凭证,请勿公开分享。
|
||||
</Steps>
|
||||
|
||||
@@ -59,8 +53,6 @@ tags:
|
||||
|
||||
**机器人用户 ID** 将根据您的令牌自动生成,无需手动输入。
|
||||
|
||||

|
||||
|
||||
### 可选:设置 Webhook 密钥
|
||||
|
||||
您可以选择输入一个 **Webhook 密钥令牌** 以增加安全性。此密钥用于验证来自 Telegram 的入站 Webhook 请求。
|
||||
@@ -76,8 +68,6 @@ tags:
|
||||
|
||||
在 LobeHub 的渠道设置中点击 **测试连接** 以验证集成。然后打开 Telegram,搜索您的机器人用户名并发送消息。机器人应通过您的 LobeHub 代理进行响应。
|
||||
|
||||

|
||||
|
||||
## 填写你的平台身份(推荐)
|
||||
|
||||
**高级设置**里有一个可选字段影响日常使用体验,建议一开始就填好。
|
||||
@@ -102,8 +92,6 @@ tags:
|
||||
2. 默认情况下,机器人在被 `@your_bot_username` 提及时会响应
|
||||
3. 发送一条提及机器人的消息以开始互动
|
||||
|
||||

|
||||
|
||||
<Callout type={'warning'}>
|
||||
**关于隐私模式(Group Privacy):** Telegram 机器人默认启用隐私模式,仅接收群组中 @提及、回复机器人的消息以及 / 命令。如果您在创建机器人后更改了隐私模式设置,**必须将机器人从群组中移除后重新加入**,新的设置才会对该群组生效。
|
||||
</Callout>
|
||||
|
||||
@@ -220,6 +220,13 @@
|
||||
"inbox.title": "Lobe AI",
|
||||
"input.addAi": "إضافة رسالة من الذكاء الاصطناعي",
|
||||
"input.addUser": "إضافة رسالة من المستخدم",
|
||||
"input.costEstimate.creditsPerMillionTokens": "{{credits}} ائتمان/مليون رموز",
|
||||
"input.costEstimate.hint": "التكلفة المقدرة: ~{{credits}} ائتمان",
|
||||
"input.costEstimate.inputLabel": "الإدخال",
|
||||
"input.costEstimate.outputLabel": "الإخراج",
|
||||
"input.costEstimate.settingsLink": "ضبط حد التحذير",
|
||||
"input.costEstimate.tokenCount": "~{{tokens}} رموز",
|
||||
"input.costEstimate.tooltip": "تم التقدير بناءً على السياق الحالي، الأدوات، وتسعير النموذج. قد تختلف التكلفة الفعلية.",
|
||||
"input.disclaimer": "قد يخطئ الوكلاء. استخدم حكمك الخاص للمعلومات الحساسة.",
|
||||
"input.errorMsg": "فشل الإرسال: {{errorMsg}}. أعد المحاولة أو أرسل لاحقًا.",
|
||||
"input.more": "المزيد",
|
||||
@@ -779,6 +786,7 @@
|
||||
"upload.preview.prepareTasks": "جارٍ تجهيز الأجزاء...",
|
||||
"upload.preview.status.pending": "جارٍ التحضير للرفع...",
|
||||
"upload.preview.status.processing": "جارٍ معالجة الملف...",
|
||||
"upload.validation.unsupportedFileType": "نوع الملف غير مدعوم: {{files}}. الصور المدعومة: JPG، PNG، GIF، WebP. المستندات المدعومة تشمل PDF، Word، Excel، PowerPoint، Markdown، النص، CSV، JSON، وملفات التعليمات البرمجية.",
|
||||
"upload.validation.videoSizeExceeded": "يجب ألا يتجاوز حجم ملف الفيديو 20 ميغابايت. الحجم الحالي هو {{actualSize}}.",
|
||||
"viewMode.fullWidth": "العرض الكامل",
|
||||
"viewMode.normal": "قياسي",
|
||||
@@ -894,6 +902,8 @@
|
||||
"workingPanel.localFile.closeOther": "إغلاق الآخرين",
|
||||
"workingPanel.localFile.closeRight": "إغلاق إلى اليمين",
|
||||
"workingPanel.localFile.error": "تعذر تحميل هذا الملف",
|
||||
"workingPanel.localFile.preview.raw": "خام",
|
||||
"workingPanel.localFile.preview.render": "معاينة",
|
||||
"workingPanel.localFile.truncated": "تم تقليص معاينة الملف إلى {{limit}} حرفًا",
|
||||
"workingPanel.progress": "Progress",
|
||||
"workingPanel.progress.allCompleted": "All tasks completed",
|
||||
@@ -959,6 +969,8 @@
|
||||
"workingPanel.review.viewMode.unified": "التبديل إلى العرض الموحد",
|
||||
"workingPanel.review.wordWrap.disable": "تعطيل التفاف النص",
|
||||
"workingPanel.review.wordWrap.enable": "تمكين التفاف النص",
|
||||
"workingPanel.skills.empty": "لم يتم العثور على مهارات في هذا المشروع",
|
||||
"workingPanel.skills.title": "المهارات",
|
||||
"workingPanel.space": "مسافة",
|
||||
"workingPanel.title": "Working Panel",
|
||||
"you": "أنت",
|
||||
|
||||
@@ -121,6 +121,16 @@
|
||||
"ModelSwitchPanel.detail.context": "طول السياق",
|
||||
"ModelSwitchPanel.detail.pricing": "الأسعار",
|
||||
"ModelSwitchPanel.detail.pricing.cachedInput": "المدخلات المخزنة ${{amount}}/مليون",
|
||||
"ModelSwitchPanel.detail.pricing.credits.cachedInput": "مدخل مخزن {{amount}} أرصدة/مليون رموز",
|
||||
"ModelSwitchPanel.detail.pricing.credits.image": "أرصدة/صورة",
|
||||
"ModelSwitchPanel.detail.pricing.credits.input": "مدخل {{amount}} أرصدة/مليون رموز",
|
||||
"ModelSwitchPanel.detail.pricing.credits.megapixel": "أرصدة/ميجا بكسل",
|
||||
"ModelSwitchPanel.detail.pricing.credits.millionCharacters": "أرصدة/مليون أحرف",
|
||||
"ModelSwitchPanel.detail.pricing.credits.millionTokens": "أرصدة/مليون رموز",
|
||||
"ModelSwitchPanel.detail.pricing.credits.output": "مخرج {{amount}} أرصدة/مليون رموز",
|
||||
"ModelSwitchPanel.detail.pricing.credits.perImage": "~ {{amount}} أرصدة / صورة",
|
||||
"ModelSwitchPanel.detail.pricing.credits.perVideo": "~ {{amount}} أرصدة / فيديو",
|
||||
"ModelSwitchPanel.detail.pricing.credits.second": "أرصدة/ثانية",
|
||||
"ModelSwitchPanel.detail.pricing.group.audio": "الصوت",
|
||||
"ModelSwitchPanel.detail.pricing.group.image": "الصورة",
|
||||
"ModelSwitchPanel.detail.pricing.group.text": "النص",
|
||||
|
||||
@@ -1,8 +1,10 @@
|
||||
{
|
||||
"actionTag.category.command": "أمر",
|
||||
"actionTag.category.projectSkill": "مهارة المشروع",
|
||||
"actionTag.category.skill": "مهارة",
|
||||
"actionTag.category.tool": "أداة",
|
||||
"actionTag.tooltip.command": "يشغّل أمر الشرطة المائلة على جانب العميل قبل الإرسال.",
|
||||
"actionTag.tooltip.projectSkill": "يتم إرسالها كاستدعاء شرطة مائلة بحيث يقوم CLI الخاص بالوكيل بتشغيل مهارة المشروع المطابقة.",
|
||||
"actionTag.tooltip.skill": "يحمّل حزمة مهارات قابلة لإعادة الاستخدام لهذا الطلب.",
|
||||
"actionTag.tooltip.tool": "يشير إلى أداة اختارها المستخدم صراحةً لهذا الطلب.",
|
||||
"actions.expand.off": "طي",
|
||||
|
||||
@@ -11,6 +11,19 @@
|
||||
"brief.action.ignore": "تجاهل",
|
||||
"brief.action.retry": "إعادة المحاولة",
|
||||
"brief.addFeedback": "مشاركة الملاحظات",
|
||||
"brief.agentSignal.selfReview.applied.heading": "محدث",
|
||||
"brief.agentSignal.selfReview.applied.summary": "تم تطبيق تحديث حلم واحد.",
|
||||
"brief.agentSignal.selfReview.applied.summary_plural": "تم تطبيق {{count}} تحديثات حلم.",
|
||||
"brief.agentSignal.selfReview.applied.title": "تم تحديث موارد الحلم",
|
||||
"brief.agentSignal.selfReview.error.heading": "مشكلة",
|
||||
"brief.agentSignal.selfReview.error.summary": "تعذر إكمال بعض الأعمال أثناء هذا الحلم.",
|
||||
"brief.agentSignal.selfReview.error.title": "واجه الحلم مشكلة",
|
||||
"brief.agentSignal.selfReview.ideas.summary": "تم حفظ ملاحظات الحلم للمراجعة المستقبلية.",
|
||||
"brief.agentSignal.selfReview.ideas.title": "ملاحظات الحلم",
|
||||
"brief.agentSignal.selfReview.proposal.heading": "اقتراح",
|
||||
"brief.agentSignal.selfReview.proposal.summary": "هناك اقتراح حلم واحد يحتاج إلى مراجعتك.",
|
||||
"brief.agentSignal.selfReview.proposal.summary_plural": "هناك {{count}} اقتراحات حلم تحتاج إلى مراجعتك.",
|
||||
"brief.agentSignal.selfReview.proposal.title": "اقتراح الحلم يحتاج إلى مراجعة",
|
||||
"brief.collapse": "عرض أقل",
|
||||
"brief.commentPlaceholder": "شارك ملاحظاتك...",
|
||||
"brief.commentSubmit": "إرسال الملاحظات",
|
||||
|
||||
@@ -1,8 +1,6 @@
|
||||
{
|
||||
"addUserMessage.desc": "أضف الإدخال الحالي كرسالة مستخدم دون بدء التوليد",
|
||||
"addUserMessage.title": "إضافة رسالة مستخدم",
|
||||
"clearCurrentMessages.desc": "مسح الرسائل والملفات المرفوعة من المحادثة الحالية",
|
||||
"clearCurrentMessages.title": "مسح رسائل المحادثة",
|
||||
"commandPalette.desc": "افتح لوحة الأوامر العامة للوصول السريع إلى الميزات",
|
||||
"commandPalette.title": "لوحة الأوامر",
|
||||
"deleteAndRegenerateMessage.desc": "حذف الرسالة الأخيرة وإعادة توليدها",
|
||||
|
||||
+11
-18
@@ -106,7 +106,6 @@
|
||||
"MiniMax-Hailuo-2.3.description": "نموذج جديد لإنشاء الفيديو مع تحسينات شاملة في حركة الجسم، والواقعية الفيزيائية، واتباع التعليمات.",
|
||||
"MiniMax-M1.description": "نموذج استدلال داخلي جديد بسلسلة تفكير تصل إلى 80K ومدخلات حتى 1M، يقدم أداءً مماثلاً لأفضل النماذج العالمية.",
|
||||
"MiniMax-M2-Stable.description": "مصمم لتدفقات العمل البرمجية والوكلاء بكفاءة عالية، مع قدرة تزامن أعلى للاستخدام التجاري.",
|
||||
"MiniMax-M2.1-Lightning.description": "قدرات برمجة متعددة اللغات قوية مع استنتاج أسرع وأكثر كفاءة.",
|
||||
"MiniMax-M2.1-highspeed.description": "قدرات برمجة متعددة اللغات قوية، تجربة برمجة مطورة بشكل شامل. أسرع وأكثر كفاءة.",
|
||||
"MiniMax-M2.1.description": "MiniMax-M2.1 هو نموذج مفتوح المصدر رائد من MiniMax، يركز على حل المهام الواقعية المعقدة. يتميز بقدرات برمجة متعددة اللغات والقدرة على أداء المهام المعقدة كوكلاء ذكي.",
|
||||
"MiniMax-M2.5-highspeed.description": "MiniMax M2.5 Highspeed: نفس أداء M2.5 مع استدلال أسرع.",
|
||||
@@ -315,13 +314,13 @@
|
||||
"claude-3-haiku-20240307.description": "Claude 3 Haiku هو أسرع وأصغر نموذج من Anthropic، مصمم لتقديم استجابات شبه فورية بأداء سريع ودقيق.",
|
||||
"claude-3-opus-20240229.description": "Claude 3 Opus هو أقوى نموذج من Anthropic للمهام المعقدة، يتميز بالأداء العالي، الذكاء، الطلاقة، والفهم.",
|
||||
"claude-3-sonnet-20240229.description": "Claude 3 Sonnet يوازن بين الذكاء والسرعة لتلبية احتياجات المؤسسات، ويوفر فائدة عالية بتكلفة أقل ونشر موثوق على نطاق واسع.",
|
||||
"claude-haiku-4-5-20251001.description": "Claude Haiku 4.5 هو أسرع وأذكى نموذج هايكو من Anthropic، يتميز بسرعة البرق وتفكير ممتد.",
|
||||
"claude-haiku-4-5-20251001.description": "Claude Haiku 4.5 هو النموذج الأكثر سرعة وذكاءً من Anthropic، يتميز بسرعة البرق وقدرات استدلال موسعة.",
|
||||
"claude-haiku-4-5.description": "Claude Haiku 4.5 من Anthropic — نموذج Haiku من الجيل التالي مع تحسينات في التفكير والرؤية.",
|
||||
"claude-haiku-4.5.description": "Claude Haiku 4.5 هو نموذج Haiku الأسرع والأذكى من Anthropic، يتميز بسرعة البرق وقدرات استدلال موسعة.",
|
||||
"claude-opus-4-1-20250805-thinking.description": "Claude Opus 4.1 Thinking هو إصدار متقدم يمكنه عرض عملية تفكيره.",
|
||||
"claude-opus-4-1-20250805.description": "Claude Opus 4.1 هو أحدث وأقوى نموذج من Anthropic للمهام المعقدة للغاية، يتميز بالأداء والذكاء والطلاقة والفهم.",
|
||||
"claude-opus-4-1-20250805.description": "Claude Opus 4.1 هو أحدث وأقوى نموذج من Anthropic للمهام المعقدة للغاية، يتميز بالأداء العالي، الذكاء، الطلاقة، والفهم.",
|
||||
"claude-opus-4-1.description": "Claude Opus 4.1 من Anthropic — نموذج تفكير متميز مع قدرات تحليل عميقة.",
|
||||
"claude-opus-4-20250514.description": "Claude Opus 4 هو أقوى نموذج من Anthropic للمهام المعقدة للغاية، يتميز بالأداء والذكاء والطلاقة والفهم.",
|
||||
"claude-opus-4-20250514.description": "Claude Opus 4 هو النموذج الأكثر قوة من Anthropic للمهام المعقدة للغاية، يتميز بالأداء العالي، الذكاء، الطلاقة، والاستيعاب.",
|
||||
"claude-opus-4-5-20251101.description": "Claude Opus 4.5 هو النموذج الرائد من Anthropic، يجمع بين الذكاء الاستثنائي والأداء القابل للتوسع، مثالي للمهام المعقدة التي تتطلب استجابات عالية الجودة وتفكير متقدم.",
|
||||
"claude-opus-4-5.description": "Claude Opus 4.5 من Anthropic — نموذج رئيسي مع تفكير وبرمجة من الدرجة الأولى.",
|
||||
"claude-opus-4-6.description": "Claude Opus 4.6 من Anthropic — نافذة سياق 1M نموذج رئيسي مع تفكير متقدم.",
|
||||
@@ -330,7 +329,7 @@
|
||||
"claude-opus-4.6-fast.description": "Claude Opus 4.6 هو النموذج الأكثر ذكاءً من Anthropic لبناء الوكلاء والبرمجة.",
|
||||
"claude-opus-4.6.description": "Claude Opus 4.6 هو النموذج الأكثر ذكاءً من Anthropic لبناء الوكلاء والبرمجة.",
|
||||
"claude-sonnet-4-20250514-thinking.description": "Claude Sonnet 4 Thinking يمكنه تقديم استجابات شبه فورية أو تفكير متسلسل مرئي.",
|
||||
"claude-sonnet-4-20250514.description": "Claude Sonnet 4 هو النموذج الأكثر ذكاءً من Anthropic حتى الآن، يقدم استجابات شبه فورية أو تفكير ممتد خطوة بخطوة مع تحكم دقيق لمستخدمي API.",
|
||||
"claude-sonnet-4-20250514.description": "Claude Sonnet 4 يمكنه تقديم استجابات شبه فورية أو تفكير ممتد خطوة بخطوة مع عملية مرئية.",
|
||||
"claude-sonnet-4-5-20250929.description": "Claude Sonnet 4.5 هو النموذج الأكثر ذكاءً من Anthropic حتى الآن.",
|
||||
"claude-sonnet-4-5.description": "Claude Sonnet 4.5 من Anthropic — نموذج Sonnet محسّن مع أداء برمجي معزز.",
|
||||
"claude-sonnet-4-6.description": "Claude Sonnet 4.6 من Anthropic — أحدث نموذج Sonnet مع برمجة واستخدام أدوات متفوقة.",
|
||||
@@ -404,7 +403,7 @@
|
||||
"deepseek-ai/deepseek-llm-67b-chat.description": "DeepSeek LLM Chat (67B) هو نموذج مبتكر يوفر فهمًا عميقًا للغة وتفاعلًا ذكيًا.",
|
||||
"deepseek-ai/deepseek-v3.1-terminus.description": "DeepSeek V3.1 هو نموذج تفكير من الجيل التالي يتمتع بقدرات أقوى في التفكير المعقد وسلسلة التفكير لمهام التحليل العميق.",
|
||||
"deepseek-ai/deepseek-v3.2.description": "DeepSeek V3.2 هو نموذج استدلال من الجيل التالي يتميز بقدرات استدلال معقدة وسلسلة التفكير.",
|
||||
"deepseek-chat.description": "اسم مستعار متوافق لوضع عدم التفكير في DeepSeek V4 Flash. مقرر إيقافه — استخدم DeepSeek V4 Flash بدلاً منه.",
|
||||
"deepseek-chat.description": "نموذج مفتوح المصدر جديد يجمع بين القدرات العامة وقدرات البرمجة. يحافظ على الحوار العام لنموذج الدردشة وقوة البرمجة لنموذج المبرمج، مع تحسين توافق التفضيلات. كما يحسن DeepSeek-V2.5 الكتابة واتباع التعليمات.",
|
||||
"deepseek-coder-33B-instruct.description": "DeepSeek Coder 33B هو نموذج لغة برمجية تم تدريبه على 2 تريليون رمز (87٪ كود، 13٪ نص صيني/إنجليزي). يقدم نافذة سياق 16K ومهام الإكمال في المنتصف، ويوفر إكمال كود على مستوى المشاريع وملء مقاطع الكود.",
|
||||
"deepseek-coder-v2.description": "DeepSeek Coder V2 هو نموذج كود MoE مفتوح المصدر يتميز بأداء قوي في مهام البرمجة، ويضاهي GPT-4 Turbo.",
|
||||
"deepseek-coder-v2:236b.description": "DeepSeek Coder V2 هو نموذج كود MoE مفتوح المصدر يتميز بأداء قوي في مهام البرمجة، ويضاهي GPT-4 Turbo.",
|
||||
@@ -426,7 +425,7 @@
|
||||
"deepseek-r1-fast-online.description": "الإصدار الكامل السريع من DeepSeek R1 مع بحث ويب في الوقت الحقيقي، يجمع بين قدرات بحجم 671B واستجابة أسرع.",
|
||||
"deepseek-r1-online.description": "الإصدار الكامل من DeepSeek R1 مع 671 مليار معلمة وبحث ويب في الوقت الحقيقي، يوفر فهمًا وتوليدًا أقوى.",
|
||||
"deepseek-r1.description": "يستخدم DeepSeek-R1 بيانات البداية الباردة قبل التعلم المعزز ويؤدي أداءً مماثلًا لـ OpenAI-o1 في الرياضيات، والبرمجة، والتفكير.",
|
||||
"deepseek-reasoner.description": "اسم مستعار متوافق لوضع التفكير في DeepSeek V4 Flash. مقرر إيقافه — استخدم DeepSeek V4 Flash بدلاً منه.",
|
||||
"deepseek-reasoner.description": "نموذج استدلال DeepSeek يركز على مهام الاستدلال المنطقي المعقدة.",
|
||||
"deepseek-v2.description": "DeepSeek V2 هو نموذج MoE فعال لمعالجة منخفضة التكلفة.",
|
||||
"deepseek-v2:236b.description": "DeepSeek V2 236B هو نموذج DeepSeek الموجه للبرمجة مع قدرات قوية في توليد الكود.",
|
||||
"deepseek-v3-0324.description": "DeepSeek-V3-0324 هو نموذج MoE يحتوي على 671 مليار معلمة يتميز بقوة في البرمجة، والقدرات التقنية، وفهم السياق، والتعامل مع النصوص الطويلة.",
|
||||
@@ -491,8 +490,6 @@
|
||||
"doubao-seedream-4-0-250828.description": "Seedream 4.0 هو نموذج توليد صور من ByteDance Seed، يدعم إدخال النصوص والصور مع توليد صور عالية الجودة وقابلة للتحكم بدرجة كبيرة. يُولّد الصور من التعليمات النصية.",
|
||||
"doubao-seedream-4-5-251128.description": "Seedream 4.5 هو أحدث نموذج متعدد الوسائط من ByteDance، يدمج قدرات تحويل النص إلى صورة، والصورة إلى صورة، وتوليد الصور بالجملة، مع دمج الفهم العام وقدرات الاستدلال. مقارنة بالإصدار السابق 4.0، يقدم جودة توليد محسّنة بشكل كبير، مع تحسين تناسق التحرير ودمج الصور المتعددة. يوفر تحكمًا أكثر دقة في التفاصيل البصرية، مما يجعل النصوص الصغيرة والوجوه الصغيرة أكثر طبيعية، ويحقق تخطيطًا وألوانًا أكثر انسجامًا، مما يعزز الجماليات العامة.",
|
||||
"doubao-seedream-5-0-260128.description": "Doubao-Seedream-5.0-lite هو أحدث نموذج لتوليد الصور من ByteDance. لأول مرة، يدمج قدرات الاسترجاع عبر الإنترنت، مما يسمح له بتضمين معلومات الويب في الوقت الفعلي وتعزيز حداثة الصور المولدة. كما تم ترقية ذكاء النموذج، مما يمكنه من تفسير التعليمات المعقدة والمحتوى البصري بدقة. بالإضافة إلى ذلك، يقدم تغطية محسّنة للمعرفة العالمية، وتناسقًا مرجعيًا، وجودة توليد في السيناريوهات المهنية، مما يلبي بشكل أفضل احتياجات الإبداع البصري على مستوى المؤسسات.",
|
||||
"dreamina-seedance-2-0-260128.description": "Seedance 2.0 من ByteDance هو أقوى نموذج لتوليد الفيديو، يدعم إنشاء الفيديو المرجعي متعدد الوسائط، تحرير الفيديو، تمديد الفيديو، تحويل النص إلى فيديو، وتحويل الصورة إلى فيديو مع صوت متزامن.",
|
||||
"dreamina-seedance-2-0-fast-260128.description": "Seedance 2.0 Fast من ByteDance يقدم نفس القدرات مثل Seedance 2.0 مع سرعات توليد أسرع وسعر أكثر تنافسية.",
|
||||
"emohaa.description": "Emohaa هو نموذج للصحة النفسية يتمتع بقدرات استشارية احترافية لمساعدة المستخدمين على فهم المشكلات العاطفية.",
|
||||
"ernie-4.5-0.3b.description": "ERNIE 4.5 0.3B هو نموذج مفتوح المصدر وخفيف الوزن، مصمم للنشر المحلي والمخصص.",
|
||||
"ernie-4.5-8k-preview.description": "ERNIE 4.5 8K Preview هو نموذج معاينة بسياق 8K لتقييم أداء ERNIE 4.5.",
|
||||
@@ -506,6 +503,7 @@
|
||||
"ernie-5.0-thinking-latest.description": "Wenxin 5.0 Thinking هو نموذج رائد متعدد الوسائط أصلي يدعم النصوص، الصور، الصوت، والفيديو بشكل موحد. يوفر ترقيات شاملة للقدرات في الأسئلة المعقدة، الإبداع، وسيناريوهات الوكلاء.",
|
||||
"ernie-5.0-thinking-preview.description": "معاينة Wenxin 5.0 Thinking هو نموذج رائد متعدد الوسائط أصلي يدعم النصوص، الصور، الصوت، والفيديو بشكل موحد. يوفر ترقيات شاملة للقدرات في الأسئلة المعقدة، الإبداع، وسيناريوهات الوكلاء.",
|
||||
"ernie-5.0.description": "ERNIE 5.0، النموذج الجديد في سلسلة ERNIE، هو نموذج كبير متعدد الوسائط أصلي. يعتمد نهج نمذجة متعدد الوسائط موحد، حيث يقوم بنمذجة النصوص، الصور، الصوت، والفيديو بشكل مشترك لتقديم قدرات متعددة الوسائط شاملة. تم تحسين قدراته الأساسية بشكل كبير، محققًا أداءً قويًا في تقييمات المعايير. يتفوق بشكل خاص في الفهم متعدد الوسائط، اتباع التعليمات، الكتابة الإبداعية، الدقة الواقعية، تخطيط الوكلاء، واستخدام الأدوات.",
|
||||
"ernie-5.1.description": "ERNIE 5.1 هو أحدث نموذج في سلسلة ERNIE، يتميز بترقيات شاملة لقدراته الأساسية. يظهر تحسينات كبيرة في مجالات مثل الوكلاء، معالجة المعرفة، الاستدلال، والبحث العميق. يعتمد هذا الإصدار على بنية تعلم معزز غير متزامن بالكامل ومفككة، مصممة خصيصًا لمعالجة التحديات الرئيسية في تطور النماذج الكبيرة نحو اتخاذ القرارات الذاتية للوكلاء، بما في ذلك التناقضات العددية بين التدريب والاستدلال، انخفاض استخدام موارد الحوسبة غير المتجانسة، والقضايا العالمية الناتجة عن تأثيرات الذيل الطويل. بالإضافة إلى ذلك، يتم استخدام تقنيات تدريب ما بعد واسعة النطاق للوكلاء لتعزيز قدرات النموذج وأداء التعميم. من خلال إطار عمل تعاوني من ثلاث مراحل يشمل البيئة، الخبراء، وعمليات الدمج، لا يضمن النهج كفاءة التدريب فحسب، بل يحسن بشكل كبير من استقرار النموذج وأدائه في المهام المعقدة.",
|
||||
"ernie-char-fiction-8k-preview.description": "معاينة ERNIE Character Fiction 8K هو نموذج لإنشاء الشخصيات والحبكات القصصية، مخصص لتقييم الميزات والاختبار.",
|
||||
"ernie-char-fiction-8k.description": "ERNIE Character Fiction 8K هو نموذج شخصيات للروايات وإنشاء الحبكات، مناسب لتوليد القصص الطويلة.",
|
||||
"ernie-image-turbo.description": "ERNIE-Image هو نموذج نص إلى صورة بـ 8 مليارات معلمة تم تطويره بواسطة Baidu. يحتل المرتبة الأولى في العديد من المعايير، محققًا المركز الأول في SuperCLUE في الصين ويتصدر المسار مفتوح المصدر.",
|
||||
@@ -517,8 +515,7 @@
|
||||
"ernie-x1-turbo-32k.description": "ERNIE X1 Turbo 32K هو نموذج تفكير سريع بسياق 32K للاستدلال المعقد والدردشة متعددة الأدوار.",
|
||||
"ernie-x1.1-preview.description": "معاينة ERNIE X1.1 هو نموذج تفكير مخصص للتقييم والاختبار.",
|
||||
"ernie-x1.1.description": "ERNIE X1.1 هو نموذج تفكير تجريبي للتقييم والاختبار.",
|
||||
"fal-ai/bytedance/seedream/v4.5.description": "Seedream 4.5، تم تطويره بواسطة فريق ByteDance Seed، يدعم تحرير الصور المتعددة والتكوين. يتميز بتناسق الموضوع المحسن، اتباع التعليمات بدقة، فهم المنطق المكاني، التعبير الجمالي، تصميم الملصقات وتصميم الشعارات مع توليد النصوص والصور بدقة عالية.",
|
||||
"fal-ai/bytedance/seedream/v4.description": "Seedream 4.0، تم تطويره بواسطة ByteDance Seed، يدعم إدخال النصوص والصور لتوليد صور عالية الجودة وقابلة للتحكم بناءً على التعليمات.",
|
||||
"fal-ai/bytedance/seedream/v4.description": "Seedream 4.0 هو نموذج توليد الصور من ByteDance Seed، يدعم المدخلات النصية والصورية مع توليد صور عالي الجودة وقابل للتحكم بدرجة كبيرة. يقوم بتوليد الصور من التعليمات النصية.",
|
||||
"fal-ai/flux-kontext/dev.description": "نموذج FLUX.1 يركز على تحرير الصور، ويدعم إدخال النصوص والصور.",
|
||||
"fal-ai/flux-pro/kontext.description": "FLUX.1 Kontext [pro] يقبل النصوص وصور مرجعية كمدخلات، مما يتيح تعديلات محلية مستهدفة وتحولات معقدة في المشهد العام.",
|
||||
"fal-ai/flux/krea.description": "Flux Krea [dev] هو نموذج لتوليد الصور يتميز بميول جمالية نحو صور أكثر واقعية وطبيعية.",
|
||||
@@ -526,8 +523,8 @@
|
||||
"fal-ai/hunyuan-image/v3.description": "نموذج قوي لتوليد الصور متعدد الوسائط أصلي.",
|
||||
"fal-ai/imagen4/preview.description": "نموذج عالي الجودة لتوليد الصور من Google.",
|
||||
"fal-ai/nano-banana.description": "Nano Banana هو أحدث وأسرع وأكثر نماذج Google كفاءةً لتوليد وتحرير الصور من خلال المحادثة.",
|
||||
"fal-ai/qwen-image-edit.description": "نموذج تحرير الصور الاحترافي من فريق Qwen، يدعم التعديلات الدلالية والمظهرية، تحرير النصوص الدقيقة باللغتين الصينية والإنجليزية، نقل الأنماط، التدوير، والمزيد.",
|
||||
"fal-ai/qwen-image.description": "نموذج قوي لتوليد الصور من فريق Qwen يتميز بتقديم نصوص صينية قوية وأنماط بصرية متنوعة.",
|
||||
"fal-ai/qwen-image-edit.description": "نموذج تحرير الصور الاحترافي من فريق Qwen يدعم التعديلات الدلالية والمظهرية، ويحرر النصوص الصينية والإنجليزية بدقة، ويمكّن من تعديلات عالية الجودة مثل نقل الأنماط وتدوير الكائنات.",
|
||||
"fal-ai/qwen-image.description": "نموذج توليد الصور القوي من فريق Qwen يتميز بعرض نصوص صينية مبهرة وأنماط بصرية متنوعة.",
|
||||
"flux-1-schnell.description": "نموذج تحويل النص إلى صورة يحتوي على 12 مليار معلمة من Black Forest Labs يستخدم تقنيات تقطير الانتشار العدائي الكامن لتوليد صور عالية الجودة في 1-4 خطوات. ينافس البدائل المغلقة ومتاح بموجب ترخيص Apache-2.0 للاستخدام الشخصي والبحثي والتجاري.",
|
||||
"flux-dev.description": "نموذج مفتوح المصدر مخصص لتوليد الصور لأغراض البحث والابتكار غير التجاري، مع تحسينات فعالة.",
|
||||
"flux-kontext-max.description": "توليد وتحرير صور سياقية متقدمة، تجمع بين النصوص والصور لتحقيق نتائج دقيقة ومتسقة.",
|
||||
@@ -569,7 +566,7 @@
|
||||
"gemini-3-pro-image-preview:image.description": "Gemini 3 Pro Image (Nano Banana Pro) هو نموذج توليد الصور من Google ويدعم أيضًا الدردشة متعددة الوسائط.",
|
||||
"gemini-3-pro-preview.description": "Gemini 3 Pro هو أقوى نموذج من Google للوكيل الذكي والبرمجة الإبداعية، يقدم تفاعلاً أعمق وصورًا أغنى مع استدلال متقدم.",
|
||||
"gemini-3.1-flash-image-preview.description": "Gemini 3.1 Flash Image (Nano Banana 2) يقدم جودة صور احترافية بسرعة فائقة مع دعم الدردشة متعددة الوسائط.",
|
||||
"gemini-3.1-flash-image-preview:image.description": "Gemini 3.1 Flash Image (Nano Banana 2) يقدم جودة صور بمستوى احترافي بسرعة Flash مع دعم الدردشة متعددة الوسائط.",
|
||||
"gemini-3.1-flash-image-preview:image.description": "Gemini 3.1 Flash Image (Nano Banana 2) هو أسرع نموذج توليد صور أصلي من Google مع دعم التفكير، وتوليد الصور الحواري، وتحرير الصور.",
|
||||
"gemini-3.1-flash-lite-preview.description": "Gemini 3.1 Flash-Lite Preview هو النموذج الأكثر كفاءة من حيث التكلفة من Google، مُحسّن للمهام الوكيلة ذات الحجم الكبير، الترجمة، ومعالجة البيانات.",
|
||||
"gemini-3.1-flash-lite.description": "Gemini 3.1 Flash-Lite هو النموذج متعدد الوسائط الأكثر كفاءة من Google، مُحسّن للمهام الوكيلية ذات الحجم الكبير، الترجمة، ومعالجة البيانات.",
|
||||
"gemini-3.1-pro-preview.description": "Gemini 3.1 Pro Preview يحسن من Gemini 3 Pro مع قدرات استدلال محسّنة ويضيف دعم مستوى التفكير المتوسط.",
|
||||
@@ -734,8 +731,6 @@
|
||||
"grok-4-fast-reasoning.description": "يسعدنا إطلاق Grok 4 Fast، أحدث تقدم في نماذج الاستدلال منخفضة التكلفة.",
|
||||
"grok-4.20-0309-non-reasoning.description": "نموذج غير تفكير للاستخدامات البسيطة.",
|
||||
"grok-4.20-0309-reasoning.description": "نموذج ذكي وسريع للغاية يفكر قبل الرد.",
|
||||
"grok-4.20-beta-0309-non-reasoning.description": "نسخة غير تفكيرية للاستخدامات البسيطة.",
|
||||
"grok-4.20-beta-0309-reasoning.description": "نموذج ذكي وسريع للغاية يفكر قبل الرد.",
|
||||
"grok-4.20-multi-agent-0309.description": "فريق من 4 أو 16 وكيلًا، يتفوق في حالات الاستخدام البحثية، لا يدعم حاليًا الأدوات على جانب العميل. يدعم فقط أدوات xAI على جانب الخادم (مثل X Search، أدوات البحث على الويب) وأدوات MCP البعيدة.",
|
||||
"grok-4.3.description": "أكثر نموذج لغة كبير يسعى للحقيقة في العالم.",
|
||||
"grok-4.description": "أحدث نموذج Grok الرائد بأداء لا مثيل له في اللغة، الرياضيات، والاستدلال — نموذج شامل حقيقي. يشير حاليًا إلى grok-4-0709؛ نظرًا للموارد المحدودة، فإن سعره مؤقتًا أعلى بنسبة 10% من السعر الرسمي ومن المتوقع أن يعود إلى السعر الرسمي لاحقًا.",
|
||||
@@ -1220,8 +1215,6 @@
|
||||
"qwq.description": "QwQ هو نموذج استدلال من عائلة Qwen. مقارنة بالنماذج المضبوطة على التعليمات، يقدم قدرات تفكير واستدلال تعزز الأداء بشكل كبير، خاصة في المشكلات الصعبة. QwQ-32B هو نموذج متوسط الحجم ينافس أفضل نماذج الاستدلال مثل DeepSeek-R1 و o1-mini.",
|
||||
"qwq_32b.description": "نموذج استدلال متوسط الحجم من عائلة Qwen. مقارنة بالنماذج المضبوطة على التعليمات، تعزز قدرات التفكير والاستدلال في QwQ الأداء بشكل كبير، خاصة في المشكلات الصعبة.",
|
||||
"r1-1776.description": "R1-1776 هو إصدار ما بعد التدريب من DeepSeek R1 مصمم لتقديم معلومات واقعية غير خاضعة للرقابة أو التحيز.",
|
||||
"seedance-1-5-pro-251215.description": "Seedance 1.5 Pro من ByteDance يدعم تحويل النص إلى فيديو، تحويل الصورة إلى فيديو (الإطار الأول، الإطار الأول + الأخير)، وتوليد الصوت المتزامن مع المرئيات.",
|
||||
"seedream-5-0-260128.description": "ByteDance-Seedream-5.0-lite من BytePlus يتميز بتوليد معزز بالاسترجاع عبر الويب للحصول على معلومات في الوقت الحقيقي، تفسير محسّن للتعليمات المعقدة، وتحسين تناسق المرجع لإنشاء بصري احترافي.",
|
||||
"solar-mini-ja.description": "Solar Mini (Ja) يوسع Solar Mini مع تركيز على اللغة اليابانية مع الحفاظ على الأداء القوي والكفاءة في الإنجليزية والكورية.",
|
||||
"solar-mini.description": "Solar Mini هو نموذج لغة مدمج يتفوق على GPT-3.5، يتميز بقدرات متعددة اللغات قوية تدعم الإنجليزية والكورية، ويقدم حلاً فعالاً بصمة صغيرة.",
|
||||
"solar-pro.description": "Solar Pro هو نموذج لغة عالي الذكاء من Upstage، يركز على اتباع التعليمات باستخدام وحدة معالجة رسومات واحدة، مع درجات IFEval تتجاوز 80. حالياً يدعم اللغة الإنجليزية؛ وكان من المقرر إصدار النسخة الكاملة في نوفمبر 2024 مع دعم لغات موسع وسياق أطول.",
|
||||
|
||||
@@ -27,6 +27,13 @@
|
||||
"agent.layout.skipConfirm.ok": "تخطي الآن",
|
||||
"agent.layout.skipConfirm.title": "تخطي الإعداد الآن؟",
|
||||
"agent.layout.switchMessage": "لست في مزاج لذلك اليوم؟ يمكنك التبديل إلى <modeLink><modeText>{{mode}}</modeText></modeLink> أو <skipLink><skipText>{{skip}}</skipText></skipLink>.",
|
||||
"agent.layout.switchMessageClassic": "لست في المزاج اليوم؟ يمكنك التبديل إلى <modeLink><modeText>{{mode}}</modeText></modeLink>.",
|
||||
"agent.messenger.cta.discord": "أضف إلى Discord",
|
||||
"agent.messenger.cta.slack": "أضف إلى Slack",
|
||||
"agent.messenger.cta.telegram": "افتح في Telegram",
|
||||
"agent.messenger.subtitle": "تحدث مع وكيلك على Telegram أو Slack أو Discord",
|
||||
"agent.messenger.telegramQrCaption": "امسح باستخدام كاميرا هاتفك",
|
||||
"agent.messenger.title": "ابق معي أينما كنت تراسل",
|
||||
"agent.modeSwitch.agent": "تفاعلي",
|
||||
"agent.modeSwitch.classic": "كلاسيكي",
|
||||
"agent.modeSwitch.collapse": "طي",
|
||||
@@ -68,6 +75,13 @@
|
||||
"agent.wrapUp.confirm.content": "سأحفظ ما ناقشناه حتى الآن. يمكنك دائمًا العودة ومتابعة الحديث لاحقًا.",
|
||||
"agent.wrapUp.confirm.ok": "إنهاء الآن",
|
||||
"agent.wrapUp.confirm.title": "إنهاء الإعداد الآن؟",
|
||||
"agentPicker.allCategories": "الكل",
|
||||
"agentPicker.continue": "متابعة",
|
||||
"agentPicker.skip": "تخطي الآن",
|
||||
"agentPicker.subtitle": "أضف بعضًا إلى مكتبتك الآن — اكتشف المزيد في أي وقت لاحقًا.",
|
||||
"agentPicker.title": "لنضف بعض الوكلاء إلى مكتبتك",
|
||||
"agentPicker.title2": "اختر ما يناسب طريقة عملك",
|
||||
"agentPicker.title3": "يمكنك دائمًا إضافة المزيد لاحقًا — ابدأ ببعض الخيارات",
|
||||
"back": "رجوع",
|
||||
"finish": "ابدأ الآن",
|
||||
"interests.area.business": "الأعمال والاستراتيجية",
|
||||
|
||||
+10
-2
@@ -39,8 +39,8 @@
|
||||
"builtins.lobe-agent-documents.inspector.docCount": "{{count}} مستندات",
|
||||
"builtins.lobe-agent-documents.inspector.opsCount": "{{count}} عمليات",
|
||||
"builtins.lobe-agent-documents.inspector.opsResult": "{{success}}/{{total}} عمليات",
|
||||
"builtins.lobe-agent-documents.inspector.target.agent": "في الوكيل",
|
||||
"builtins.lobe-agent-documents.inspector.target.currentTopic": "في الموضوع",
|
||||
"builtins.lobe-agent-documents.inspector.scope.agent": "في الوكيل",
|
||||
"builtins.lobe-agent-documents.inspector.scope.currentTopic": "في الموضوع",
|
||||
"builtins.lobe-agent-documents.title": "مستندات الوكيل",
|
||||
"builtins.lobe-agent-management.apiName.callAgent": "وكيل الاتصال",
|
||||
"builtins.lobe-agent-management.apiName.createAgent": "إنشاء وكيل",
|
||||
@@ -90,6 +90,14 @@
|
||||
"builtins.lobe-agent.title": "وكيل لوب",
|
||||
"builtins.lobe-claude-code.agent.instruction": "تعليمات",
|
||||
"builtins.lobe-claude-code.agent.result": "النتيجة",
|
||||
"builtins.lobe-claude-code.task.createLabel": "إنشاء المهمة: ",
|
||||
"builtins.lobe-claude-code.task.getLabel": "تفحص المهمة #{{taskId}}",
|
||||
"builtins.lobe-claude-code.task.listLabel": "عرض المهام",
|
||||
"builtins.lobe-claude-code.task.updateCompleted": "مكتملة",
|
||||
"builtins.lobe-claude-code.task.updateDeleted": "محذوفة",
|
||||
"builtins.lobe-claude-code.task.updateInProgress": "بدأت",
|
||||
"builtins.lobe-claude-code.task.updateLabel": "تحديث المهمة #{{taskId}}",
|
||||
"builtins.lobe-claude-code.task.updatePending": "إعادة تعيين",
|
||||
"builtins.lobe-claude-code.todoWrite.allDone": "جميع المهام مكتملة",
|
||||
"builtins.lobe-claude-code.todoWrite.currentStep": "الخطوة الحالية",
|
||||
"builtins.lobe-claude-code.todoWrite.todos": "المهام",
|
||||
|
||||
@@ -33,7 +33,6 @@
|
||||
"jina.description": "تأسست Jina AI في عام 2020، وهي شركة رائدة في مجال البحث الذكي. تشمل تقنياتها نماذج المتجهات، ومعيدو الترتيب، ونماذج لغوية صغيرة لبناء تطبيقات بحث توليدية ومتعددة الوسائط عالية الجودة.",
|
||||
"kimicodingplan.description": "كود Kimi من Moonshot AI يوفر الوصول إلى نماذج Kimi بما في ذلك K2.5 لأداء مهام الترميز.",
|
||||
"lmstudio.description": "LM Studio هو تطبيق سطح مكتب لتطوير وتجربة النماذج اللغوية الكبيرة على جهازك.",
|
||||
"lobehub.description": "يستخدم LobeHub Cloud واجهات برمجة التطبيقات الرسمية للوصول إلى نماذج الذكاء الاصطناعي ويقيس الاستخدام باستخدام أرصدة مرتبطة برموز النماذج.",
|
||||
"longcat.description": "LongCat هو سلسلة من نماذج الذكاء الاصطناعي التوليدية الكبيرة التي تم تطويرها بشكل مستقل بواسطة Meituan. تم تصميمه لتعزيز إنتاجية المؤسسة الداخلية وتمكين التطبيقات المبتكرة من خلال بنية حسابية فعالة وقدرات متعددة الوسائط قوية.",
|
||||
"minimax.description": "تأسست MiniMax في عام 2021، وتبني نماذج ذكاء اصطناعي متعددة الوسائط للأغراض العامة، بما في ذلك نماذج نصية بمليارات المعلمات، ونماذج صوتية وبصرية، بالإضافة إلى تطبيقات مثل Hailuo AI.",
|
||||
"minimaxcodingplan.description": "خطة الرموز MiniMax توفر الوصول إلى نماذج MiniMax بما في ذلك M2.7 لأداء مهام الترميز عبر اشتراك ثابت الرسوم.",
|
||||
|
||||
@@ -55,6 +55,12 @@
|
||||
"credits.autoTopUp.toggle": "تفعيل الشحن التلقائي",
|
||||
"credits.autoTopUp.upgradeHint": "اشترك في خطة مدفوعة لتفعيل الشحن التلقائي",
|
||||
"credits.autoTopUp.validation.targetMustExceedThreshold": "يجب أن يكون الرصيد المستهدف أكبر من الحد الأدنى",
|
||||
"credits.costEstimateHint.desc": "عرض تحذير خفيف قبل الإرسال عندما تصل التكلفة التقديرية للنموذج إلى الحد الخاص بك",
|
||||
"credits.costEstimateHint.saveError": "فشل في حفظ إعدادات تنبيه تقدير التكلفة",
|
||||
"credits.costEstimateHint.saveSuccess": "تم حفظ إعدادات تنبيه تقدير التكلفة",
|
||||
"credits.costEstimateHint.threshold": "حد التحذير",
|
||||
"credits.costEstimateHint.title": "تنبيه تقدير التكلفة",
|
||||
"credits.costEstimateHint.validation.threshold": "يجب أن يكون الحد أكبر من أو يساوي 0",
|
||||
"credits.packages.auto": "تلقائي",
|
||||
"credits.packages.charged": "تم خصم ${{amount}}",
|
||||
"credits.packages.expired": "منتهية",
|
||||
|
||||
@@ -40,6 +40,14 @@
|
||||
"agentMarketplace.render.alreadyInLibraryTag": "موجود بالفعل في المكتبة",
|
||||
"agentMarketplace.render.alreadyInLibrary_one": "{{count}} موجود بالفعل في المكتبة",
|
||||
"agentMarketplace.render.alreadyInLibrary_other": "{{count}} موجود بالفعل في المكتبة",
|
||||
"claudeCode.askUserQuestion.escape.back": "العودة إلى الخيارات",
|
||||
"claudeCode.askUserQuestion.escape.enter": "أو اكتب مباشرة",
|
||||
"claudeCode.askUserQuestion.escape.placeholder": "اكتب إجابتك هنا…",
|
||||
"claudeCode.askUserQuestion.multiSelectTag": "(اختيار متعدد)",
|
||||
"claudeCode.askUserQuestion.skip": "تخطي",
|
||||
"claudeCode.askUserQuestion.submit": "إرسال",
|
||||
"claudeCode.askUserQuestion.timeExpired": "انتهى الوقت — سيتم استخدام الخيار 1 لكل سؤال.",
|
||||
"claudeCode.askUserQuestion.timeRemaining": "الوقت المتبقي: {{time}} · الأسئلة غير المجابة ستُعتمد على الخيار 1 عند انتهاء الوقت.",
|
||||
"codeInterpreter-legacy.error": "خطأ في التنفيذ",
|
||||
"codeInterpreter-legacy.executing": "جارٍ التنفيذ...",
|
||||
"codeInterpreter-legacy.files": "الملفات:",
|
||||
|
||||
@@ -56,6 +56,7 @@
|
||||
"renameModal.title": "إعادة تسمية الموضوع",
|
||||
"searchPlaceholder": "ابحث في المواضيع...",
|
||||
"searchResultEmpty": "لم يتم العثور على نتائج.",
|
||||
"sidebar.title": "المواضيع",
|
||||
"taskManager.agent": "وكيل المهام",
|
||||
"taskManager.welcome": "اسألني عن مهامك",
|
||||
"temp": "مؤقت",
|
||||
|
||||
@@ -220,6 +220,13 @@
|
||||
"inbox.title": "Lobe AI",
|
||||
"input.addAi": "Добави AI съобщение",
|
||||
"input.addUser": "Добави потребителско съобщение",
|
||||
"input.costEstimate.creditsPerMillionTokens": "{{credits}} кредита/М токена",
|
||||
"input.costEstimate.hint": "Оценена цена: ~{{credits}} кредита",
|
||||
"input.costEstimate.inputLabel": "Вход",
|
||||
"input.costEstimate.outputLabel": "Изход",
|
||||
"input.costEstimate.settingsLink": "Настройка на прага за предупреждение",
|
||||
"input.costEstimate.tokenCount": "~{{tokens}} токена",
|
||||
"input.costEstimate.tooltip": "Оценено въз основа на текущия контекст, инструменти и ценообразуване на модела. Реалната цена може да варира.",
|
||||
"input.disclaimer": "Агентите могат да допускат грешки. Използвайте собствена преценка за важна информация.",
|
||||
"input.errorMsg": "Изпращането не бе успешно: {{errorMsg}}. Опитайте отново или по-късно.",
|
||||
"input.more": "Още",
|
||||
@@ -779,6 +786,7 @@
|
||||
"upload.preview.prepareTasks": "Подготовка на части...",
|
||||
"upload.preview.status.pending": "Подготовка за качване...",
|
||||
"upload.preview.status.processing": "Обработка на файла...",
|
||||
"upload.validation.unsupportedFileType": "Неподдържан тип файл: {{files}}. Поддържани изображения: JPG, PNG, GIF, WebP. Поддържани документи включват PDF, Word, Excel, PowerPoint, Markdown, текст, CSV, JSON и файлове с код.",
|
||||
"upload.validation.videoSizeExceeded": "Размерът на видеофайла не трябва да надвишава 20MB. Текущият размер е {{actualSize}}.",
|
||||
"viewMode.fullWidth": "Пълна ширина",
|
||||
"viewMode.normal": "Стандартен",
|
||||
@@ -894,6 +902,8 @@
|
||||
"workingPanel.localFile.closeOther": "Затвори другите",
|
||||
"workingPanel.localFile.closeRight": "Затвори надясно",
|
||||
"workingPanel.localFile.error": "Не може да се зареди този файл",
|
||||
"workingPanel.localFile.preview.raw": "Суров",
|
||||
"workingPanel.localFile.preview.render": "Преглед",
|
||||
"workingPanel.localFile.truncated": "Прегледът на файла е съкратен до {{limit}} символа",
|
||||
"workingPanel.progress": "Progress",
|
||||
"workingPanel.progress.allCompleted": "All tasks completed",
|
||||
@@ -959,6 +969,8 @@
|
||||
"workingPanel.review.viewMode.unified": "Превключете към обединен изглед",
|
||||
"workingPanel.review.wordWrap.disable": "Деактивирай пренасяне на думи",
|
||||
"workingPanel.review.wordWrap.enable": "Активирай пренасяне на думи",
|
||||
"workingPanel.skills.empty": "Няма намерени умения в този проект",
|
||||
"workingPanel.skills.title": "Умения",
|
||||
"workingPanel.space": "Пространство",
|
||||
"workingPanel.title": "Working Panel",
|
||||
"you": "Вие",
|
||||
|
||||
@@ -121,6 +121,16 @@
|
||||
"ModelSwitchPanel.detail.context": "Дължина на контекста",
|
||||
"ModelSwitchPanel.detail.pricing": "Ценообразуване",
|
||||
"ModelSwitchPanel.detail.pricing.cachedInput": "Кеширан вход ${{amount}}/М",
|
||||
"ModelSwitchPanel.detail.pricing.credits.cachedInput": "Кеширан вход {{amount}} кредита/М токени",
|
||||
"ModelSwitchPanel.detail.pricing.credits.image": "кредити/изображение",
|
||||
"ModelSwitchPanel.detail.pricing.credits.input": "Вход {{amount}} кредита/М токени",
|
||||
"ModelSwitchPanel.detail.pricing.credits.megapixel": "кредити/МП",
|
||||
"ModelSwitchPanel.detail.pricing.credits.millionCharacters": "кредити/М символа",
|
||||
"ModelSwitchPanel.detail.pricing.credits.millionTokens": "кредити/М токени",
|
||||
"ModelSwitchPanel.detail.pricing.credits.output": "Изход {{amount}} кредита/М токени",
|
||||
"ModelSwitchPanel.detail.pricing.credits.perImage": "~ {{amount}} кредита / изображение",
|
||||
"ModelSwitchPanel.detail.pricing.credits.perVideo": "~ {{amount}} кредита / видео",
|
||||
"ModelSwitchPanel.detail.pricing.credits.second": "кредити/сек",
|
||||
"ModelSwitchPanel.detail.pricing.group.audio": "Аудио",
|
||||
"ModelSwitchPanel.detail.pricing.group.image": "Изображение",
|
||||
"ModelSwitchPanel.detail.pricing.group.text": "Текст",
|
||||
|
||||
@@ -1,8 +1,10 @@
|
||||
{
|
||||
"actionTag.category.command": "Команда",
|
||||
"actionTag.category.projectSkill": "Умение за проект",
|
||||
"actionTag.category.skill": "Умение",
|
||||
"actionTag.category.tool": "Инструмент",
|
||||
"actionTag.tooltip.command": "Изпълнява локална slash команда преди изпращане.",
|
||||
"actionTag.tooltip.projectSkill": "Изпраща се като команда със знак наклонена черта, така че CLI на агента да изпълни съответното умение за проект.",
|
||||
"actionTag.tooltip.skill": "Зарежда многократно използваем пакет с умения за тази заявка.",
|
||||
"actionTag.tooltip.tool": "Маркира инструмент, който потребителят е избрал изрично за тази заявка.",
|
||||
"actions.expand.off": "Свий",
|
||||
|
||||
@@ -11,6 +11,19 @@
|
||||
"brief.action.ignore": "Игнорирай",
|
||||
"brief.action.retry": "Опит отново",
|
||||
"brief.addFeedback": "Споделяне на обратна връзка",
|
||||
"brief.agentSignal.selfReview.applied.heading": "Актуализирано",
|
||||
"brief.agentSignal.selfReview.applied.summary": "{{count}} актуализация на мечтата беше приложена.",
|
||||
"brief.agentSignal.selfReview.applied.summary_plural": "{{count}} актуализации на мечтата бяха приложени.",
|
||||
"brief.agentSignal.selfReview.applied.title": "Актуализирани ресурси на мечтата",
|
||||
"brief.agentSignal.selfReview.error.heading": "Проблем",
|
||||
"brief.agentSignal.selfReview.error.summary": "Някои задачи не можаха да бъдат завършени по време на тази мечта.",
|
||||
"brief.agentSignal.selfReview.error.title": "Мечтата срещна проблем",
|
||||
"brief.agentSignal.selfReview.ideas.summary": "Запазени бележки за мечтата за бъдещ преглед.",
|
||||
"brief.agentSignal.selfReview.ideas.title": "Бележки за мечтата",
|
||||
"brief.agentSignal.selfReview.proposal.heading": "Предложение",
|
||||
"brief.agentSignal.selfReview.proposal.summary": "{{count}} предложение за мечтата изисква вашия преглед.",
|
||||
"brief.agentSignal.selfReview.proposal.summary_plural": "{{count}} предложения за мечтата изискват вашия преглед.",
|
||||
"brief.agentSignal.selfReview.proposal.title": "Предложение за мечтата изисква преглед",
|
||||
"brief.collapse": "Покажи по-малко",
|
||||
"brief.commentPlaceholder": "Споделете вашата обратна връзка...",
|
||||
"brief.commentSubmit": "Изпращане на обратна връзка",
|
||||
|
||||
@@ -1,8 +1,6 @@
|
||||
{
|
||||
"addUserMessage.desc": "Добавете текущия вход като потребителско съобщение без да се задейства генериране",
|
||||
"addUserMessage.title": "Добавяне на потребителско съобщение",
|
||||
"clearCurrentMessages.desc": "Изчистете съобщенията и качените файлове от текущия разговор",
|
||||
"clearCurrentMessages.title": "Изчистване на съобщенията от разговора",
|
||||
"commandPalette.desc": "Отворете глобалната палитра с команди за бърз достъп до функциите",
|
||||
"commandPalette.title": "Палитра с команди",
|
||||
"deleteAndRegenerateMessage.desc": "Изтрийте последното съобщение и го генерирайте отново",
|
||||
|
||||
+12
-19
@@ -106,7 +106,6 @@
|
||||
"MiniMax-Hailuo-2.3.description": "Чисто нов модел за видео генериране с цялостни подобрения в движенията на тялото, физическата реалистичност и следването на инструкции.",
|
||||
"MiniMax-M1.description": "Нов вътрешен модел за разсъждение с 80K верига на мисълта и 1M вход, предлагащ производителност, сравнима с водещите глобални модели.",
|
||||
"MiniMax-M2-Stable.description": "Създаден за ефективно програмиране и агентски работни потоци, с по-висока едновременност за търговска употреба.",
|
||||
"MiniMax-M2.1-Lightning.description": "Мощни многоезични програмни възможности с по-бързо и ефективно извеждане.",
|
||||
"MiniMax-M2.1-highspeed.description": "Мощни многоезични програмни възможности, цялостно подобрено програмиране. По-бързо и по-ефективно.",
|
||||
"MiniMax-M2.1.description": "MiniMax-M2.1 е водеща отворена голяма езикова система от MiniMax, фокусирана върху решаването на сложни реални задачи. Основните ѝ предимства са възможностите за програмиране на множество езици и способността да действа като агент за решаване на сложни задачи.",
|
||||
"MiniMax-M2.5-highspeed.description": "MiniMax M2.5 Highspeed: Същата производителност като M2.5, но с по-бързо извеждане.",
|
||||
@@ -315,13 +314,13 @@
|
||||
"claude-3-haiku-20240307.description": "Claude 3 Haiku е най-бързият и най-компактен модел на Anthropic, проектиран за почти мигновени отговори с бърза и точна производителност.",
|
||||
"claude-3-opus-20240229.description": "Claude 3 Opus е най-мощният модел на Anthropic за силно сложни задачи, отличаващ се с производителност, интелигентност, плавност и разбиране.",
|
||||
"claude-3-sonnet-20240229.description": "Claude 3 Sonnet балансира интелигентност и скорост за корпоративни натоварвания, осигурявайки висока полезност на по-ниска цена и надеждно мащабно внедряване.",
|
||||
"claude-haiku-4-5-20251001.description": "Claude Haiku 4.5 е най-бързият и интелигентен модел Haiku на Anthropic, с мълниеносна скорост и разширено мислене.",
|
||||
"claude-haiku-4-5-20251001.description": "Claude Haiku 4.5 е най-бързият и най-умният Haiku модел на Anthropic, с мълниеносна скорост и разширени възможности за разсъждение.",
|
||||
"claude-haiku-4-5.description": "Claude Haiku 4.5 от Anthropic — ново поколение Haiku с подобрено разсъждение и визия.",
|
||||
"claude-haiku-4.5.description": "Claude Haiku 4.5 е най-бързият и най-умен Haiku модел на Anthropic, с мълниеносна скорост и разширено разсъждение.",
|
||||
"claude-opus-4-1-20250805-thinking.description": "Claude Opus 4.1 Thinking е усъвършенстван вариант, който може да разкрие процеса си на разсъждение.",
|
||||
"claude-opus-4-1-20250805.description": "Claude Opus 4.1 е най-новият и най-способен модел на Anthropic за силно сложни задачи, превъзхождащ в производителност, интелигентност, плавност и разбиране.",
|
||||
"claude-opus-4-1-20250805.description": "Claude Opus 4.1 е най-новият и най-способен модел на Anthropic за силно сложни задачи, отличаващ се с висока производителност, интелигентност, плавност и разбиране.",
|
||||
"claude-opus-4-1.description": "Claude Opus 4.1 от Anthropic — премиум модел за дълбок анализ и разсъждение.",
|
||||
"claude-opus-4-20250514.description": "Claude Opus 4 е най-мощният модел на Anthropic за силно сложни задачи, превъзхождащ в производителност, интелигентност, плавност и разбиране.",
|
||||
"claude-opus-4-20250514.description": "Claude Opus 4 е най-мощният модел на Anthropic за силно сложни задачи, отличаващ се с висока производителност, интелигентност, плавност и разбиране.",
|
||||
"claude-opus-4-5-20251101.description": "Claude Opus 4.5 е флагманският модел на Anthropic, комбиниращ изключителна интелигентност с мащабируема производителност, идеален за сложни задачи, изискващи най-висококачествени отговори и разсъждение.",
|
||||
"claude-opus-4-5.description": "Claude Opus 4.5 от Anthropic — флагмански модел с върхово разсъждение и кодови умения.",
|
||||
"claude-opus-4-6.description": "Claude Opus 4.6 от Anthropic — флагман с 1M контекст и усъвършенствано разсъждение.",
|
||||
@@ -330,7 +329,7 @@
|
||||
"claude-opus-4.6-fast.description": "Claude Opus 4.6 е най-интелигентният модел на Anthropic за създаване на агенти и програмиране.",
|
||||
"claude-opus-4.6.description": "Claude Opus 4.6 е най-интелигентният модел на Anthropic за създаване на агенти и програмиране.",
|
||||
"claude-sonnet-4-20250514-thinking.description": "Claude Sonnet 4 Thinking може да генерира почти мигновени отговори или разширено стъпково мислене с видим процес.",
|
||||
"claude-sonnet-4-20250514.description": "Claude Sonnet 4 е най-интелигентният модел на Anthropic досега, предлагащ почти мигновени отговори или разширено стъпка по стъпка мислене с фино управление за API потребители.",
|
||||
"claude-sonnet-4-20250514.description": "Claude Sonnet 4 може да генерира почти мигновени отговори или разширено поетапно мислене с видим процес.",
|
||||
"claude-sonnet-4-5-20250929.description": "Claude Sonnet 4.5 е най-интелигентният модел на Anthropic досега.",
|
||||
"claude-sonnet-4-5.description": "Claude Sonnet 4.5 от Anthropic — подобрен Sonnet с по‑силни кодови способности.",
|
||||
"claude-sonnet-4-6.description": "Claude Sonnet 4.6 от Anthropic — последният Sonnet с превъзходно кодиране и работа с инструменти.",
|
||||
@@ -404,7 +403,7 @@
|
||||
"deepseek-ai/deepseek-llm-67b-chat.description": "DeepSeek LLM Chat (67B) е иновативен модел, предлагащ дълбоко езиково разбиране и интеракция.",
|
||||
"deepseek-ai/deepseek-v3.1-terminus.description": "DeepSeek V3.1 е модел за разсъждение от ново поколение с по-силни способности за сложни разсъждения и верига от мисли за задълбочени аналитични задачи.",
|
||||
"deepseek-ai/deepseek-v3.2.description": "DeepSeek V3.2 е модел за разсъждение от следващо поколение с по-силни способности за сложни разсъждения и верига на мисълта.",
|
||||
"deepseek-chat.description": "Съвместимостен псевдоним за DeepSeek V4 Flash в режим без мислене. Предстои да бъде прекратен — използвайте DeepSeek V4 Flash вместо това.",
|
||||
"deepseek-chat.description": "Нов модел с отворен код, комбиниращ общи и кодови способности. Той запазва общия диалогов характер на чат модела и силните кодови възможности на кодиращия модел, с по-добро съответствие на предпочитанията. DeepSeek-V2.5 също така подобрява писането и следването на инструкции.",
|
||||
"deepseek-coder-33B-instruct.description": "DeepSeek Coder 33B е езиков модел за програмиране, обучен върху 2 трилиона токени (87% код, 13% китайски/английски текст). Въвежда 16K контекстен прозорец и задачи за попълване в средата, осигурявайки допълване на код на ниво проект и попълване на фрагменти.",
|
||||
"deepseek-coder-v2.description": "DeepSeek Coder V2 е отворен MoE модел за програмиране, който се представя на ниво GPT-4 Turbo.",
|
||||
"deepseek-coder-v2:236b.description": "DeepSeek Coder V2 е отворен MoE модел за програмиране, който се представя на ниво GPT-4 Turbo.",
|
||||
@@ -426,7 +425,7 @@
|
||||
"deepseek-r1-fast-online.description": "Пълна бърза версия на DeepSeek R1 с търсене в реално време в уеб, комбинираща възможности от мащаб 671B и по-бърз отговор.",
|
||||
"deepseek-r1-online.description": "Пълна версия на DeepSeek R1 с 671 милиарда параметъра и търсене в реално време в уеб, предлагаща по-силно разбиране и генериране.",
|
||||
"deepseek-r1.description": "DeepSeek-R1 използва данни от студен старт преди подсиленото обучение и се представя наравно с OpenAI-o1 в математика, програмиране и разсъждение.",
|
||||
"deepseek-reasoner.description": "Съвместимостен псевдоним за DeepSeek V4 Flash в режим на мислене. Предстои да бъде прекратен — използвайте DeepSeek V4 Flash вместо това.",
|
||||
"deepseek-reasoner.description": "DeepSeek модел за разсъждение, фокусиран върху сложни логически задачи.",
|
||||
"deepseek-v2.description": "DeepSeek V2 е ефективен MoE модел за икономична обработка.",
|
||||
"deepseek-v2:236b.description": "DeepSeek V2 236B е модел на DeepSeek, фокусиран върху програмиране, с висока производителност при генериране на код.",
|
||||
"deepseek-v3-0324.description": "DeepSeek-V3-0324 е MoE модел с 671 милиарда параметъра, с изключителни способности в програмиране, технически задачи, разбиране на контекст и обработка на дълги текстове.",
|
||||
@@ -491,8 +490,6 @@
|
||||
"doubao-seedream-4-0-250828.description": "Seedream 4.0 е модел за генериране на изображения от ByteDance Seed, поддържащ вход от текст и изображения с високо контролируемо, висококачествено генериране на изображения. Генерира изображения от текстови подсказки.",
|
||||
"doubao-seedream-4-5-251128.description": "Seedream 4.5 е най-новият мултимодален модел за изображения на ByteDance, интегриращ текст-към-изображение, изображение-към-изображение и групово генериране на изображения, като включва обща логика и способности за разсъждение. В сравнение с предишната версия 4.0, той предлага значително подобрено качество на генериране, с по-добра консистентност при редактиране и мулти-изображение сливане. Осигурява по-прецизен контрол върху визуалните детайли, като произвежда малък текст и малки лица по-естествено, и постига по-хармонично оформление и цветове, подобрявайки цялостната естетика.",
|
||||
"doubao-seedream-5-0-260128.description": "Doubao-Seedream-5.0-lite е най-новият модел за генериране на изображения на ByteDance. За първи път интегрира възможности за онлайн извличане, позволявайки му да включва информация в реално време от уеб и да подобрява актуалността на генерираните изображения. Интелигентността на модела също е подобрена, позволявайки прецизно интерпретиране на сложни инструкции и визуално съдържание. Освен това предлага подобрено глобално покритие на знания, консистентност на референциите и качество на генериране в професионални сценарии, по-добре отговаряйки на нуждите за визуално създаване на корпоративно ниво.",
|
||||
"dreamina-seedance-2-0-260128.description": "Seedance 2.0 от ByteDance е най-мощният модел за генериране на видео, поддържащ многомодално генериране на референтни видеа, редактиране на видео, разширение на видео, текст към видео и изображение към видео със синхронизиран звук.",
|
||||
"dreamina-seedance-2-0-fast-260128.description": "Seedance 2.0 Fast от ByteDance предлага същите възможности като Seedance 2.0 с по-бързи скорости на генериране на по-конкурентна цена.",
|
||||
"emohaa.description": "Emohaa е модел за психично здраве с професионални консултантски способности, който помага на потребителите да разберат емоционални проблеми.",
|
||||
"ernie-4.5-0.3b.description": "ERNIE 4.5 0.3B е лек модел с отворен код за локално и персонализирано внедряване.",
|
||||
"ernie-4.5-8k-preview.description": "ERNIE 4.5 8K Preview е модел за предварителен преглед с 8K контекст за оценка на ERNIE 4.5.",
|
||||
@@ -506,6 +503,7 @@
|
||||
"ernie-5.0-thinking-latest.description": "Wenxin 5.0 Thinking е флагмански модел с пълна модалност, обединяващ текст, изображение, аудио и видео. Осигурява значителни подобрения за сложни QA, творчество и агентски сценарии.",
|
||||
"ernie-5.0-thinking-preview.description": "Wenxin 5.0 Thinking Preview е флагмански модел с пълна модалност, обединяващ текст, изображение, аудио и видео. Осигурява значителни подобрения за сложни QA, творчество и агентски сценарии.",
|
||||
"ernie-5.0.description": "ERNIE 5.0 е ново поколение мултимодален модел, който обединява текст, изображения, аудио и видео. Основните му способности са значително подобрени — силен в разбиране, следване на инструкции, творчество, фактическа точност, планиране и работа с инструменти.",
|
||||
"ernie-5.1.description": "ERNIE 5.1 е най-новият модел от серията ERNIE, с цялостни подобрения на основните си способности. Той демонстрира значителни подобрения в области като агенти, обработка на знания, разсъждение и дълбоко търсене. Това издание използва разделена напълно асинхронна архитектура за подсилено обучение, специално проектирана за справяне с ключови предизвикателства в еволюцията на големите модели към автономно вземане на решения от агенти, включително числови несъответствия между обучение и извеждане, ниско използване на хетерогенни изчислителни ресурси и глобални проблеми, причинени от ефекти на дългата опашка. Освен това се прилагат техники за постобучение на агенти в голям мащаб, за да се подобрят допълнително способностите и общата производителност на модела. Чрез тристепенна съвместна рамка, включваща процеси на среда, експерт и сливане, подходът не само гарантира ефективност на обучението, но и значително подобрява стабилността и производителността на модела при сложни задачи.",
|
||||
"ernie-char-fiction-8k-preview.description": "ERNIE Character Fiction 8K Preview е предварителен модел за създаване на персонажи и сюжет, предназначен за оценка и тестване на функции.",
|
||||
"ernie-char-fiction-8k.description": "ERNIE Character Fiction 8K е модел за персонажи, предназначен за романи и създаване на сюжет, подходящ за генериране на дълги истории.",
|
||||
"ernie-image-turbo.description": "ERNIE‑Image е 8B параметъра текст‑към‑изображение модел от Baidu. Води в множество класации, включително първо място в SuperCLUE в Китай.",
|
||||
@@ -517,8 +515,7 @@
|
||||
"ernie-x1-turbo-32k.description": "ERNIE X1 Turbo 32K е бърз мислещ модел с 32K контекст за сложни разсъждения и многозавойни разговори.",
|
||||
"ernie-x1.1-preview.description": "ERNIE X1.1 Preview е предварителен модел за мислене, предназначен за оценка и тестване.",
|
||||
"ernie-x1.1.description": "ERNIE X1.1 е мисловен модел за предварителен преглед за оценка и тестване.",
|
||||
"fal-ai/bytedance/seedream/v4.5.description": "Seedream 4.5, създаден от екипа Seed на ByteDance, поддържа редактиране и композиция на множество изображения. Характеризира се с подобрена консистентност на обектите, прецизно следване на инструкции, разбиране на пространствена логика, естетично изразяване, оформление на плакати и дизайн на лого с високопрецизно рендиране на текст и изображения.",
|
||||
"fal-ai/bytedance/seedream/v4.description": "Seedream 4.0, създаден от ByteDance Seed, поддържа текстови и визуални входове за силно контролируемо, висококачествено генериране на изображения от подсказки.",
|
||||
"fal-ai/bytedance/seedream/v4.description": "Seedream 4.0 е модел за генериране на изображения от ByteDance Seed, поддържащ текстови и визуални входове с високо контролируемо и висококачествено генериране на изображения. Той генерира изображения от текстови подсказки.",
|
||||
"fal-ai/flux-kontext/dev.description": "FLUX.1 модел, фокусиран върху редактиране на изображения, поддържащ вход от текст и изображения.",
|
||||
"fal-ai/flux-pro/kontext.description": "FLUX.1 Kontext [pro] приема текст и референтни изображения като вход, позволявайки целенасочени локални редакции и сложни глобални трансформации на сцени.",
|
||||
"fal-ai/flux/krea.description": "Flux Krea [dev] е модел за генериране на изображения с естетично предпочитание към по-реалистични и естествени изображения.",
|
||||
@@ -526,8 +523,8 @@
|
||||
"fal-ai/hunyuan-image/v3.description": "Мощен роден мултимодален модел за генериране на изображения.",
|
||||
"fal-ai/imagen4/preview.description": "Модел за висококачествено генериране на изображения от Google.",
|
||||
"fal-ai/nano-banana.description": "Nano Banana е най-новият, най-бърз и най-ефективен роден мултимодален модел на Google, позволяващ генериране и редактиране на изображения чрез разговор.",
|
||||
"fal-ai/qwen-image-edit.description": "Професионален модел за редактиране на изображения от екипа Qwen, поддържащ семантични и визуални редакции, прецизно редактиране на текст на китайски/английски, трансфер на стил, ротация и други.",
|
||||
"fal-ai/qwen-image.description": "Мощен модел за генериране на изображения от екипа Qwen с силно рендиране на китайски текст и разнообразни визуални стилове.",
|
||||
"fal-ai/qwen-image-edit.description": "Професионален модел за редактиране на изображения от екипа на Qwen, който поддържа семантични и визуални редакции, прецизно редактира китайски и английски текст и позволява висококачествени редакции като трансфер на стил и ротация на обекти.",
|
||||
"fal-ai/qwen-image.description": "Мощен модел за генериране на изображения от екипа на Qwen с впечатляващо рендиране на китайски текст и разнообразни визуални стилове.",
|
||||
"flux-1-schnell.description": "Модел за преобразуване на текст в изображение с 12 милиарда параметъра от Black Forest Labs, използващ латентна дифузионна дестилация за генериране на висококачествени изображения в 1–4 стъпки. Съперничи на затворени алтернативи и е пуснат под лиценз Apache-2.0 за лична, изследователска и търговска употреба.",
|
||||
"flux-dev.description": "Модел за генериране на изображения с отворен код, оптимизиран за неконкурентни изследвания и иновации.",
|
||||
"flux-kontext-max.description": "Съвременно генериране и редактиране на изображения с контекст, комбиниращо текст и изображения за прецизни и последователни резултати.",
|
||||
@@ -566,10 +563,10 @@
|
||||
"gemini-3-flash-preview.description": "Gemini 3 Flash е най-интелигентният модел, създаден за скорост, съчетаващ авангардна интелигентност с отлично търсене и обоснованост.",
|
||||
"gemini-3-flash.description": "Gemini 3 Flash от Google — ултрабърз модел с мултимодална поддръжка.",
|
||||
"gemini-3-pro-image-preview.description": "Gemini 3 Pro Image (Nano Banana Pro) е модел за генериране на изображения на Google, който също поддържа мултимодален диалог.",
|
||||
"gemini-3-pro-image-preview:image.description": "Gemini 3 Pro Image (Nano Banana Pro) е моделът на Google за генериране на изображения и също така поддържа многомодален чат.",
|
||||
"gemini-3-pro-image-preview:image.description": "Gemini 3 Pro Image (Nano Banana Pro) е моделът на Google за генериране на изображения, който също поддържа мултимодален чат.",
|
||||
"gemini-3-pro-preview.description": "Gemini 3 Pro е най-мощният агентен и „vibe-coding“ модел на Google, който предлага по-богати визуализации и по-дълбоко взаимодействие, базирано на съвременно логическо мислене.",
|
||||
"gemini-3.1-flash-image-preview.description": "Gemini 3.1 Flash Image (Nano Banana 2) е най-бързият модел на Google за генериране на изображения с поддръжка на мислене, разговорно генериране и редактиране на изображения.",
|
||||
"gemini-3.1-flash-image-preview:image.description": "Gemini 3.1 Flash Image (Nano Banana 2) предоставя качество на изображения от професионално ниво с Flash скорост и поддръжка на многомодален чат.",
|
||||
"gemini-3.1-flash-image-preview:image.description": "Gemini 3.1 Flash Image (Nano Banana 2) е най-бързият модел на Google за генериране на изображения с поддръжка на мислене, разговорно генериране и редактиране на изображения.",
|
||||
"gemini-3.1-flash-lite-preview.description": "Gemini 3.1 Flash-Lite Preview е най-икономичният мултимодален модел на Google, оптимизиран за задачи с голям обем, превод и обработка на данни.",
|
||||
"gemini-3.1-flash-lite.description": "Gemini 3.1 Flash-Lite е най-икономичният мултимодален модел на Google, оптимизиран за задачи с голям обем, превод и обработка на данни.",
|
||||
"gemini-3.1-pro-preview.description": "Gemini 3.1 Pro Preview подобрява Gemini 3 Pro с усъвършенствани способности за разсъждение и добавя поддръжка за средно ниво на мислене.",
|
||||
@@ -734,8 +731,6 @@
|
||||
"grok-4-fast-reasoning.description": "С гордост представяме Grok 4 Fast – нашият най-нов напредък в икономичните логически модели.",
|
||||
"grok-4.20-0309-non-reasoning.description": "Неразсъждаващ вариант за прости случаи.",
|
||||
"grok-4.20-0309-reasoning.description": "Интелигентен, изключително бърз модел с разсъждение.",
|
||||
"grok-4.20-beta-0309-non-reasoning.description": "Вариант без мислене за прости случаи на употреба.",
|
||||
"grok-4.20-beta-0309-reasoning.description": "Интелигентен, изключително бърз модел, който разсъждава преди да отговори.",
|
||||
"grok-4.20-multi-agent-0309.description": "Екип от 4 или 16 агента — отличен за проучвания; поддържа само xAI сървърни инструменти.",
|
||||
"grok-4.3.description": "Най-истинно търсещият голям езиков модел в света",
|
||||
"grok-4.description": "Най-новият флагман Grok с ненадмината производителност в езика, математиката и разсъжденията — истински универсален модел. В момента сочи към grok-4-0709; поради ограничени ресурси временно е с 10% по-висока цена от официалната и се очаква да се върне към официалната цена по-късно.",
|
||||
@@ -1220,8 +1215,6 @@
|
||||
"qwq.description": "QwQ е модел за аргументация от семейството на Qwen. В сравнение със стандартните модели, обучени с инструкции, предлага мисловни и логически способности, които значително подобряват ефективността при трудни задачи. QwQ-32B е среден по размер модел, който се конкурира с водещи модели като DeepSeek-R1 и o1-mini.",
|
||||
"qwq_32b.description": "Среден по размер модел за аргументация от семейството на Qwen. В сравнение със стандартните модели, обучени с инструкции, мисловните и логическите способности на QwQ значително подобряват ефективността при трудни задачи.",
|
||||
"r1-1776.description": "R1-1776 е дообучен вариант на DeepSeek R1, създаден да предоставя неконфронтирана, обективна и фактическа информация.",
|
||||
"seedance-1-5-pro-251215.description": "Seedance 1.5 Pro от ByteDance поддържа текст към видео, изображение към видео (първи кадър, първи+последен кадър) и генериране на звук, синхронизиран с визуализации.",
|
||||
"seedream-5-0-260128.description": "ByteDance-Seedream-5.0-lite от BytePlus предлага генериране, обогатено с уеб извличане за информация в реално време, подобрена интерпретация на сложни подсказки и подобрена консистентност на референциите за професионално визуално създаване.",
|
||||
"solar-mini-ja.description": "Solar Mini (Ja) разширява Solar Mini с фокус върху японски език, като запазва ефективността и силната производителност на английски и корейски.",
|
||||
"solar-mini.description": "Solar Mini е компактен LLM, който превъзхожда GPT-3.5, с мощни многоезични възможности, поддържащ английски и корейски, и предлага ефективно решение с малък отпечатък.",
|
||||
"solar-pro.description": "Solar Pro е интелигентен LLM от Upstage, фокусиран върху следване на инструкции на един GPU, с IFEval резултати над 80. Понастоящем поддържа английски; пълното издание е планирано за ноември 2024 с разширена езикова поддръжка и по-дълъг контекст.",
|
||||
|
||||
@@ -27,6 +27,13 @@
|
||||
"agent.layout.skipConfirm.ok": "Пропуснете засега",
|
||||
"agent.layout.skipConfirm.title": "Да пропуснете въвеждането засега?",
|
||||
"agent.layout.switchMessage": "Не сте в настроение днес? Можете да преминете в <modeLink><modeText>{{mode}}</modeText></modeLink> или да <skipLink><skipText>{{skip}}</skipText></skipLink>.",
|
||||
"agent.layout.switchMessageClassic": "Не ви допада днес? Можете да превключите на <modeLink><modeText>{{mode}}</modeText></modeLink>.",
|
||||
"agent.messenger.cta.discord": "Добави към Discord",
|
||||
"agent.messenger.cta.slack": "Добави към Slack",
|
||||
"agent.messenger.cta.telegram": "Отвори в Telegram",
|
||||
"agent.messenger.subtitle": "Чатете с вашия агент в Telegram, Slack или Discord",
|
||||
"agent.messenger.telegramQrCaption": "Сканирайте с камерата на телефона си",
|
||||
"agent.messenger.title": "Дръжте ме с вас, където и да съобщавате",
|
||||
"agent.modeSwitch.agent": "Разговорен",
|
||||
"agent.modeSwitch.classic": "Класически",
|
||||
"agent.modeSwitch.collapse": "Свий",
|
||||
@@ -68,6 +75,13 @@
|
||||
"agent.wrapUp.confirm.content": "Ще запазя това, което обсъдихме до момента. Винаги можете да се върнете и да продължим разговора.",
|
||||
"agent.wrapUp.confirm.ok": "Приключи сега",
|
||||
"agent.wrapUp.confirm.title": "Да приключим ли онбординга?",
|
||||
"agentPicker.allCategories": "Всички",
|
||||
"agentPicker.continue": "Продължи",
|
||||
"agentPicker.skip": "Пропусни за сега",
|
||||
"agentPicker.subtitle": "Добавете няколко към вашата библиотека сега — открийте още по-късно.",
|
||||
"agentPicker.title": "Нека добавим няколко агента към вашата библиотека",
|
||||
"agentPicker.title2": "Изберете тези, които съответстват на начина ви на работа",
|
||||
"agentPicker.title3": "Винаги можете да добавите още по-късно — започнете с няколко",
|
||||
"back": "Назад",
|
||||
"finish": "Да започнем",
|
||||
"interests.area.business": "Бизнес и стратегия",
|
||||
|
||||
@@ -39,8 +39,8 @@
|
||||
"builtins.lobe-agent-documents.inspector.docCount": "{{count}} документа",
|
||||
"builtins.lobe-agent-documents.inspector.opsCount": "{{count}} операции",
|
||||
"builtins.lobe-agent-documents.inspector.opsResult": "{{success}}/{{total}} операции",
|
||||
"builtins.lobe-agent-documents.inspector.target.agent": "в агент",
|
||||
"builtins.lobe-agent-documents.inspector.target.currentTopic": "в тема",
|
||||
"builtins.lobe-agent-documents.inspector.scope.agent": "в агент",
|
||||
"builtins.lobe-agent-documents.inspector.scope.currentTopic": "в тема",
|
||||
"builtins.lobe-agent-documents.title": "Документи на агент",
|
||||
"builtins.lobe-agent-management.apiName.callAgent": "Обаждане на агент",
|
||||
"builtins.lobe-agent-management.apiName.createAgent": "Създаване на агент",
|
||||
@@ -90,6 +90,14 @@
|
||||
"builtins.lobe-agent.title": "Lobe Агент",
|
||||
"builtins.lobe-claude-code.agent.instruction": "Инструкция",
|
||||
"builtins.lobe-claude-code.agent.result": "Резултат",
|
||||
"builtins.lobe-claude-code.task.createLabel": "Създаване на задача: ",
|
||||
"builtins.lobe-claude-code.task.getLabel": "Преглеждане на задача #{{taskId}}",
|
||||
"builtins.lobe-claude-code.task.listLabel": "Списък със задачи",
|
||||
"builtins.lobe-claude-code.task.updateCompleted": "Завършено",
|
||||
"builtins.lobe-claude-code.task.updateDeleted": "Изтрито",
|
||||
"builtins.lobe-claude-code.task.updateInProgress": "Започнато",
|
||||
"builtins.lobe-claude-code.task.updateLabel": "Актуализиране на задача #{{taskId}}",
|
||||
"builtins.lobe-claude-code.task.updatePending": "Нулиране",
|
||||
"builtins.lobe-claude-code.todoWrite.allDone": "Всички задачи са изпълнени",
|
||||
"builtins.lobe-claude-code.todoWrite.currentStep": "Текуща стъпка",
|
||||
"builtins.lobe-claude-code.todoWrite.todos": "Задачи",
|
||||
|
||||
@@ -33,7 +33,6 @@
|
||||
"jina.description": "Основана през 2020 г., Jina AI е водеща компания в областта на търсещия AI. Технологичният ѝ стек включва векторни модели, преоценители и малки езикови модели за създаване на надеждни генеративни и мултимодални търсещи приложения.",
|
||||
"kimicodingplan.description": "Kimi Code от Moonshot AI предоставя достъп до модели Kimi, включително K2.5, за задачи, свързани с програмиране.",
|
||||
"lmstudio.description": "LM Studio е десктоп приложение за разработка и експериментиране с LLM на вашия компютър.",
|
||||
"lobehub.description": "LobeHub Cloud използва официални API, за да осъществява достъп до AI модели и измерва използването чрез Кредити, свързани с токените на модела.",
|
||||
"longcat.description": "LongCat е серия от големи модели за генеративен AI, независимо разработени от Meituan. Той е създаден да подобри вътрешната продуктивност на предприятието и да позволи иновативни приложения чрез ефективна изчислителна архитектура и силни мултимодални възможности.",
|
||||
"minimax.description": "Основана през 2021 г., MiniMax създава универсален AI с мултимодални базови модели, включително текстови модели с трилиони параметри, речеви и визуални модели, както и приложения като Hailuo AI.",
|
||||
"minimaxcodingplan.description": "MiniMax Token Plan предоставя достъп до модели MiniMax, включително M2.7, за задачи, свързани с програмиране, чрез абонамент с фиксирана такса.",
|
||||
|
||||
@@ -55,6 +55,12 @@
|
||||
"credits.autoTopUp.toggle": "Активирайте автоматичното презареждане",
|
||||
"credits.autoTopUp.upgradeHint": "Абонирайте се за платен план, за да активирате автоматичното презареждане",
|
||||
"credits.autoTopUp.validation.targetMustExceedThreshold": "Целевият баланс трябва да бъде по-голям от прага",
|
||||
"credits.costEstimateHint.desc": "Показване на леко предупреждение преди изпращане, когато прогнозната цена на модела достигне вашия праг",
|
||||
"credits.costEstimateHint.saveError": "Неуспешно запазване на настройките за предупреждение за прогнозна цена",
|
||||
"credits.costEstimateHint.saveSuccess": "Настройките за предупреждение за прогнозна цена са запазени",
|
||||
"credits.costEstimateHint.threshold": "Праг за предупреждение",
|
||||
"credits.costEstimateHint.title": "Предупреждение за прогнозна цена",
|
||||
"credits.costEstimateHint.validation.threshold": "Прагът трябва да бъде по-голям или равен на 0",
|
||||
"credits.packages.auto": "Автоматично",
|
||||
"credits.packages.charged": "Таксувани ${{amount}}",
|
||||
"credits.packages.expired": "Изтекъл",
|
||||
|
||||
@@ -40,6 +40,14 @@
|
||||
"agentMarketplace.render.alreadyInLibraryTag": "Вече в библиотеката",
|
||||
"agentMarketplace.render.alreadyInLibrary_one": "{{count}} вече в библиотеката",
|
||||
"agentMarketplace.render.alreadyInLibrary_other": "{{count}} вече в библиотеката",
|
||||
"claudeCode.askUserQuestion.escape.back": "Назад към опциите",
|
||||
"claudeCode.askUserQuestion.escape.enter": "Или въведете директно",
|
||||
"claudeCode.askUserQuestion.escape.placeholder": "Въведете вашия отговор тук…",
|
||||
"claudeCode.askUserQuestion.multiSelectTag": "(многоизбор)",
|
||||
"claudeCode.askUserQuestion.skip": "Пропусни",
|
||||
"claudeCode.askUserQuestion.submit": "Изпрати",
|
||||
"claudeCode.askUserQuestion.timeExpired": "Времето изтече — използва се опция 1 за всеки въпрос.",
|
||||
"claudeCode.askUserQuestion.timeRemaining": "Оставащо време: {{time}} · въпросите без отговор ще се задават на опция 1 при изтичане на времето.",
|
||||
"codeInterpreter-legacy.error": "Грешка при изпълнение",
|
||||
"codeInterpreter-legacy.executing": "Изпълнение...",
|
||||
"codeInterpreter-legacy.files": "Файлове:",
|
||||
|
||||
@@ -56,6 +56,7 @@
|
||||
"renameModal.title": "Преименуване на тема",
|
||||
"searchPlaceholder": "Търсене в темите...",
|
||||
"searchResultEmpty": "Няма намерени резултати от търсенето.",
|
||||
"sidebar.title": "Теми",
|
||||
"taskManager.agent": "Агент за задачи",
|
||||
"taskManager.welcome": "Попитай ме за твоите задачи",
|
||||
"temp": "Временна",
|
||||
|
||||
@@ -220,6 +220,13 @@
|
||||
"inbox.title": "Lobe AI",
|
||||
"input.addAi": "KI-Nachricht hinzufügen",
|
||||
"input.addUser": "Benutzernachricht hinzufügen",
|
||||
"input.costEstimate.creditsPerMillionTokens": "{{credits}} Credits/M Tokens",
|
||||
"input.costEstimate.hint": "Geschätzte Kosten: ~{{credits}} Credits",
|
||||
"input.costEstimate.inputLabel": "Eingabe",
|
||||
"input.costEstimate.outputLabel": "Ausgabe",
|
||||
"input.costEstimate.settingsLink": "Warnschwelle anpassen",
|
||||
"input.costEstimate.tokenCount": "~{{tokens}} Tokens",
|
||||
"input.costEstimate.tooltip": "Geschätzt basierend auf aktuellem Kontext, Tools und Modellpreisen. Tatsächliche Kosten können abweichen.",
|
||||
"input.disclaimer": "Agenten können Fehler machen. Verwenden Sie Ihr Urteilsvermögen bei kritischen Informationen.",
|
||||
"input.errorMsg": "Senden fehlgeschlagen: {{errorMsg}}. Versuchen Sie es erneut oder später.",
|
||||
"input.more": "Mehr",
|
||||
@@ -779,6 +786,7 @@
|
||||
"upload.preview.prepareTasks": "Datei wird vorbereitet...",
|
||||
"upload.preview.status.pending": "Vorbereitung zum Hochladen...",
|
||||
"upload.preview.status.processing": "Datei wird verarbeitet...",
|
||||
"upload.validation.unsupportedFileType": "Nicht unterstützter Dateityp: {{files}}. Unterstützte Bilder: JPG, PNG, GIF, WebP. Unterstützte Dokumente umfassen PDF, Word, Excel, PowerPoint, Markdown, Text, CSV, JSON und Code-Dateien.",
|
||||
"upload.validation.videoSizeExceeded": "Die Videodatei darf 20 MB nicht überschreiten. Aktuelle Größe: {{actualSize}}.",
|
||||
"viewMode.fullWidth": "Volle Breite",
|
||||
"viewMode.normal": "Standard",
|
||||
@@ -894,6 +902,8 @@
|
||||
"workingPanel.localFile.closeOther": "Andere schließen",
|
||||
"workingPanel.localFile.closeRight": "Rechts schließen",
|
||||
"workingPanel.localFile.error": "Diese Datei konnte nicht geladen werden",
|
||||
"workingPanel.localFile.preview.raw": "Rohdaten",
|
||||
"workingPanel.localFile.preview.render": "Vorschau",
|
||||
"workingPanel.localFile.truncated": "Dateivorschau auf {{limit}} Zeichen gekürzt",
|
||||
"workingPanel.progress": "Progress",
|
||||
"workingPanel.progress.allCompleted": "All tasks completed",
|
||||
@@ -959,6 +969,8 @@
|
||||
"workingPanel.review.viewMode.unified": "Zur einheitlichen Ansicht wechseln",
|
||||
"workingPanel.review.wordWrap.disable": "Zeilenumbruch deaktivieren",
|
||||
"workingPanel.review.wordWrap.enable": "Zeilenumbruch aktivieren",
|
||||
"workingPanel.skills.empty": "Keine Fähigkeiten in diesem Projekt gefunden",
|
||||
"workingPanel.skills.title": "Fähigkeiten",
|
||||
"workingPanel.space": "Leerzeichen",
|
||||
"workingPanel.title": "Working Panel",
|
||||
"you": "Du",
|
||||
|
||||
@@ -121,6 +121,16 @@
|
||||
"ModelSwitchPanel.detail.context": "Kontextlänge",
|
||||
"ModelSwitchPanel.detail.pricing": "Preise",
|
||||
"ModelSwitchPanel.detail.pricing.cachedInput": "Gecachter Input ${{amount}}/M",
|
||||
"ModelSwitchPanel.detail.pricing.credits.cachedInput": "Zwischengespeicherter Eingabewert {{amount}} Credits/M Tokens",
|
||||
"ModelSwitchPanel.detail.pricing.credits.image": "Credits/Bild",
|
||||
"ModelSwitchPanel.detail.pricing.credits.input": "Eingabe {{amount}} Credits/M Tokens",
|
||||
"ModelSwitchPanel.detail.pricing.credits.megapixel": "Credits/MP",
|
||||
"ModelSwitchPanel.detail.pricing.credits.millionCharacters": "Credits/M Zeichen",
|
||||
"ModelSwitchPanel.detail.pricing.credits.millionTokens": "Credits/M Tokens",
|
||||
"ModelSwitchPanel.detail.pricing.credits.output": "Ausgabe {{amount}} Credits/M Tokens",
|
||||
"ModelSwitchPanel.detail.pricing.credits.perImage": "~ {{amount}} Credits / Bild",
|
||||
"ModelSwitchPanel.detail.pricing.credits.perVideo": "~ {{amount}} Credits / Video",
|
||||
"ModelSwitchPanel.detail.pricing.credits.second": "Credits/s",
|
||||
"ModelSwitchPanel.detail.pricing.group.audio": "Audio",
|
||||
"ModelSwitchPanel.detail.pricing.group.image": "Bild",
|
||||
"ModelSwitchPanel.detail.pricing.group.text": "Text",
|
||||
|
||||
@@ -1,8 +1,10 @@
|
||||
{
|
||||
"actionTag.category.command": "Befehl",
|
||||
"actionTag.category.projectSkill": "Projektfertigkeit",
|
||||
"actionTag.category.skill": "Fähigkeit",
|
||||
"actionTag.category.tool": "Werkzeug",
|
||||
"actionTag.tooltip.command": "Führt vor dem Senden einen clientseitigen Slash-Befehl aus.",
|
||||
"actionTag.tooltip.projectSkill": "Als Slash-Befehl gesendet, damit die CLI des Agenten die passende Projektfertigkeit ausführt.",
|
||||
"actionTag.tooltip.skill": "Lädt für diese Anfrage ein wiederverwendbares Fähigkeitspaket.",
|
||||
"actionTag.tooltip.tool": "Markiert ein Werkzeug, das der Benutzer für diese Anfrage ausdrücklich ausgewählt hat.",
|
||||
"actions.expand.off": "Einklappen",
|
||||
|
||||
@@ -11,6 +11,19 @@
|
||||
"brief.action.ignore": "Ignorieren",
|
||||
"brief.action.retry": "Erneut versuchen",
|
||||
"brief.addFeedback": "Feedback teilen",
|
||||
"brief.agentSignal.selfReview.applied.heading": "Aktualisiert",
|
||||
"brief.agentSignal.selfReview.applied.summary": "{{count}} Traumaktualisierung wurde angewendet.",
|
||||
"brief.agentSignal.selfReview.applied.summary_plural": "{{count}} Traumaktualisierungen wurden angewendet.",
|
||||
"brief.agentSignal.selfReview.applied.title": "Traumressourcen aktualisiert",
|
||||
"brief.agentSignal.selfReview.error.heading": "Problem",
|
||||
"brief.agentSignal.selfReview.error.summary": "Einige Arbeiten konnten während dieses Traums nicht abgeschlossen werden.",
|
||||
"brief.agentSignal.selfReview.error.title": "Traum stieß auf ein Problem",
|
||||
"brief.agentSignal.selfReview.ideas.summary": "Gespeicherte Traumnotizen für zukünftige Überprüfung.",
|
||||
"brief.agentSignal.selfReview.ideas.title": "Traumnotizen",
|
||||
"brief.agentSignal.selfReview.proposal.heading": "Vorschlag",
|
||||
"brief.agentSignal.selfReview.proposal.summary": "{{count}} Traumvorschlag benötigt Ihre Überprüfung.",
|
||||
"brief.agentSignal.selfReview.proposal.summary_plural": "{{count}} Traumvorschläge benötigen Ihre Überprüfung.",
|
||||
"brief.agentSignal.selfReview.proposal.title": "Traumvorschlag benötigt Überprüfung",
|
||||
"brief.collapse": "Weniger anzeigen",
|
||||
"brief.commentPlaceholder": "Ihr Feedback teilen...",
|
||||
"brief.commentSubmit": "Feedback senden",
|
||||
|
||||
@@ -1,8 +1,6 @@
|
||||
{
|
||||
"addUserMessage.desc": "Füge die aktuelle Eingabe als Benutzernachricht hinzu, ohne die Generierung auszulösen",
|
||||
"addUserMessage.title": "Benutzernachricht hinzufügen",
|
||||
"clearCurrentMessages.desc": "Lösche die Nachrichten und hochgeladenen Dateien aus dem aktuellen Gespräch",
|
||||
"clearCurrentMessages.title": "Gesprächsnachrichten löschen",
|
||||
"commandPalette.desc": "Öffne die globale Befehlspalette für schnellen Zugriff auf Funktionen",
|
||||
"commandPalette.title": "Befehlspalette",
|
||||
"deleteAndRegenerateMessage.desc": "Lösche die letzte Nachricht und generiere sie neu",
|
||||
|
||||
+10
-17
@@ -106,7 +106,6 @@
|
||||
"MiniMax-Hailuo-2.3.description": "Brandneues Videoerzeugungsmodell mit umfassenden Verbesserungen in Körperbewegung, physikalischem Realismus und Befolgung von Anweisungen.",
|
||||
"MiniMax-M1.description": "Ein neues Inhouse-Argumentationsmodell mit 80K Chain-of-Thought und 1M Eingabe, vergleichbar mit führenden globalen Modellen.",
|
||||
"MiniMax-M2-Stable.description": "Entwickelt für effizientes Coden und Agenten-Workflows mit höherer Parallelität für den kommerziellen Einsatz.",
|
||||
"MiniMax-M2.1-Lightning.description": "Leistungsstarke mehrsprachige Programmierfähigkeiten mit schnellerer und effizienterer Inferenz.",
|
||||
"MiniMax-M2.1-highspeed.description": "Leistungsstarke mehrsprachige Programmierfähigkeiten, umfassend verbesserte Programmiererfahrung. Schneller und effizienter.",
|
||||
"MiniMax-M2.1.description": "MiniMax-M2.1 ist das Flaggschiff unter den Open-Source-Großmodellen von MiniMax und konzentriert sich auf die Lösung komplexer Aufgaben aus der realen Welt. Seine zentralen Stärken liegen in der mehrsprachigen Programmierfähigkeit und der Fähigkeit, als Agent komplexe Aufgaben zu bewältigen.",
|
||||
"MiniMax-M2.5-highspeed.description": "MiniMax M2.5 Highspeed: Gleiche Leistung wie M2.5 mit schnellerer Inferenz.",
|
||||
@@ -315,13 +314,13 @@
|
||||
"claude-3-haiku-20240307.description": "Claude 3 Haiku ist das schnellste und kompakteste Modell von Anthropic, entwickelt für nahezu sofortige Antworten mit schneller, präziser Leistung.",
|
||||
"claude-3-opus-20240229.description": "Claude 3 Opus ist das leistungsstärkste Modell von Anthropic für hochkomplexe Aufgaben. Es überzeugt in Leistung, Intelligenz, Sprachfluss und Verständnis.",
|
||||
"claude-3-sonnet-20240229.description": "Claude 3 Sonnet bietet eine ausgewogene Kombination aus Intelligenz und Geschwindigkeit für Unternehmensanwendungen. Es liefert hohe Nutzbarkeit bei geringeren Kosten und zuverlässiger Skalierbarkeit.",
|
||||
"claude-haiku-4-5-20251001.description": "Claude Haiku 4.5 ist das schnellste und intelligenteste Haiku-Modell von Anthropic, mit blitzschneller Geschwindigkeit und erweitertem Denken.",
|
||||
"claude-haiku-4-5-20251001.description": "Claude Haiku 4.5 ist das schnellste und intelligenteste Haiku-Modell von Anthropic, mit blitzschneller Geschwindigkeit und erweitertem logischen Denken.",
|
||||
"claude-haiku-4-5.description": "Claude Haiku 4.5 von Anthropic — Next-Gen-Haiku mit verbessertem Reasoning und Vision.",
|
||||
"claude-haiku-4.5.description": "Claude Haiku 4.5 ist das schnellste und intelligenteste Haiku-Modell von Anthropic, mit blitzschneller Geschwindigkeit und erweiterten Denkfähigkeiten.",
|
||||
"claude-opus-4-1-20250805-thinking.description": "Claude Opus 4.1 Thinking ist eine erweiterte Variante, die ihren Denkprozess offenlegen kann.",
|
||||
"claude-opus-4-1-20250805.description": "Claude Opus 4.1 ist das neueste und leistungsfähigste Modell von Anthropic für hochkomplexe Aufgaben, das in Leistung, Intelligenz, Sprachgewandtheit und Verständnis herausragt.",
|
||||
"claude-opus-4-1.description": "Claude Opus 4.1 von Anthropic — Premium-Reasoning-Modell mit tiefgehender Analysefähigkeit.",
|
||||
"claude-opus-4-20250514.description": "Claude Opus 4 ist das leistungsstärkste Modell von Anthropic für hochkomplexe Aufgaben, das in Leistung, Intelligenz, Sprachgewandtheit und Verständnis herausragt.",
|
||||
"claude-opus-4-20250514.description": "Claude Opus 4 ist das leistungsstärkste Modell von Anthropic für hochkomplexe Aufgaben, das in Leistung, Intelligenz, Sprachgewandtheit und Verständnis brilliert.",
|
||||
"claude-opus-4-5-20251101.description": "Claude Opus 4.5 ist das Flaggschiffmodell von Anthropic. Es kombiniert herausragende Intelligenz mit skalierbarer Leistung und ist ideal für komplexe Aufgaben, die höchste Qualität bei Antworten und logischem Denken erfordern.",
|
||||
"claude-opus-4-5.description": "Claude Opus 4.5 von Anthropic — Flaggschiffmodell mit erstklassigem Reasoning und Coding.",
|
||||
"claude-opus-4-6.description": "Claude Opus 4.6 von Anthropic — Flaggschiffmodell mit 1M Kontextfenster und erweitertem Reasoning.",
|
||||
@@ -330,7 +329,7 @@
|
||||
"claude-opus-4.6-fast.description": "Claude Opus 4.6 ist das intelligenteste Modell von Anthropic für die Entwicklung von Agenten und Programmierung.",
|
||||
"claude-opus-4.6.description": "Claude Opus 4.6 ist das intelligenteste Modell von Anthropic für die Entwicklung von Agenten und Programmierung.",
|
||||
"claude-sonnet-4-20250514-thinking.description": "Claude Sonnet 4 Thinking kann nahezu sofortige Antworten oder schrittweises Denken mit sichtbarem Prozess erzeugen.",
|
||||
"claude-sonnet-4-20250514.description": "Claude Sonnet 4 ist das bisher intelligenteste Modell von Anthropic, das nahezu sofortige Antworten oder erweitertes schrittweises Denken mit fein abgestimmter Kontrolle für API-Nutzer bietet.",
|
||||
"claude-sonnet-4-20250514.description": "Claude Sonnet 4 kann nahezu sofortige Antworten oder ausführliches schrittweises Denken mit sichtbarem Prozess erzeugen.",
|
||||
"claude-sonnet-4-5-20250929.description": "Claude Sonnet 4.5 ist das bisher intelligenteste Modell von Anthropic.",
|
||||
"claude-sonnet-4-5.description": "Claude Sonnet 4.5 von Anthropic — weiterentwickeltes Sonnet mit verbesserter Coding-Leistung.",
|
||||
"claude-sonnet-4-6.description": "Claude Sonnet 4.6 von Anthropic — neuestes Sonnet mit überlegener Coding- und Tool-Nutzung.",
|
||||
@@ -404,7 +403,7 @@
|
||||
"deepseek-ai/deepseek-llm-67b-chat.description": "DeepSeek LLM Chat (67B) ist ein innovatives Modell mit tiefem Sprachverständnis und Interaktionsfähigkeit.",
|
||||
"deepseek-ai/deepseek-v3.1-terminus.description": "DeepSeek V3.1 ist ein Next-Gen-Denkmodell mit stärkerem komplexem Denken und Chain-of-Thought für tiefgreifende Analyseaufgaben.",
|
||||
"deepseek-ai/deepseek-v3.2.description": "DeepSeek V3.2 ist ein Next-Gen-Modell für logisches Denken mit stärkeren Fähigkeiten für komplexes Denken und Kettenlogik.",
|
||||
"deepseek-chat.description": "Kompatibilitätsalias für den DeepSeek V4 Flash-Modus ohne Denken. Geplant für die Ausmusterung — verwenden Sie stattdessen DeepSeek V4 Flash.",
|
||||
"deepseek-chat.description": "Ein neues Open-Source-Modell, das allgemeine und Code-Fähigkeiten kombiniert. Es bewahrt den allgemeinen Dialog des Chat-Modells und die starken Codierungsfähigkeiten des Coder-Modells, mit besserer Präferenzabstimmung. DeepSeek-V2.5 verbessert außerdem das Schreiben und die Befolgung von Anweisungen.",
|
||||
"deepseek-coder-33B-instruct.description": "DeepSeek Coder 33B ist ein Code-Sprachmodell, trainiert auf 2 B Tokens (87 % Code, 13 % chinesisch/englischer Text). Es bietet ein 16K-Kontextfenster und Fill-in-the-Middle-Aufgaben für projektweite Codevervollständigung und Snippet-Ergänzung.",
|
||||
"deepseek-coder-v2.description": "DeepSeek Coder V2 ist ein Open-Source-MoE-Code-Modell mit starker Leistung bei Programmieraufgaben, vergleichbar mit GPT-4 Turbo.",
|
||||
"deepseek-coder-v2:236b.description": "DeepSeek Coder V2 ist ein Open-Source-MoE-Code-Modell mit starker Leistung bei Programmieraufgaben, vergleichbar mit GPT-4 Turbo.",
|
||||
@@ -426,7 +425,7 @@
|
||||
"deepseek-r1-fast-online.description": "DeepSeek R1 Schnellversion mit Echtzeit-Websuche – kombiniert 671B-Fähigkeiten mit schneller Reaktion.",
|
||||
"deepseek-r1-online.description": "DeepSeek R1 Vollversion mit 671B Parametern und Echtzeit-Websuche – bietet stärkeres Verständnis und bessere Generierung.",
|
||||
"deepseek-r1.description": "DeepSeek-R1 nutzt Cold-Start-Daten vor dem RL und erreicht vergleichbare Leistungen wie OpenAI-o1 bei Mathematik, Programmierung und logischem Denken.",
|
||||
"deepseek-reasoner.description": "Kompatibilitätsalias für den DeepSeek V4 Flash-Denkmodus. Geplant für die Ausmusterung — verwenden Sie stattdessen DeepSeek V4 Flash.",
|
||||
"deepseek-reasoner.description": "Ein DeepSeek-Logikmodell, das sich auf komplexe logische Denkaufgaben konzentriert.",
|
||||
"deepseek-v2.description": "DeepSeek V2 ist ein effizientes MoE-Modell für kostengünstige Verarbeitung.",
|
||||
"deepseek-v2:236b.description": "DeepSeek V2 236B ist das codefokussierte Modell von DeepSeek mit starker Codegenerierung.",
|
||||
"deepseek-v3-0324.description": "DeepSeek-V3-0324 ist ein MoE-Modell mit 671B Parametern und herausragenden Stärken in Programmierung, technischer Kompetenz, Kontextverständnis und Langtextverarbeitung.",
|
||||
@@ -491,8 +490,6 @@
|
||||
"doubao-seedream-4-0-250828.description": "Seedream 4.0 ist ein Bildgenerierungsmodell von ByteDance Seed, das Text- und Bildeingaben unterstützt und eine hochgradig kontrollierbare, hochwertige Bildgenerierung ermöglicht. Es erzeugt Bilder aus Texteingaben.",
|
||||
"doubao-seedream-4-5-251128.description": "Seedream 4.5 ist das neueste multimodale Bildmodell von ByteDance, das Text-zu-Bild, Bild-zu-Bild und Batch-Bilderzeugung integriert und dabei Allgemeinwissen und logisches Denken einbezieht. Im Vergleich zur vorherigen Version 4.0 bietet es eine deutlich verbesserte Generierungsqualität, bessere Konsistenz bei der Bearbeitung und Multi-Bild-Fusion. Es ermöglicht eine präzisere Kontrolle über visuelle Details, erzeugt kleine Texte und kleine Gesichter natürlicher und erreicht harmonischere Layouts und Farben, wodurch die Gesamtästhetik verbessert wird.",
|
||||
"doubao-seedream-5-0-260128.description": "Doubao-Seedream-5.0-lite ist das neueste Bildgenerierungsmodell von ByteDance. Erstmals integriert es Online-Retrieval-Funktionen, die es ermöglichen, Echtzeit-Webinformationen einzubeziehen und die Aktualität der generierten Bilder zu verbessern. Die Intelligenz des Modells wurde ebenfalls aufgerüstet, um komplexe Anweisungen und visuelle Inhalte präzise zu interpretieren. Darüber hinaus bietet es eine verbesserte globale Wissensabdeckung, Konsistenz bei Referenzen und Generierungsqualität in professionellen Szenarien, um den visuellen Erstellungsbedarf auf Unternehmensebene besser zu erfüllen.",
|
||||
"dreamina-seedance-2-0-260128.description": "Seedance 2.0 von ByteDance ist das leistungsstärkste Videogenerierungsmodell, das multimodale Referenzvideogenerierung, Videobearbeitung, Videoerweiterung, Text-zu-Video und Bild-zu-Video mit synchronisiertem Audio unterstützt.",
|
||||
"dreamina-seedance-2-0-fast-260128.description": "Seedance 2.0 Fast von ByteDance bietet die gleichen Funktionen wie Seedance 2.0 mit schnellerer Generierungsgeschwindigkeit zu einem wettbewerbsfähigeren Preis.",
|
||||
"emohaa.description": "Emohaa ist ein Modell für psychische Gesundheit mit professionellen Beratungsfähigkeiten, das Nutzern hilft, emotionale Probleme zu verstehen.",
|
||||
"ernie-4.5-0.3b.description": "ERNIE 4.5 0.3B ist ein quelloffenes, leichtgewichtiges Modell für lokale und individuell angepasste Bereitstellungen.",
|
||||
"ernie-4.5-8k-preview.description": "ERNIE 4.5 8K Preview ist ein Vorschau-Modell mit 8K Kontextlänge zur Bewertung von ERNIE 4.5.",
|
||||
@@ -506,6 +503,7 @@
|
||||
"ernie-5.0-thinking-latest.description": "Wenxin 5.0 Thinking ist ein natives, vollmodales Flaggschiffmodell mit einheitlicher Modellierung von Text, Bild, Audio und Video. Es bietet umfassende Leistungsverbesserungen für komplexe Frage-Antwort-, Kreativ- und Agenten-Szenarien.",
|
||||
"ernie-5.0-thinking-preview.description": "Wenxin 5.0 Thinking Preview ist ein natives, vollmodales Flaggschiffmodell mit einheitlicher Modellierung von Text, Bild, Audio und Video. Es bietet umfassende Leistungsverbesserungen für komplexe Frage-Antwort-, Kreativ- und Agenten-Szenarien.",
|
||||
"ernie-5.0.description": "ERNIE 5.0, das neue Modell der ERNIE-Serie, ist ein nativ multimodales Großmodell. Es nutzt einen einheitlichen multimodalen Ansatz, um Text, Bilder, Audio und Video gemeinsam zu modellieren und umfassende multimodale Fähigkeiten bereitzustellen. Die Basisfähigkeiten wurden stark verbessert und erzielen hervorragende Ergebnisse in Benchmarks. Besonders stark ist es in multimodalem Verständnis, Befolgen von Anweisungen, kreativem Schreiben, Faktengenauigkeit, agentenbasiertem Planen und Tool-Nutzung.",
|
||||
"ernie-5.1.description": "ERNIE 5.1 ist das neueste Modell der ERNIE-Serie und bietet umfassende Verbesserungen seiner grundlegenden Fähigkeiten. Es zeigt bedeutende Fortschritte in Bereichen wie Agenten, Wissensverarbeitung, logischem Denken und tiefgehender Suche. Diese Version verwendet eine entkoppelte, vollständig asynchrone Verstärkungslernarchitektur, die speziell entwickelt wurde, um zentrale Herausforderungen bei der Weiterentwicklung großer Modelle hin zu autonomer Entscheidungsfindung durch Agenten zu bewältigen, einschließlich numerischer Diskrepanzen zwischen Training und Inferenz, geringer Auslastung heterogener Rechenressourcen und globaler Probleme durch Langschwanz-Effekte. Darüber hinaus werden großskalige Agenten-Nachtrainierungstechniken eingesetzt, um die Fähigkeiten und die Generalisierungsleistung des Modells weiter zu verbessern. Durch ein dreistufiges kollaboratives Framework, das Umgebung, Experten und Fusionsprozesse umfasst, wird nicht nur die Trainingseffizienz sichergestellt, sondern auch die Stabilität und Leistung des Modells bei komplexen Aufgaben erheblich verbessert.",
|
||||
"ernie-char-fiction-8k-preview.description": "ERNIE Character Fiction 8K Preview ist ein Vorschau-Modell zur Charakter- und Plot-Erstellung für Funktionsbewertung und Tests.",
|
||||
"ernie-char-fiction-8k.description": "ERNIE Character Fiction 8K ist ein Persönlichkeitsmodell für Romane und Plot-Erstellung, geeignet für die Generierung von Langform-Geschichten.",
|
||||
"ernie-image-turbo.description": "ERNIE-Image ist ein Text-zu-Bild-Modell mit 8B Parametern von Baidu. Es zählt zu den besten Modellen in mehreren Benchmarks, inklusive Platz 1 (geteilt) bei SuperCLUE in China, und ist führend im Open-Source-Bereich.",
|
||||
@@ -517,8 +515,7 @@
|
||||
"ernie-x1-turbo-32k.description": "ERNIE X1 Turbo 32K ist ein schnelles Denkmodell mit 32K Kontext für komplexe Schlussfolgerungen und mehrstufige Gespräche.",
|
||||
"ernie-x1.1-preview.description": "ERNIE X1.1 Preview ist ein Vorschau-Modell mit Denkfähigkeit zur Bewertung und zum Testen.",
|
||||
"ernie-x1.1.description": "ERNIE X1.1 ist ein Vorschau-Denkmodell für Evaluierung und Tests.",
|
||||
"fal-ai/bytedance/seedream/v4.5.description": "Seedream 4.5, entwickelt vom ByteDance Seed-Team, unterstützt die Bearbeitung und Komposition mehrerer Bilder. Es bietet verbesserte Konsistenz von Motiven, präzise Befolgung von Anweisungen, räumliches Logikverständnis, ästhetischen Ausdruck, Posterlayout und Logodesign mit hochpräziser Text-Bild-Wiedergabe.",
|
||||
"fal-ai/bytedance/seedream/v4.description": "Seedream 4.0, entwickelt von ByteDance Seed, unterstützt Text- und Bildeingaben für hochkontrollierbare, qualitativ hochwertige Bildgenerierung aus Eingabeaufforderungen.",
|
||||
"fal-ai/bytedance/seedream/v4.description": "Seedream 4.0 ist ein Bildgenerierungsmodell von ByteDance Seed, das Text- und Bildinputs unterstützt und hochkontrollierbare, qualitativ hochwertige Bildgenerierung ermöglicht. Es erzeugt Bilder aus Textaufforderungen.",
|
||||
"fal-ai/flux-kontext/dev.description": "FLUX.1-Modell mit Fokus auf Bildbearbeitung, unterstützt Text- und Bildeingaben.",
|
||||
"fal-ai/flux-pro/kontext.description": "FLUX.1 Kontext [pro] akzeptiert Texte und Referenzbilder als Eingabe und ermöglicht gezielte lokale Bearbeitungen sowie komplexe globale Szenentransformationen.",
|
||||
"fal-ai/flux/krea.description": "Flux Krea [dev] ist ein Bildgenerierungsmodell mit ästhetischer Ausrichtung auf realistischere, natürliche Bilder.",
|
||||
@@ -526,8 +523,8 @@
|
||||
"fal-ai/hunyuan-image/v3.description": "Ein leistungsstarkes natives multimodales Bildgenerierungsmodell.",
|
||||
"fal-ai/imagen4/preview.description": "Hochwertiges Bildgenerierungsmodell von Google.",
|
||||
"fal-ai/nano-banana.description": "Nano Banana ist das neueste, schnellste und effizienteste native multimodale Modell von Google. Es ermöglicht Bildgenerierung und -bearbeitung im Dialog.",
|
||||
"fal-ai/qwen-image-edit.description": "Ein professionelles Bildbearbeitungsmodell vom Qwen-Team, das semantische und optische Bearbeitungen, präzise chinesische/englische Textbearbeitung, Stilübertragung, Drehung und mehr unterstützt.",
|
||||
"fal-ai/qwen-image.description": "Ein leistungsstarkes Bildgenerierungsmodell vom Qwen-Team mit starker chinesischer Textrendering-Fähigkeit und vielfältigen visuellen Stilen.",
|
||||
"fal-ai/qwen-image-edit.description": "Ein professionelles Bildbearbeitungsmodell des Qwen-Teams, das semantische und visuelle Bearbeitungen unterstützt, präzise chinesischen und englischen Text bearbeitet und hochwertige Bearbeitungen wie Stilübertragungen und Objektrotationen ermöglicht.",
|
||||
"fal-ai/qwen-image.description": "Ein leistungsstarkes Bildgenerierungsmodell des Qwen-Teams mit beeindruckender chinesischer Textrendering und vielfältigen visuellen Stilen.",
|
||||
"flux-1-schnell.description": "Ein Text-zu-Bild-Modell mit 12 Milliarden Parametern von Black Forest Labs, das latente adversariale Diffusionsdistillation nutzt, um hochwertige Bilder in 1–4 Schritten zu erzeugen. Es konkurriert mit geschlossenen Alternativen und ist unter Apache-2.0 für persönliche, Forschungs- und kommerzielle Nutzung verfügbar.",
|
||||
"flux-dev.description": "Open-Source‑Bildgenerierungsmodell für Forschung und Entwicklung, effizient optimiert für nichtkommerzielle Innovationsforschung.",
|
||||
"flux-kontext-max.description": "Modernste kontextuelle Bildgenerierung und -bearbeitung, kombiniert Text und Bilder für präzise, kohärente Ergebnisse.",
|
||||
@@ -569,7 +566,7 @@
|
||||
"gemini-3-pro-image-preview:image.description": "Gemini 3 Pro Image (Nano Banana Pro) ist Googles Bildgenerierungsmodell und unterstützt auch multimodale Chats.",
|
||||
"gemini-3-pro-preview.description": "Gemini 3 Pro ist Googles leistungsstärkstes Agenten- und Vibe-Coding-Modell. Es bietet reichhaltigere visuelle Inhalte und tiefere Interaktionen auf Basis modernster logischer Fähigkeiten.",
|
||||
"gemini-3.1-flash-image-preview.description": "Gemini 3.1 Flash Image (Nano Banana 2) ist Googles schnellstes natives Bildgenerierungsmodell mit Denkunterstützung, konversationaler Bildgenerierung und -bearbeitung.",
|
||||
"gemini-3.1-flash-image-preview:image.description": "Gemini 3.1 Flash Image (Nano Banana 2) liefert Pro-Level-Bildqualität mit Flash-Geschwindigkeit und unterstützt multimodale Chats.",
|
||||
"gemini-3.1-flash-image-preview:image.description": "Gemini 3.1 Flash Image (Nano Banana 2) ist Googles schnellstes natives Bildgenerierungsmodell mit Unterstützung für Denken, konversationelle Bildgenerierung und -bearbeitung.",
|
||||
"gemini-3.1-flash-lite-preview.description": "Gemini 3.1 Flash-Lite Preview ist Googles kosteneffizientestes multimodales Modell, optimiert für hochvolumige agentische Aufgaben, Übersetzung und Datenverarbeitung.",
|
||||
"gemini-3.1-flash-lite.description": "Gemini 3.1 Flash-Lite ist Googles kosteneffizientestes multimodales Modell, optimiert für hochvolumige agentenbasierte Aufgaben, Übersetzungen und Datenverarbeitung.",
|
||||
"gemini-3.1-pro-preview.description": "Gemini 3.1 Pro Preview verbessert Gemini 3 Pro mit erweiterten Fähigkeiten für logisches Denken und unterstützt mittleres Denklevel.",
|
||||
@@ -734,8 +731,6 @@
|
||||
"grok-4-fast-reasoning.description": "Wir freuen uns, Grok 4 Fast vorzustellen – unser neuester Fortschritt bei kosteneffizienten Denkmodellen.",
|
||||
"grok-4.20-0309-non-reasoning.description": "Eine Non-Reasoning-Variante für einfache Anwendungsfälle.",
|
||||
"grok-4.20-0309-reasoning.description": "Intelligentes, extrem schnelles Modell, das vor der Antwort aktiv denkt.",
|
||||
"grok-4.20-beta-0309-non-reasoning.description": "Eine Variante ohne Denkprozesse für einfache Anwendungsfälle.",
|
||||
"grok-4.20-beta-0309-reasoning.description": "Intelligentes, blitzschnelles Modell, das vor der Antwort überlegt.",
|
||||
"grok-4.20-multi-agent-0309.description": "Ein Team aus 4 oder 16 Agenten, hervorragend für Rechercheaufgaben. Unterstützt derzeit keine clientseitigen Tools. Unterstützt ausschließlich serverseitige xAI-Tools (z. B. X Search, Web Search Tools) und Remote-MCP-Tools.",
|
||||
"grok-4.3.description": "Das wahrheitssuchendste große Sprachmodell der Welt",
|
||||
"grok-4.description": "Das neueste Grok-Flaggschiff mit unvergleichlicher Leistung in Sprache, Mathematik und Logik — ein wahrer Alleskönner. Derzeit verweist es auf grok-4-0709; aufgrund begrenzter Ressourcen ist der Preis vorübergehend 10 % höher als der offizielle Preis und wird voraussichtlich später wieder auf den offiziellen Preis zurückkehren.",
|
||||
@@ -1220,8 +1215,6 @@
|
||||
"qwq.description": "QwQ ist ein Schlussfolgerungsmodell aus der Qwen-Familie. Im Vergleich zu standardmäßig instruktionstunierten Modellen bietet es überlegene Denk- und Schlussfolgerungsfähigkeiten, die die Leistung bei nachgelagerten Aufgaben deutlich verbessern – insbesondere bei schwierigen Problemen. QwQ-32B ist ein mittelgroßes Modell, das mit führenden Schlussfolgerungsmodellen wie DeepSeek-R1 und o1-mini mithalten kann.",
|
||||
"qwq_32b.description": "Mittelgroßes Schlussfolgerungsmodell aus der Qwen-Familie. Im Vergleich zu standardmäßig instruktionstunierten Modellen steigern QwQs Denk- und Schlussfolgerungsfähigkeiten die Leistung bei nachgelagerten Aufgaben deutlich – insbesondere bei schwierigen Problemen.",
|
||||
"r1-1776.description": "R1-1776 ist eine nachtrainierte Variante von DeepSeek R1, die darauf ausgelegt ist, unzensierte, objektive und faktenbasierte Informationen bereitzustellen.",
|
||||
"seedance-1-5-pro-251215.description": "Seedance 1.5 Pro von ByteDance unterstützt Text-zu-Video, Bild-zu-Video (erster Frame, erster+letzter Frame) und Audiogenerierung synchronisiert mit visuellen Inhalten.",
|
||||
"seedream-5-0-260128.description": "ByteDance-Seedream-5.0-lite von BytePlus bietet webgestützte Generierung für Echtzeitinformationen, verbesserte Interpretation komplexer Eingabeaufforderungen und verbesserte Konsistenz von Referenzen für professionelle visuelle Kreationen.",
|
||||
"solar-mini-ja.description": "Solar Mini (Ja) erweitert Solar Mini mit einem Fokus auf Japanisch und behält dabei eine effiziente und starke Leistung in Englisch und Koreanisch bei.",
|
||||
"solar-mini.description": "Solar Mini ist ein kompaktes LLM, das GPT-3.5 übertrifft. Es bietet starke mehrsprachige Fähigkeiten in Englisch und Koreanisch und ist eine effiziente Lösung mit kleinem Ressourcenbedarf.",
|
||||
"solar-pro.description": "Solar Pro ist ein hochintelligentes LLM von Upstage, das auf Befolgen von Anweisungen auf einer einzelnen GPU ausgelegt ist und IFEval-Werte über 80 erreicht. Derzeit wird Englisch unterstützt; die vollständige Veröffentlichung mit erweitertem Sprachsupport und längeren Kontexten war für November 2024 geplant.",
|
||||
|
||||
@@ -27,6 +27,13 @@
|
||||
"agent.layout.skipConfirm.ok": "Für jetzt überspringen",
|
||||
"agent.layout.skipConfirm.title": "Onboarding jetzt überspringen?",
|
||||
"agent.layout.switchMessage": "Heute nicht so in Stimmung? Du kannst zum <modeLink><modeText>{{mode}}</modeText></modeLink> wechseln oder <skipLink><skipText>{{skip}}</skipText></skipLink>.",
|
||||
"agent.layout.switchMessageClassic": "Nicht in der Stimmung heute? Du kannst zu <modeLink><modeText>{{mode}}</modeText></modeLink> wechseln.",
|
||||
"agent.messenger.cta.discord": "Zu Discord hinzufügen",
|
||||
"agent.messenger.cta.slack": "Zu Slack hinzufügen",
|
||||
"agent.messenger.cta.telegram": "In Telegram öffnen",
|
||||
"agent.messenger.subtitle": "Chatte mit deinem Agenten auf Telegram, Slack oder Discord",
|
||||
"agent.messenger.telegramQrCaption": "Mit der Handykamera scannen",
|
||||
"agent.messenger.title": "Nimm mich überall mit, wo du Nachrichten sendest",
|
||||
"agent.modeSwitch.agent": "Konversation",
|
||||
"agent.modeSwitch.classic": "Klassisch",
|
||||
"agent.modeSwitch.collapse": "Einklappen",
|
||||
@@ -68,6 +75,13 @@
|
||||
"agent.wrapUp.confirm.content": "Ich speichere, was wir bisher besprochen haben. Sie können jederzeit zurückkommen und weiter chatten.",
|
||||
"agent.wrapUp.confirm.ok": "Jetzt abschließen",
|
||||
"agent.wrapUp.confirm.title": "Onboarding jetzt abschließen?",
|
||||
"agentPicker.allCategories": "Alle",
|
||||
"agentPicker.continue": "Weiter",
|
||||
"agentPicker.skip": "Jetzt überspringen",
|
||||
"agentPicker.subtitle": "Füge jetzt ein paar zu deiner Bibliothek hinzu – entdecke später jederzeit mehr.",
|
||||
"agentPicker.title": "Lass uns ein paar Agenten zu deiner Bibliothek hinzufügen",
|
||||
"agentPicker.title2": "Wähle die aus, die zu deiner Arbeitsweise passen",
|
||||
"agentPicker.title3": "Du kannst später immer mehr hinzufügen – starte mit ein paar",
|
||||
"back": "Zurück",
|
||||
"finish": "Los geht’s",
|
||||
"interests.area.business": "Geschäft & Strategie",
|
||||
|
||||
@@ -39,8 +39,8 @@
|
||||
"builtins.lobe-agent-documents.inspector.docCount": "{{count}} Dokumente",
|
||||
"builtins.lobe-agent-documents.inspector.opsCount": "{{count}} Vorgänge",
|
||||
"builtins.lobe-agent-documents.inspector.opsResult": "{{success}}/{{total}} Vorgänge",
|
||||
"builtins.lobe-agent-documents.inspector.target.agent": "im Agenten",
|
||||
"builtins.lobe-agent-documents.inspector.target.currentTopic": "im Thema",
|
||||
"builtins.lobe-agent-documents.inspector.scope.agent": "im Agenten",
|
||||
"builtins.lobe-agent-documents.inspector.scope.currentTopic": "im Thema",
|
||||
"builtins.lobe-agent-documents.title": "Agentendokumente",
|
||||
"builtins.lobe-agent-management.apiName.callAgent": "Agent anrufen",
|
||||
"builtins.lobe-agent-management.apiName.createAgent": "Agent erstellen",
|
||||
@@ -90,6 +90,14 @@
|
||||
"builtins.lobe-agent.title": "Lobe-Agent",
|
||||
"builtins.lobe-claude-code.agent.instruction": "Anweisung",
|
||||
"builtins.lobe-claude-code.agent.result": "Ergebnis",
|
||||
"builtins.lobe-claude-code.task.createLabel": "Aufgabe erstellen: ",
|
||||
"builtins.lobe-claude-code.task.getLabel": "Aufgabe #{{taskId}} überprüfen",
|
||||
"builtins.lobe-claude-code.task.listLabel": "Aufgaben auflisten",
|
||||
"builtins.lobe-claude-code.task.updateCompleted": "Abgeschlossen",
|
||||
"builtins.lobe-claude-code.task.updateDeleted": "Gelöscht",
|
||||
"builtins.lobe-claude-code.task.updateInProgress": "Gestartet",
|
||||
"builtins.lobe-claude-code.task.updateLabel": "Aufgabe #{{taskId}} aktualisieren",
|
||||
"builtins.lobe-claude-code.task.updatePending": "Zurücksetzen",
|
||||
"builtins.lobe-claude-code.todoWrite.allDone": "Alle Aufgaben abgeschlossen",
|
||||
"builtins.lobe-claude-code.todoWrite.currentStep": "Aktueller Schritt",
|
||||
"builtins.lobe-claude-code.todoWrite.todos": "Aufgaben",
|
||||
|
||||
@@ -33,7 +33,6 @@
|
||||
"jina.description": "Jina AI wurde 2020 gegründet und ist ein führendes Unternehmen im Bereich Such-KI. Der Such-Stack umfasst Vektormodelle, Reranker und kleine Sprachmodelle für zuverlässige, hochwertige generative und multimodale Suchanwendungen.",
|
||||
"kimicodingplan.description": "Kimi Code von Moonshot AI bietet Zugriff auf Kimi-Modelle, darunter K2.5, für Coding-Aufgaben.",
|
||||
"lmstudio.description": "LM Studio ist eine Desktop-App zur Entwicklung und zum Experimentieren mit LLMs auf dem eigenen Computer.",
|
||||
"lobehub.description": "LobeHub Cloud verwendet offizielle APIs, um auf KI-Modelle zuzugreifen, und misst die Nutzung mit Credits, die an Modell-Token gebunden sind.",
|
||||
"longcat.description": "LongCat ist eine Reihe von generativen KI-Großmodellen, die unabhängig von Meituan entwickelt wurden. Sie sind darauf ausgelegt, die Produktivität innerhalb des Unternehmens zu steigern und innovative Anwendungen durch eine effiziente Rechenarchitektur und starke multimodale Fähigkeiten zu ermöglichen.",
|
||||
"minimax.description": "MiniMax wurde 2021 gegründet und entwickelt allgemeine KI mit multimodalen Foundation-Modellen, darunter Textmodelle mit Billionen Parametern, Sprach- und Bildmodelle sowie Apps wie Hailuo AI.",
|
||||
"minimaxcodingplan.description": "Der MiniMax Token Plan bietet Zugriff auf MiniMax-Modelle, darunter M2.7, für Coding-Aufgaben im Rahmen eines Festpreis-Abonnements.",
|
||||
|
||||
@@ -55,6 +55,12 @@
|
||||
"credits.autoTopUp.toggle": "Automatische Aufladung aktivieren",
|
||||
"credits.autoTopUp.upgradeHint": "Abonnieren Sie einen kostenpflichtigen Plan, um die automatische Aufladung zu aktivieren",
|
||||
"credits.autoTopUp.validation.targetMustExceedThreshold": "Das Zielguthaben muss größer als der Schwellenwert sein",
|
||||
"credits.costEstimateHint.desc": "Zeigen Sie eine leichte Warnung an, bevor Sie senden, wenn die geschätzten Modellkosten Ihren Schwellenwert erreichen",
|
||||
"credits.costEstimateHint.saveError": "Fehler beim Speichern der Einstellungen für die Kostenschätzungswarnung",
|
||||
"credits.costEstimateHint.saveSuccess": "Einstellungen für die Kostenschätzungswarnung gespeichert",
|
||||
"credits.costEstimateHint.threshold": "Warnschwelle",
|
||||
"credits.costEstimateHint.title": "Kostenschätzungswarnung",
|
||||
"credits.costEstimateHint.validation.threshold": "Der Schwellenwert muss größer oder gleich 0 sein",
|
||||
"credits.packages.auto": "Automatisch",
|
||||
"credits.packages.charged": "Berechnet ${{amount}}",
|
||||
"credits.packages.expired": "Abgelaufen",
|
||||
|
||||
@@ -40,6 +40,14 @@
|
||||
"agentMarketplace.render.alreadyInLibraryTag": "Bereits in der Bibliothek",
|
||||
"agentMarketplace.render.alreadyInLibrary_one": "{{count}} bereits in der Bibliothek",
|
||||
"agentMarketplace.render.alreadyInLibrary_other": "{{count}} bereits in der Bibliothek",
|
||||
"claudeCode.askUserQuestion.escape.back": "Zurück zu den Optionen",
|
||||
"claudeCode.askUserQuestion.escape.enter": "Oder direkt eingeben",
|
||||
"claudeCode.askUserQuestion.escape.placeholder": "Geben Sie Ihre Antwort hier ein…",
|
||||
"claudeCode.askUserQuestion.multiSelectTag": "(Mehrfachauswahl)",
|
||||
"claudeCode.askUserQuestion.skip": "Überspringen",
|
||||
"claudeCode.askUserQuestion.submit": "Absenden",
|
||||
"claudeCode.askUserQuestion.timeExpired": "Zeit abgelaufen — Option 1 für jede Frage wird verwendet.",
|
||||
"claudeCode.askUserQuestion.timeRemaining": "Verbleibende Zeit: {{time}} · unbeantwortete Fragen werden bei Ablauf auf Option 1 gesetzt.",
|
||||
"codeInterpreter-legacy.error": "Ausführungsfehler",
|
||||
"codeInterpreter-legacy.executing": "Wird ausgeführt...",
|
||||
"codeInterpreter-legacy.files": "Dateien:",
|
||||
|
||||
@@ -56,6 +56,7 @@
|
||||
"renameModal.title": "Thema umbenennen",
|
||||
"searchPlaceholder": "Themen suchen...",
|
||||
"searchResultEmpty": "Keine Suchergebnisse gefunden.",
|
||||
"sidebar.title": "Themen",
|
||||
"taskManager.agent": "Aufgaben-Agent",
|
||||
"taskManager.welcome": "Frag mich nach deinen Aufgaben",
|
||||
"temp": "Temporär",
|
||||
|
||||
@@ -220,6 +220,13 @@
|
||||
"inbox.title": "Lobe AI",
|
||||
"input.addAi": "Add an AI message",
|
||||
"input.addUser": "Add a user message",
|
||||
"input.costEstimate.creditsPerMillionTokens": "{{credits}} credits/M tokens",
|
||||
"input.costEstimate.hint": "Estimated cost: ~{{credits}} credits",
|
||||
"input.costEstimate.inputLabel": "Input",
|
||||
"input.costEstimate.outputLabel": "Output",
|
||||
"input.costEstimate.settingsLink": "Adjust warning threshold",
|
||||
"input.costEstimate.tokenCount": "~{{tokens}} tokens",
|
||||
"input.costEstimate.tooltip": "Estimated from current context, tools, and model pricing. Actual cost may vary.",
|
||||
"input.disclaimer": "Agents can make mistakes. Use your judgment for critical info.",
|
||||
"input.errorMsg": "Send failed: {{errorMsg}}. Retry, or send again later.",
|
||||
"input.more": "More",
|
||||
@@ -779,6 +786,7 @@
|
||||
"upload.preview.prepareTasks": "Preparing chunks...",
|
||||
"upload.preview.status.pending": "Preparing to upload...",
|
||||
"upload.preview.status.processing": "Processing file...",
|
||||
"upload.validation.unsupportedFileType": "Unsupported file type: {{files}}. Supported images: JPG, PNG, GIF, WebP. Supported documents include PDF, Word, Excel, PowerPoint, Markdown, text, CSV, JSON, and code files.",
|
||||
"upload.validation.videoSizeExceeded": "Video file size must not exceed 20MB. Current file size is {{actualSize}}.",
|
||||
"viewMode.fullWidth": "Full Width",
|
||||
"viewMode.normal": "Standard",
|
||||
|
||||
@@ -121,6 +121,16 @@
|
||||
"ModelSwitchPanel.detail.context": "Context Length",
|
||||
"ModelSwitchPanel.detail.pricing": "Pricing",
|
||||
"ModelSwitchPanel.detail.pricing.cachedInput": "Cached input ${{amount}}/M",
|
||||
"ModelSwitchPanel.detail.pricing.credits.cachedInput": "Cached input {{amount}} credits/M tokens",
|
||||
"ModelSwitchPanel.detail.pricing.credits.image": "credits/img",
|
||||
"ModelSwitchPanel.detail.pricing.credits.input": "Input {{amount}} credits/M tokens",
|
||||
"ModelSwitchPanel.detail.pricing.credits.megapixel": "credits/MP",
|
||||
"ModelSwitchPanel.detail.pricing.credits.millionCharacters": "credits/M chars",
|
||||
"ModelSwitchPanel.detail.pricing.credits.millionTokens": "credits/M tokens",
|
||||
"ModelSwitchPanel.detail.pricing.credits.output": "Output {{amount}} credits/M tokens",
|
||||
"ModelSwitchPanel.detail.pricing.credits.perImage": "~ {{amount}} credits / image",
|
||||
"ModelSwitchPanel.detail.pricing.credits.perVideo": "~ {{amount}} credits / video",
|
||||
"ModelSwitchPanel.detail.pricing.credits.second": "credits/s",
|
||||
"ModelSwitchPanel.detail.pricing.group.audio": "Audio",
|
||||
"ModelSwitchPanel.detail.pricing.group.image": "Image",
|
||||
"ModelSwitchPanel.detail.pricing.group.text": "Text",
|
||||
|
||||
@@ -1,8 +1,6 @@
|
||||
{
|
||||
"addUserMessage.desc": "Add the current input as a user message without triggering generation",
|
||||
"addUserMessage.title": "Add a User Message",
|
||||
"clearCurrentMessages.desc": "Clear the messages and uploaded files from the current conversation",
|
||||
"clearCurrentMessages.title": "Clear Conversation Messages",
|
||||
"commandPalette.desc": "Open the global command palette for quick access to features",
|
||||
"commandPalette.title": "Command Palette",
|
||||
"deleteAndRegenerateMessage.desc": "Delete the last message and regenerate",
|
||||
|
||||
+13
-20
@@ -106,7 +106,6 @@
|
||||
"MiniMax-Hailuo-2.3.description": "Brand-new video generation model with comprehensive upgrades in body motion, physical realism, and instruction following.",
|
||||
"MiniMax-M1.description": "A new in-house reasoning model with 80K chain-of-thought and 1M input, delivering performance comparable to top global models.",
|
||||
"MiniMax-M2-Stable.description": "Built for efficient coding and agent workflows, with higher concurrency for commercial use.",
|
||||
"MiniMax-M2.1-Lightning.description": "Powerful multilingual programming capabilities with faster and more efficient inference.",
|
||||
"MiniMax-M2.1-highspeed.description": "Powerful multilingual programming capabilities, comprehensively upgraded programming experience. Faster and more efficient.",
|
||||
"MiniMax-M2.1.description": "MiniMax-M2.1 is a flagship open-source large model from MiniMax, focusing on solving complex real-world tasks. Its core strengths are multi-language programming capabilities and the ability to solve complex tasks as an Agent.",
|
||||
"MiniMax-M2.5-highspeed.description": "MiniMax M2.5 Highspeed: Same performance as M2.5 with faster inference.",
|
||||
@@ -315,13 +314,13 @@
|
||||
"claude-3-haiku-20240307.description": "Claude 3 Haiku is Anthropic’s fastest and most compact model, designed for near-instant responses with fast, accurate performance.",
|
||||
"claude-3-opus-20240229.description": "Claude 3 Opus is Anthropic’s most powerful model for highly complex tasks, excelling in performance, intelligence, fluency, and comprehension.",
|
||||
"claude-3-sonnet-20240229.description": "Claude 3 Sonnet balances intelligence and speed for enterprise workloads, delivering high utility at lower cost and reliable large-scale deployment.",
|
||||
"claude-haiku-4-5-20251001.description": "Claude Haiku 4.5 is Anthropic's fastest and most intelligent Haiku model, with lightning speed and extended thinking.",
|
||||
"claude-haiku-4-5-20251001.description": "Claude Haiku 4.5 is Anthropic’s fastest and smartest Haiku model, with lightning speed and extended reasoning.",
|
||||
"claude-haiku-4-5.description": "Claude Haiku 4.5 by Anthropic — next-gen Haiku with enhanced reasoning and vision.",
|
||||
"claude-haiku-4.5.description": "Claude Haiku 4.5 is Anthropic’s fastest and smartest Haiku model, with lightning speed and extended reasoning.",
|
||||
"claude-opus-4-1-20250805-thinking.description": "Claude Opus 4.1 Thinking is an advanced variant that can reveal its reasoning process.",
|
||||
"claude-opus-4-1-20250805.description": "Claude Opus 4.1 is Anthropic's latest and most capable model for highly complex tasks, excelling in performance, intelligence, fluency, and understanding.",
|
||||
"claude-opus-4-1-20250805.description": "Claude Opus 4.1 is Anthropic’s latest and most capable model for highly complex tasks, excelling in performance, intelligence, fluency, and understanding.",
|
||||
"claude-opus-4-1.description": "Claude Opus 4.1 by Anthropic — premium reasoning model with deep analysis capabilities.",
|
||||
"claude-opus-4-20250514.description": "Claude Opus 4 is Anthropic's most powerful model for highly complex tasks, excelling in performance, intelligence, fluency, and understanding.",
|
||||
"claude-opus-4-20250514.description": "Claude Opus 4 is Anthropic’s most powerful model for highly complex tasks, excelling in performance, intelligence, fluency, and comprehension.",
|
||||
"claude-opus-4-5-20251101.description": "Claude Opus 4.5 is Anthropic’s flagship model, combining outstanding intelligence with scalable performance, ideal for complex tasks requiring the highest-quality responses and reasoning.",
|
||||
"claude-opus-4-5.description": "Claude Opus 4.5 by Anthropic — flagship model with top-tier reasoning and coding.",
|
||||
"claude-opus-4-6.description": "Claude Opus 4.6 by Anthropic — 1M context window flagship with advanced reasoning.",
|
||||
@@ -330,8 +329,8 @@
|
||||
"claude-opus-4.6-fast.description": "Claude Opus 4.6 is Anthropic’s most intelligent model for building agents and coding.",
|
||||
"claude-opus-4.6.description": "Claude Opus 4.6 is Anthropic’s most intelligent model for building agents and coding.",
|
||||
"claude-sonnet-4-20250514-thinking.description": "Claude Sonnet 4 Thinking can produce near-instant responses or extended step-by-step thinking with visible process.",
|
||||
"claude-sonnet-4-20250514.description": "Claude Sonnet 4 is Anthropic's most intelligent model to date, offering near-instant responses or extended step-by-step thinking with fine-grained control for API users.",
|
||||
"claude-sonnet-4-5-20250929.description": "Claude Sonnet 4.5 is Anthropic's most intelligent model to date.",
|
||||
"claude-sonnet-4-20250514.description": "Claude Sonnet 4 can produce near-instant responses or extended step-by-step thinking with visible process.",
|
||||
"claude-sonnet-4-5-20250929.description": "Claude Sonnet 4.5 is Anthropic’s most intelligent model to date.",
|
||||
"claude-sonnet-4-5.description": "Claude Sonnet 4.5 by Anthropic — improved Sonnet with enhanced coding performance.",
|
||||
"claude-sonnet-4-6.description": "Claude Sonnet 4.6 by Anthropic — latest Sonnet with superior coding and tool use.",
|
||||
"claude-sonnet-4.5.description": "Claude Sonnet 4.5 is Anthropic’s most intelligent model to date.",
|
||||
@@ -404,7 +403,7 @@
|
||||
"deepseek-ai/deepseek-llm-67b-chat.description": "DeepSeek LLM Chat (67B) is an innovative model offering deep language understanding and interaction.",
|
||||
"deepseek-ai/deepseek-v3.1-terminus.description": "DeepSeek V3.1 is a next-gen reasoning model with stronger complex reasoning and chain-of-thought for deep analysis tasks.",
|
||||
"deepseek-ai/deepseek-v3.2.description": "DeepSeek V3.2 is a next-gen reasoning model with stronger complex reasoning and chain-of-thought capabilities.",
|
||||
"deepseek-chat.description": "Compatibility alias for DeepSeek V4 Flash non-thinking mode. Slated for deprecation — use DeepSeek V4 Flash instead.",
|
||||
"deepseek-chat.description": "A new open-source model combining general and code abilities. It preserves the chat model’s general dialogue and the coder model’s strong coding, with better preference alignment. DeepSeek-V2.5 also improves writing and instruction following.",
|
||||
"deepseek-coder-33B-instruct.description": "DeepSeek Coder 33B is a code language model trained on 2T tokens (87% code, 13% Chinese/English text). It introduces a 16K context window and fill-in-the-middle tasks, providing project-level code completion and snippet infilling.",
|
||||
"deepseek-coder-v2.description": "DeepSeek Coder V2 is an open-source MoE code model that performs strongly on coding tasks, comparable to GPT-4 Turbo.",
|
||||
"deepseek-coder-v2:236b.description": "DeepSeek Coder V2 is an open-source MoE code model that performs strongly on coding tasks, comparable to GPT-4 Turbo.",
|
||||
@@ -426,7 +425,7 @@
|
||||
"deepseek-r1-fast-online.description": "DeepSeek R1 fast full version with real-time web search, combining 671B-scale capability and faster response.",
|
||||
"deepseek-r1-online.description": "DeepSeek R1 full version with 671B parameters and real-time web search, offering stronger understanding and generation.",
|
||||
"deepseek-r1.description": "DeepSeek-R1 uses cold-start data before RL and performs comparably to OpenAI-o1 on math, coding, and reasoning.",
|
||||
"deepseek-reasoner.description": "Compatibility alias for DeepSeek V4 Flash thinking mode. Slated for deprecation — use DeepSeek V4 Flash instead.",
|
||||
"deepseek-reasoner.description": "A DeepSeek reasoning model focused on complex logical reasoning tasks.",
|
||||
"deepseek-v2.description": "DeepSeek V2 is an efficient MoE model for cost-effective processing.",
|
||||
"deepseek-v2:236b.description": "DeepSeek V2 236B is DeepSeek’s code-focused model with strong code generation.",
|
||||
"deepseek-v3-0324.description": "DeepSeek-V3-0324 is a 671B-parameter MoE model with standout strengths in programming and technical capability, context understanding, and long-text handling.",
|
||||
@@ -491,8 +490,6 @@
|
||||
"doubao-seedream-4-0-250828.description": "Seedream 4.0 is an image generation model from ByteDance Seed, supporting text and image inputs with highly controllable, high-quality image generation. It generates images from text prompts.",
|
||||
"doubao-seedream-4-5-251128.description": "Seedream 4.5 is ByteDance’s latest multimodal image model, integrating text-to-image, image-to-image, and batch image generation capabilities, while incorporating commonsense and reasoning abilities. Compared to the previous 4.0 version, it delivers significantly improved generation quality, with better editing consistency and multi-image fusion. It offers more precise control over visual details, producing small text and small faces more naturally, and achieves more harmonious layout and color, enhancing overall aesthetics.",
|
||||
"doubao-seedream-5-0-260128.description": "Doubao-Seedream-5.0-lite is ByteDance’s latest image-generation model. For the first time, it integrates online retrieval capabilities, allowing it to incorporate real-time web information and enhance the timeliness of generated images. The model’s intelligence has also been upgraded, enabling precise interpretation of complex instructions and visual content. Additionally, it offers improved global knowledge coverage, reference consistency, and generation quality in professional scenarios, better meeting enterprise-level visual creation needs.",
|
||||
"dreamina-seedance-2-0-260128.description": "Seedance 2.0 by ByteDance is the most powerful video generation model, supporting multimodal reference video generation, video editing, video extension, text-to-video, and image-to-video with synchronized audio.",
|
||||
"dreamina-seedance-2-0-fast-260128.description": "Seedance 2.0 Fast by ByteDance offers the same capabilities as Seedance 2.0 with faster generation speeds at a more competitive price.",
|
||||
"emohaa.description": "Emohaa is a mental health model with professional counseling abilities to help users understand emotional issues.",
|
||||
"ernie-4.5-0.3b.description": "ERNIE 4.5 0.3B is an open-source lightweight model for local and customized deployment.",
|
||||
"ernie-4.5-8k-preview.description": "ERNIE 4.5 8K Preview is an 8K context preview model for evaluating ERNIE 4.5.",
|
||||
@@ -506,6 +503,7 @@
|
||||
"ernie-5.0-thinking-latest.description": "Wenxin 5.0 Thinking is a native full-modal flagship model with unified text, image, audio, and video modeling. It delivers broad capability upgrades for complex QA, creation, and agent scenarios.",
|
||||
"ernie-5.0-thinking-preview.description": "Wenxin 5.0 Thinking Preview is a native full-modal flagship model with unified text, image, audio, and video modeling. It delivers broad capability upgrades for complex QA, creation, and agent scenarios.",
|
||||
"ernie-5.0.description": "ERNIE 5.0, the new-generation model in the ERNIE series, is a natively multimodal large model. It adopts a unified multimodal modeling approach, jointly modeling text, images, audio, and video to deliver comprehensive multimodal capabilities. Its foundational abilities have been significantly upgraded, achieving strong performance on benchmark evaluations. It particularly excels in multimodal understanding, instruction following, creative writing, factual accuracy, agent planning, and tool utilization.",
|
||||
"ernie-5.1.description": "ERNIE 5.1 is the latest model in the ERNIE series, featuring comprehensive upgrades to its foundational capabilities. It demonstrates significant improvements in areas such as agents, knowledge processing, reasoning, and deep search. This release adopts a decoupled fully asynchronous reinforcement learning architecture, specifically designed to address key challenges in the evolution of large models toward autonomous agent decision-making, including training–inference numerical discrepancies, low utilization of heterogeneous computing resources, and global issues caused by long-tail effects. In addition, large-scale agent post-training techniques are employed to further enhance the model’s capabilities and generalization performance. Through a three-stage collaborative framework involving environment, expert, and fusion processes, the approach not only ensures training efficiency but also significantly improves the model’s stability and performance on complex tasks.",
|
||||
"ernie-char-fiction-8k-preview.description": "ERNIE Character Fiction 8K Preview is a character and plot creation model preview for feature evaluation and testing.",
|
||||
"ernie-char-fiction-8k.description": "ERNIE Character Fiction 8K is a persona model for novels and plot creation, suited for long-form story generation.",
|
||||
"ernie-image-turbo.description": "ERNIE-Image is an 8B-parameter text-to-image model developed by Baidu. It ranks among the top on multiple benchmarks, achieving a tied first place in SuperCLUE in China and leading in the open-source track.",
|
||||
@@ -517,8 +515,7 @@
|
||||
"ernie-x1-turbo-32k.description": "ERNIE X1 Turbo 32K is a fast thinking model with 32K context for complex reasoning and multi-turn chat.",
|
||||
"ernie-x1.1-preview.description": "ERNIE X1.1 Preview is a thinking-model preview for evaluation and testing.",
|
||||
"ernie-x1.1.description": "ERNIE X1.1 is a thinking-model preview for evaluation and testing.",
|
||||
"fal-ai/bytedance/seedream/v4.5.description": "Seedream 4.5, built by ByteDance Seed team, supports multi-image editing and composition. Features enhanced subject consistency, precise instruction following, spatial logic understanding, aesthetic expression, poster layout and logo design with high-precision text-image rendering.",
|
||||
"fal-ai/bytedance/seedream/v4.description": "Seedream 4.0, built by ByteDance Seed, supports text and image inputs for highly controllable, high-quality image generation from prompts.",
|
||||
"fal-ai/bytedance/seedream/v4.description": "Seedream 4.0 is an image generation model from ByteDance Seed, supporting text and image inputs with highly controllable, high-quality image generation. It generates images from text prompts.",
|
||||
"fal-ai/flux-kontext/dev.description": "FLUX.1 model focused on image editing, supporting text and image inputs.",
|
||||
"fal-ai/flux-pro/kontext.description": "FLUX.1 Kontext [pro] accepts text and reference images as input, enabling targeted local edits and complex global scene transformations.",
|
||||
"fal-ai/flux/krea.description": "Flux Krea [dev] is an image generation model with an aesthetic bias toward more realistic, natural images.",
|
||||
@@ -526,8 +523,8 @@
|
||||
"fal-ai/hunyuan-image/v3.description": "A powerful native multimodal image generation model.",
|
||||
"fal-ai/imagen4/preview.description": "High-quality image generation model from Google.",
|
||||
"fal-ai/nano-banana.description": "Nano Banana is Google’s newest, fastest, and most efficient native multimodal model, enabling image generation and editing through conversation.",
|
||||
"fal-ai/qwen-image-edit.description": "A professional image editing model from the Qwen team, supporting semantic and appearance edits, precise Chinese/English text editing, style transfer, rotation, and more.",
|
||||
"fal-ai/qwen-image.description": "A powerful image generation model from the Qwen team with strong Chinese text rendering and diverse visual styles.",
|
||||
"fal-ai/qwen-image-edit.description": "A professional image editing model from the Qwen team that supports semantic and appearance edits, precisely edits Chinese and English text, and enables high-quality edits such as style transfer and object rotation.",
|
||||
"fal-ai/qwen-image.description": "A powerful image generation model from the Qwen team with impressive Chinese text rendering and diverse visual styles.",
|
||||
"flux-1-schnell.description": "A 12B-parameter text-to-image model from Black Forest Labs using latent adversarial diffusion distillation to generate high-quality images in 1-4 steps. It rivals closed alternatives and is released under Apache-2.0 for personal, research, and commercial use.",
|
||||
"flux-dev.description": "Open-source R&D image generation model, efficiently optimized for non-commercial innovation research.",
|
||||
"flux-kontext-max.description": "State-of-the-art contextual image generation and editing, combining text and images for precise, coherent results.",
|
||||
@@ -566,10 +563,10 @@
|
||||
"gemini-3-flash-preview.description": "Gemini 3 Flash is the smartest model built for speed, combining cutting-edge intelligence with excellent search grounding.",
|
||||
"gemini-3-flash.description": "Gemini 3 Flash by Google — ultra-fast model with multimodal input support.",
|
||||
"gemini-3-pro-image-preview.description": "Gemini 3 Pro Image (Nano Banana Pro) is Google's image generation model that also supports multimodal dialogue.",
|
||||
"gemini-3-pro-image-preview:image.description": "Gemini 3 Pro Image (Nano Banana Pro) is Google's image generation model and also supports multimodal chat.",
|
||||
"gemini-3-pro-image-preview:image.description": "Gemini 3 Pro Image (Nano Banana Pro) is Google’s image generation model and also supports multimodal chat.",
|
||||
"gemini-3-pro-preview.description": "Gemini 3 Pro is Google’s most powerful agent and vibe-coding model, delivering richer visuals and deeper interaction on top of state-of-the-art reasoning.",
|
||||
"gemini-3.1-flash-image-preview.description": "Gemini 3.1 Flash Image (Nano Banana 2) is Google's fastest native image generation model with thinking support, conversational image generation and editing.",
|
||||
"gemini-3.1-flash-image-preview:image.description": "Gemini 3.1 Flash Image (Nano Banana 2) delivers Pro-level image quality at Flash speed with multimodal chat support.",
|
||||
"gemini-3.1-flash-image-preview:image.description": "Gemini 3.1 Flash Image (Nano Banana 2) is Google's fastest native image generation model with thinking support, conversational image generation and editing.",
|
||||
"gemini-3.1-flash-lite-preview.description": "Gemini 3.1 Flash-Lite Preview is Google's most cost-efficient multimodal model, optimized for high-volume agentic tasks, translation, and data processing.",
|
||||
"gemini-3.1-flash-lite.description": "Gemini 3.1 Flash-Lite is Google's most cost-efficient multimodal model, optimized for high-volume agentic tasks, translation, and data processing.",
|
||||
"gemini-3.1-pro-preview.description": "Gemini 3.1 Pro Preview improves on Gemini 3 Pro with enhanced reasoning capabilities and adds medium thinking level support.",
|
||||
@@ -734,8 +731,6 @@
|
||||
"grok-4-fast-reasoning.description": "We’re excited to release Grok 4 Fast, our latest progress in cost-effective reasoning models.",
|
||||
"grok-4.20-0309-non-reasoning.description": "A non-reasoning variant for simple use cases",
|
||||
"grok-4.20-0309-reasoning.description": "Intelligent, blazing-fast model that reasons before responding",
|
||||
"grok-4.20-beta-0309-non-reasoning.description": "A non-reasoning variant for simple use cases",
|
||||
"grok-4.20-beta-0309-reasoning.description": "Intelligent, blazing-fast model that reasons before responding",
|
||||
"grok-4.20-multi-agent-0309.description": "A team of 4 or 16 agents, Excels at research use cases, Does not currently support client-side tools. Only supports xAI server side tools (eg X Search, Web Search tools) and remote MCP tools.",
|
||||
"grok-4.3.description": "The most truth-seeking large language model in the world",
|
||||
"grok-4.description": "Latest Grok flagship with unmatched performance in language, math, and reasoning — a true all-rounder. Currently points to grok-4-0709; due to limited resources it is temporarily 10% higher than official pricing and is expected to return to official price later.",
|
||||
@@ -1220,8 +1215,6 @@
|
||||
"qwq.description": "QwQ is a reasoning model in the Qwen family. Compared with standard instruction-tuned models, it brings thinking and reasoning abilities that significantly improve downstream performance, especially on hard problems. QwQ-32B is a mid-sized reasoning model that competes well with top reasoning models like DeepSeek-R1 and o1-mini.",
|
||||
"qwq_32b.description": "Mid-sized reasoning model in the Qwen family. Compared with standard instruction-tuned models, QwQ’s thinking and reasoning abilities significantly boost downstream performance, especially on hard problems.",
|
||||
"r1-1776.description": "R1-1776 is a post-trained variant of DeepSeek R1 designed to provide uncensored, unbiased factual information.",
|
||||
"seedance-1-5-pro-251215.description": "Seedance 1.5 Pro by ByteDance supports text-to-video, image-to-video (first frame, first+last frame), and audio generation synchronized with visuals.",
|
||||
"seedream-5-0-260128.description": "ByteDance-Seedream-5.0-lite by BytePlus features web-retrieval-augmented generation for real-time information, enhanced complex prompt interpretation, and improved reference consistency for professional visual creation.",
|
||||
"solar-mini-ja.description": "Solar Mini (Ja) extends Solar Mini with a focus on Japanese while maintaining efficient, strong performance in English and Korean.",
|
||||
"solar-mini.description": "Solar Mini is a compact LLM that outperforms GPT-3.5, with strong multilingual capability supporting English and Korean, offering an efficient small-footprint solution.",
|
||||
"solar-pro.description": "Solar Pro is a high-intelligence LLM from Upstage, focused on instruction following on a single GPU, with IFEval scores above 80. It currently supports English; the full release was planned for November 2024 with expanded language support and longer context.",
|
||||
|
||||
@@ -28,6 +28,12 @@
|
||||
"agent.layout.skipConfirm.title": "Skip onboarding for now?",
|
||||
"agent.layout.switchMessage": "Not feeling it today? You can switch to <modeLink><modeText>{{mode}}</modeText></modeLink> or <skipLink><skipText>{{skip}}</skipText></skipLink>.",
|
||||
"agent.layout.switchMessageClassic": "Not feeling it today? You can switch to <modeLink><modeText>{{mode}}</modeText></modeLink>.",
|
||||
"agent.messenger.cta.discord": "Add to Discord",
|
||||
"agent.messenger.cta.slack": "Add to Slack",
|
||||
"agent.messenger.cta.telegram": "Open in Telegram",
|
||||
"agent.messenger.subtitle": "Chat with your agent on Telegram, Slack, or Discord",
|
||||
"agent.messenger.telegramQrCaption": "Scan with your phone camera",
|
||||
"agent.messenger.title": "Keep me with you, wherever you message",
|
||||
"agent.modeSwitch.agent": "Conversational",
|
||||
"agent.modeSwitch.classic": "Classic",
|
||||
"agent.modeSwitch.collapse": "Collapse",
|
||||
|
||||
@@ -39,8 +39,8 @@
|
||||
"builtins.lobe-agent-documents.inspector.docCount": "{{count}} docs",
|
||||
"builtins.lobe-agent-documents.inspector.opsCount": "{{count}} ops",
|
||||
"builtins.lobe-agent-documents.inspector.opsResult": "{{success}}/{{total}} ops",
|
||||
"builtins.lobe-agent-documents.inspector.target.agent": "in agent",
|
||||
"builtins.lobe-agent-documents.inspector.target.currentTopic": "in topic",
|
||||
"builtins.lobe-agent-documents.inspector.scope.agent": "in agent",
|
||||
"builtins.lobe-agent-documents.inspector.scope.currentTopic": "in topic",
|
||||
"builtins.lobe-agent-documents.title": "Agent Documents",
|
||||
"builtins.lobe-agent-management.apiName.callAgent": "Call agent",
|
||||
"builtins.lobe-agent-management.apiName.createAgent": "Create agent",
|
||||
|
||||
@@ -33,7 +33,6 @@
|
||||
"jina.description": "Founded in 2020, Jina AI is a leading search AI company. Its search stack includes vector models, rerankers, and small language models to build reliable, high-quality generative and multimodal search apps.",
|
||||
"kimicodingplan.description": "Kimi Code from Moonshot AI provides access to Kimi models including K2.5 for coding tasks.",
|
||||
"lmstudio.description": "LM Studio is a desktop app for developing and experimenting with LLMs on your computer.",
|
||||
"lobehub.description": "LobeHub Cloud uses official APIs to access AI models and measures usage with Credits tied to model tokens.",
|
||||
"longcat.description": "LongCat is a series of generative AI large models independently developed by Meituan. It is designed to enhance internal enterprise productivity and enable innovative applications through an efficient computational architecture and strong multimodal capabilities.",
|
||||
"minimax.description": "Founded in 2021, MiniMax builds general-purpose AI with multimodal foundation models, including trillion-parameter MoE text models, speech models, and vision models, along with apps like Hailuo AI.",
|
||||
"minimaxcodingplan.description": "MiniMax Token Plan provides access to MiniMax models including M2.7 for coding tasks via a fixed-fee subscription.",
|
||||
|
||||
@@ -55,6 +55,12 @@
|
||||
"credits.autoTopUp.toggle": "Enable Auto Top-Up",
|
||||
"credits.autoTopUp.upgradeHint": "Subscribe to a paid plan to enable auto top-up",
|
||||
"credits.autoTopUp.validation.targetMustExceedThreshold": "Target balance must be greater than threshold",
|
||||
"credits.costEstimateHint.desc": "Show a lightweight warning before sending when the estimated model cost reaches your threshold",
|
||||
"credits.costEstimateHint.saveError": "Failed to save cost estimate alert settings",
|
||||
"credits.costEstimateHint.saveSuccess": "Cost estimate alert settings saved",
|
||||
"credits.costEstimateHint.threshold": "Warning Threshold",
|
||||
"credits.costEstimateHint.title": "Cost Estimate Alert",
|
||||
"credits.costEstimateHint.validation.threshold": "Threshold must be greater than or equal to 0",
|
||||
"credits.packages.auto": "Auto",
|
||||
"credits.packages.charged": "Charged ${{amount}}",
|
||||
"credits.packages.expired": "Expired",
|
||||
|
||||
@@ -220,6 +220,13 @@
|
||||
"inbox.title": "Lobe AI",
|
||||
"input.addAi": "Agregar mensaje de IA",
|
||||
"input.addUser": "Agregar mensaje de usuario",
|
||||
"input.costEstimate.creditsPerMillionTokens": "{{credits}} créditos/M tokens",
|
||||
"input.costEstimate.hint": "Costo estimado: ~{{credits}} créditos",
|
||||
"input.costEstimate.inputLabel": "Entrada",
|
||||
"input.costEstimate.outputLabel": "Salida",
|
||||
"input.costEstimate.settingsLink": "Ajustar umbral de advertencia",
|
||||
"input.costEstimate.tokenCount": "~{{tokens}} tokens",
|
||||
"input.costEstimate.tooltip": "Estimado a partir del contexto actual, herramientas y precios del modelo. El costo real puede variar.",
|
||||
"input.disclaimer": "Los agentes pueden cometer errores. Usa tu criterio para información crítica.",
|
||||
"input.errorMsg": "Error al enviar: {{errorMsg}}. Intenta de nuevo más tarde.",
|
||||
"input.more": "Más",
|
||||
@@ -779,6 +786,7 @@
|
||||
"upload.preview.prepareTasks": "Preparando fragmentos...",
|
||||
"upload.preview.status.pending": "Preparando para subir...",
|
||||
"upload.preview.status.processing": "Procesando archivo...",
|
||||
"upload.validation.unsupportedFileType": "Tipo de archivo no compatible: {{files}}. Imágenes compatibles: JPG, PNG, GIF, WebP. Documentos compatibles incluyen PDF, Word, Excel, PowerPoint, Markdown, texto, CSV, JSON y archivos de código.",
|
||||
"upload.validation.videoSizeExceeded": "El tamaño del archivo de video no debe superar los 20MB. Tamaño actual: {{actualSize}}.",
|
||||
"viewMode.fullWidth": "Ancho completo",
|
||||
"viewMode.normal": "Estándar",
|
||||
@@ -894,6 +902,8 @@
|
||||
"workingPanel.localFile.closeOther": "Cerrar Otros",
|
||||
"workingPanel.localFile.closeRight": "Cerrar a la Derecha",
|
||||
"workingPanel.localFile.error": "No se pudo cargar este archivo",
|
||||
"workingPanel.localFile.preview.raw": "Sin procesar",
|
||||
"workingPanel.localFile.preview.render": "Vista previa",
|
||||
"workingPanel.localFile.truncated": "Vista previa del archivo truncada a {{limit}} caracteres",
|
||||
"workingPanel.progress": "Progress",
|
||||
"workingPanel.progress.allCompleted": "All tasks completed",
|
||||
@@ -959,6 +969,8 @@
|
||||
"workingPanel.review.viewMode.unified": "Cambiar a vista unificada",
|
||||
"workingPanel.review.wordWrap.disable": "Desactivar ajuste de línea",
|
||||
"workingPanel.review.wordWrap.enable": "Activar ajuste de línea",
|
||||
"workingPanel.skills.empty": "No se encontraron habilidades en este proyecto",
|
||||
"workingPanel.skills.title": "Habilidades",
|
||||
"workingPanel.space": "Espacio",
|
||||
"workingPanel.title": "Working Panel",
|
||||
"you": "Tú",
|
||||
|
||||
@@ -121,6 +121,16 @@
|
||||
"ModelSwitchPanel.detail.context": "Longitud del contexto",
|
||||
"ModelSwitchPanel.detail.pricing": "Precios",
|
||||
"ModelSwitchPanel.detail.pricing.cachedInput": "Entrada en caché ${{amount}}/M",
|
||||
"ModelSwitchPanel.detail.pricing.credits.cachedInput": "Entrada en caché {{amount}} créditos/M tokens",
|
||||
"ModelSwitchPanel.detail.pricing.credits.image": "créditos/img",
|
||||
"ModelSwitchPanel.detail.pricing.credits.input": "Entrada {{amount}} créditos/M tokens",
|
||||
"ModelSwitchPanel.detail.pricing.credits.megapixel": "créditos/MP",
|
||||
"ModelSwitchPanel.detail.pricing.credits.millionCharacters": "créditos/M caracteres",
|
||||
"ModelSwitchPanel.detail.pricing.credits.millionTokens": "créditos/M tokens",
|
||||
"ModelSwitchPanel.detail.pricing.credits.output": "Salida {{amount}} créditos/M tokens",
|
||||
"ModelSwitchPanel.detail.pricing.credits.perImage": "~ {{amount}} créditos / imagen",
|
||||
"ModelSwitchPanel.detail.pricing.credits.perVideo": "~ {{amount}} créditos / video",
|
||||
"ModelSwitchPanel.detail.pricing.credits.second": "créditos/s",
|
||||
"ModelSwitchPanel.detail.pricing.group.audio": "Audio",
|
||||
"ModelSwitchPanel.detail.pricing.group.image": "Imagen",
|
||||
"ModelSwitchPanel.detail.pricing.group.text": "Texto",
|
||||
|
||||
@@ -1,8 +1,10 @@
|
||||
{
|
||||
"actionTag.category.command": "Comando",
|
||||
"actionTag.category.projectSkill": "Habilidad del proyecto",
|
||||
"actionTag.category.skill": "Habilidad",
|
||||
"actionTag.category.tool": "Herramienta",
|
||||
"actionTag.tooltip.command": "Ejecuta un comando de barra en el cliente antes de enviar.",
|
||||
"actionTag.tooltip.projectSkill": "Enviado como una invocación de barra diagonal para que la CLI del agente ejecute la habilidad del proyecto correspondiente.",
|
||||
"actionTag.tooltip.skill": "Carga un paquete de habilidades reutilizable para esta solicitud.",
|
||||
"actionTag.tooltip.tool": "Marca una herramienta que el usuario seleccionó explícitamente para esta solicitud.",
|
||||
"actions.expand.off": "Colapsar",
|
||||
|
||||
@@ -11,6 +11,19 @@
|
||||
"brief.action.ignore": "Ignorar",
|
||||
"brief.action.retry": "Reintentar",
|
||||
"brief.addFeedback": "Compartir comentarios",
|
||||
"brief.agentSignal.selfReview.applied.heading": "Actualizado",
|
||||
"brief.agentSignal.selfReview.applied.summary": "Se aplicó {{count}} actualización de sueño.",
|
||||
"brief.agentSignal.selfReview.applied.summary_plural": "Se aplicaron {{count}} actualizaciones de sueño.",
|
||||
"brief.agentSignal.selfReview.applied.title": "Recursos de sueño actualizados",
|
||||
"brief.agentSignal.selfReview.error.heading": "Problema",
|
||||
"brief.agentSignal.selfReview.error.summary": "Algunos trabajos no pudieron completarse durante este sueño.",
|
||||
"brief.agentSignal.selfReview.error.title": "El sueño encontró un problema",
|
||||
"brief.agentSignal.selfReview.ideas.summary": "Notas de sueño guardadas para revisión futura.",
|
||||
"brief.agentSignal.selfReview.ideas.title": "Notas de sueño",
|
||||
"brief.agentSignal.selfReview.proposal.heading": "Sugerencia",
|
||||
"brief.agentSignal.selfReview.proposal.summary": "{{count}} sugerencia de sueño necesita tu revisión.",
|
||||
"brief.agentSignal.selfReview.proposal.summary_plural": "{{count}} sugerencias de sueño necesitan tu revisión.",
|
||||
"brief.agentSignal.selfReview.proposal.title": "Sugerencia de sueño necesita revisión",
|
||||
"brief.collapse": "Mostrar menos",
|
||||
"brief.commentPlaceholder": "Comparte tus comentarios...",
|
||||
"brief.commentSubmit": "Enviar comentarios",
|
||||
|
||||
@@ -1,8 +1,6 @@
|
||||
{
|
||||
"addUserMessage.desc": "Agregar la entrada actual como un mensaje de usuario sin activar la generación",
|
||||
"addUserMessage.title": "Agregar un mensaje de usuario",
|
||||
"clearCurrentMessages.desc": "Borrar los mensajes y archivos subidos de la conversación actual",
|
||||
"clearCurrentMessages.title": "Borrar mensajes de la conversación",
|
||||
"commandPalette.desc": "Abrir el panel de comandos global para acceder rápidamente a las funciones",
|
||||
"commandPalette.title": "Panel de comandos",
|
||||
"deleteAndRegenerateMessage.desc": "Eliminar el último mensaje y regenerarlo",
|
||||
|
||||
+11
-18
@@ -106,7 +106,6 @@
|
||||
"MiniMax-Hailuo-2.3.description": "Nuevo modelo de generación de video con mejoras integrales en movimiento corporal, realismo físico y seguimiento de instrucciones.",
|
||||
"MiniMax-M1.description": "Nuevo modelo de razonamiento interno con 80K de cadena de pensamiento y 1M de entrada, con rendimiento comparable a los mejores modelos globales.",
|
||||
"MiniMax-M2-Stable.description": "Diseñado para codificación eficiente y flujos de trabajo de agentes, con mayor concurrencia para uso comercial.",
|
||||
"MiniMax-M2.1-Lightning.description": "Potentes capacidades de programación multilingüe con inferencia más rápida y eficiente.",
|
||||
"MiniMax-M2.1-highspeed.description": "Potentes capacidades de programación multilingüe, con una experiencia de programación completamente mejorada. Más rápido y eficiente.",
|
||||
"MiniMax-M2.1.description": "MiniMax-M2.1 es un modelo insignia de código abierto de MiniMax, enfocado en resolver tareas complejas del mundo real. Sus principales fortalezas son sus capacidades de programación multilingüe y su habilidad para resolver tareas complejas como un Agente.",
|
||||
"MiniMax-M2.5-highspeed.description": "MiniMax M2.5 Highspeed: Mismo rendimiento que M2.5 con inferencia más rápida.",
|
||||
@@ -315,13 +314,13 @@
|
||||
"claude-3-haiku-20240307.description": "Claude 3 Haiku es el modelo más rápido y compacto de Anthropic, diseñado para respuestas casi instantáneas con rendimiento rápido y preciso.",
|
||||
"claude-3-opus-20240229.description": "Claude 3 Opus es el modelo más potente de Anthropic para tareas altamente complejas, destacando en rendimiento, inteligencia, fluidez y comprensión.",
|
||||
"claude-3-sonnet-20240229.description": "Claude 3 Sonnet equilibra inteligencia y velocidad para cargas de trabajo empresariales, ofreciendo alta utilidad a menor costo y despliegue confiable a gran escala.",
|
||||
"claude-haiku-4-5-20251001.description": "Claude Haiku 4.5 es el modelo Haiku más rápido e inteligente de Anthropic, con velocidad relámpago y pensamiento extendido.",
|
||||
"claude-haiku-4-5-20251001.description": "Claude Haiku 4.5 es el modelo Haiku más rápido e inteligente de Anthropic, con velocidad relámpago y razonamiento extendido.",
|
||||
"claude-haiku-4-5.description": "Claude Haiku 4.5 de Anthropic: Haiku de nueva generación con razonamiento y visión mejorados.",
|
||||
"claude-haiku-4.5.description": "Claude Haiku 4.5 es el modelo Haiku más rápido e inteligente de Anthropic, con velocidad relámpago y razonamiento extendido.",
|
||||
"claude-opus-4-1-20250805-thinking.description": "Claude Opus 4.1 Thinking es una variante avanzada que puede mostrar su proceso de razonamiento.",
|
||||
"claude-opus-4-1-20250805.description": "Claude Opus 4.1 es el modelo más reciente y avanzado de Anthropic para tareas altamente complejas, destacando en rendimiento, inteligencia, fluidez y comprensión.",
|
||||
"claude-opus-4-1-20250805.description": "Claude Opus 4.1 es el modelo más reciente y capaz de Anthropic para tareas altamente complejas, destacando en rendimiento, inteligencia, fluidez y comprensión.",
|
||||
"claude-opus-4-1.description": "Claude Opus 4.1 de Anthropic: modelo de razonamiento premium con profundas capacidades de análisis.",
|
||||
"claude-opus-4-20250514.description": "Claude Opus 4 es el modelo más poderoso de Anthropic para tareas altamente complejas, destacando en rendimiento, inteligencia, fluidez y comprensión.",
|
||||
"claude-opus-4-20250514.description": "Claude Opus 4 es el modelo más poderoso de Anthropic para tareas altamente complejas, sobresaliendo en rendimiento, inteligencia, fluidez y comprensión.",
|
||||
"claude-opus-4-5-20251101.description": "Claude Opus 4.5 es el modelo insignia de Anthropic, combinando inteligencia excepcional con rendimiento escalable, ideal para tareas complejas que requieren respuestas y razonamiento de la más alta calidad.",
|
||||
"claude-opus-4-5.description": "Claude Opus 4.5 de Anthropic: modelo insignia con razonamiento y programación de primer nivel.",
|
||||
"claude-opus-4-6.description": "Claude Opus 4.6 de Anthropic: modelo insignia con ventana de contexto de 1M y razonamiento avanzado.",
|
||||
@@ -330,7 +329,7 @@
|
||||
"claude-opus-4.6-fast.description": "Claude Opus 4.6 es el modelo más inteligente de Anthropic para construir agentes y programar.",
|
||||
"claude-opus-4.6.description": "Claude Opus 4.6 es el modelo más inteligente de Anthropic para construir agentes y programar.",
|
||||
"claude-sonnet-4-20250514-thinking.description": "Claude Sonnet 4 Thinking puede generar respuestas casi instantáneas o pensamiento paso a paso extendido con proceso visible.",
|
||||
"claude-sonnet-4-20250514.description": "Claude Sonnet 4 es el modelo más inteligente de Anthropic hasta la fecha, ofreciendo respuestas casi instantáneas o pensamiento paso a paso extendido con control detallado para usuarios de API.",
|
||||
"claude-sonnet-4-20250514.description": "Claude Sonnet 4 puede generar respuestas casi instantáneas o razonamientos detallados paso a paso con un proceso visible.",
|
||||
"claude-sonnet-4-5-20250929.description": "Claude Sonnet 4.5 es el modelo más inteligente de Anthropic hasta la fecha.",
|
||||
"claude-sonnet-4-5.description": "Claude Sonnet 4.5 de Anthropic: versión mejorada de Sonnet con mayor rendimiento en programación.",
|
||||
"claude-sonnet-4-6.description": "Claude Sonnet 4.6 de Anthropic: última versión de Sonnet con programación superior y uso avanzado de herramientas.",
|
||||
@@ -404,7 +403,7 @@
|
||||
"deepseek-ai/deepseek-llm-67b-chat.description": "DeepSeek LLM Chat (67B) es un modelo innovador que ofrece una comprensión profunda del lenguaje y una interacción avanzada.",
|
||||
"deepseek-ai/deepseek-v3.1-terminus.description": "DeepSeek V3.1 es un modelo de razonamiento de nueva generación con capacidades mejoradas para razonamiento complejo y cadenas de pensamiento, ideal para tareas de análisis profundo.",
|
||||
"deepseek-ai/deepseek-v3.2.description": "DeepSeek V3.2 es un modelo de razonamiento de próxima generación con capacidades mejoradas de razonamiento complejo y cadenas de pensamiento.",
|
||||
"deepseek-chat.description": "Alias de compatibilidad para el modo sin razonamiento de DeepSeek V4 Flash. Programado para ser descontinuado: utiliza DeepSeek V4 Flash en su lugar.",
|
||||
"deepseek-chat.description": "Un nuevo modelo de código abierto que combina habilidades generales y de codificación. Preserva el diálogo general del modelo de chat y la sólida capacidad de codificación del modelo de programador, con una mejor alineación de preferencias. DeepSeek-V2.5 también mejora la escritura y el seguimiento de instrucciones.",
|
||||
"deepseek-coder-33B-instruct.description": "DeepSeek Coder 33B es un modelo de lenguaje para código entrenado con 2T de tokens (87% código, 13% texto en chino/inglés). Introduce una ventana de contexto de 16K y tareas de completado intermedio, ofreciendo completado de código a nivel de proyecto y relleno de fragmentos.",
|
||||
"deepseek-coder-v2.description": "DeepSeek Coder V2 es un modelo de código MoE de código abierto que tiene un rendimiento sólido en tareas de programación, comparable a GPT-4 Turbo.",
|
||||
"deepseek-coder-v2:236b.description": "DeepSeek Coder V2 es un modelo de código MoE de código abierto que tiene un rendimiento sólido en tareas de programación, comparable a GPT-4 Turbo.",
|
||||
@@ -426,7 +425,7 @@
|
||||
"deepseek-r1-fast-online.description": "Versión completa rápida de DeepSeek R1 con búsqueda web en tiempo real, combinando capacidad a escala 671B y respuesta ágil.",
|
||||
"deepseek-r1-online.description": "Versión completa de DeepSeek R1 con 671B de parámetros y búsqueda web en tiempo real, ofreciendo mejor comprensión y generación.",
|
||||
"deepseek-r1.description": "DeepSeek-R1 utiliza datos de arranque en frío antes del aprendizaje por refuerzo y tiene un rendimiento comparable a OpenAI-o1 en matemáticas, programación y razonamiento.",
|
||||
"deepseek-reasoner.description": "Alias de compatibilidad para el modo de razonamiento de DeepSeek V4 Flash. Programado para ser descontinuado: utiliza DeepSeek V4 Flash en su lugar.",
|
||||
"deepseek-reasoner.description": "Un modelo de razonamiento DeepSeek enfocado en tareas de razonamiento lógico complejo.",
|
||||
"deepseek-v2.description": "DeepSeek V2 es un modelo MoE eficiente para procesamiento rentable.",
|
||||
"deepseek-v2:236b.description": "DeepSeek V2 236B es el modelo de DeepSeek centrado en código con fuerte generación de código.",
|
||||
"deepseek-v3-0324.description": "DeepSeek-V3-0324 es un modelo MoE con 671 mil millones de parámetros, con fortalezas destacadas en programación, capacidad técnica, comprensión de contexto y manejo de textos largos.",
|
||||
@@ -491,8 +490,6 @@
|
||||
"doubao-seedream-4-0-250828.description": "Seedream 4.0 es un modelo de generación de imágenes de ByteDance Seed que admite entradas de texto e imagen con generación de imágenes de alta calidad y altamente controlable. Genera imágenes a partir de indicaciones de texto.",
|
||||
"doubao-seedream-4-5-251128.description": "Seedream 4.5 es el último modelo multimodal de imágenes de ByteDance, que integra capacidades de texto a imagen, imagen a imagen y generación de imágenes por lotes, mientras incorpora sentido común y habilidades de razonamiento. En comparación con la versión 4.0 anterior, ofrece una calidad de generación significativamente mejorada, con mayor consistencia en la edición y fusión de múltiples imágenes. Proporciona un control más preciso sobre los detalles visuales, produciendo texto y rostros pequeños de manera más natural, y logra una disposición y color más armoniosos, mejorando la estética general.",
|
||||
"doubao-seedream-5-0-260128.description": "Doubao-Seedream-5.0-lite es el último modelo de generación de imágenes de ByteDance. Por primera vez, integra capacidades de recuperación en línea, permitiendo incorporar información web en tiempo real y mejorar la actualidad de las imágenes generadas. La inteligencia del modelo también ha sido mejorada, permitiendo una interpretación precisa de instrucciones complejas y contenido visual. Además, ofrece una mejor cobertura de conocimiento global, consistencia de referencia y calidad de generación en escenarios profesionales, satisfaciendo mejor las necesidades de creación visual a nivel empresarial.",
|
||||
"dreamina-seedance-2-0-260128.description": "Seedance 2.0 de ByteDance es el modelo de generación de video más poderoso, compatible con generación de video multimodal de referencia, edición de video, extensión de video, texto a video e imagen a video con audio sincronizado.",
|
||||
"dreamina-seedance-2-0-fast-260128.description": "Seedance 2.0 Fast de ByteDance ofrece las mismas capacidades que Seedance 2.0 con velocidades de generación más rápidas a un precio más competitivo.",
|
||||
"emohaa.description": "Emohaa es un modelo de salud mental con capacidades profesionales de asesoramiento para ayudar a los usuarios a comprender problemas emocionales.",
|
||||
"ernie-4.5-0.3b.description": "ERNIE 4.5 0.3B es un modelo ligero de código abierto para implementación local y personalizada.",
|
||||
"ernie-4.5-8k-preview.description": "ERNIE 4.5 8K Preview es un modelo de vista previa con contexto de 8K para evaluar ERNIE 4.5.",
|
||||
@@ -506,6 +503,7 @@
|
||||
"ernie-5.0-thinking-latest.description": "Wenxin 5.0 Thinking es un modelo insignia nativo multimodal con modelado unificado de texto, imagen, audio y video. Ofrece mejoras amplias en capacidades para preguntas complejas, creación y escenarios de agentes.",
|
||||
"ernie-5.0-thinking-preview.description": "Wenxin 5.0 Thinking Preview es un modelo insignia nativo multimodal con modelado unificado de texto, imagen, audio y video. Ofrece mejoras amplias en capacidades para preguntas complejas, creación y escenarios de agentes.",
|
||||
"ernie-5.0.description": "ERNIE 5.0, el modelo de nueva generación de la serie ERNIE, es un modelo multimodal nativo. Adopta un enfoque unificado de modelado multimodal, integrando texto, imágenes, audio y vídeo para ofrecer capacidades completas. Sus habilidades fundamentales han sido significativamente mejoradas, logrando un sólido rendimiento en benchmarks. Destaca en comprensión multimodal, seguimiento de instrucciones, redacción creativa, precisión factual, planificación agéntica y uso de herramientas.",
|
||||
"ernie-5.1.description": "ERNIE 5.1 es el modelo más reciente de la serie ERNIE, con mejoras integrales en sus capacidades fundamentales. Demuestra avances significativos en áreas como agentes, procesamiento de conocimiento, razonamiento y búsqueda profunda. Esta versión adopta una arquitectura de aprendizaje por refuerzo completamente asincrónica y desacoplada, diseñada específicamente para abordar desafíos clave en la evolución de modelos grandes hacia la toma de decisiones autónoma por parte de agentes, incluyendo discrepancias numéricas entre entrenamiento e inferencia, baja utilización de recursos informáticos heterogéneos y problemas globales causados por efectos de larga cola. Además, se emplean técnicas de post-entrenamiento a gran escala para agentes, lo que mejora aún más las capacidades y el rendimiento de generalización del modelo. A través de un marco colaborativo de tres etapas que involucra procesos de entorno, experto y fusión, el enfoque no solo garantiza la eficiencia del entrenamiento, sino que también mejora significativamente la estabilidad y el rendimiento del modelo en tareas complejas.",
|
||||
"ernie-char-fiction-8k-preview.description": "ERNIE Character Fiction 8K Preview es un modelo preliminar para la creación de personajes y tramas, diseñado para evaluación y pruebas.",
|
||||
"ernie-char-fiction-8k.description": "ERNIE Character Fiction 8K es un modelo de personajes para novelas y creación de tramas, ideal para generación de historias extensas.",
|
||||
"ernie-image-turbo.description": "ERNIE‑Image es un modelo de texto a imagen de 8B parámetros desarrollado por Baidu. Se sitúa entre los mejores en múltiples benchmarks, logrando el primer puesto compartido en SuperCLUE en China y liderando la categoría de código abierto.",
|
||||
@@ -517,8 +515,7 @@
|
||||
"ernie-x1-turbo-32k.description": "ERNIE X1 Turbo 32K es un modelo de pensamiento rápido con contexto de 32K para razonamiento complejo y chat de múltiples turnos.",
|
||||
"ernie-x1.1-preview.description": "ERNIE X1.1 Preview es una vista previa del modelo de pensamiento para evaluación y pruebas.",
|
||||
"ernie-x1.1.description": "ERNIE X1.1 es un modelo de pensamiento en vista previa para evaluación y pruebas.",
|
||||
"fal-ai/bytedance/seedream/v4.5.description": "Seedream 4.5, desarrollado por el equipo Seed de ByteDance, admite edición y composición de múltiples imágenes. Incluye consistencia mejorada de sujetos, seguimiento preciso de instrucciones, comprensión de lógica espacial, expresión estética, diseño de carteles y logotipos con renderizado de texto-imagen de alta precisión.",
|
||||
"fal-ai/bytedance/seedream/v4.description": "Seedream 4.0, desarrollado por ByteDance Seed, admite entradas de texto e imagen para generación de imágenes altamente controlable y de alta calidad a partir de indicaciones.",
|
||||
"fal-ai/bytedance/seedream/v4.description": "Seedream 4.0 es un modelo de generación de imágenes de ByteDance Seed, que admite entradas de texto e imagen con generación de imágenes altamente controlable y de alta calidad. Genera imágenes a partir de indicaciones de texto.",
|
||||
"fal-ai/flux-kontext/dev.description": "Modelo FLUX.1 centrado en la edición de imágenes, compatible con entradas de texto e imagen.",
|
||||
"fal-ai/flux-pro/kontext.description": "FLUX.1 Kontext [pro] acepta texto e imágenes de referencia como entrada, permitiendo ediciones locales dirigidas y transformaciones globales complejas de escenas.",
|
||||
"fal-ai/flux/krea.description": "Flux Krea [dev] es un modelo de generación de imágenes con una inclinación estética hacia imágenes más realistas y naturales.",
|
||||
@@ -526,8 +523,8 @@
|
||||
"fal-ai/hunyuan-image/v3.description": "Un potente modelo nativo multimodal de generación de imágenes.",
|
||||
"fal-ai/imagen4/preview.description": "Modelo de generación de imágenes de alta calidad de Google.",
|
||||
"fal-ai/nano-banana.description": "Nano Banana es el modelo multimodal nativo más nuevo, rápido y eficiente de Google, que permite generación y edición de imágenes mediante conversación.",
|
||||
"fal-ai/qwen-image-edit.description": "Un modelo profesional de edición de imágenes del equipo Qwen, que admite ediciones semánticas y de apariencia, edición precisa de texto en chino/inglés, transferencia de estilo, rotación y más.",
|
||||
"fal-ai/qwen-image.description": "Un modelo poderoso de generación de imágenes del equipo Qwen con un fuerte renderizado de texto en chino y estilos visuales diversos.",
|
||||
"fal-ai/qwen-image-edit.description": "Un modelo profesional de edición de imágenes del equipo Qwen que admite ediciones semánticas y de apariencia, edita con precisión texto en chino e inglés, y permite ediciones de alta calidad como transferencia de estilo y rotación de objetos.",
|
||||
"fal-ai/qwen-image.description": "Un modelo poderoso de generación de imágenes del equipo Qwen con una impresionante representación de texto en chino y estilos visuales diversos.",
|
||||
"flux-1-schnell.description": "Modelo de texto a imagen con 12 mil millones de parámetros de Black Forest Labs que utiliza destilación difusiva adversarial latente para generar imágenes de alta calidad en 1 a 4 pasos. Compite con alternativas cerradas y se lanza bajo licencia Apache-2.0 para uso personal, de investigación y comercial.",
|
||||
"flux-dev.description": "Modelo de generación de imágenes de I+D de código abierto, optimizado de forma eficiente para investigación innovadora no comercial.",
|
||||
"flux-kontext-max.description": "Generación y edición de imágenes contextual de última generación, combinando texto e imágenes para resultados precisos y coherentes.",
|
||||
@@ -569,7 +566,7 @@
|
||||
"gemini-3-pro-image-preview:image.description": "Gemini 3 Pro Image (Nano Banana Pro) es el modelo de generación de imágenes de Google y también admite chat multimodal.",
|
||||
"gemini-3-pro-preview.description": "Gemini 3 Pro es el agente más potente de Google y modelo de codificación emocional, que ofrece visuales más ricos e interacción más profunda sobre un razonamiento de última generación.",
|
||||
"gemini-3.1-flash-image-preview.description": "Gemini 3.1 Flash Image (Nano Banana 2) es el modelo nativo de generación de imágenes más rápido de Google con soporte de pensamiento, generación conversacional de imágenes y edición.",
|
||||
"gemini-3.1-flash-image-preview:image.description": "Gemini 3.1 Flash Image (Nano Banana 2) ofrece calidad de imagen a nivel Pro a velocidad Flash con soporte para chat multimodal.",
|
||||
"gemini-3.1-flash-image-preview:image.description": "Gemini 3.1 Flash Image (Nano Banana 2) es el modelo nativo de generación de imágenes más rápido de Google, con soporte para razonamiento, generación conversacional de imágenes y edición.",
|
||||
"gemini-3.1-flash-lite-preview.description": "Gemini 3.1 Flash-Lite Preview es el modelo multimodal más rentable de Google, optimizado para tareas agentivas de alto volumen, traducción y procesamiento de datos.",
|
||||
"gemini-3.1-flash-lite.description": "Gemini 3.1 Flash-Lite es el modelo multimodal más eficiente en costos de Google, optimizado para tareas agentivas de alto volumen, traducción y procesamiento de datos.",
|
||||
"gemini-3.1-pro-preview.description": "Gemini 3.1 Pro Preview mejora las capacidades de razonamiento de Gemini 3 Pro y añade soporte para un nivel de pensamiento medio.",
|
||||
@@ -734,8 +731,6 @@
|
||||
"grok-4-fast-reasoning.description": "Nos complace lanzar Grok 4 Fast, nuestro último avance en modelos de razonamiento rentables.",
|
||||
"grok-4.20-0309-non-reasoning.description": "Variante sin razonamiento para casos de uso simples.",
|
||||
"grok-4.20-0309-reasoning.description": "Modelo inteligente y rapidísimo que razona antes de responder.",
|
||||
"grok-4.20-beta-0309-non-reasoning.description": "Una variante sin razonamiento para casos de uso simples.",
|
||||
"grok-4.20-beta-0309-reasoning.description": "Modelo inteligente y ultrarrápido que razona antes de responder.",
|
||||
"grok-4.20-multi-agent-0309.description": "Equipo de 4 o 16 agentes. Destaca en casos de investigación. No admite herramientas del lado del cliente. Solo admite herramientas del lado del servidor de xAI (como X Search, Web Search) y herramientas MCP remotas.",
|
||||
"grok-4.3.description": "El modelo de lenguaje grande más orientado a la verdad en el mundo.",
|
||||
"grok-4.description": "Último modelo insignia de Grok con un rendimiento inigualable en lenguaje, matemáticas y razonamiento — un verdadero todoterreno. Actualmente apunta a grok-4-0709; debido a recursos limitados, tiene un precio temporalmente un 10% más alto que el oficial y se espera que regrese al precio oficial más adelante.",
|
||||
@@ -1220,8 +1215,6 @@
|
||||
"qwq.description": "QwQ es un modelo de razonamiento de la familia Qwen. En comparación con los modelos estándar ajustados por instrucciones, ofrece capacidades de pensamiento y razonamiento que mejoran significativamente el rendimiento en tareas difíciles. QwQ-32B es un modelo de razonamiento de tamaño medio que compite con los mejores modelos como DeepSeek-R1 y o1-mini.",
|
||||
"qwq_32b.description": "Modelo de razonamiento de tamaño medio de la familia Qwen. En comparación con los modelos estándar ajustados por instrucciones, las capacidades de pensamiento y razonamiento de QwQ mejoran significativamente el rendimiento en tareas difíciles.",
|
||||
"r1-1776.description": "R1-1776 es una variante postentrenada de DeepSeek R1 diseñada para proporcionar información factual sin censura ni sesgo.",
|
||||
"seedance-1-5-pro-251215.description": "Seedance 1.5 Pro de ByteDance admite texto a video, imagen a video (primer cuadro, primer+último cuadro) y generación de audio sincronizado con visuales.",
|
||||
"seedream-5-0-260128.description": "ByteDance-Seedream-5.0-lite de BytePlus incluye generación aumentada con recuperación web para información en tiempo real, interpretación mejorada de indicaciones complejas y mayor consistencia de referencia para creación visual profesional.",
|
||||
"solar-mini-ja.description": "Solar Mini (Ja) amplía Solar Mini con un enfoque en japonés, manteniendo un rendimiento eficiente y sólido en inglés y coreano.",
|
||||
"solar-mini.description": "Solar Mini es un modelo LLM compacto que supera a GPT-3.5, con una sólida capacidad multilingüe compatible con inglés y coreano, ofreciendo una solución eficiente de bajo consumo.",
|
||||
"solar-pro.description": "Solar Pro es un LLM de alta inteligencia de Upstage, enfocado en el seguimiento de instrucciones en una sola GPU, con puntuaciones IFEval superiores a 80. Actualmente admite inglés; el lanzamiento completo estaba previsto para noviembre de 2024 con soporte de idiomas ampliado y contexto más largo.",
|
||||
|
||||
@@ -27,6 +27,13 @@
|
||||
"agent.layout.skipConfirm.ok": "Omitir por ahora",
|
||||
"agent.layout.skipConfirm.title": "¿Omitir la configuración inicial por ahora?",
|
||||
"agent.layout.switchMessage": "¿No te convence hoy? Puedes cambiar a <modeLink><modeText>{{mode}}</modeText></modeLink> o <skipLink><skipText>{{skip}}</skipText></skipLink>.",
|
||||
"agent.layout.switchMessageClassic": "¿No te sientes con ganas hoy? Puedes cambiar a <modeLink><modeText>{{mode}}</modeText></modeLink>.",
|
||||
"agent.messenger.cta.discord": "Añadir a Discord",
|
||||
"agent.messenger.cta.slack": "Añadir a Slack",
|
||||
"agent.messenger.cta.telegram": "Abrir en Telegram",
|
||||
"agent.messenger.subtitle": "Chatea con tu agente en Telegram, Slack o Discord",
|
||||
"agent.messenger.telegramQrCaption": "Escanea con la cámara de tu teléfono",
|
||||
"agent.messenger.title": "Llévame contigo, donde sea que envíes mensajes",
|
||||
"agent.modeSwitch.agent": "Conversacional",
|
||||
"agent.modeSwitch.classic": "Clásico",
|
||||
"agent.modeSwitch.collapse": "Colapsar",
|
||||
@@ -68,6 +75,13 @@
|
||||
"agent.wrapUp.confirm.content": "Guardaré lo que hemos visto hasta ahora. Siempre puedes volver y seguir charlando más adelante.",
|
||||
"agent.wrapUp.confirm.ok": "Terminar ahora",
|
||||
"agent.wrapUp.confirm.title": "¿Finalizar la incorporación ahora?",
|
||||
"agentPicker.allCategories": "Todos",
|
||||
"agentPicker.continue": "Continuar",
|
||||
"agentPicker.skip": "Saltar por ahora",
|
||||
"agentPicker.subtitle": "Añade algunos a tu biblioteca ahora — descubre más en cualquier momento después.",
|
||||
"agentPicker.title": "Añadamos algunos agentes a tu biblioteca",
|
||||
"agentPicker.title2": "Elige los que se adapten a tu forma de trabajar",
|
||||
"agentPicker.title3": "Siempre puedes añadir más después — empieza con algunos",
|
||||
"back": "Volver",
|
||||
"finish": "Comenzar",
|
||||
"interests.area.business": "Negocios y Estrategia",
|
||||
|
||||
@@ -39,8 +39,8 @@
|
||||
"builtins.lobe-agent-documents.inspector.docCount": "{{count}} documentos",
|
||||
"builtins.lobe-agent-documents.inspector.opsCount": "{{count}} operaciones",
|
||||
"builtins.lobe-agent-documents.inspector.opsResult": "{{success}}/{{total}} operaciones",
|
||||
"builtins.lobe-agent-documents.inspector.target.agent": "en agente",
|
||||
"builtins.lobe-agent-documents.inspector.target.currentTopic": "en tema",
|
||||
"builtins.lobe-agent-documents.inspector.scope.agent": "en agente",
|
||||
"builtins.lobe-agent-documents.inspector.scope.currentTopic": "en tema",
|
||||
"builtins.lobe-agent-documents.title": "Documentos del Agente",
|
||||
"builtins.lobe-agent-management.apiName.callAgent": "Agente de llamada",
|
||||
"builtins.lobe-agent-management.apiName.createAgent": "Crear agente",
|
||||
@@ -90,6 +90,14 @@
|
||||
"builtins.lobe-agent.title": "Agente Lobe",
|
||||
"builtins.lobe-claude-code.agent.instruction": "Instrucción",
|
||||
"builtins.lobe-claude-code.agent.result": "Resultado",
|
||||
"builtins.lobe-claude-code.task.createLabel": "Creando tarea: ",
|
||||
"builtins.lobe-claude-code.task.getLabel": "Inspeccionando tarea #{{taskId}}",
|
||||
"builtins.lobe-claude-code.task.listLabel": "Listando tareas",
|
||||
"builtins.lobe-claude-code.task.updateCompleted": "Completado",
|
||||
"builtins.lobe-claude-code.task.updateDeleted": "Eliminado",
|
||||
"builtins.lobe-claude-code.task.updateInProgress": "Iniciado",
|
||||
"builtins.lobe-claude-code.task.updateLabel": "Actualizando tarea #{{taskId}}",
|
||||
"builtins.lobe-claude-code.task.updatePending": "Restablecer",
|
||||
"builtins.lobe-claude-code.todoWrite.allDone": "Todas las tareas completadas",
|
||||
"builtins.lobe-claude-code.todoWrite.currentStep": "Paso actual",
|
||||
"builtins.lobe-claude-code.todoWrite.todos": "Tareas",
|
||||
|
||||
@@ -33,7 +33,6 @@
|
||||
"jina.description": "Fundada en 2020, Jina AI es una empresa líder en búsqueda con IA. Su pila de búsqueda incluye modelos vectoriales, reordenadores y pequeños modelos de lenguaje para construir aplicaciones generativas y multimodales confiables y de alta calidad.",
|
||||
"kimicodingplan.description": "Kimi Code de Moonshot AI proporciona acceso a los modelos Kimi, incluidos K2.5, para tareas de codificación.",
|
||||
"lmstudio.description": "LM Studio es una aplicación de escritorio para desarrollar y experimentar con LLMs en tu ordenador.",
|
||||
"lobehub.description": "LobeHub Cloud utiliza APIs oficiales para acceder a modelos de IA y mide el uso con Créditos vinculados a los tokens del modelo.",
|
||||
"longcat.description": "LongCat es una serie de modelos grandes de inteligencia artificial generativa desarrollados de manera independiente por Meituan. Está diseñado para mejorar la productividad interna de la empresa y permitir aplicaciones innovadoras mediante una arquitectura computacional eficiente y sólidas capacidades multimodales.",
|
||||
"minimax.description": "Fundada en 2021, MiniMax desarrolla IA de propósito general con modelos fundacionales multimodales, incluyendo modelos de texto MoE con billones de parámetros, modelos de voz y visión, junto con aplicaciones como Hailuo AI.",
|
||||
"minimaxcodingplan.description": "El Plan de Tokens MiniMax proporciona acceso a los modelos MiniMax, incluidos M2.7, para tareas de codificación mediante una suscripción de tarifa fija.",
|
||||
|
||||
@@ -55,6 +55,12 @@
|
||||
"credits.autoTopUp.toggle": "Activar Recarga Automática",
|
||||
"credits.autoTopUp.upgradeHint": "Suscríbete a un plan de pago para habilitar la recarga automática",
|
||||
"credits.autoTopUp.validation.targetMustExceedThreshold": "El saldo objetivo debe ser mayor que el umbral",
|
||||
"credits.costEstimateHint.desc": "Muestra una advertencia ligera antes de enviar cuando el costo estimado del modelo alcanza tu umbral",
|
||||
"credits.costEstimateHint.saveError": "No se pudieron guardar las configuraciones de alerta de estimación de costos",
|
||||
"credits.costEstimateHint.saveSuccess": "Configuraciones de alerta de estimación de costos guardadas",
|
||||
"credits.costEstimateHint.threshold": "Umbral de Advertencia",
|
||||
"credits.costEstimateHint.title": "Alerta de Estimación de Costos",
|
||||
"credits.costEstimateHint.validation.threshold": "El umbral debe ser mayor o igual a 0",
|
||||
"credits.packages.auto": "Automático",
|
||||
"credits.packages.charged": "Cargado ${{amount}}",
|
||||
"credits.packages.expired": "Expirado",
|
||||
|
||||
@@ -40,6 +40,14 @@
|
||||
"agentMarketplace.render.alreadyInLibraryTag": "Ya en la biblioteca",
|
||||
"agentMarketplace.render.alreadyInLibrary_one": "{{count}} ya en la biblioteca",
|
||||
"agentMarketplace.render.alreadyInLibrary_other": "{{count}} ya en la biblioteca",
|
||||
"claudeCode.askUserQuestion.escape.back": "Volver a las opciones",
|
||||
"claudeCode.askUserQuestion.escape.enter": "O escribe directamente",
|
||||
"claudeCode.askUserQuestion.escape.placeholder": "Escribe tu respuesta aquí…",
|
||||
"claudeCode.askUserQuestion.multiSelectTag": "(selección múltiple)",
|
||||
"claudeCode.askUserQuestion.skip": "Omitir",
|
||||
"claudeCode.askUserQuestion.submit": "Enviar",
|
||||
"claudeCode.askUserQuestion.timeExpired": "Tiempo expirado — usando la opción 1 de cada pregunta.",
|
||||
"claudeCode.askUserQuestion.timeRemaining": "Tiempo restante: {{time}} · las preguntas sin respuesta se asignan a la opción 1 al agotarse el tiempo.",
|
||||
"codeInterpreter-legacy.error": "Error de Ejecución",
|
||||
"codeInterpreter-legacy.executing": "Ejecutando...",
|
||||
"codeInterpreter-legacy.files": "Archivos:",
|
||||
|
||||
@@ -56,6 +56,7 @@
|
||||
"renameModal.title": "Renombrar tema",
|
||||
"searchPlaceholder": "Buscar temas...",
|
||||
"searchResultEmpty": "No se encontraron resultados de búsqueda.",
|
||||
"sidebar.title": "Temas",
|
||||
"taskManager.agent": "Agente de Tareas",
|
||||
"taskManager.welcome": "Pregúntame sobre tus tareas",
|
||||
"temp": "Temporal",
|
||||
|
||||
@@ -220,6 +220,13 @@
|
||||
"inbox.title": "Lobe AI",
|
||||
"input.addAi": "افزودن پیام هوش مصنوعی",
|
||||
"input.addUser": "افزودن پیام کاربر",
|
||||
"input.costEstimate.creditsPerMillionTokens": "{{credits}} اعتبار/میلیون توکن",
|
||||
"input.costEstimate.hint": "هزینه تخمینی: ~{{credits}} اعتبار",
|
||||
"input.costEstimate.inputLabel": "ورودی",
|
||||
"input.costEstimate.outputLabel": "خروجی",
|
||||
"input.costEstimate.settingsLink": "تنظیم آستانه هشدار",
|
||||
"input.costEstimate.tokenCount": "~{{tokens}} توکن",
|
||||
"input.costEstimate.tooltip": "تخمین زده شده بر اساس زمینه فعلی، ابزارها و قیمتگذاری مدل. هزینه واقعی ممکن است متفاوت باشد.",
|
||||
"input.disclaimer": "عوامل ممکن است اشتباه کنند. برای اطلاعات حساس از قضاوت خود استفاده کنید.",
|
||||
"input.errorMsg": "ارسال ناموفق: {{errorMsg}}. دوباره تلاش کنید یا بعداً ارسال نمایید.",
|
||||
"input.more": "بیشتر",
|
||||
@@ -779,6 +786,7 @@
|
||||
"upload.preview.prepareTasks": "در حال آمادهسازی بخشها...",
|
||||
"upload.preview.status.pending": "در حال آمادهسازی برای بارگذاری...",
|
||||
"upload.preview.status.processing": "در حال پردازش فایل...",
|
||||
"upload.validation.unsupportedFileType": "نوع فایل پشتیبانی نشده: {{files}}. تصاویر پشتیبانی شده: JPG، PNG، GIF، WebP. اسناد پشتیبانی شده شامل PDF، Word، Excel، PowerPoint، Markdown، متن، CSV، JSON و فایلهای کد هستند.",
|
||||
"upload.validation.videoSizeExceeded": "حجم فایل ویدیو نباید بیش از ۲۰ مگابایت باشد. حجم فعلی: {{actualSize}}.",
|
||||
"viewMode.fullWidth": "تمامعرض",
|
||||
"viewMode.normal": "استاندارد",
|
||||
@@ -894,6 +902,8 @@
|
||||
"workingPanel.localFile.closeOther": "بستن سایرین",
|
||||
"workingPanel.localFile.closeRight": "بستن به سمت راست",
|
||||
"workingPanel.localFile.error": "بارگذاری این فایل ممکن نیست",
|
||||
"workingPanel.localFile.preview.raw": "خام",
|
||||
"workingPanel.localFile.preview.render": "پیشنمایش",
|
||||
"workingPanel.localFile.truncated": "پیشنمایش فایل به {{limit}} کاراکتر محدود شده است",
|
||||
"workingPanel.progress": "Progress",
|
||||
"workingPanel.progress.allCompleted": "All tasks completed",
|
||||
@@ -959,6 +969,8 @@
|
||||
"workingPanel.review.viewMode.unified": "تغییر به نمای یکپارچه",
|
||||
"workingPanel.review.wordWrap.disable": "غیرفعال کردن پیچش کلمات",
|
||||
"workingPanel.review.wordWrap.enable": "فعال کردن پیچش کلمات",
|
||||
"workingPanel.skills.empty": "هیچ مهارتی در این پروژه یافت نشد",
|
||||
"workingPanel.skills.title": "مهارتها",
|
||||
"workingPanel.space": "فضا",
|
||||
"workingPanel.title": "Working Panel",
|
||||
"you": "شما",
|
||||
|
||||
@@ -121,6 +121,16 @@
|
||||
"ModelSwitchPanel.detail.context": "طول زمینه",
|
||||
"ModelSwitchPanel.detail.pricing": "قیمتگذاری",
|
||||
"ModelSwitchPanel.detail.pricing.cachedInput": "ورودی کششده ${{amount}}/میلیون",
|
||||
"ModelSwitchPanel.detail.pricing.credits.cachedInput": "ورودی ذخیرهشده {{amount}} اعتبار/میلیون توکن",
|
||||
"ModelSwitchPanel.detail.pricing.credits.image": "اعتبار/تصویر",
|
||||
"ModelSwitchPanel.detail.pricing.credits.input": "ورودی {{amount}} اعتبار/میلیون توکن",
|
||||
"ModelSwitchPanel.detail.pricing.credits.megapixel": "اعتبار/مگاپیکسل",
|
||||
"ModelSwitchPanel.detail.pricing.credits.millionCharacters": "اعتبار/میلیون کاراکتر",
|
||||
"ModelSwitchPanel.detail.pricing.credits.millionTokens": "اعتبار/میلیون توکن",
|
||||
"ModelSwitchPanel.detail.pricing.credits.output": "خروجی {{amount}} اعتبار/میلیون توکن",
|
||||
"ModelSwitchPanel.detail.pricing.credits.perImage": "~ {{amount}} اعتبار / تصویر",
|
||||
"ModelSwitchPanel.detail.pricing.credits.perVideo": "~ {{amount}} اعتبار / ویدیو",
|
||||
"ModelSwitchPanel.detail.pricing.credits.second": "اعتبار/ثانیه",
|
||||
"ModelSwitchPanel.detail.pricing.group.audio": "صوت",
|
||||
"ModelSwitchPanel.detail.pricing.group.image": "تصویر",
|
||||
"ModelSwitchPanel.detail.pricing.group.text": "متن",
|
||||
|
||||
@@ -1,8 +1,10 @@
|
||||
{
|
||||
"actionTag.category.command": "دستور",
|
||||
"actionTag.category.projectSkill": "مهارت پروژه",
|
||||
"actionTag.category.skill": "مهارت",
|
||||
"actionTag.category.tool": "ابزار",
|
||||
"actionTag.tooltip.command": "پیش از ارسال، یک دستور اسلش سمت کلاینت را اجرا میکند.",
|
||||
"actionTag.tooltip.projectSkill": "به عنوان یک فراخوانی اسلش ارسال میشود تا CLI عامل مهارت پروژه مطابقتیافته را اجرا کند.",
|
||||
"actionTag.tooltip.skill": "برای این درخواست، یک بسته مهارت قابل استفاده مجدد را بارگذاری میکند.",
|
||||
"actionTag.tooltip.tool": "ابزاری را که کاربر بهطور صریح برای این درخواست انتخاب کرده است علامتگذاری میکند.",
|
||||
"actions.expand.off": "جمع کردن",
|
||||
|
||||
@@ -11,6 +11,19 @@
|
||||
"brief.action.ignore": "نادیده گرفتن",
|
||||
"brief.action.retry": "تلاش دوباره",
|
||||
"brief.addFeedback": "اشتراکگذاری بازخورد",
|
||||
"brief.agentSignal.selfReview.applied.heading": "بهروزرسانی شد",
|
||||
"brief.agentSignal.selfReview.applied.summary": "{{count}} بهروزرسانی رویا اعمال شد.",
|
||||
"brief.agentSignal.selfReview.applied.summary_plural": "{{count}} بهروزرسانیهای رویا اعمال شدند.",
|
||||
"brief.agentSignal.selfReview.applied.title": "منابع بهروزرسانی شده رویا",
|
||||
"brief.agentSignal.selfReview.error.heading": "مشکل",
|
||||
"brief.agentSignal.selfReview.error.summary": "برخی کارها در طول این رویا کامل نشدند.",
|
||||
"brief.agentSignal.selfReview.error.title": "رویا با مشکلی مواجه شد",
|
||||
"brief.agentSignal.selfReview.ideas.summary": "یادداشتهای رویا برای بررسیهای آینده ذخیره شدند.",
|
||||
"brief.agentSignal.selfReview.ideas.title": "یادداشتهای رویا",
|
||||
"brief.agentSignal.selfReview.proposal.heading": "پیشنهاد",
|
||||
"brief.agentSignal.selfReview.proposal.summary": "{{count}} پیشنهاد رویا نیاز به بررسی شما دارد.",
|
||||
"brief.agentSignal.selfReview.proposal.summary_plural": "{{count}} پیشنهادهای رویا نیاز به بررسی شما دارند.",
|
||||
"brief.agentSignal.selfReview.proposal.title": "پیشنهاد رویا نیاز به بررسی دارد",
|
||||
"brief.collapse": "نمایش کمتر",
|
||||
"brief.commentPlaceholder": "بازخورد خود را بنویسید...",
|
||||
"brief.commentSubmit": "ارسال بازخورد",
|
||||
|
||||
@@ -1,8 +1,6 @@
|
||||
{
|
||||
"addUserMessage.desc": "افزودن ورودی فعلی بهعنوان پیام کاربر بدون شروع تولید پاسخ",
|
||||
"addUserMessage.title": "افزودن پیام کاربر",
|
||||
"clearCurrentMessages.desc": "پاکسازی پیامها و فایلهای بارگذاریشده از گفتوگوی فعلی",
|
||||
"clearCurrentMessages.title": "پاکسازی پیامهای گفتوگو",
|
||||
"commandPalette.desc": "باز کردن پنل فرمان جهانی برای دسترسی سریع به قابلیتها",
|
||||
"commandPalette.title": "پنل فرمان",
|
||||
"deleteAndRegenerateMessage.desc": "حذف آخرین پیام و تولید مجدد آن",
|
||||
|
||||
+12
-19
@@ -106,7 +106,6 @@
|
||||
"MiniMax-Hailuo-2.3.description": "مدل جدید تولید ویدئو با ارتقاهای جامع در حرکت بدن، واقعگرایی فیزیکی و پیروی از دستورالعملها.",
|
||||
"MiniMax-M1.description": "یک مدل استدلالی داخلی جدید با ۸۰ هزار زنجیره تفکر و ورودی ۱ میلیون توکن، با عملکردی در سطح مدلهای برتر جهانی.",
|
||||
"MiniMax-M2-Stable.description": "طراحیشده برای کدنویسی کارآمد و جریانهای کاری عاملمحور، با همزمانی بالاتر برای استفاده تجاری.",
|
||||
"MiniMax-M2.1-Lightning.description": "قابلیتهای برنامهنویسی چندزبانه قدرتمند با استنتاج سریعتر و کارآمدتر.",
|
||||
"MiniMax-M2.1-highspeed.description": "قابلیتهای برنامهنویسی چندزبانه قدرتمند، تجربه برنامهنویسی کاملاً ارتقاء یافته. سریعتر و کارآمدتر.",
|
||||
"MiniMax-M2.1.description": "MiniMax-M2.1 یک مدل بزرگ متنباز پیشرفته از MiniMax است که بر حل وظایف پیچیده دنیای واقعی تمرکز دارد. نقاط قوت اصلی آن شامل توانایی برنامهنویسی چندزبانه و قابلیت عمل بهعنوان یک عامل هوشمند برای حل مسائل پیچیده است.",
|
||||
"MiniMax-M2.5-highspeed.description": "MiniMax M2.5 Highspeed: همان عملکرد M2.5 با استنتاج سریعتر.",
|
||||
@@ -315,13 +314,13 @@
|
||||
"claude-3-haiku-20240307.description": "Claude 3 Haiku سریعترین و فشردهترین مدل Anthropic است که برای پاسخهای تقریباً فوری با عملکرد سریع و دقیق طراحی شده است.",
|
||||
"claude-3-opus-20240229.description": "Claude 3 Opus قدرتمندترین مدل Anthropic برای وظایف بسیار پیچیده است که در عملکرد، هوش، روانی و درک زبان برتری دارد.",
|
||||
"claude-3-sonnet-20240229.description": "Claude 3 Sonnet تعادل بین هوش و سرعت را برای بارهای کاری سازمانی برقرار میکند و با هزینه کمتر، بهرهوری بالا و استقرار قابل اعتماد در مقیاس وسیع را ارائه میدهد.",
|
||||
"claude-haiku-4-5-20251001.description": "Claude Haiku 4.5 سریعترین و هوشمندترین مدل هایکو Anthropic است، با سرعت فوقالعاده و توانایی تفکر گسترده.",
|
||||
"claude-haiku-4-5-20251001.description": "Claude Haiku 4.5 سریعترین و هوشمندترین مدل هایکو Anthropic است که با سرعتی برقآسا و توانایی استدلال پیشرفته عمل میکند.",
|
||||
"claude-haiku-4-5.description": "Claude Haiku 4.5 از Anthropic — نسل جدید Haiku با استدلال و پردازش تصویری پیشرفته.",
|
||||
"claude-haiku-4.5.description": "Claude Haiku 4.5 سریعترین و هوشمندترین مدل Haiku از Anthropic است که با سرعت برقآسا و توانایی استدلال پیشرفته ارائه میشود.",
|
||||
"claude-opus-4-1-20250805-thinking.description": "Claude Opus 4.1 Thinking یک نسخه پیشرفته است که میتواند فرآیند استدلال خود را آشکار کند.",
|
||||
"claude-opus-4-1-20250805.description": "Claude Opus 4.1 جدیدترین و توانمندترین مدل Anthropic برای وظایف بسیار پیچیده است که در عملکرد، هوش، روانی و درک برتری دارد.",
|
||||
"claude-opus-4-1-20250805.description": "Claude Opus 4.1 جدیدترین و توانمندترین مدل Anthropic برای انجام وظایف بسیار پیچیده است که در عملکرد، هوش، روانی و درک برتری دارد.",
|
||||
"claude-opus-4-1.description": "Claude Opus 4.1 از Anthropic — مدل استدلال سطحبالا با توانایی تحلیل عمیق.",
|
||||
"claude-opus-4-20250514.description": "Claude Opus 4 قدرتمندترین مدل Anthropic برای وظایف بسیار پیچیده است که در عملکرد، هوش، روانی و درک برتری دارد.",
|
||||
"claude-opus-4-20250514.description": "Claude Opus 4 قدرتمندترین مدل Anthropic برای انجام وظایف بسیار پیچیده است که در عملکرد، هوش، روانی و فهم برتری دارد.",
|
||||
"claude-opus-4-5-20251101.description": "Claude Opus 4.5 مدل پرچمدار Anthropic است که هوش برجسته را با عملکرد مقیاسپذیر ترکیب میکند و برای وظایف پیچیدهای که نیاز به پاسخهای باکیفیت و استدلال دارند، ایدهآل است.",
|
||||
"claude-opus-4-5.description": "Claude Opus 4.5 از Anthropic — مدل پرچمدار با استدلال و کدنویسی سطحبالا.",
|
||||
"claude-opus-4-6.description": "Claude Opus 4.6 از Anthropic — مدل پرچمدار با پنجره زمینه ۱ میلیون و توانایی استدلال پیشرفته.",
|
||||
@@ -330,7 +329,7 @@
|
||||
"claude-opus-4.6-fast.description": "Claude Opus 4.6 هوشمندترین مدل Anthropic برای ساخت عوامل و کدنویسی است.",
|
||||
"claude-opus-4.6.description": "Claude Opus 4.6 هوشمندترین مدل Anthropic برای ساخت عوامل و کدنویسی است.",
|
||||
"claude-sonnet-4-20250514-thinking.description": "Claude Sonnet 4 Thinking میتواند پاسخهای تقریباً فوری یا تفکر گامبهگام طولانی با فرآیند قابل مشاهده تولید کند.",
|
||||
"claude-sonnet-4-20250514.description": "Claude Sonnet 4 هوشمندترین مدل Anthropic تا به امروز است که پاسخهای تقریباً فوری یا تفکر گامبهگام گسترده با کنترل دقیق برای کاربران API ارائه میدهد.",
|
||||
"claude-sonnet-4-20250514.description": "Claude Sonnet 4 میتواند پاسخهای تقریباً فوری یا تفکر گامبهگام گسترده با فرآیند قابل مشاهده تولید کند.",
|
||||
"claude-sonnet-4-5-20250929.description": "Claude Sonnet 4.5 هوشمندترین مدل Anthropic تا به امروز است.",
|
||||
"claude-sonnet-4-5.description": "Claude Sonnet 4.5 از Anthropic — نسخه بهبودیافته Sonnet با عملکرد بهتر در کدنویسی.",
|
||||
"claude-sonnet-4-6.description": "Claude Sonnet 4.6 از Anthropic — جدیدترین Sonnet با کدنویسی برتر و استفاده بهتر از ابزار.",
|
||||
@@ -404,7 +403,7 @@
|
||||
"deepseek-ai/deepseek-llm-67b-chat.description": "DeepSeek LLM Chat (67B) یک مدل نوآورانه با درک عمیق زبان و تعامل است.",
|
||||
"deepseek-ai/deepseek-v3.1-terminus.description": "DeepSeek V3.1 یک مدل استدلال نسل بعدی با توانایی استدلال پیچیده و زنجیره تفکر برای وظایف تحلیلی عمیق است.",
|
||||
"deepseek-ai/deepseek-v3.2.description": "DeepSeek V3.2 یک مدل استدلال نسل بعدی با قابلیتهای استدلال پیچیدهتر و زنجیرهای از تفکر است.",
|
||||
"deepseek-chat.description": "نام مستعار سازگار برای حالت غیرتفکری DeepSeek V4 Flash. برنامهریزی شده برای توقف استفاده — به جای آن از DeepSeek V4 Flash استفاده کنید.",
|
||||
"deepseek-chat.description": "یک مدل متنباز جدید که تواناییهای عمومی و کدنویسی را ترکیب میکند. این مدل گفتگوی عمومی مدل چت و کدنویسی قوی مدل کدنویس را حفظ کرده و با همترازی بهتر ترجیحات همراه است. DeepSeek-V2.5 همچنین نوشتن و پیروی از دستورالعملها را بهبود میبخشد.",
|
||||
"deepseek-coder-33B-instruct.description": "DeepSeek Coder 33B یک مدل زبان برنامهنویسی است که با ۲ تریلیون توکن (۸۷٪ کد، ۱۳٪ متن چینی/انگلیسی) آموزش دیده است. این مدل دارای پنجره متنی ۱۶K و وظایف تکمیل در میانه است که تکمیل کد در سطح پروژه و پر کردن قطعات کد را فراهم میکند.",
|
||||
"deepseek-coder-v2.description": "DeepSeek Coder V2 یک مدل کدنویسی MoE متنباز است که در وظایف برنامهنویسی عملکردی همسطح با GPT-4 Turbo دارد.",
|
||||
"deepseek-coder-v2:236b.description": "DeepSeek Coder V2 یک مدل کدنویسی MoE متنباز است که در وظایف برنامهنویسی عملکردی همسطح با GPT-4 Turbo دارد.",
|
||||
@@ -426,7 +425,7 @@
|
||||
"deepseek-r1-fast-online.description": "نسخه کامل سریع DeepSeek R1 با جستجوی وب در زمان واقعی که توانایی در مقیاس ۶۷۱B را با پاسخدهی سریعتر ترکیب میکند.",
|
||||
"deepseek-r1-online.description": "نسخه کامل DeepSeek R1 با ۶۷۱ میلیارد پارامتر و جستجوی وب در زمان واقعی که درک و تولید قویتری را ارائه میدهد.",
|
||||
"deepseek-r1.description": "DeepSeek-R1 پیش از یادگیری تقویتی از دادههای شروع سرد استفاده میکند و در وظایف ریاضی، کدنویسی و استدلال عملکردی همسطح با OpenAI-o1 دارد.",
|
||||
"deepseek-reasoner.description": "نام مستعار سازگار برای حالت تفکری DeepSeek V4 Flash. برنامهریزی شده برای توقف استفاده — به جای آن از DeepSeek V4 Flash استفاده کنید.",
|
||||
"deepseek-reasoner.description": "یک مدل استدلال DeepSeek که بر وظایف پیچیده استدلال منطقی متمرکز است.",
|
||||
"deepseek-v2.description": "DeepSeek V2 یک مدل MoE کارآمد است که پردازش مقرونبهصرفه را امکانپذیر میسازد.",
|
||||
"deepseek-v2:236b.description": "DeepSeek V2 236B مدل متمرکز بر کدنویسی DeepSeek است که توانایی بالایی در تولید کد دارد.",
|
||||
"deepseek-v3-0324.description": "DeepSeek-V3-0324 یک مدل MoE با ۶۷۱ میلیارد پارامتر است که در برنامهنویسی، تواناییهای فنی، درک زمینه و پردازش متون بلند عملکرد برجستهای دارد.",
|
||||
@@ -491,8 +490,6 @@
|
||||
"doubao-seedream-4-0-250828.description": "Seedream 4.0 یک مدل تولید تصویر از ByteDance Seed است که از ورودیهای متن و تصویر پشتیبانی میکند و تولید تصویر با کیفیت بالا و قابل کنترل را ارائه میدهد. این مدل تصاویر را از دستورات متنی تولید میکند.",
|
||||
"doubao-seedream-4-5-251128.description": "Seedream 4.5 جدیدترین مدل چندوجهی تصویر ByteDance است که قابلیتهای تبدیل متن به تصویر، تصویر به تصویر و تولید دستهای تصاویر را ادغام میکند و تواناییهای استدلال و دانش عمومی را نیز در بر میگیرد. در مقایسه با نسخه قبلی 4.0، کیفیت تولید بهطور قابلتوجهی بهبود یافته است، با سازگاری بهتر در ویرایش و ترکیب چند تصویر. کنترل دقیقتری بر جزئیات بصری ارائه میدهد، متنهای کوچک و چهرههای کوچک را بهطور طبیعیتر تولید میکند و به هماهنگی بهتر در چیدمان و رنگ دست مییابد، که زیبایی کلی را افزایش میدهد.",
|
||||
"doubao-seedream-5-0-260128.description": "Doubao-Seedream-5.0-lite جدیدترین مدل تولید تصویر ByteDance است. برای اولین بار، قابلیتهای بازیابی آنلاین را ادغام کرده است که به آن امکان میدهد اطلاعات وب لحظهای را وارد کند و بهموقع بودن تصاویر تولید شده را افزایش دهد. هوش مدل نیز ارتقا یافته است، که تفسیر دقیق دستورالعملهای پیچیده و محتوای بصری را امکانپذیر میکند. علاوه بر این، پوشش دانش جهانی، سازگاری مرجع و کیفیت تولید در سناریوهای حرفهای بهبود یافته است، که نیازهای خلق بصری در سطح سازمانی را بهتر برآورده میکند.",
|
||||
"dreamina-seedance-2-0-260128.description": "Seedance 2.0 توسط ByteDance قدرتمندترین مدل تولید ویدئو است که از تولید ویدئو با مرجع چندوجهی، ویرایش ویدئو، گسترش ویدئو، متن به ویدئو و تصویر به ویدئو با صدای همگامسازی شده پشتیبانی میکند.",
|
||||
"dreamina-seedance-2-0-fast-260128.description": "Seedance 2.0 Fast توسط ByteDance همان قابلیتهای Seedance 2.0 را با سرعت تولید بالاتر و قیمت رقابتیتر ارائه میدهد.",
|
||||
"emohaa.description": "Emohaa یک مدل سلامت روان با توانایی مشاوره حرفهای است که به کاربران در درک مسائل احساسی کمک میکند.",
|
||||
"ernie-4.5-0.3b.description": "ERNIE 4.5 0.3B یک مدل سبک متنباز برای استقرار محلی و سفارشیسازی شده است.",
|
||||
"ernie-4.5-8k-preview.description": "پیشنمایش مدل با پنجره متنی ۸هزار توکن برای ارزیابی ERNIE 4.5.",
|
||||
@@ -506,6 +503,7 @@
|
||||
"ernie-5.0-thinking-latest.description": "Wenxin 5.0 Thinking یک مدل پرچمدار بومی تماموجهی است که مدلسازی متن، تصویر، صدا و ویدیو را یکپارچه میکند. این مدل ارتقاهای گستردهای در توانایی برای پرسش و پاسخ پیچیده، تولید محتوا و سناریوهای عامل ارائه میدهد.",
|
||||
"ernie-5.0-thinking-preview.description": "پیشنمایش Wenxin 5.0 Thinking، یک مدل پرچمدار بومی تماموجهی با مدلسازی یکپارچه متن، تصویر، صدا و ویدیو. این مدل ارتقاهای گستردهای در توانایی برای پرسش و پاسخ پیچیده، تولید محتوا و سناریوهای عامل ارائه میدهد.",
|
||||
"ernie-5.0.description": "ERNIE 5.0 نسل جدید مدلهای سری ERNIE است؛ یک مدل بزرگ چندوجهی که از ابتدا بر اساس یک رویکرد مدلسازی یکپارچه ساخته شده است. این مدل متن، تصویر، صوت و ویدئو را به شکل مشترک مدلسازی کرده و تواناییهای چندوجهی قدرتمندی ارائه میدهد. تواناییهای بنیادی آن ارتقا یافته و عملکرد قوی در ارزیابیهای معیار نشان میدهد. این مدل در درک چندوجهی، پیروی از دستور، نوشتن خلاق، دقت واقعی، برنامهریزی ایجنتی و استفاده از ابزار عملکرد برجستهای دارد.",
|
||||
"ernie-5.1.description": "ERNIE 5.1 جدیدترین مدل در سری ERNIE است که ارتقاهای جامعی در قابلیتهای بنیادی خود ارائه میدهد. این مدل بهبودهای قابل توجهی در زمینههایی مانند عاملها، پردازش دانش، استدلال و جستجوی عمیق نشان میدهد. این نسخه از معماری تقویت یادگیری کاملاً غیرهمزمان و جداشده استفاده میکند که به طور خاص برای رفع چالشهای کلیدی در تکامل مدلهای بزرگ به سمت تصمیمگیری خودکار عاملها طراحی شده است، از جمله اختلافات عددی آموزش-استنتاج، استفاده کم از منابع محاسباتی ناهمگن و مسائل جهانی ناشی از اثرات دم بلند. علاوه بر این، تکنیکهای آموزش پس از عامل در مقیاس بزرگ برای افزایش قابلیتها و عملکرد تعمیم مدل به کار گرفته شدهاند. از طریق یک چارچوب همکاری سه مرحلهای شامل فرآیندهای محیط، متخصص و ادغام، این رویکرد نه تنها کارایی آموزش را تضمین میکند بلکه به طور قابل توجهی پایداری و عملکرد مدل را در وظایف پیچیده بهبود میبخشد.",
|
||||
"ernie-char-fiction-8k-preview.description": "پیشنمایش ERNIE Character Fiction 8K یک مدل ساخت شخصیت و داستان برای ارزیابی و آزمایش ویژگیها است.",
|
||||
"ernie-char-fiction-8k.description": "ERNIE Character Fiction 8K یک مدل شخصیتی برای رماننویسی و خلق داستان است که برای تولید داستانهای بلند مناسب است.",
|
||||
"ernie-image-turbo.description": "ERNIE-Image یک مدل متنبهتصویر با ۸ میلیارد پارامتر از Baidu است. این مدل در چندین معیار در میان بهترینها قرار میگیرد و در SuperCLUE چین رتبه اول مشترک و رتبه برتر در بخش متنباز دارد.",
|
||||
@@ -517,8 +515,7 @@
|
||||
"ernie-x1-turbo-32k.description": "ERNIE X1 Turbo 32K یک مدل تفکر سریع با زمینه ۳۲K برای استدلال پیچیده و گفتوگوی چندمرحلهای است.",
|
||||
"ernie-x1.1-preview.description": "پیشنمایش ERNIE X1.1 یک مدل تفکر برای ارزیابی و آزمایش است.",
|
||||
"ernie-x1.1.description": "ERNIE X1.1 یک مدل تفکر پیشنمایش برای ارزیابی و آزمایش است.",
|
||||
"fal-ai/bytedance/seedream/v4.5.description": "Seedream 4.5 که توسط تیم Seed ByteDance ساخته شده است، از ویرایش و ترکیب چندتصویری پشتیبانی میکند. ویژگیها شامل سازگاری بهتر موضوع، پیروی دقیق از دستورات، درک منطق فضایی، بیان زیباییشناختی، طراحی پوستر و لوگو با رندر دقیق متن-تصویر است.",
|
||||
"fal-ai/bytedance/seedream/v4.description": "Seedream 4.0 که توسط تیم Seed ByteDance ساخته شده است، از ورودیهای متن و تصویر برای تولید تصاویر باکیفیت و قابلکنترل از طریق دستورات پشتیبانی میکند.",
|
||||
"fal-ai/bytedance/seedream/v4.description": "Seedream 4.0 یک مدل تولید تصویر از ByteDance Seed است که از ورودیهای متنی و تصویری پشتیبانی میکند و تولید تصاویر با کیفیت بالا و کنترلپذیری بالا را ممکن میسازد. این مدل تصاویر را از دستورات متنی تولید میکند.",
|
||||
"fal-ai/flux-kontext/dev.description": "مدل FLUX.1 با تمرکز بر ویرایش تصویر که از ورودیهای متنی و تصویری پشتیبانی میکند.",
|
||||
"fal-ai/flux-pro/kontext.description": "FLUX.1 Kontext [pro] ورودیهای متنی و تصاویر مرجع را میپذیرد و امکان ویرایشهای محلی هدفمند و تغییرات پیچیده در صحنه کلی را فراهم میکند.",
|
||||
"fal-ai/flux/krea.description": "Flux Krea [dev] یک مدل تولید تصویر با تمایل زیباییشناسی به تصاویر طبیعی و واقعگرایانهتر است.",
|
||||
@@ -526,8 +523,8 @@
|
||||
"fal-ai/hunyuan-image/v3.description": "یک مدل قدرتمند بومی چندوجهی برای تولید تصویر.",
|
||||
"fal-ai/imagen4/preview.description": "مدل تولید تصویر با کیفیت بالا از گوگل.",
|
||||
"fal-ai/nano-banana.description": "Nano Banana جدیدترین، سریعترین و کارآمدترین مدل چندوجهی بومی گوگل است که امکان تولید و ویرایش تصویر از طریق مکالمه را فراهم میکند.",
|
||||
"fal-ai/qwen-image-edit.description": "مدل ویرایش تصویر حرفهای از تیم Qwen که از ویرایشهای معنایی و ظاهری، ویرایش دقیق متنهای چینی/انگلیسی، انتقال سبک، چرخش و موارد دیگر پشتیبانی میکند.",
|
||||
"fal-ai/qwen-image.description": "مدل قدرتمند تولید تصویر از تیم Qwen با قابلیت رندر قوی متن چینی و سبکهای بصری متنوع.",
|
||||
"fal-ai/qwen-image-edit.description": "یک مدل حرفهای ویرایش تصویر از تیم Qwen که از ویرایشهای معنایی و ظاهری پشتیبانی میکند، متنهای چینی و انگلیسی را با دقت ویرایش میکند و ویرایشهای با کیفیت بالا مانند انتقال سبک و چرخش اشیاء را ممکن میسازد.",
|
||||
"fal-ai/qwen-image.description": "یک مدل قدرتمند تولید تصویر از تیم Qwen با قابلیتهای برجسته در رندر متن چینی و سبکهای بصری متنوع.",
|
||||
"flux-1-schnell.description": "مدل تبدیل متن به تصویر با ۱۲ میلیارد پارامتر از Black Forest Labs که از تقطیر انتشار تقابلی نهفته برای تولید تصاویر با کیفیت بالا در ۱ تا ۴ مرحله استفاده میکند. این مدل با جایگزینهای بسته رقابت میکند و تحت مجوز Apache-2.0 برای استفاده شخصی، تحقیقاتی و تجاری منتشر شده است.",
|
||||
"flux-dev.description": "مدل تولید تصویر متنباز برای تحقیق و توسعه، بهطور کارآمد برای پژوهشهای نوآورانهٔ غیرتجاری بهینهسازی شده است.",
|
||||
"flux-kontext-max.description": "تولید و ویرایش تصویر متنی-زمینهای پیشرفته که متن و تصویر را برای نتایج دقیق و منسجم ترکیب میکند.",
|
||||
@@ -566,10 +563,10 @@
|
||||
"gemini-3-flash-preview.description": "Gemini 3 Flash هوشمندترین مدل طراحیشده برای سرعت است که هوش پیشرفته را با قابلیت جستوجوی دقیق ترکیب میکند.",
|
||||
"gemini-3-flash.description": "Gemini 3 Flash از Google — مدل بسیار سریع با پشتیبانی ورودی چندوجهی.",
|
||||
"gemini-3-pro-image-preview.description": "Gemini 3 Pro Image (Nano Banana Pro) مدل تولید تصویر گوگل است که از گفتگوی چندوجهی نیز پشتیبانی میکند.",
|
||||
"gemini-3-pro-image-preview:image.description": "Gemini 3 Pro Image (Nano Banana Pro) مدل تولید تصویر گوگل است و همچنین از چت چندوجهی پشتیبانی میکند.",
|
||||
"gemini-3-pro-image-preview:image.description": "Gemini 3 Pro Image (Nano Banana Pro) مدل تولید تصویر گوگل است که از چت چندوجهی نیز پشتیبانی میکند.",
|
||||
"gemini-3-pro-preview.description": "Gemini 3 Pro قدرتمندترین مدل عامل و کدنویسی احساسی گوگل است که تعاملات بصری غنیتر و تعامل عمیقتری را بر پایه استدلال پیشرفته ارائه میدهد.",
|
||||
"gemini-3.1-flash-image-preview.description": "Gemini 3.1 Flash Image (Nano Banana 2) سریعترین مدل تولید تصویر بومی گوگل با پشتیبانی از تفکر، تولید و ویرایش تصویر مکالمهای است.",
|
||||
"gemini-3.1-flash-image-preview:image.description": "Gemini 3.1 Flash Image (Nano Banana 2) کیفیت تصویر در سطح حرفهای را با سرعت Flash و پشتیبانی از چت چندوجهی ارائه میدهد.",
|
||||
"gemini-3.1-flash-image-preview:image.description": "Gemini 3.1 Flash Image (Nano Banana 2) سریعترین مدل تولید تصویر بومی گوگل است که از تفکر، تولید و ویرایش تصاویر در مکالمات پشتیبانی میکند.",
|
||||
"gemini-3.1-flash-lite-preview.description": "Gemini 3.1 Flash-Lite Preview اقتصادیترین مدل چندوجهی گوگل است که برای وظایف عاملمحور با حجم بالا، ترجمه و پردازش دادهها بهینه شده است.",
|
||||
"gemini-3.1-flash-lite.description": "Gemini 3.1 Flash-Lite اقتصادیترین مدل چندوجهی گوگل است که برای وظایف عاملی با حجم بالا، ترجمه و پردازش داده بهینه شده است.",
|
||||
"gemini-3.1-pro-preview.description": "پیشنمایش Gemini 3.1 Pro قابلیتهای استدلال بهبود یافته را به Gemini 3 Pro اضافه میکند و از سطح تفکر متوسط پشتیبانی میکند.",
|
||||
@@ -734,8 +731,6 @@
|
||||
"grok-4-fast-reasoning.description": "با افتخار Grok 4 Fast را معرفی میکنیم، جدیدترین پیشرفت ما در مدلهای استدلال مقرونبهصرفه.",
|
||||
"grok-4.20-0309-non-reasoning.description": "نسخه بدون استدلال برای کاربردهای ساده.",
|
||||
"grok-4.20-0309-reasoning.description": "مدلی هوشمند و بسیار سریع که قبل از پاسخ استدلال میکند.",
|
||||
"grok-4.20-beta-0309-non-reasoning.description": "نسخه غیرتفکری برای موارد استفاده ساده.",
|
||||
"grok-4.20-beta-0309-reasoning.description": "مدل هوشمند و فوقالعاده سریع که قبل از پاسخدهی استدلال میکند.",
|
||||
"grok-4.20-multi-agent-0309.description": "مجموعهای از ۴ یا ۱۶ ایجنت که در پژوهش عملکرد عالی دارد. در حال حاضر از ابزارهای سمت کاربر پشتیبانی نمیکند و تنها ابزارهای سمت سرور xAI (مانند X Search و Web Search) و ابزارهای MCP از راه دور را پشتیبانی میکند.",
|
||||
"grok-4.3.description": "حقیقتجویانهترین مدل زبان بزرگ در جهان",
|
||||
"grok-4.description": "جدیدترین مدل پرچمدار Grok با عملکرد بینظیر در زبان، ریاضیات و استدلال — یک مدل همهجانبه واقعی. در حال حاضر به grok-4-0709 اشاره دارد؛ به دلیل منابع محدود، قیمت آن موقتاً ۱۰٪ بالاتر از قیمت رسمی است و انتظار میرود به قیمت رسمی بازگردد.",
|
||||
@@ -1220,8 +1215,6 @@
|
||||
"qwq.description": "QwQ یک مدل استدلال در خانواده Qwen است. در مقایسه با مدلهای تنظیمشده با دستورالعمل استاندارد، توانایی تفکر و استدلال آن عملکرد پاییندستی را بهویژه در مسائل دشوار بهطور قابل توجهی بهبود میبخشد. QwQ-32B یک مدل استدلال میانرده است که با مدلهای برتر مانند DeepSeek-R1 و o1-mini رقابت میکند.",
|
||||
"qwq_32b.description": "مدل استدلال میانرده در خانواده Qwen. در مقایسه با مدلهای تنظیمشده با دستورالعمل استاندارد، توانایی تفکر و استدلال QwQ عملکرد پاییندستی را بهویژه در مسائل دشوار بهطور قابل توجهی بهبود میبخشد.",
|
||||
"r1-1776.description": "R1-1776 نسخه پسآموزشی مدل DeepSeek R1 است که برای ارائه اطلاعات واقعی، بدون سانسور و بیطرف طراحی شده است.",
|
||||
"seedance-1-5-pro-251215.description": "Seedance 1.5 Pro توسط ByteDance از متن به ویدئو، تصویر به ویدئو (فریم اول، فریم اول+آخر) و تولید صدا همگام با تصاویر پشتیبانی میکند.",
|
||||
"seedream-5-0-260128.description": "ByteDance-Seedream-5.0-lite توسط BytePlus دارای تولید تقویتشده با بازیابی وب برای اطلاعات بلادرنگ، تفسیر پیشرفته دستورات پیچیده و بهبود سازگاری مرجع برای خلق بصری حرفهای است.",
|
||||
"solar-mini-ja.description": "Solar Mini (ژاپنی) نسخهای از Solar Mini با تمرکز بر زبان ژاپنی است که در عین حال عملکرد قوی و کارآمدی در زبانهای انگلیسی و کرهای حفظ میکند.",
|
||||
"solar-mini.description": "Solar Mini یک مدل زبانی فشرده است که عملکردی بهتر از GPT-3.5 دارد و با پشتیبانی چندزبانه قوی از زبانهای انگلیسی و کرهای، راهحلی کارآمد با حجم کم ارائه میدهد.",
|
||||
"solar-pro.description": "Solar Pro یک مدل زبانی هوشمند از Upstage است که برای پیروی از دستورالعملها روی یک GPU طراحی شده و امتیاز IFEval بالای ۸۰ دارد. در حال حاضر از زبان انگلیسی پشتیبانی میکند؛ انتشار کامل آن برای نوامبر ۲۰۲۴ با پشتیبانی زبانی گستردهتر و زمینه طولانیتر برنامهریزی شده است.",
|
||||
|
||||
@@ -27,6 +27,13 @@
|
||||
"agent.layout.skipConfirm.ok": "فعلاً رد کن",
|
||||
"agent.layout.skipConfirm.title": "فعلاً از راهاندازی اولیه رد میشی؟",
|
||||
"agent.layout.switchMessage": "امروز حال و هواشو نداری؟ میتونی به <modeLink><modeText>{{mode}}</modeText></modeLink> یا <skipLink><skipText>{{skip}}</skipText></skipLink> تغییر بدی.",
|
||||
"agent.layout.switchMessageClassic": "امروز حسش نیست؟ میتوانید به <modeLink><modeText>{{mode}}</modeText></modeLink> تغییر دهید.",
|
||||
"agent.messenger.cta.discord": "افزودن به دیسکورد",
|
||||
"agent.messenger.cta.slack": "افزودن به اسلک",
|
||||
"agent.messenger.cta.telegram": "باز کردن در تلگرام",
|
||||
"agent.messenger.subtitle": "با نماینده خود در تلگرام، اسلک یا دیسکورد گفتگو کنید",
|
||||
"agent.messenger.telegramQrCaption": "با دوربین گوشی خود اسکن کنید",
|
||||
"agent.messenger.title": "من را هر جا که پیام میدهید، همراه خود داشته باشید",
|
||||
"agent.modeSwitch.agent": "مکالمهای",
|
||||
"agent.modeSwitch.classic": "کلاسیک",
|
||||
"agent.modeSwitch.collapse": "بستن",
|
||||
@@ -68,6 +75,13 @@
|
||||
"agent.wrapUp.confirm.content": "آنچه تا اینجا گفتیم را ذخیره میکنم. هر زمان خواستید میتوانید برگردید و ادامه دهید.",
|
||||
"agent.wrapUp.confirm.ok": "همین حالا تمام کن",
|
||||
"agent.wrapUp.confirm.title": "آیا میخواهید روند آشنایی را همین حالا تمام کنید؟",
|
||||
"agentPicker.allCategories": "همه",
|
||||
"agentPicker.continue": "ادامه",
|
||||
"agentPicker.skip": "فعلاً رد کردن",
|
||||
"agentPicker.subtitle": "چند مورد را اکنون به کتابخانه خود اضافه کنید — هر زمان که خواستید موارد بیشتری کشف کنید.",
|
||||
"agentPicker.title": "بیایید چند نماینده به کتابخانه شما اضافه کنیم",
|
||||
"agentPicker.title2": "مواردی را انتخاب کنید که با نحوه کار شما مطابقت دارند",
|
||||
"agentPicker.title3": "همیشه میتوانید موارد بیشتری اضافه کنید — با چند مورد شروع کنید",
|
||||
"back": "بازگشت",
|
||||
"finish": "شروع کن",
|
||||
"interests.area.business": "کسبوکار و استراتژی",
|
||||
|
||||
@@ -39,8 +39,8 @@
|
||||
"builtins.lobe-agent-documents.inspector.docCount": "{{count}} سند",
|
||||
"builtins.lobe-agent-documents.inspector.opsCount": "{{count}} عملیات",
|
||||
"builtins.lobe-agent-documents.inspector.opsResult": "{{success}}/{{total}} عملیات",
|
||||
"builtins.lobe-agent-documents.inspector.target.agent": "در عامل",
|
||||
"builtins.lobe-agent-documents.inspector.target.currentTopic": "در موضوع",
|
||||
"builtins.lobe-agent-documents.inspector.scope.agent": "در عامل",
|
||||
"builtins.lobe-agent-documents.inspector.scope.currentTopic": "در موضوع",
|
||||
"builtins.lobe-agent-documents.title": "اسناد عامل",
|
||||
"builtins.lobe-agent-management.apiName.callAgent": "نماینده تماس",
|
||||
"builtins.lobe-agent-management.apiName.createAgent": "ایجاد نماینده",
|
||||
@@ -90,6 +90,14 @@
|
||||
"builtins.lobe-agent.title": "عامل لوب",
|
||||
"builtins.lobe-claude-code.agent.instruction": "دستورالعمل",
|
||||
"builtins.lobe-claude-code.agent.result": "نتیجه",
|
||||
"builtins.lobe-claude-code.task.createLabel": "ایجاد وظیفه: ",
|
||||
"builtins.lobe-claude-code.task.getLabel": "بررسی وظیفه #{{taskId}}",
|
||||
"builtins.lobe-claude-code.task.listLabel": "فهرست وظایف",
|
||||
"builtins.lobe-claude-code.task.updateCompleted": "تکمیل شده",
|
||||
"builtins.lobe-claude-code.task.updateDeleted": "حذف شده",
|
||||
"builtins.lobe-claude-code.task.updateInProgress": "شروع شده",
|
||||
"builtins.lobe-claude-code.task.updateLabel": "بهروزرسانی وظیفه #{{taskId}}",
|
||||
"builtins.lobe-claude-code.task.updatePending": "بازنشانی",
|
||||
"builtins.lobe-claude-code.todoWrite.allDone": "همه کارها انجام شدند",
|
||||
"builtins.lobe-claude-code.todoWrite.currentStep": "مرحلهی فعلی",
|
||||
"builtins.lobe-claude-code.todoWrite.todos": "کارها",
|
||||
|
||||
@@ -33,7 +33,6 @@
|
||||
"jina.description": "Jina AI که در سال 2020 تأسیس شد، یک شرکت پیشرو در زمینه جستجوی هوش مصنوعی است. پشته جستجوی آن شامل مدلهای برداری، رتبهبندها و مدلهای زبانی کوچک برای ساخت اپلیکیشنهای جستجوی مولد و چندوجهی با کیفیت بالا است.",
|
||||
"kimicodingplan.description": "Kimi Code از Moonshot AI دسترسی به مدلهای Kimi شامل K2.5 را برای وظایف کدنویسی فراهم میکند.",
|
||||
"lmstudio.description": "LM Studio یک اپلیکیشن دسکتاپ برای توسعه و آزمایش مدلهای زبانی بزرگ روی رایانه شخصی شماست.",
|
||||
"lobehub.description": "LobeHub Cloud از APIهای رسمی برای دسترسی به مدلهای هوش مصنوعی استفاده میکند و مصرف را با اعتباراتی که به توکنهای مدل مرتبط هستند، اندازهگیری میکند.",
|
||||
"longcat.description": "لانگکت مجموعهای از مدلهای بزرگ هوش مصنوعی تولیدی است که بهطور مستقل توسط میتوآن توسعه داده شده است. این مدلها برای افزایش بهرهوری داخلی شرکت و امکانپذیر کردن کاربردهای نوآورانه از طریق معماری محاسباتی کارآمد و قابلیتهای چندوجهی قدرتمند طراحی شدهاند.",
|
||||
"minimax.description": "MiniMax که در سال 2021 تأسیس شد، هوش مصنوعی چندمنظوره با مدلهای پایه چندوجهی از جمله مدلهای متنی با پارامترهای تریلیونی، مدلهای گفتاری و تصویری توسعه میدهد و اپهایی مانند Hailuo AI را ارائه میکند.",
|
||||
"minimaxcodingplan.description": "طرح توکن MiniMax دسترسی به مدلهای MiniMax شامل M2.7 را برای وظایف کدنویسی از طریق اشتراک با هزینه ثابت فراهم میکند.",
|
||||
|
||||
@@ -55,6 +55,12 @@
|
||||
"credits.autoTopUp.toggle": "فعال کردن شارژ خودکار",
|
||||
"credits.autoTopUp.upgradeHint": "برای فعال کردن شارژ خودکار به یک طرح پولی اشتراک بگیرید",
|
||||
"credits.autoTopUp.validation.targetMustExceedThreshold": "موجودی هدف باید بیشتر از آستانه باشد",
|
||||
"credits.costEstimateHint.desc": "قبل از ارسال، هنگامی که هزینه تخمینی مدل به آستانه شما میرسد، یک هشدار سبک نمایش دهید",
|
||||
"credits.costEstimateHint.saveError": "ذخیره تنظیمات هشدار هزینه تخمینی ناموفق بود",
|
||||
"credits.costEstimateHint.saveSuccess": "تنظیمات هشدار هزینه تخمینی ذخیره شد",
|
||||
"credits.costEstimateHint.threshold": "آستانه هشدار",
|
||||
"credits.costEstimateHint.title": "هشدار هزینه تخمینی",
|
||||
"credits.costEstimateHint.validation.threshold": "آستانه باید بزرگتر یا مساوی با ۰ باشد",
|
||||
"credits.packages.auto": "خودکار",
|
||||
"credits.packages.charged": "شارژ شده ${{amount}}",
|
||||
"credits.packages.expired": "منقضی شده",
|
||||
|
||||
@@ -40,6 +40,14 @@
|
||||
"agentMarketplace.render.alreadyInLibraryTag": "قبلاً در کتابخانه",
|
||||
"agentMarketplace.render.alreadyInLibrary_one": "{{count}} قبلاً در کتابخانه",
|
||||
"agentMarketplace.render.alreadyInLibrary_other": "{{count}} قبلاً در کتابخانه",
|
||||
"claudeCode.askUserQuestion.escape.back": "بازگشت به گزینهها",
|
||||
"claudeCode.askUserQuestion.escape.enter": "یا مستقیماً تایپ کنید",
|
||||
"claudeCode.askUserQuestion.escape.placeholder": "پاسخ خود را اینجا تایپ کنید…",
|
||||
"claudeCode.askUserQuestion.multiSelectTag": "(چند انتخابی)",
|
||||
"claudeCode.askUserQuestion.skip": "رد کردن",
|
||||
"claudeCode.askUserQuestion.submit": "ارسال",
|
||||
"claudeCode.askUserQuestion.timeExpired": "زمان به پایان رسید — استفاده از گزینه ۱ برای هر سوال.",
|
||||
"claudeCode.askUserQuestion.timeRemaining": "زمان باقیمانده: {{time}} · سوالات بیپاسخ به طور پیشفرض به گزینه ۱ در زمان پایان تنظیم میشوند.",
|
||||
"codeInterpreter-legacy.error": "خطای اجرا",
|
||||
"codeInterpreter-legacy.executing": "در حال اجرا...",
|
||||
"codeInterpreter-legacy.files": "فایلها:",
|
||||
|
||||
@@ -56,6 +56,7 @@
|
||||
"renameModal.title": "تغییر نام موضوع",
|
||||
"searchPlaceholder": "جستجوی گفتوگوها...",
|
||||
"searchResultEmpty": "نتیجهای برای جستجو یافت نشد.",
|
||||
"sidebar.title": "موضوعات",
|
||||
"taskManager.agent": "عامل وظایف",
|
||||
"taskManager.welcome": "در مورد کارهایت از من بپرس",
|
||||
"temp": "موقت",
|
||||
|
||||
@@ -220,6 +220,13 @@
|
||||
"inbox.title": "Lobe IA",
|
||||
"input.addAi": "Ajouter un message IA",
|
||||
"input.addUser": "Ajouter un message utilisateur",
|
||||
"input.costEstimate.creditsPerMillionTokens": "{{credits}} crédits/M tokens",
|
||||
"input.costEstimate.hint": "Coût estimé : ~{{credits}} crédits",
|
||||
"input.costEstimate.inputLabel": "Entrée",
|
||||
"input.costEstimate.outputLabel": "Sortie",
|
||||
"input.costEstimate.settingsLink": "Ajuster le seuil d'avertissement",
|
||||
"input.costEstimate.tokenCount": "~{{tokens}} tokens",
|
||||
"input.costEstimate.tooltip": "Estimé à partir du contexte actuel, des outils et des tarifs du modèle. Le coût réel peut varier.",
|
||||
"input.disclaimer": "Les agents peuvent faire des erreurs. Faites preuve de discernement pour les informations critiques.",
|
||||
"input.errorMsg": "Échec de l’envoi : {{errorMsg}}. Réessayez ou envoyez plus tard.",
|
||||
"input.more": "Plus",
|
||||
@@ -779,6 +786,7 @@
|
||||
"upload.preview.prepareTasks": "Préparation des segments...",
|
||||
"upload.preview.status.pending": "Préparation au téléversement...",
|
||||
"upload.preview.status.processing": "Traitement du fichier...",
|
||||
"upload.validation.unsupportedFileType": "Type de fichier non pris en charge : {{files}}. Images prises en charge : JPG, PNG, GIF, WebP. Les documents pris en charge incluent PDF, Word, Excel, PowerPoint, Markdown, texte, CSV, JSON et fichiers de code.",
|
||||
"upload.validation.videoSizeExceeded": "La taille du fichier vidéo ne doit pas dépasser 20 Mo. Taille actuelle : {{actualSize}}.",
|
||||
"viewMode.fullWidth": "Pleine largeur",
|
||||
"viewMode.normal": "Standard",
|
||||
@@ -894,6 +902,8 @@
|
||||
"workingPanel.localFile.closeOther": "Fermer les autres",
|
||||
"workingPanel.localFile.closeRight": "Fermer à droite",
|
||||
"workingPanel.localFile.error": "Impossible de charger ce fichier",
|
||||
"workingPanel.localFile.preview.raw": "Brut",
|
||||
"workingPanel.localFile.preview.render": "Aperçu",
|
||||
"workingPanel.localFile.truncated": "Aperçu du fichier tronqué à {{limit}} caractères",
|
||||
"workingPanel.progress": "Progress",
|
||||
"workingPanel.progress.allCompleted": "All tasks completed",
|
||||
@@ -959,6 +969,8 @@
|
||||
"workingPanel.review.viewMode.unified": "Passer à la vue unifiée",
|
||||
"workingPanel.review.wordWrap.disable": "Désactiver le retour à la ligne",
|
||||
"workingPanel.review.wordWrap.enable": "Activer le retour à la ligne",
|
||||
"workingPanel.skills.empty": "Aucune compétence trouvée dans ce projet",
|
||||
"workingPanel.skills.title": "Compétences",
|
||||
"workingPanel.space": "Espace",
|
||||
"workingPanel.title": "Working Panel",
|
||||
"you": "Vous",
|
||||
|
||||
@@ -121,6 +121,16 @@
|
||||
"ModelSwitchPanel.detail.context": "Longueur du contexte",
|
||||
"ModelSwitchPanel.detail.pricing": "Tarification",
|
||||
"ModelSwitchPanel.detail.pricing.cachedInput": "Entrée en cache ${{amount}}/M",
|
||||
"ModelSwitchPanel.detail.pricing.credits.cachedInput": "Entrée mise en cache {{amount}} crédits/M tokens",
|
||||
"ModelSwitchPanel.detail.pricing.credits.image": "crédits/img",
|
||||
"ModelSwitchPanel.detail.pricing.credits.input": "Entrée {{amount}} crédits/M tokens",
|
||||
"ModelSwitchPanel.detail.pricing.credits.megapixel": "crédits/MP",
|
||||
"ModelSwitchPanel.detail.pricing.credits.millionCharacters": "crédits/M caractères",
|
||||
"ModelSwitchPanel.detail.pricing.credits.millionTokens": "crédits/M tokens",
|
||||
"ModelSwitchPanel.detail.pricing.credits.output": "Sortie {{amount}} crédits/M tokens",
|
||||
"ModelSwitchPanel.detail.pricing.credits.perImage": "~ {{amount}} crédits / image",
|
||||
"ModelSwitchPanel.detail.pricing.credits.perVideo": "~ {{amount}} crédits / vidéo",
|
||||
"ModelSwitchPanel.detail.pricing.credits.second": "crédits/s",
|
||||
"ModelSwitchPanel.detail.pricing.group.audio": "Audio",
|
||||
"ModelSwitchPanel.detail.pricing.group.image": "Image",
|
||||
"ModelSwitchPanel.detail.pricing.group.text": "Texte",
|
||||
|
||||
@@ -1,8 +1,10 @@
|
||||
{
|
||||
"actionTag.category.command": "Commande",
|
||||
"actionTag.category.projectSkill": "Compétence de projet",
|
||||
"actionTag.category.skill": "Compétence",
|
||||
"actionTag.category.tool": "Outil",
|
||||
"actionTag.tooltip.command": "Exécute une commande slash côté client avant l’envoi.",
|
||||
"actionTag.tooltip.projectSkill": "Envoyé comme une invocation par barre oblique pour que le CLI de l'agent exécute la compétence de projet correspondante.",
|
||||
"actionTag.tooltip.skill": "Charge un paquet de compétences réutilisable pour cette requête.",
|
||||
"actionTag.tooltip.tool": "Marque un outil que l’utilisateur a explicitement sélectionné pour cette requête.",
|
||||
"actions.expand.off": "Réduire",
|
||||
|
||||
@@ -11,6 +11,19 @@
|
||||
"brief.action.ignore": "Ignorer",
|
||||
"brief.action.retry": "Réessayer",
|
||||
"brief.addFeedback": "Partager un retour",
|
||||
"brief.agentSignal.selfReview.applied.heading": "Mis à jour",
|
||||
"brief.agentSignal.selfReview.applied.summary": "{{count}} mise à jour de rêve a été appliquée.",
|
||||
"brief.agentSignal.selfReview.applied.summary_plural": "{{count}} mises à jour de rêve ont été appliquées.",
|
||||
"brief.agentSignal.selfReview.applied.title": "Ressources de rêve mises à jour",
|
||||
"brief.agentSignal.selfReview.error.heading": "Problème",
|
||||
"brief.agentSignal.selfReview.error.summary": "Certains travaux n'ont pas pu être terminés pendant ce rêve.",
|
||||
"brief.agentSignal.selfReview.error.title": "Le rêve a rencontré un problème",
|
||||
"brief.agentSignal.selfReview.ideas.summary": "Notes de rêve enregistrées pour une révision future.",
|
||||
"brief.agentSignal.selfReview.ideas.title": "Notes de rêve",
|
||||
"brief.agentSignal.selfReview.proposal.heading": "Suggestion",
|
||||
"brief.agentSignal.selfReview.proposal.summary": "{{count}} suggestion de rêve nécessite votre révision.",
|
||||
"brief.agentSignal.selfReview.proposal.summary_plural": "{{count}} suggestions de rêve nécessitent votre révision.",
|
||||
"brief.agentSignal.selfReview.proposal.title": "Suggestion de rêve à réviser",
|
||||
"brief.collapse": "Afficher moins",
|
||||
"brief.commentPlaceholder": "Partagez votre retour...",
|
||||
"brief.commentSubmit": "Envoyer le retour",
|
||||
|
||||
@@ -1,8 +1,6 @@
|
||||
{
|
||||
"addUserMessage.desc": "Ajouter l'entrée actuelle comme message utilisateur sans déclencher la génération",
|
||||
"addUserMessage.title": "Ajouter un message utilisateur",
|
||||
"clearCurrentMessages.desc": "Effacer les messages et les fichiers téléchargés de la conversation en cours",
|
||||
"clearCurrentMessages.title": "Effacer les messages de la conversation",
|
||||
"commandPalette.desc": "Ouvrir la palette de commandes globale pour un accès rapide aux fonctionnalités",
|
||||
"commandPalette.title": "Palette de commandes",
|
||||
"deleteAndRegenerateMessage.desc": "Supprimer le dernier message et le régénérer",
|
||||
|
||||
+13
-20
@@ -106,7 +106,6 @@
|
||||
"MiniMax-Hailuo-2.3.description": "Nouveau modèle de génération vidéo avec des améliorations complètes dans les mouvements corporels, le réalisme physique et le suivi des instructions.",
|
||||
"MiniMax-M1.description": "Un nouveau modèle de raisonnement interne avec 80 000 chaînes de pensée et 1 million d’entrées, offrant des performances comparables aux meilleurs modèles mondiaux.",
|
||||
"MiniMax-M2-Stable.description": "Conçu pour un codage efficace et des flux de travail d’agents, avec une plus grande simultanéité pour un usage commercial.",
|
||||
"MiniMax-M2.1-Lightning.description": "Capacités de programmation multilingues puissantes avec une inférence plus rapide et plus efficace.",
|
||||
"MiniMax-M2.1-highspeed.description": "Des capacités de programmation multilingues puissantes, offrant une expérience de programmation entièrement améliorée. Plus rapide et plus efficace.",
|
||||
"MiniMax-M2.1.description": "MiniMax-M2.1 est un modèle phare open source de MiniMax, conçu pour résoudre des tâches complexes du monde réel. Ses principaux atouts résident dans ses capacités de programmation multilingue et sa faculté à résoudre des problèmes complexes en tant qu'agent.",
|
||||
"MiniMax-M2.5-highspeed.description": "MiniMax M2.5 Highspeed : Même performance que M2.5 avec une inférence plus rapide.",
|
||||
@@ -315,13 +314,13 @@
|
||||
"claude-3-haiku-20240307.description": "Claude 3 Haiku est le modèle le plus rapide et le plus compact d’Anthropic, conçu pour des réponses quasi instantanées avec des performances rapides et précises.",
|
||||
"claude-3-opus-20240229.description": "Claude 3 Opus est le modèle le plus puissant d’Anthropic pour les tâches complexes, excellent en performance, intelligence, fluidité et compréhension.",
|
||||
"claude-3-sonnet-20240229.description": "Claude 3 Sonnet équilibre intelligence et rapidité pour les charges de travail en entreprise, offrant une grande utilité à moindre coût et un déploiement fiable à grande échelle.",
|
||||
"claude-haiku-4-5-20251001.description": "Claude Haiku 4.5 est le modèle Haiku le plus rapide et le plus intelligent d'Anthropic, avec une vitesse fulgurante et une réflexion approfondie.",
|
||||
"claude-haiku-4-5-20251001.description": "Claude Haiku 4.5 est le modèle Haiku le plus rapide et le plus intelligent d’Anthropic, avec une vitesse fulgurante et un raisonnement étendu.",
|
||||
"claude-haiku-4-5.description": "Claude Haiku 4.5 par Anthropic — modèle Haiku de nouvelle génération avec un raisonnement et une vision améliorés.",
|
||||
"claude-haiku-4.5.description": "Claude Haiku 4.5 est le modèle Haiku le plus rapide et le plus intelligent d’Anthropic, avec une vitesse fulgurante et un raisonnement étendu.",
|
||||
"claude-opus-4-1-20250805-thinking.description": "Claude Opus 4.1 Thinking est une variante avancée capable de révéler son processus de raisonnement.",
|
||||
"claude-opus-4-1-20250805.description": "Claude Opus 4.1 est le dernier modèle d'Anthropic, le plus performant pour les tâches hautement complexes, excelle en performance, intelligence, fluidité et compréhension.",
|
||||
"claude-opus-4-1-20250805.description": "Claude Opus 4.1 est le modèle le plus récent et le plus performant d’Anthropic pour les tâches hautement complexes, excelling en performance, intelligence, fluidité et compréhension.",
|
||||
"claude-opus-4-1.description": "Claude Opus 4.1 par Anthropic — modèle de raisonnement premium avec des capacités d'analyse approfondie.",
|
||||
"claude-opus-4-20250514.description": "Claude Opus 4 est le modèle le plus puissant d'Anthropic pour les tâches hautement complexes, excelle en performance, intelligence, fluidité et compréhension.",
|
||||
"claude-opus-4-20250514.description": "Claude Opus 4 est le modèle le plus puissant d’Anthropic pour les tâches hautement complexes, excelling en performance, intelligence, fluidité et compréhension.",
|
||||
"claude-opus-4-5-20251101.description": "Claude Opus 4.5 est le modèle phare d’Anthropic, combinant intelligence exceptionnelle et performance évolutive, idéal pour les tâches complexes nécessitant des réponses et un raisonnement de très haute qualité.",
|
||||
"claude-opus-4-5.description": "Claude Opus 4.5 par Anthropic — modèle phare avec un raisonnement et un codage de premier ordre.",
|
||||
"claude-opus-4-6.description": "Claude Opus 4.6 par Anthropic — modèle phare avec une fenêtre de contexte de 1M et un raisonnement avancé.",
|
||||
@@ -330,8 +329,8 @@
|
||||
"claude-opus-4.6-fast.description": "Claude Opus 4.6 est le modèle le plus intelligent d’Anthropic pour la création d’agents et le codage.",
|
||||
"claude-opus-4.6.description": "Claude Opus 4.6 est le modèle le plus intelligent d’Anthropic pour la création d’agents et le codage.",
|
||||
"claude-sonnet-4-20250514-thinking.description": "Claude Sonnet 4 Thinking peut produire des réponses quasi instantanées ou une réflexion détaillée étape par étape avec un processus visible.",
|
||||
"claude-sonnet-4-20250514.description": "Claude Sonnet 4 est le modèle le plus intelligent d'Anthropic à ce jour, offrant des réponses quasi-instantanées ou une réflexion détaillée étape par étape avec un contrôle précis pour les utilisateurs d'API.",
|
||||
"claude-sonnet-4-5-20250929.description": "Claude Sonnet 4.5 est le modèle le plus intelligent d'Anthropic à ce jour.",
|
||||
"claude-sonnet-4-20250514.description": "Claude Sonnet 4 peut produire des réponses quasi instantanées ou un raisonnement détaillé étape par étape avec un processus visible.",
|
||||
"claude-sonnet-4-5-20250929.description": "Claude Sonnet 4.5 est le modèle le plus intelligent d’Anthropic à ce jour.",
|
||||
"claude-sonnet-4-5.description": "Claude Sonnet 4.5 par Anthropic — Sonnet amélioré avec des performances de codage accrues.",
|
||||
"claude-sonnet-4-6.description": "Claude Sonnet 4.6 par Anthropic — dernier modèle Sonnet avec un codage supérieur et une utilisation d'outils avancée.",
|
||||
"claude-sonnet-4.5.description": "Claude Sonnet 4.5 est le modèle le plus intelligent d’Anthropic à ce jour.",
|
||||
@@ -404,7 +403,7 @@
|
||||
"deepseek-ai/deepseek-llm-67b-chat.description": "DeepSeek LLM Chat (67B) est un modèle innovant offrant une compréhension linguistique approfondie et une interaction fluide.",
|
||||
"deepseek-ai/deepseek-v3.1-terminus.description": "DeepSeek V3.1 est un modèle de raisonnement nouvelle génération avec un raisonnement complexe renforcé et une chaîne de pensée pour les tâches d’analyse approfondie.",
|
||||
"deepseek-ai/deepseek-v3.2.description": "DeepSeek V3.2 est un modèle de raisonnement de nouvelle génération avec des capacités renforcées de raisonnement complexe et de chaîne de pensée.",
|
||||
"deepseek-chat.description": "Alias de compatibilité pour le mode non-réflexif de DeepSeek V4 Flash. Prévu pour être déprécié — utilisez DeepSeek V4 Flash à la place.",
|
||||
"deepseek-chat.description": "Un nouveau modèle open-source combinant des capacités générales et de codage. Il conserve le dialogue général du modèle de chat et les solides compétences en codage du modèle de programmeur, avec un meilleur alignement des préférences. DeepSeek-V2.5 améliore également l’écriture et le suivi des instructions.",
|
||||
"deepseek-coder-33B-instruct.description": "DeepSeek Coder 33B est un modèle de langage pour le code entraîné sur 2T de tokens (87 % de code, 13 % de texte en chinois/anglais). Il introduit une fenêtre de contexte de 16K et des tâches de remplissage au milieu, offrant une complétion de code à l’échelle du projet et un remplissage de fragments.",
|
||||
"deepseek-coder-v2.description": "DeepSeek Coder V2 est un modèle de code MoE open source performant sur les tâches de programmation, comparable à GPT-4 Turbo.",
|
||||
"deepseek-coder-v2:236b.description": "DeepSeek Coder V2 est un modèle de code MoE open source performant sur les tâches de programmation, comparable à GPT-4 Turbo.",
|
||||
@@ -426,7 +425,7 @@
|
||||
"deepseek-r1-fast-online.description": "Version complète rapide de DeepSeek R1 avec recherche web en temps réel, combinant des capacités à l’échelle de 671B et des réponses plus rapides.",
|
||||
"deepseek-r1-online.description": "Version complète de DeepSeek R1 avec 671B de paramètres et recherche web en temps réel, offrant une meilleure compréhension et génération.",
|
||||
"deepseek-r1.description": "DeepSeek-R1 utilise des données de démarrage à froid avant l’apprentissage par renforcement et affiche des performances comparables à OpenAI-o1 en mathématiques, codage et raisonnement.",
|
||||
"deepseek-reasoner.description": "Alias de compatibilité pour le mode réflexif de DeepSeek V4 Flash. Prévu pour être déprécié — utilisez DeepSeek V4 Flash à la place.",
|
||||
"deepseek-reasoner.description": "Un modèle de raisonnement DeepSeek axé sur des tâches complexes de raisonnement logique.",
|
||||
"deepseek-v2.description": "DeepSeek V2 est un modèle MoE efficace pour un traitement économique.",
|
||||
"deepseek-v2:236b.description": "DeepSeek V2 236B est le modèle axé sur le code de DeepSeek avec une forte génération de code.",
|
||||
"deepseek-v3-0324.description": "DeepSeek-V3-0324 est un modèle MoE de 671B paramètres avec des points forts en programmation, compréhension du contexte et traitement de longs textes.",
|
||||
@@ -491,8 +490,6 @@
|
||||
"doubao-seedream-4-0-250828.description": "Seedream 4.0 est un modèle de génération d’image de ByteDance Seed, prenant en charge les entrées texte et image avec une génération d’image de haute qualité et hautement contrôlable. Il génère des images à partir d’invites textuelles.",
|
||||
"doubao-seedream-4-5-251128.description": "Seedream 4.5 est le dernier modèle d'image multimodal de ByteDance, intégrant des capacités de génération de texte en image, d'image en image et de génération d'images par lots, tout en incorporant des compétences en raisonnement et en bon sens. Par rapport à la version précédente 4.0, il offre une qualité de génération nettement améliorée, avec une meilleure cohérence d'édition et une fusion multi-images. Il permet un contrôle plus précis des détails visuels, produisant des textes et des visages plus petits de manière plus naturelle, et atteint une mise en page et des couleurs plus harmonieuses, améliorant l'esthétique globale.",
|
||||
"doubao-seedream-5-0-260128.description": "Doubao-Seedream-5.0-lite est le dernier modèle de génération d'images de ByteDance. Pour la première fois, il intègre des capacités de recherche en ligne, lui permettant d'incorporer des informations web en temps réel et d'améliorer la pertinence des images générées. L'intelligence du modèle a également été améliorée, permettant une interprétation précise des instructions complexes et du contenu visuel. De plus, il offre une meilleure couverture des connaissances globales, une cohérence des références et une qualité de génération dans des scénarios professionnels, répondant mieux aux besoins de création visuelle au niveau des entreprises.",
|
||||
"dreamina-seedance-2-0-260128.description": "Seedance 2.0 de ByteDance est le modèle de génération vidéo le plus puissant, prenant en charge la génération de vidéos multimodales de référence, le montage vidéo, l'extension vidéo, la conversion texte en vidéo et image en vidéo avec audio synchronisé.",
|
||||
"dreamina-seedance-2-0-fast-260128.description": "Seedance 2.0 Fast de ByteDance offre les mêmes capacités que Seedance 2.0 avec des vitesses de génération plus rapides à un prix plus compétitif.",
|
||||
"emohaa.description": "Emohaa est un modèle de santé mentale doté de compétences professionnelles en conseil pour aider les utilisateurs à comprendre leurs problèmes émotionnels.",
|
||||
"ernie-4.5-0.3b.description": "ERNIE 4.5 0.3B est un modèle léger open source conçu pour un déploiement local et personnalisé.",
|
||||
"ernie-4.5-8k-preview.description": "ERNIE 4.5 8K Preview est un modèle de prévisualisation avec contexte 8K pour l’évaluation d’ERNIE 4.5.",
|
||||
@@ -506,6 +503,7 @@
|
||||
"ernie-5.0-thinking-latest.description": "Wenxin 5.0 Thinking est un modèle phare natif tout-modal avec modélisation unifiée du texte, de l’image, de l’audio et de la vidéo. Il offre des améliorations majeures pour la QA complexe, la création et les scénarios d’agents.",
|
||||
"ernie-5.0-thinking-preview.description": "Wenxin 5.0 Thinking Preview est un modèle phare natif tout-modal avec modélisation unifiée du texte, de l’image, de l’audio et de la vidéo. Il offre des améliorations majeures pour la QA complexe, la création et les scénarios d’agents.",
|
||||
"ernie-5.0.description": "ERNIE 5.0, le modèle de nouvelle génération de la série ERNIE, est un modèle natif multimodal de grande taille. Il adopte une approche de modélisation multimodale unifiée, modélisant conjointement le texte, les images, l'audio et la vidéo pour offrir des capacités multimodales complètes. Ses capacités fondamentales ont été considérablement améliorées, atteignant des performances élevées lors des évaluations de référence. Il excelle particulièrement dans la compréhension multimodale, le suivi des instructions, l'écriture créative, la précision factuelle, la planification d'agents et l'utilisation d'outils.",
|
||||
"ernie-5.1.description": "ERNIE 5.1 est le dernier modèle de la série ERNIE, avec des améliorations complètes de ses capacités fondamentales. Il démontre des progrès significatifs dans des domaines tels que les agents, le traitement des connaissances, le raisonnement et la recherche approfondie. Cette version adopte une architecture d’apprentissage par renforcement entièrement asynchrone et découplée, spécifiquement conçue pour relever les défis clés de l’évolution des grands modèles vers une prise de décision autonome des agents, y compris les écarts numériques entre l’entraînement et l’inférence, la faible utilisation des ressources informatiques hétérogènes et les problèmes globaux causés par les effets de longue traîne. De plus, des techniques de post-entraînement à grande échelle pour les agents sont employées pour améliorer davantage les capacités et les performances de généralisation du modèle. Grâce à un cadre collaboratif en trois étapes impliquant des processus d’environnement, d’expert et de fusion, l’approche garantit non seulement l’efficacité de l’entraînement, mais améliore également de manière significative la stabilité et les performances du modèle sur des tâches complexes.",
|
||||
"ernie-char-fiction-8k-preview.description": "ERNIE Character Fiction 8K Preview est une préversion de modèle pour la création de personnages et d’intrigues, destinée à l’évaluation des fonctionnalités.",
|
||||
"ernie-char-fiction-8k.description": "ERNIE Character Fiction 8K est un modèle de personnage pour romans et création d’intrigues, adapté à la génération d’histoires longues.",
|
||||
"ernie-image-turbo.description": "ERNIE-Image est un modèle texte-vers-image de 8 milliards de paramètres développé par Baidu. Il se classe parmi les meilleurs sur plusieurs benchmarks, atteignant la première place ex aequo dans SuperCLUE en Chine et en tête dans la catégorie open source.",
|
||||
@@ -517,8 +515,7 @@
|
||||
"ernie-x1-turbo-32k.description": "ERNIE X1 Turbo 32K est un modèle de réflexion rapide avec un contexte de 32K pour le raisonnement complexe et les dialogues multi-tours.",
|
||||
"ernie-x1.1-preview.description": "ERNIE X1.1 Preview est une préversion de modèle de réflexion pour l’évaluation et les tests.",
|
||||
"ernie-x1.1.description": "ERNIE X1.1 est un modèle de réflexion en aperçu pour évaluation et test.",
|
||||
"fal-ai/bytedance/seedream/v4.5.description": "Seedream 4.5, développé par l'équipe Seed de ByteDance, prend en charge l'édition et la composition multi-images. Inclut une meilleure cohérence des sujets, un suivi précis des instructions, une compréhension de la logique spatiale, une expression esthétique, une mise en page de posters et la conception de logos avec un rendu texte-image de haute précision.",
|
||||
"fal-ai/bytedance/seedream/v4.description": "Seedream 4.0, développé par ByteDance Seed, prend en charge les entrées texte et image pour une génération d'images hautement contrôlable et de haute qualité à partir de prompts.",
|
||||
"fal-ai/bytedance/seedream/v4.description": "Seedream 4.0 est un modèle de génération d’images de ByteDance Seed, prenant en charge les entrées texte et image avec une génération d’images hautement contrôlable et de haute qualité. Il génère des images à partir de descriptions textuelles.",
|
||||
"fal-ai/flux-kontext/dev.description": "Modèle FLUX.1 axé sur l’édition d’images, prenant en charge les entrées texte et image.",
|
||||
"fal-ai/flux-pro/kontext.description": "FLUX.1 Kontext [pro] accepte des textes et des images de référence en entrée, permettant des modifications locales ciblées et des transformations globales complexes de scènes.",
|
||||
"fal-ai/flux/krea.description": "Flux Krea [dev] est un modèle de génération d’images avec une préférence esthétique pour des images plus réalistes et naturelles.",
|
||||
@@ -526,8 +523,8 @@
|
||||
"fal-ai/hunyuan-image/v3.description": "Un puissant modèle natif multimodal de génération d’images.",
|
||||
"fal-ai/imagen4/preview.description": "Modèle de génération d’images de haute qualité développé par Google.",
|
||||
"fal-ai/nano-banana.description": "Nano Banana est le modèle multimodal natif le plus récent, le plus rapide et le plus efficace de Google, permettant la génération et l’édition d’images via la conversation.",
|
||||
"fal-ai/qwen-image-edit.description": "Un modèle professionnel d'édition d'images de l'équipe Qwen, prenant en charge les modifications sémantiques et d'apparence, l'édition précise de texte en chinois/anglais, le transfert de style, la rotation et plus encore.",
|
||||
"fal-ai/qwen-image.description": "Un modèle puissant de génération d'images de l'équipe Qwen avec un rendu texte chinois robuste et des styles visuels variés.",
|
||||
"fal-ai/qwen-image-edit.description": "Un modèle professionnel d’édition d’images de l’équipe Qwen qui prend en charge les modifications sémantiques et d’apparence, édite précisément le texte en chinois et en anglais, et permet des modifications de haute qualité telles que le transfert de style et la rotation d’objets.",
|
||||
"fal-ai/qwen-image.description": "Un puissant modèle de génération d’images de l’équipe Qwen avec un rendu impressionnant du texte en chinois et des styles visuels variés.",
|
||||
"flux-1-schnell.description": "Modèle texte-vers-image à 12 milliards de paramètres de Black Forest Labs utilisant la distillation par diffusion latente adversariale pour générer des images de haute qualité en 1 à 4 étapes. Il rivalise avec les alternatives propriétaires et est publié sous licence Apache-2.0 pour un usage personnel, de recherche et commercial.",
|
||||
"flux-dev.description": "Modèle open source de génération d’images destiné à la R&D, optimisé efficacement pour la recherche d’innovation non commerciale.",
|
||||
"flux-kontext-max.description": "Génération et édition d’images contextuelles de pointe, combinant texte et images pour des résultats précis et cohérents.",
|
||||
@@ -566,10 +563,10 @@
|
||||
"gemini-3-flash-preview.description": "Gemini 3 Flash est le modèle le plus intelligent conçu pour la vitesse, alliant intelligence de pointe et ancrage de recherche performant.",
|
||||
"gemini-3-flash.description": "Gemini 3 Flash par Google — modèle ultra-rapide avec prise en charge des entrées multimodales.",
|
||||
"gemini-3-pro-image-preview.description": "Gemini 3 Pro Image (Nano Banana Pro) est le modèle de génération d'images de Google qui prend également en charge le dialogue multimodal.",
|
||||
"gemini-3-pro-image-preview:image.description": "Gemini 3 Pro Image (Nano Banana Pro) est le modèle de génération d'images de Google et prend également en charge le chat multimodal.",
|
||||
"gemini-3-pro-image-preview:image.description": "Gemini 3 Pro Image (Nano Banana Pro) est le modèle de génération d’images de Google et prend également en charge le chat multimodal.",
|
||||
"gemini-3-pro-preview.description": "Gemini 3 Pro est le modèle agent et de codage le plus puissant de Google, offrant des visuels enrichis et une interaction plus poussée grâce à un raisonnement de pointe.",
|
||||
"gemini-3.1-flash-image-preview.description": "Gemini 3.1 Flash Image (Nano Banana 2) est le modèle de génération d'images natif le plus rapide de Google avec prise en charge de la réflexion, génération et édition d'images conversationnelles.",
|
||||
"gemini-3.1-flash-image-preview:image.description": "Gemini 3.1 Flash Image (Nano Banana 2) offre une qualité d'image de niveau Pro à une vitesse Flash avec prise en charge du chat multimodal.",
|
||||
"gemini-3.1-flash-image-preview:image.description": "Gemini 3.1 Flash Image (Nano Banana 2) est le modèle de génération d’images natif le plus rapide de Google, avec prise en charge de la réflexion, génération et édition d’images conversationnelles.",
|
||||
"gemini-3.1-flash-lite-preview.description": "Gemini 3.1 Flash-Lite Preview est le modèle multimodal le plus économique de Google, optimisé pour les tâches agentiques à haut volume, la traduction et le traitement des données.",
|
||||
"gemini-3.1-flash-lite.description": "Gemini 3.1 Flash-Lite est le modèle multimodal le plus économique de Google, optimisé pour les tâches agentiques à haut volume, la traduction et le traitement des données.",
|
||||
"gemini-3.1-pro-preview.description": "Gemini 3.1 Pro Preview améliore Gemini 3 Pro avec des capacités de raisonnement renforcées et ajoute un support de niveau de réflexion moyen.",
|
||||
@@ -734,8 +731,6 @@
|
||||
"grok-4-fast-reasoning.description": "Nous sommes ravis de présenter Grok 4 Fast, notre dernière avancée en matière de modèles de raisonnement économiques.",
|
||||
"grok-4.20-0309-non-reasoning.description": "Une variante sans raisonnement pour des cas d'utilisation simples.",
|
||||
"grok-4.20-0309-reasoning.description": "Modèle intelligent et ultra-rapide qui raisonne avant de répondre.",
|
||||
"grok-4.20-beta-0309-non-reasoning.description": "Une variante non-réflexive pour des cas d'utilisation simples.",
|
||||
"grok-4.20-beta-0309-reasoning.description": "Modèle intelligent et ultra-rapide qui réfléchit avant de répondre.",
|
||||
"grok-4.20-multi-agent-0309.description": "Une équipe de 4 ou 16 agents, excelle dans les cas d'utilisation de recherche. Ne prend actuellement pas en charge les outils côté client. Prend uniquement en charge les outils côté serveur xAI (par exemple X Search, outils de recherche Web) et les outils MCP distants.",
|
||||
"grok-4.3.description": "Le modèle de langage de grande taille le plus axé sur la vérité au monde",
|
||||
"grok-4.description": "Dernier modèle phare Grok avec des performances inégalées en langage, mathématiques et raisonnement — un véritable polyvalent. Actuellement pointé vers grok-4-0709 ; en raison de ressources limitées, son prix est temporairement 10 % plus élevé que le tarif officiel et devrait revenir au prix officiel ultérieurement.",
|
||||
@@ -1220,8 +1215,6 @@
|
||||
"qwq.description": "QwQ est un modèle de raisonnement de la famille Qwen. Comparé aux modèles classiques ajustés par instruction, il apporte des capacités de réflexion et de raisonnement qui améliorent considérablement les performances en aval, notamment sur les problèmes complexes. QwQ-32B est un modèle de raisonnement de taille moyenne qui rivalise avec les meilleurs modèles comme DeepSeek-R1 et o1-mini.",
|
||||
"qwq_32b.description": "Modèle de raisonnement de taille moyenne de la famille Qwen. Comparé aux modèles classiques ajustés par instruction, les capacités de réflexion et de raisonnement de QwQ améliorent considérablement les performances en aval, notamment sur les problèmes complexes.",
|
||||
"r1-1776.description": "R1-1776 est une variante post-entraînée de DeepSeek R1 conçue pour fournir des informations factuelles non censurées et impartiales.",
|
||||
"seedance-1-5-pro-251215.description": "Seedance 1.5 Pro de ByteDance prend en charge la conversion texte en vidéo, image en vidéo (première image, première+dernière image) et la génération audio synchronisée avec les visuels.",
|
||||
"seedream-5-0-260128.description": "ByteDance-Seedream-5.0-lite par BytePlus propose une génération augmentée par récupération web pour des informations en temps réel, une interprétation améliorée des prompts complexes et une meilleure cohérence des références pour la création visuelle professionnelle.",
|
||||
"solar-mini-ja.description": "Solar Mini (Ja) étend Solar Mini avec un accent sur le japonais tout en maintenant des performances efficaces et solides en anglais et en coréen.",
|
||||
"solar-mini.description": "Solar Mini est un modèle LLM compact surpassant GPT-3.5, avec de solides capacités multilingues en anglais et en coréen, offrant une solution efficace à faible empreinte.",
|
||||
"solar-pro.description": "Solar Pro est un LLM intelligent développé par Upstage, axé sur le suivi d'instructions sur un seul GPU, avec des scores IFEval supérieurs à 80. Il prend actuellement en charge l'anglais ; la version complète est prévue pour novembre 2024 avec un support linguistique élargi et un contexte plus long.",
|
||||
|
||||
@@ -27,6 +27,13 @@
|
||||
"agent.layout.skipConfirm.ok": "Passer pour le moment",
|
||||
"agent.layout.skipConfirm.title": "Passer l'initialisation pour l'instant ?",
|
||||
"agent.layout.switchMessage": "Pas d'humeur aujourd'hui ? Vous pouvez passer en <modeLink><modeText>{{mode}}</modeText></modeLink> ou <skipLink><skipText>{{skip}}</skipText></skipLink>.",
|
||||
"agent.layout.switchMessageClassic": "Pas d'humeur aujourd'hui ? Vous pouvez passer à <modeLink><modeText>{{mode}}</modeText></modeLink>.",
|
||||
"agent.messenger.cta.discord": "Ajouter à Discord",
|
||||
"agent.messenger.cta.slack": "Ajouter à Slack",
|
||||
"agent.messenger.cta.telegram": "Ouvrir dans Telegram",
|
||||
"agent.messenger.subtitle": "Discutez avec votre agent sur Telegram, Slack ou Discord",
|
||||
"agent.messenger.telegramQrCaption": "Scannez avec l'appareil photo de votre téléphone",
|
||||
"agent.messenger.title": "Gardez-moi avec vous, où que vous envoyiez des messages",
|
||||
"agent.modeSwitch.agent": "Conversationnel",
|
||||
"agent.modeSwitch.classic": "Classique",
|
||||
"agent.modeSwitch.collapse": "Réduire",
|
||||
@@ -68,6 +75,13 @@
|
||||
"agent.wrapUp.confirm.content": "J’enregistrerai ce que nous avons couvert jusqu’ici. Vous pourrez toujours revenir discuter plus tard.",
|
||||
"agent.wrapUp.confirm.ok": "Terminer maintenant",
|
||||
"agent.wrapUp.confirm.title": "Terminer l’accueil maintenant ?",
|
||||
"agentPicker.allCategories": "Tous",
|
||||
"agentPicker.continue": "Continuer",
|
||||
"agentPicker.skip": "Passer pour l'instant",
|
||||
"agentPicker.subtitle": "Ajoutez-en quelques-uns à votre bibliothèque maintenant — découvrez-en plus à tout moment plus tard.",
|
||||
"agentPicker.title": "Ajoutons quelques agents à votre bibliothèque",
|
||||
"agentPicker.title2": "Choisissez ceux qui correspondent à votre façon de travailler",
|
||||
"agentPicker.title3": "Vous pouvez toujours en ajouter plus tard — commencez par quelques-uns",
|
||||
"back": "Retour",
|
||||
"finish": "Commencer",
|
||||
"interests.area.business": "Affaires & Stratégie",
|
||||
|
||||
@@ -39,8 +39,8 @@
|
||||
"builtins.lobe-agent-documents.inspector.docCount": "{{count}} documents",
|
||||
"builtins.lobe-agent-documents.inspector.opsCount": "{{count}} opérations",
|
||||
"builtins.lobe-agent-documents.inspector.opsResult": "{{success}}/{{total}} opérations",
|
||||
"builtins.lobe-agent-documents.inspector.target.agent": "dans l'agent",
|
||||
"builtins.lobe-agent-documents.inspector.target.currentTopic": "dans le sujet",
|
||||
"builtins.lobe-agent-documents.inspector.scope.agent": "dans l'agent",
|
||||
"builtins.lobe-agent-documents.inspector.scope.currentTopic": "dans le sujet",
|
||||
"builtins.lobe-agent-documents.title": "Documents de l'agent",
|
||||
"builtins.lobe-agent-management.apiName.callAgent": "Appeler un agent",
|
||||
"builtins.lobe-agent-management.apiName.createAgent": "Créer un agent",
|
||||
@@ -90,6 +90,14 @@
|
||||
"builtins.lobe-agent.title": "Agent Lobe",
|
||||
"builtins.lobe-claude-code.agent.instruction": "Consigne",
|
||||
"builtins.lobe-claude-code.agent.result": "Résultat",
|
||||
"builtins.lobe-claude-code.task.createLabel": "Création de tâche : ",
|
||||
"builtins.lobe-claude-code.task.getLabel": "Inspection de la tâche #{{taskId}}",
|
||||
"builtins.lobe-claude-code.task.listLabel": "Liste des tâches",
|
||||
"builtins.lobe-claude-code.task.updateCompleted": "Terminée",
|
||||
"builtins.lobe-claude-code.task.updateDeleted": "Supprimée",
|
||||
"builtins.lobe-claude-code.task.updateInProgress": "Commencée",
|
||||
"builtins.lobe-claude-code.task.updateLabel": "Mise à jour de la tâche #{{taskId}}",
|
||||
"builtins.lobe-claude-code.task.updatePending": "Réinitialisée",
|
||||
"builtins.lobe-claude-code.todoWrite.allDone": "Toutes les tâches sont terminées",
|
||||
"builtins.lobe-claude-code.todoWrite.currentStep": "Étape actuelle",
|
||||
"builtins.lobe-claude-code.todoWrite.todos": "Tâches",
|
||||
|
||||
@@ -33,7 +33,6 @@
|
||||
"jina.description": "Fondée en 2020, Jina AI est une entreprise leader en IA de recherche. Sa pile technologique comprend des modèles vectoriels, des rerankers et de petits modèles linguistiques pour créer des applications de recherche générative et multimodale fiables et de haute qualité.",
|
||||
"kimicodingplan.description": "Kimi Code de Moonshot AI offre un accès aux modèles Kimi, y compris K2.5, pour des tâches de codage.",
|
||||
"lmstudio.description": "LM Studio est une application de bureau pour développer et expérimenter avec des LLMs sur votre ordinateur.",
|
||||
"lobehub.description": "LobeHub Cloud utilise des API officielles pour accéder aux modèles d'IA et mesure l'utilisation avec des Crédits liés aux jetons des modèles.",
|
||||
"longcat.description": "LongCat est une série de grands modèles d'IA générative développés indépendamment par Meituan. Elle est conçue pour améliorer la productivité interne de l'entreprise et permettre des applications innovantes grâce à une architecture informatique efficace et de puissantes capacités multimodales.",
|
||||
"minimax.description": "Fondée en 2021, MiniMax développe une IA généraliste avec des modèles fondamentaux multimodaux, incluant des modèles texte MoE à un billion de paramètres, des modèles vocaux et visuels, ainsi que des applications comme Hailuo AI.",
|
||||
"minimaxcodingplan.description": "Le plan de jetons MiniMax offre un accès aux modèles MiniMax, y compris M2.7, pour des tâches de codage via un abonnement à tarif fixe.",
|
||||
|
||||
@@ -55,6 +55,12 @@
|
||||
"credits.autoTopUp.toggle": "Activer la recharge automatique",
|
||||
"credits.autoTopUp.upgradeHint": "Abonnez-vous à un plan payant pour activer la recharge automatique",
|
||||
"credits.autoTopUp.validation.targetMustExceedThreshold": "Le solde cible doit être supérieur au seuil",
|
||||
"credits.costEstimateHint.desc": "Afficher un avertissement léger avant l'envoi lorsque le coût estimé du modèle atteint votre seuil",
|
||||
"credits.costEstimateHint.saveError": "Échec de l'enregistrement des paramètres d'alerte de l'estimation des coûts",
|
||||
"credits.costEstimateHint.saveSuccess": "Paramètres d'alerte de l'estimation des coûts enregistrés",
|
||||
"credits.costEstimateHint.threshold": "Seuil d'avertissement",
|
||||
"credits.costEstimateHint.title": "Alerte d'estimation des coûts",
|
||||
"credits.costEstimateHint.validation.threshold": "Le seuil doit être supérieur ou égal à 0",
|
||||
"credits.packages.auto": "Automatique",
|
||||
"credits.packages.charged": "Facturé ${{amount}}",
|
||||
"credits.packages.expired": "Expiré",
|
||||
|
||||
@@ -40,6 +40,14 @@
|
||||
"agentMarketplace.render.alreadyInLibraryTag": "Déjà dans la bibliothèque",
|
||||
"agentMarketplace.render.alreadyInLibrary_one": "{{count}} déjà dans la bibliothèque",
|
||||
"agentMarketplace.render.alreadyInLibrary_other": "{{count}} déjà dans la bibliothèque",
|
||||
"claudeCode.askUserQuestion.escape.back": "Retour aux options",
|
||||
"claudeCode.askUserQuestion.escape.enter": "Ou tapez directement",
|
||||
"claudeCode.askUserQuestion.escape.placeholder": "Tapez votre réponse ici…",
|
||||
"claudeCode.askUserQuestion.multiSelectTag": "(sélection multiple)",
|
||||
"claudeCode.askUserQuestion.skip": "Passer",
|
||||
"claudeCode.askUserQuestion.submit": "Soumettre",
|
||||
"claudeCode.askUserQuestion.timeExpired": "Temps écoulé — utilisation de l'option 1 pour chaque question.",
|
||||
"claudeCode.askUserQuestion.timeRemaining": "Temps restant : {{time}} · les questions sans réponse par défaut passent à l'option 1 à l'expiration.",
|
||||
"codeInterpreter-legacy.error": "Erreur d'exécution",
|
||||
"codeInterpreter-legacy.executing": "Exécution en cours...",
|
||||
"codeInterpreter-legacy.files": "Fichiers :",
|
||||
|
||||
@@ -56,6 +56,7 @@
|
||||
"renameModal.title": "Renommer le sujet",
|
||||
"searchPlaceholder": "Rechercher des sujets...",
|
||||
"searchResultEmpty": "Aucun résultat trouvé.",
|
||||
"sidebar.title": "Sujets",
|
||||
"taskManager.agent": "Agent de tâches",
|
||||
"taskManager.welcome": "Demandez-moi à propos de vos tâches",
|
||||
"temp": "Temporaire",
|
||||
|
||||
@@ -220,6 +220,13 @@
|
||||
"inbox.title": "Lobe AI",
|
||||
"input.addAi": "Aggiungi un messaggio AI",
|
||||
"input.addUser": "Aggiungi un messaggio utente",
|
||||
"input.costEstimate.creditsPerMillionTokens": "{{credits}} crediti/M token",
|
||||
"input.costEstimate.hint": "Costo stimato: ~{{credits}} crediti",
|
||||
"input.costEstimate.inputLabel": "Input",
|
||||
"input.costEstimate.outputLabel": "Output",
|
||||
"input.costEstimate.settingsLink": "Regola la soglia di avviso",
|
||||
"input.costEstimate.tokenCount": "~{{tokens}} token",
|
||||
"input.costEstimate.tooltip": "Stimato dal contesto attuale, dagli strumenti e dai prezzi del modello. Il costo effettivo potrebbe variare.",
|
||||
"input.disclaimer": "Gli agenti possono commettere errori. Usa il tuo giudizio per informazioni critiche.",
|
||||
"input.errorMsg": "Invio non riuscito: {{errorMsg}}. Riprova o invia più tardi.",
|
||||
"input.more": "Altro",
|
||||
@@ -779,6 +786,7 @@
|
||||
"upload.preview.prepareTasks": "Preparazione segmenti...",
|
||||
"upload.preview.status.pending": "Preparazione al caricamento...",
|
||||
"upload.preview.status.processing": "Elaborazione file...",
|
||||
"upload.validation.unsupportedFileType": "Tipo di file non supportato: {{files}}. Immagini supportate: JPG, PNG, GIF, WebP. Documenti supportati includono PDF, Word, Excel, PowerPoint, Markdown, testo, CSV, JSON e file di codice.",
|
||||
"upload.validation.videoSizeExceeded": "La dimensione del file video non deve superare i 20MB. Dimensione attuale: {{actualSize}}.",
|
||||
"viewMode.fullWidth": "Larghezza completa",
|
||||
"viewMode.normal": "Standard",
|
||||
@@ -894,6 +902,8 @@
|
||||
"workingPanel.localFile.closeOther": "Chiudi Altri",
|
||||
"workingPanel.localFile.closeRight": "Chiudi a Destra",
|
||||
"workingPanel.localFile.error": "Impossibile caricare questo file",
|
||||
"workingPanel.localFile.preview.raw": "Grezzo",
|
||||
"workingPanel.localFile.preview.render": "Anteprima",
|
||||
"workingPanel.localFile.truncated": "Anteprima del file troncata a {{limit}} caratteri",
|
||||
"workingPanel.progress": "Progress",
|
||||
"workingPanel.progress.allCompleted": "All tasks completed",
|
||||
@@ -959,6 +969,8 @@
|
||||
"workingPanel.review.viewMode.unified": "Passa alla vista unificata",
|
||||
"workingPanel.review.wordWrap.disable": "Disabilita ritorno a capo automatico",
|
||||
"workingPanel.review.wordWrap.enable": "Abilita ritorno a capo automatico",
|
||||
"workingPanel.skills.empty": "Nessuna competenza trovata in questo progetto",
|
||||
"workingPanel.skills.title": "Competenze",
|
||||
"workingPanel.space": "Spazio",
|
||||
"workingPanel.title": "Working Panel",
|
||||
"you": "Tu",
|
||||
|
||||
@@ -121,6 +121,16 @@
|
||||
"ModelSwitchPanel.detail.context": "Lunghezza del Contesto",
|
||||
"ModelSwitchPanel.detail.pricing": "Prezzi",
|
||||
"ModelSwitchPanel.detail.pricing.cachedInput": "Input memorizzato ${{amount}}/M",
|
||||
"ModelSwitchPanel.detail.pricing.credits.cachedInput": "Input memorizzato nella cache {{amount}} crediti/M token",
|
||||
"ModelSwitchPanel.detail.pricing.credits.image": "crediti/img",
|
||||
"ModelSwitchPanel.detail.pricing.credits.input": "Input {{amount}} crediti/M token",
|
||||
"ModelSwitchPanel.detail.pricing.credits.megapixel": "crediti/MP",
|
||||
"ModelSwitchPanel.detail.pricing.credits.millionCharacters": "crediti/M caratteri",
|
||||
"ModelSwitchPanel.detail.pricing.credits.millionTokens": "crediti/M token",
|
||||
"ModelSwitchPanel.detail.pricing.credits.output": "Output {{amount}} crediti/M token",
|
||||
"ModelSwitchPanel.detail.pricing.credits.perImage": "~ {{amount}} crediti / immagine",
|
||||
"ModelSwitchPanel.detail.pricing.credits.perVideo": "~ {{amount}} crediti / video",
|
||||
"ModelSwitchPanel.detail.pricing.credits.second": "crediti/s",
|
||||
"ModelSwitchPanel.detail.pricing.group.audio": "Audio",
|
||||
"ModelSwitchPanel.detail.pricing.group.image": "Immagine",
|
||||
"ModelSwitchPanel.detail.pricing.group.text": "Testo",
|
||||
|
||||
@@ -1,8 +1,10 @@
|
||||
{
|
||||
"actionTag.category.command": "Comando",
|
||||
"actionTag.category.projectSkill": "Competenza di progetto",
|
||||
"actionTag.category.skill": "Abilità",
|
||||
"actionTag.category.tool": "Strumento",
|
||||
"actionTag.tooltip.command": "Esegue un comando slash lato client prima dell'invio.",
|
||||
"actionTag.tooltip.projectSkill": "Inviato come un'istruzione slash affinché la CLI dell'agente esegua la competenza di progetto corrispondente.",
|
||||
"actionTag.tooltip.skill": "Carica un pacchetto di abilità riutilizzabile per questa richiesta.",
|
||||
"actionTag.tooltip.tool": "Contrassegna uno strumento selezionato esplicitamente dall'utente per questa richiesta.",
|
||||
"actions.expand.off": "Comprimi",
|
||||
|
||||
@@ -11,6 +11,19 @@
|
||||
"brief.action.ignore": "Ignora",
|
||||
"brief.action.retry": "Riprova",
|
||||
"brief.addFeedback": "Condividi feedback",
|
||||
"brief.agentSignal.selfReview.applied.heading": "Aggiornato",
|
||||
"brief.agentSignal.selfReview.applied.summary": "{{count}} aggiornamento del sogno è stato applicato.",
|
||||
"brief.agentSignal.selfReview.applied.summary_plural": "{{count}} aggiornamenti del sogno sono stati applicati.",
|
||||
"brief.agentSignal.selfReview.applied.title": "Risorse del sogno aggiornate",
|
||||
"brief.agentSignal.selfReview.error.heading": "Problema",
|
||||
"brief.agentSignal.selfReview.error.summary": "Alcuni lavori non sono stati completati durante questo sogno.",
|
||||
"brief.agentSignal.selfReview.error.title": "Il sogno ha incontrato un problema",
|
||||
"brief.agentSignal.selfReview.ideas.summary": "Note del sogno salvate per una revisione futura.",
|
||||
"brief.agentSignal.selfReview.ideas.title": "Note del sogno",
|
||||
"brief.agentSignal.selfReview.proposal.heading": "Suggerimento",
|
||||
"brief.agentSignal.selfReview.proposal.summary": "{{count}} suggerimento del sogno necessita della tua revisione.",
|
||||
"brief.agentSignal.selfReview.proposal.summary_plural": "{{count}} suggerimenti del sogno necessitano della tua revisione.",
|
||||
"brief.agentSignal.selfReview.proposal.title": "Suggerimento del sogno da rivedere",
|
||||
"brief.collapse": "Mostra meno",
|
||||
"brief.commentPlaceholder": "Condividi il tuo feedback...",
|
||||
"brief.commentSubmit": "Invia feedback",
|
||||
|
||||
@@ -1,8 +1,6 @@
|
||||
{
|
||||
"addUserMessage.desc": "Aggiungi l'input corrente come messaggio utente senza avviare la generazione",
|
||||
"addUserMessage.title": "Aggiungi un Messaggio Utente",
|
||||
"clearCurrentMessages.desc": "Cancella i messaggi e i file caricati dalla conversazione corrente",
|
||||
"clearCurrentMessages.title": "Cancella Messaggi della Conversazione",
|
||||
"commandPalette.desc": "Apri la palette comandi globale per accedere rapidamente alle funzionalità",
|
||||
"commandPalette.title": "Palette Comandi",
|
||||
"deleteAndRegenerateMessage.desc": "Elimina l'ultimo messaggio e rigenera",
|
||||
|
||||
+12
-19
@@ -106,7 +106,6 @@
|
||||
"MiniMax-Hailuo-2.3.description": "Nuovo modello di generazione video con aggiornamenti completi nei movimenti del corpo, realismo fisico e aderenza alle istruzioni.",
|
||||
"MiniMax-M1.description": "Nuovo modello di ragionamento proprietario con 80K chain-of-thought e 1M di input, con prestazioni comparabili ai migliori modelli globali.",
|
||||
"MiniMax-M2-Stable.description": "Progettato per flussi di lavoro di codifica e agenti efficienti, con maggiore concorrenza per l'uso commerciale.",
|
||||
"MiniMax-M2.1-Lightning.description": "Potenti capacità di programmazione multilingue con inferenza più rapida ed efficiente.",
|
||||
"MiniMax-M2.1-highspeed.description": "Potenti capacità di programmazione multilingue, esperienza di programmazione completamente aggiornata. Più veloce ed efficiente.",
|
||||
"MiniMax-M2.1.description": "MiniMax-M2.1 è un modello open-source di punta di MiniMax, progettato per affrontare compiti complessi del mondo reale. I suoi punti di forza principali sono le capacità di programmazione multilingue e la risoluzione di compiti complessi come agente.",
|
||||
"MiniMax-M2.5-highspeed.description": "MiniMax M2.5 Highspeed: Stesse prestazioni di M2.5 con inferenza più veloce.",
|
||||
@@ -315,11 +314,11 @@
|
||||
"claude-3-haiku-20240307.description": "Claude 3 Haiku è il modello più veloce e compatto di Anthropic, progettato per risposte quasi istantanee con prestazioni rapide e accurate.",
|
||||
"claude-3-opus-20240229.description": "Claude 3 Opus è il modello più potente di Anthropic per compiti altamente complessi, eccellendo in prestazioni, intelligenza, fluidità e comprensione.",
|
||||
"claude-3-sonnet-20240229.description": "Claude 3 Sonnet bilancia intelligenza e velocità per carichi di lavoro aziendali, offrendo alta utilità a costi inferiori e distribuzione affidabile su larga scala.",
|
||||
"claude-haiku-4-5-20251001.description": "Claude Haiku 4.5 è il modello Haiku più veloce e intelligente di Anthropic, con velocità fulminea e pensiero esteso.",
|
||||
"claude-haiku-4-5-20251001.description": "Claude Haiku 4.5 è il modello Haiku più veloce e intelligente di Anthropic, con velocità fulminea e capacità di ragionamento estese.",
|
||||
"claude-haiku-4-5.description": "Claude Haiku 4.5 di Anthropic — Haiku di nuova generazione con ragionamento e visione migliorati.",
|
||||
"claude-haiku-4.5.description": "Claude Haiku 4.5 è il modello Haiku più veloce e intelligente di Anthropic, con velocità fulminea e capacità di ragionamento estese.",
|
||||
"claude-opus-4-1-20250805-thinking.description": "Claude Opus 4.1 Thinking è una variante avanzata in grado di mostrare il proprio processo di ragionamento.",
|
||||
"claude-opus-4-1-20250805.description": "Claude Opus 4.1 è l'ultimo e più avanzato modello di Anthropic per compiti altamente complessi, eccellendo in prestazioni, intelligenza, fluidità e comprensione.",
|
||||
"claude-opus-4-1-20250805.description": "Claude Opus 4.1 è il modello più recente e avanzato di Anthropic per compiti altamente complessi, eccellendo in prestazioni, intelligenza, fluidità e comprensione.",
|
||||
"claude-opus-4-1.description": "Claude Opus 4.1 di Anthropic — modello premium di ragionamento con capacità di analisi approfondita.",
|
||||
"claude-opus-4-20250514.description": "Claude Opus 4 è il modello più potente di Anthropic per compiti altamente complessi, eccellendo in prestazioni, intelligenza, fluidità e comprensione.",
|
||||
"claude-opus-4-5-20251101.description": "Claude Opus 4.5 è il modello di punta di Anthropic, che combina intelligenza eccezionale e prestazioni scalabili, ideale per compiti complessi che richiedono risposte e ragionamenti di altissima qualità.",
|
||||
@@ -330,8 +329,8 @@
|
||||
"claude-opus-4.6-fast.description": "Claude Opus 4.6 è il modello più intelligente di Anthropic per la creazione di agenti e la programmazione.",
|
||||
"claude-opus-4.6.description": "Claude Opus 4.6 è il modello più intelligente di Anthropic per la creazione di agenti e la programmazione.",
|
||||
"claude-sonnet-4-20250514-thinking.description": "Claude Sonnet 4 Thinking può produrre risposte quasi istantanee o riflessioni estese passo dopo passo con processo visibile.",
|
||||
"claude-sonnet-4-20250514.description": "Claude Sonnet 4 è il modello più intelligente di Anthropic fino ad oggi, offrendo risposte quasi istantanee o pensiero esteso passo dopo passo con controllo dettagliato per gli utenti API.",
|
||||
"claude-sonnet-4-5-20250929.description": "Claude Sonnet 4.5 è il modello più intelligente di Anthropic fino ad oggi.",
|
||||
"claude-sonnet-4-20250514.description": "Claude Sonnet 4 può produrre risposte quasi istantanee o pensieri estesi passo dopo passo con un processo visibile.",
|
||||
"claude-sonnet-4-5-20250929.description": "Claude Sonnet 4.5 è il modello più intelligente mai creato da Anthropic.",
|
||||
"claude-sonnet-4-5.description": "Claude Sonnet 4.5 di Anthropic — Sonnet migliorato con prestazioni di codifica avanzate.",
|
||||
"claude-sonnet-4-6.description": "Claude Sonnet 4.6 di Anthropic — ultimo Sonnet con codifica superiore e utilizzo di strumenti.",
|
||||
"claude-sonnet-4.5.description": "Claude Sonnet 4.5 è il modello più intelligente mai creato da Anthropic.",
|
||||
@@ -404,7 +403,7 @@
|
||||
"deepseek-ai/deepseek-llm-67b-chat.description": "DeepSeek LLM Chat (67B) è un modello innovativo che offre una profonda comprensione linguistica e interazione.",
|
||||
"deepseek-ai/deepseek-v3.1-terminus.description": "DeepSeek V3.1 è un modello di nuova generazione per il ragionamento, con capacità avanzate di ragionamento complesso e chain-of-thought per compiti di analisi approfondita.",
|
||||
"deepseek-ai/deepseek-v3.2.description": "DeepSeek V3.2 è un modello di ragionamento di nuova generazione con capacità avanzate di ragionamento complesso e catena di pensiero.",
|
||||
"deepseek-chat.description": "Alias di compatibilità per la modalità non pensante di DeepSeek V4 Flash. Destinato alla deprecazione — utilizzare DeepSeek V4 Flash invece.",
|
||||
"deepseek-chat.description": "Un nuovo modello open-source che combina capacità generali e di codifica. Preserva il dialogo generale del modello di chat e la forte capacità di codifica del modello coder, con un migliore allineamento delle preferenze. DeepSeek-V2.5 migliora anche la scrittura e il seguito delle istruzioni.",
|
||||
"deepseek-coder-33B-instruct.description": "DeepSeek Coder 33B è un modello linguistico per il codice addestrato su 2 trilioni di token (87% codice, 13% testo in cinese/inglese). Introduce una finestra di contesto da 16K e compiti di completamento intermedio, offrendo completamento di codice a livello di progetto e riempimento di snippet.",
|
||||
"deepseek-coder-v2.description": "DeepSeek Coder V2 è un modello MoE open-source per il codice che ottiene ottimi risultati nei compiti di programmazione, comparabile a GPT-4 Turbo.",
|
||||
"deepseek-coder-v2:236b.description": "DeepSeek Coder V2 è un modello MoE open-source per il codice che ottiene ottimi risultati nei compiti di programmazione, comparabile a GPT-4 Turbo.",
|
||||
@@ -426,7 +425,7 @@
|
||||
"deepseek-r1-fast-online.description": "DeepSeek R1 versione completa veloce con ricerca web in tempo reale, che combina capacità su scala 671B e risposte rapide.",
|
||||
"deepseek-r1-online.description": "DeepSeek R1 versione completa con 671 miliardi di parametri e ricerca web in tempo reale, che offre una comprensione e generazione più avanzate.",
|
||||
"deepseek-r1.description": "DeepSeek-R1 utilizza dati cold-start prima dell'RL e ottiene prestazioni comparabili a OpenAI-o1 in matematica, programmazione e ragionamento.",
|
||||
"deepseek-reasoner.description": "Alias di compatibilità per la modalità pensante di DeepSeek V4 Flash. Destinato alla deprecazione — utilizzare DeepSeek V4 Flash invece.",
|
||||
"deepseek-reasoner.description": "Un modello di ragionamento DeepSeek focalizzato su compiti di ragionamento logico complessi.",
|
||||
"deepseek-v2.description": "DeepSeek V2 è un modello MoE efficiente per un'elaborazione conveniente.",
|
||||
"deepseek-v2:236b.description": "DeepSeek V2 236B è il modello DeepSeek focalizzato sul codice con forte capacità di generazione.",
|
||||
"deepseek-v3-0324.description": "DeepSeek-V3-0324 è un modello MoE con 671 miliardi di parametri, con punti di forza nella programmazione, capacità tecnica, comprensione del contesto e gestione di testi lunghi.",
|
||||
@@ -491,8 +490,6 @@
|
||||
"doubao-seedream-4-0-250828.description": "Seedream 4.0 è un modello di generazione di immagini di ByteDance Seed, che supporta input di testo e immagini con generazione di immagini di alta qualità e altamente controllabile. Genera immagini da prompt testuali.",
|
||||
"doubao-seedream-4-5-251128.description": "Seedream 4.5 è l'ultimo modello multimodale di ByteDance, che integra capacità di generazione da testo a immagine, immagine a immagine e generazione di immagini in batch, incorporando anche conoscenze di senso comune e capacità di ragionamento. Rispetto alla versione precedente 4.0, offre una qualità di generazione significativamente migliorata, con una maggiore coerenza nell'editing e nella fusione di più immagini. Offre un controllo più preciso sui dettagli visivi, producendo testi e volti piccoli in modo più naturale, e raggiunge una disposizione e una colorazione più armoniose, migliorando l'estetica complessiva.",
|
||||
"doubao-seedream-5-0-260128.description": "Doubao-Seedream-5.0-lite è l'ultimo modello di generazione di immagini di ByteDance. Per la prima volta, integra capacità di recupero online, consentendo di incorporare informazioni web in tempo reale e migliorare la tempestività delle immagini generate. L'intelligenza del modello è stata inoltre aggiornata, consentendo un'interpretazione precisa di istruzioni complesse e contenuti visivi. Inoltre, offre una copertura globale della conoscenza migliorata, una maggiore coerenza di riferimento e una qualità di generazione superiore in scenari professionali, soddisfacendo meglio le esigenze di creazione visiva a livello aziendale.",
|
||||
"dreamina-seedance-2-0-260128.description": "Seedance 2.0 di ByteDance è il modello di generazione video più potente, supportando la generazione di video multimodali di riferimento, editing video, estensione video, testo-a-video e immagine-a-video con audio sincronizzato.",
|
||||
"dreamina-seedance-2-0-fast-260128.description": "Seedance 2.0 Fast di ByteDance offre le stesse capacità di Seedance 2.0 con velocità di generazione più rapide a un prezzo più competitivo.",
|
||||
"emohaa.description": "Emohaa è un modello per la salute mentale con capacità di consulenza professionale per aiutare gli utenti a comprendere le problematiche emotive.",
|
||||
"ernie-4.5-0.3b.description": "ERNIE 4.5 0.3B è un modello open-source leggero per implementazioni locali e personalizzate.",
|
||||
"ernie-4.5-8k-preview.description": "ERNIE 4.5 8K Preview è un modello di anteprima con finestra contestuale da 8K per la valutazione di ERNIE 4.5.",
|
||||
@@ -506,6 +503,7 @@
|
||||
"ernie-5.0-thinking-latest.description": "Wenxin 5.0 Thinking è un modello di punta nativo full-modal con modellazione unificata di testo, immagini, audio e video. Offre ampi miglioramenti nelle capacità per domande complesse, creazione e scenari con agenti.",
|
||||
"ernie-5.0-thinking-preview.description": "Wenxin 5.0 Thinking Preview è un modello di punta nativo full-modal con modellazione unificata di testo, immagini, audio e video. Offre ampi miglioramenti nelle capacità per domande complesse, creazione e scenari con agenti.",
|
||||
"ernie-5.0.description": "ERNIE 5.0, il modello di nuova generazione della serie ERNIE, è un grande modello multimodale nativo. Adotta un approccio di modellazione multimodale unificato, modellando congiuntamente testo, immagini, audio e video per offrire capacità multimodali complete. Le sue abilità fondamentali sono state significativamente migliorate, raggiungendo prestazioni elevate nelle valutazioni di benchmark. Eccelle particolarmente nella comprensione multimodale, nel seguito delle istruzioni, nella scrittura creativa, nell'accuratezza fattuale, nella pianificazione degli agenti e nell'utilizzo degli strumenti.",
|
||||
"ernie-5.1.description": "ERNIE 5.1 è l'ultimo modello della serie ERNIE, con aggiornamenti completi alle sue capacità fondamentali. Dimostra miglioramenti significativi in aree come agenti, elaborazione della conoscenza, ragionamento e ricerca approfondita. Questa versione adotta un'architettura di apprendimento per rinforzo completamente asincrona e decoupled, progettata specificamente per affrontare le sfide chiave nell'evoluzione dei modelli di grandi dimensioni verso la decisione autonoma degli agenti, inclusi discrepanze numeriche tra addestramento e inferenza, basso utilizzo delle risorse di calcolo eterogenee e problemi globali causati dagli effetti di lunga coda. Inoltre, vengono impiegate tecniche di post-addestramento su larga scala per agenti per migliorare ulteriormente le capacità e le prestazioni di generalizzazione del modello. Attraverso un framework collaborativo a tre stadi che coinvolge ambiente, esperto e processi di fusione, l'approccio non solo garantisce l'efficienza dell'addestramento ma migliora significativamente la stabilità e le prestazioni del modello su compiti complessi.",
|
||||
"ernie-char-fiction-8k-preview.description": "ERNIE Character Fiction 8K Preview è un’anteprima del modello per la creazione di personaggi e trame, utile per valutazioni e test di funzionalità.",
|
||||
"ernie-char-fiction-8k.description": "ERNIE Character Fiction 8K è un modello con personalità per romanzi e creazione di trame, adatto alla generazione di storie di lunga durata.",
|
||||
"ernie-image-turbo.description": "ERNIE-Image è un modello di testo-immagine con 8 miliardi di parametri sviluppato da Baidu. Si colloca tra i migliori in diversi benchmark, raggiungendo il primo posto ex aequo in SuperCLUE in Cina e guidando la pista open-source.",
|
||||
@@ -517,8 +515,7 @@
|
||||
"ernie-x1-turbo-32k.description": "ERNIE X1 Turbo 32K è un modello di pensiero veloce con contesto da 32K per ragionamento complesso e chat multi-turno.",
|
||||
"ernie-x1.1-preview.description": "ERNIE X1.1 Preview è un’anteprima del modello di pensiero per valutazioni e test.",
|
||||
"ernie-x1.1.description": "ERNIE X1.1 è un'anteprima del modello di pensiero per valutazione e test.",
|
||||
"fal-ai/bytedance/seedream/v4.5.description": "Seedream 4.5, sviluppato dal team Seed di ByteDance, supporta l'editing e la composizione multi-immagine. Caratteristiche includono coerenza del soggetto migliorata, esecuzione precisa delle istruzioni, comprensione della logica spaziale, espressione estetica, layout di poster e design di loghi con rendering testo-immagine ad alta precisione.",
|
||||
"fal-ai/bytedance/seedream/v4.description": "Seedream 4.0, sviluppato da ByteDance Seed, supporta input di testo e immagini per una generazione di immagini altamente controllabile e di alta qualità a partire dai prompt.",
|
||||
"fal-ai/bytedance/seedream/v4.description": "Seedream 4.0 è un modello di generazione di immagini di ByteDance Seed, che supporta input di testo e immagini con generazione di immagini altamente controllabile e di alta qualità. Genera immagini a partire da prompt testuali.",
|
||||
"fal-ai/flux-kontext/dev.description": "FLUX.1 è un modello focalizzato sull’editing di immagini, che supporta input di testo e immagini.",
|
||||
"fal-ai/flux-pro/kontext.description": "FLUX.1 Kontext [pro] accetta testo e immagini di riferimento come input, consentendo modifiche locali mirate e trasformazioni complesse della scena globale.",
|
||||
"fal-ai/flux/krea.description": "Flux Krea [dev] è un modello di generazione di immagini con una preferenza estetica per immagini più realistiche e naturali.",
|
||||
@@ -526,8 +523,8 @@
|
||||
"fal-ai/hunyuan-image/v3.description": "Un potente modello nativo multimodale per la generazione di immagini.",
|
||||
"fal-ai/imagen4/preview.description": "Modello di generazione di immagini di alta qualità sviluppato da Google.",
|
||||
"fal-ai/nano-banana.description": "Nano Banana è il modello multimodale nativo più recente, veloce ed efficiente di Google, che consente la generazione e l’editing di immagini tramite conversazione.",
|
||||
"fal-ai/qwen-image-edit.description": "Un modello professionale di editing immagini del team Qwen, che supporta modifiche semantiche e di aspetto, editing preciso di testo in cinese/inglese, trasferimento di stile, rotazione e altro.",
|
||||
"fal-ai/qwen-image.description": "Un potente modello di generazione immagini del team Qwen con una forte resa del testo in cinese e stili visivi diversificati.",
|
||||
"fal-ai/qwen-image-edit.description": "Un modello professionale di editing di immagini del team Qwen che supporta modifiche semantiche e di aspetto, modifica con precisione testo in cinese e inglese, e consente modifiche di alta qualità come trasferimento di stile e rotazione di oggetti.",
|
||||
"fal-ai/qwen-image.description": "Un potente modello di generazione di immagini del team Qwen con impressionante rendering di testo in cinese e stili visivi diversificati.",
|
||||
"flux-1-schnell.description": "Modello testo-immagine da 12 miliardi di parametri di Black Forest Labs che utilizza la distillazione latente avversariale per generare immagini di alta qualità in 1-4 passaggi. Con licenza Apache-2.0 per uso personale, di ricerca e commerciale.",
|
||||
"flux-dev.description": "Modello open-source per la ricerca e sviluppo nella generazione di immagini, ottimizzato in modo efficiente per la ricerca innovativa non commerciale.",
|
||||
"flux-kontext-max.description": "Generazione ed editing di immagini contestuali all’avanguardia, combinando testo e immagini per risultati precisi e coerenti.",
|
||||
@@ -566,10 +563,10 @@
|
||||
"gemini-3-flash-preview.description": "Gemini 3 Flash è il modello più intelligente progettato per la velocità, che combina intelligenza all'avanguardia con un eccellente ancoraggio alla ricerca.",
|
||||
"gemini-3-flash.description": "Gemini 3 Flash di Google — modello ultra-veloce con supporto per input multimodali.",
|
||||
"gemini-3-pro-image-preview.description": "Gemini 3 Pro Image (Nano Banana Pro) è il modello di generazione di immagini di Google che supporta anche il dialogo multimodale.",
|
||||
"gemini-3-pro-image-preview:image.description": "Gemini 3 Pro Image (Nano Banana Pro) è il modello di generazione immagini di Google e supporta anche la chat multimodale.",
|
||||
"gemini-3-pro-image-preview:image.description": "Gemini 3 Pro Image (Nano Banana Pro) è il modello di generazione di immagini di Google e supporta anche la chat multimodale.",
|
||||
"gemini-3-pro-preview.description": "Gemini 3 Pro è il modello più potente di Google per agenti e codifica creativa, offrendo visuali più ricche e interazioni più profonde grazie a un ragionamento all'avanguardia.",
|
||||
"gemini-3.1-flash-image-preview.description": "Gemini 3.1 Flash Image (Nano Banana 2) è il modello di generazione di immagini nativo più veloce di Google con supporto al pensiero, generazione e modifica di immagini conversazionali.",
|
||||
"gemini-3.1-flash-image-preview:image.description": "Gemini 3.1 Flash Image (Nano Banana 2) offre qualità di immagine di livello Pro a velocità Flash con supporto per la chat multimodale.",
|
||||
"gemini-3.1-flash-image-preview:image.description": "Gemini 3.1 Flash Image (Nano Banana 2) è il modello di generazione di immagini nativo più veloce di Google con supporto al pensiero, generazione e modifica di immagini conversazionali.",
|
||||
"gemini-3.1-flash-lite-preview.description": "Gemini 3.1 Flash-Lite Preview è il modello multimodale più economico di Google, ottimizzato per compiti agentici ad alto volume, traduzione e elaborazione dati.",
|
||||
"gemini-3.1-flash-lite.description": "Gemini 3.1 Flash-Lite è il modello multimodale più economico di Google, ottimizzato per compiti agentici ad alto volume, traduzione e elaborazione dati.",
|
||||
"gemini-3.1-pro-preview.description": "Gemini 3.1 Pro Preview migliora Gemini 3 Pro con capacità di ragionamento avanzate e aggiunge supporto per un livello di pensiero medio.",
|
||||
@@ -734,8 +731,6 @@
|
||||
"grok-4-fast-reasoning.description": "Siamo entusiasti di presentare Grok 4 Fast, il nostro ultimo progresso nei modelli di ragionamento a basso costo.",
|
||||
"grok-4.20-0309-non-reasoning.description": "Una variante senza ragionamento per casi d'uso semplici.",
|
||||
"grok-4.20-0309-reasoning.description": "Modello intelligente e velocissimo che ragiona prima di rispondere.",
|
||||
"grok-4.20-beta-0309-non-reasoning.description": "Una variante non pensante per casi d'uso semplici.",
|
||||
"grok-4.20-beta-0309-reasoning.description": "Modello intelligente e ultra-veloce che ragiona prima di rispondere.",
|
||||
"grok-4.20-multi-agent-0309.description": "Un team di 4 o 16 agenti, eccelle nei casi d'uso di ricerca, non supporta attualmente strumenti client-side. Supporta solo strumenti server-side xAI (es. X Search, strumenti di ricerca web) e strumenti MCP remoti.",
|
||||
"grok-4.3.description": "Il modello linguistico di grandi dimensioni più orientato alla verità al mondo",
|
||||
"grok-4.description": "Ultimo modello di punta Grok con prestazioni ineguagliabili in linguaggio, matematica e ragionamento — un vero tuttofare. Attualmente punta a grok-4-0709; a causa di risorse limitate, il prezzo è temporaneamente superiore del 10% rispetto al prezzo ufficiale e si prevede un ritorno al prezzo ufficiale in seguito.",
|
||||
@@ -1220,8 +1215,6 @@
|
||||
"qwq.description": "QwQ è un modello di ragionamento della famiglia Qwen. Rispetto ai modelli standard ottimizzati per istruzioni, offre capacità di pensiero e ragionamento che migliorano significativamente le prestazioni nei compiti difficili. QwQ-32B è un modello di medie dimensioni che compete con i migliori modelli di ragionamento come DeepSeek-R1 e o1-mini.",
|
||||
"qwq_32b.description": "Modello di ragionamento di medie dimensioni della famiglia Qwen. Rispetto ai modelli standard ottimizzati per istruzioni, le capacità di pensiero e ragionamento di QwQ migliorano significativamente le prestazioni nei compiti difficili.",
|
||||
"r1-1776.description": "R1-1776 è una variante post-addestrata di DeepSeek R1 progettata per fornire informazioni fattuali non censurate e imparziali.",
|
||||
"seedance-1-5-pro-251215.description": "Seedance 1.5 Pro di ByteDance supporta testo-a-video, immagine-a-video (prima immagine, prima+ultima immagine) e generazione audio sincronizzata con i visual.",
|
||||
"seedream-5-0-260128.description": "ByteDance-Seedream-5.0-lite di BytePlus offre generazione aumentata da recupero web per informazioni in tempo reale, interpretazione migliorata di prompt complessi e maggiore coerenza di riferimento per la creazione visiva professionale.",
|
||||
"solar-mini-ja.description": "Solar Mini (Ja) estende Solar Mini con un focus sul giapponese, mantenendo prestazioni efficienti e solide in inglese e coreano.",
|
||||
"solar-mini.description": "Solar Mini è un LLM compatto che supera GPT-3.5, con forte capacità multilingue in inglese e coreano, offrendo una soluzione efficiente e leggera.",
|
||||
"solar-pro.description": "Solar Pro è un LLM ad alta intelligenza di Upstage, focalizzato sull’esecuzione di istruzioni su una singola GPU, con punteggi IFEval superiori a 80. Attualmente supporta l’inglese; il rilascio completo è previsto per novembre 2024 con supporto linguistico ampliato e contesto più lungo.",
|
||||
|
||||
@@ -27,6 +27,13 @@
|
||||
"agent.layout.skipConfirm.ok": "Salta per ora",
|
||||
"agent.layout.skipConfirm.title": "Saltare l’onboarding per ora?",
|
||||
"agent.layout.switchMessage": "Non è giornata? Puoi passare a <modeLink><modeText>{{mode}}</modeText></modeLink> oppure a <skipLink><skipText>{{skip}}</skipText></skipLink>.",
|
||||
"agent.layout.switchMessageClassic": "Non ti va oggi? Puoi passare a <modeLink><modeText>{{mode}}</modeText></modeLink>.",
|
||||
"agent.messenger.cta.discord": "Aggiungi a Discord",
|
||||
"agent.messenger.cta.slack": "Aggiungi a Slack",
|
||||
"agent.messenger.cta.telegram": "Apri in Telegram",
|
||||
"agent.messenger.subtitle": "Chatta con il tuo agente su Telegram, Slack o Discord",
|
||||
"agent.messenger.telegramQrCaption": "Scansiona con la fotocamera del tuo telefono",
|
||||
"agent.messenger.title": "Tienimi con te, ovunque tu invii messaggi",
|
||||
"agent.modeSwitch.agent": "Conversazionale",
|
||||
"agent.modeSwitch.classic": "Classico",
|
||||
"agent.modeSwitch.collapse": "Comprimi",
|
||||
@@ -68,6 +75,13 @@
|
||||
"agent.wrapUp.confirm.content": "Salverò ciò che abbiamo coperto finora. Puoi sempre tornare e continuare la conversazione più tardi.",
|
||||
"agent.wrapUp.confirm.ok": "Termina ora",
|
||||
"agent.wrapUp.confirm.title": "Vuoi terminare l’onboarding adesso?",
|
||||
"agentPicker.allCategories": "Tutti",
|
||||
"agentPicker.continue": "Continua",
|
||||
"agentPicker.skip": "Salta per ora",
|
||||
"agentPicker.subtitle": "Aggiungine alcuni alla tua libreria ora — scopri di più in qualsiasi momento.",
|
||||
"agentPicker.title": "Aggiungiamo alcuni agenti alla tua libreria",
|
||||
"agentPicker.title2": "Scegli quelli che si adattano al tuo modo di lavorare",
|
||||
"agentPicker.title3": "Puoi sempre aggiungerne altri in seguito — inizia con alcuni",
|
||||
"back": "Indietro",
|
||||
"finish": "Inizia",
|
||||
"interests.area.business": "Business e Strategia",
|
||||
|
||||
@@ -39,8 +39,8 @@
|
||||
"builtins.lobe-agent-documents.inspector.docCount": "{{count}} documenti",
|
||||
"builtins.lobe-agent-documents.inspector.opsCount": "{{count}} operazioni",
|
||||
"builtins.lobe-agent-documents.inspector.opsResult": "{{success}}/{{total}} operazioni",
|
||||
"builtins.lobe-agent-documents.inspector.target.agent": "nell'agente",
|
||||
"builtins.lobe-agent-documents.inspector.target.currentTopic": "nell'argomento",
|
||||
"builtins.lobe-agent-documents.inspector.scope.agent": "nell'agente",
|
||||
"builtins.lobe-agent-documents.inspector.scope.currentTopic": "nell'argomento",
|
||||
"builtins.lobe-agent-documents.title": "Documenti dell'agente",
|
||||
"builtins.lobe-agent-management.apiName.callAgent": "Chiamare agente",
|
||||
"builtins.lobe-agent-management.apiName.createAgent": "Creare agente",
|
||||
@@ -90,6 +90,14 @@
|
||||
"builtins.lobe-agent.title": "Agente Lobe",
|
||||
"builtins.lobe-claude-code.agent.instruction": "Istruzione",
|
||||
"builtins.lobe-claude-code.agent.result": "Risultato",
|
||||
"builtins.lobe-claude-code.task.createLabel": "Creazione attività: ",
|
||||
"builtins.lobe-claude-code.task.getLabel": "Ispezione attività #{{taskId}}",
|
||||
"builtins.lobe-claude-code.task.listLabel": "Elenco attività",
|
||||
"builtins.lobe-claude-code.task.updateCompleted": "Completato",
|
||||
"builtins.lobe-claude-code.task.updateDeleted": "Eliminato",
|
||||
"builtins.lobe-claude-code.task.updateInProgress": "Avviato",
|
||||
"builtins.lobe-claude-code.task.updateLabel": "Aggiornamento attività #{{taskId}}",
|
||||
"builtins.lobe-claude-code.task.updatePending": "Reimposta",
|
||||
"builtins.lobe-claude-code.todoWrite.allDone": "Tutte le attività completate",
|
||||
"builtins.lobe-claude-code.todoWrite.currentStep": "Passaggio attuale",
|
||||
"builtins.lobe-claude-code.todoWrite.todos": "Attività",
|
||||
|
||||
@@ -33,7 +33,6 @@
|
||||
"jina.description": "Fondata nel 2020, Jina AI è un'azienda leader nell'AI per la ricerca. Il suo stack include modelli vettoriali, reranker e piccoli modelli linguistici per costruire app di ricerca generativa e multimodale affidabili e di alta qualità.",
|
||||
"kimicodingplan.description": "Kimi Code di Moonshot AI offre accesso ai modelli Kimi, inclusi K2.5, per attività di codifica.",
|
||||
"lmstudio.description": "LM Studio è un'app desktop per sviluppare e sperimentare con LLM direttamente sul tuo computer.",
|
||||
"lobehub.description": "LobeHub Cloud utilizza API ufficiali per accedere ai modelli di intelligenza artificiale e misura l'utilizzo con Crediti legati ai token del modello.",
|
||||
"longcat.description": "LongCat è una serie di modelli AI generativi di grandi dimensioni sviluppati indipendentemente da Meituan. È progettato per migliorare la produttività interna dell'azienda e consentire applicazioni innovative attraverso un'architettura computazionale efficiente e potenti capacità multimodali.",
|
||||
"minimax.description": "Fondata nel 2021, MiniMax sviluppa AI generali con modelli fondamentali multimodali, inclusi modelli testuali MoE da trilioni di parametri, modelli vocali e visivi, oltre ad app come Hailuo AI.",
|
||||
"minimaxcodingplan.description": "Il piano di token MiniMax offre accesso ai modelli MiniMax, inclusi M2.7, per attività di codifica tramite un abbonamento a tariffa fissa.",
|
||||
|
||||
@@ -55,6 +55,12 @@
|
||||
"credits.autoTopUp.toggle": "Abilita ricarica automatica",
|
||||
"credits.autoTopUp.upgradeHint": "Abbonati a un piano a pagamento per abilitare la ricarica automatica",
|
||||
"credits.autoTopUp.validation.targetMustExceedThreshold": "Il saldo obiettivo deve essere maggiore della soglia",
|
||||
"credits.costEstimateHint.desc": "Mostra un avviso leggero prima dell'invio quando il costo stimato del modello raggiunge la tua soglia",
|
||||
"credits.costEstimateHint.saveError": "Impossibile salvare le impostazioni dell'avviso di stima dei costi",
|
||||
"credits.costEstimateHint.saveSuccess": "Impostazioni dell'avviso di stima dei costi salvate",
|
||||
"credits.costEstimateHint.threshold": "Soglia di Avviso",
|
||||
"credits.costEstimateHint.title": "Avviso di Stima dei Costi",
|
||||
"credits.costEstimateHint.validation.threshold": "La soglia deve essere maggiore o uguale a 0",
|
||||
"credits.packages.auto": "Automatico",
|
||||
"credits.packages.charged": "Addebitato ${{amount}}",
|
||||
"credits.packages.expired": "Scaduto",
|
||||
|
||||
@@ -40,6 +40,14 @@
|
||||
"agentMarketplace.render.alreadyInLibraryTag": "Già nella libreria",
|
||||
"agentMarketplace.render.alreadyInLibrary_one": "{{count}} già nella libreria",
|
||||
"agentMarketplace.render.alreadyInLibrary_other": "{{count}} già nella libreria",
|
||||
"claudeCode.askUserQuestion.escape.back": "Torna alle opzioni",
|
||||
"claudeCode.askUserQuestion.escape.enter": "Oppure digita direttamente",
|
||||
"claudeCode.askUserQuestion.escape.placeholder": "Scrivi la tua risposta qui…",
|
||||
"claudeCode.askUserQuestion.multiSelectTag": "(selezione multipla)",
|
||||
"claudeCode.askUserQuestion.skip": "Salta",
|
||||
"claudeCode.askUserQuestion.submit": "Invia",
|
||||
"claudeCode.askUserQuestion.timeExpired": "Tempo scaduto — utilizzando l'opzione 1 per ogni domanda.",
|
||||
"claudeCode.askUserQuestion.timeRemaining": "Tempo rimanente: {{time}} · le domande senza risposta predefinite all'opzione 1 allo scadere del tempo.",
|
||||
"codeInterpreter-legacy.error": "Errore di Esecuzione",
|
||||
"codeInterpreter-legacy.executing": "Esecuzione in corso...",
|
||||
"codeInterpreter-legacy.files": "File:",
|
||||
|
||||
@@ -56,6 +56,7 @@
|
||||
"renameModal.title": "Rinomina argomento",
|
||||
"searchPlaceholder": "Cerca Argomenti...",
|
||||
"searchResultEmpty": "Nessun risultato trovato.",
|
||||
"sidebar.title": "Argomenti",
|
||||
"taskManager.agent": "Agente di attività",
|
||||
"taskManager.welcome": "Chiedimi dei tuoi compiti",
|
||||
"temp": "Temporaneo",
|
||||
|
||||
@@ -220,6 +220,13 @@
|
||||
"inbox.title": "Lobe AI",
|
||||
"input.addAi": "アシスタントメッセージを追加",
|
||||
"input.addUser": "ユーザーメッセージを追加",
|
||||
"input.costEstimate.creditsPerMillionTokens": "{{credits}} クレジット/Mトークン",
|
||||
"input.costEstimate.hint": "推定コスト: 約{{credits}} クレジット",
|
||||
"input.costEstimate.inputLabel": "入力",
|
||||
"input.costEstimate.outputLabel": "出力",
|
||||
"input.costEstimate.settingsLink": "警告閾値を調整",
|
||||
"input.costEstimate.tokenCount": "約{{tokens}} トークン",
|
||||
"input.costEstimate.tooltip": "現在のコンテキスト、ツール、およびモデルの価格設定に基づいて推定されています。実際のコストは異なる場合があります。",
|
||||
"input.disclaimer": "アシスタントも間違えることがあります。重要な情報はあなたの判断を最優先してください",
|
||||
"input.errorMsg": "送信中に問題が発生しました:{{errorMsg}}。再試行するか、時間を置いてから送ってください",
|
||||
"input.more": "もっと見る",
|
||||
@@ -779,6 +786,7 @@
|
||||
"upload.preview.prepareTasks": "チャンクの準備中…",
|
||||
"upload.preview.status.pending": "アップロードの準備中…",
|
||||
"upload.preview.status.processing": "ファイル処理中…",
|
||||
"upload.validation.unsupportedFileType": "サポートされていないファイルタイプ: {{files}}。サポートされている画像形式: JPG、PNG、GIF、WebP。サポートされているドキュメント形式: PDF、Word、Excel、PowerPoint、Markdown、テキスト、CSV、JSON、コードファイル。",
|
||||
"upload.validation.videoSizeExceeded": "ビデオファイルは 20MB を超えることはできません。現在は {{actualSize}} です",
|
||||
"viewMode.fullWidth": "全幅表示",
|
||||
"viewMode.normal": "標準",
|
||||
@@ -894,6 +902,8 @@
|
||||
"workingPanel.localFile.closeOther": "その他を閉じる",
|
||||
"workingPanel.localFile.closeRight": "右側を閉じる",
|
||||
"workingPanel.localFile.error": "このファイルを読み込めませんでした",
|
||||
"workingPanel.localFile.preview.raw": "生データ",
|
||||
"workingPanel.localFile.preview.render": "プレビュー",
|
||||
"workingPanel.localFile.truncated": "ファイルプレビューは{{limit}}文字に切り詰められています",
|
||||
"workingPanel.progress": "Progress",
|
||||
"workingPanel.progress.allCompleted": "All tasks completed",
|
||||
@@ -959,6 +969,8 @@
|
||||
"workingPanel.review.viewMode.unified": "統合ビューに切り替え",
|
||||
"workingPanel.review.wordWrap.disable": "ワードラップを無効化",
|
||||
"workingPanel.review.wordWrap.enable": "ワードラップを有効化",
|
||||
"workingPanel.skills.empty": "このプロジェクトにはスキルが見つかりませんでした",
|
||||
"workingPanel.skills.title": "スキル",
|
||||
"workingPanel.space": "スペース",
|
||||
"workingPanel.title": "Working Panel",
|
||||
"you": "あなた",
|
||||
|
||||
@@ -121,6 +121,16 @@
|
||||
"ModelSwitchPanel.detail.context": "コンテキスト長",
|
||||
"ModelSwitchPanel.detail.pricing": "料金",
|
||||
"ModelSwitchPanel.detail.pricing.cachedInput": "キャッシュ済み入力 ${{amount}}/M",
|
||||
"ModelSwitchPanel.detail.pricing.credits.cachedInput": "キャッシュされた入力 {{amount}} クレジット/M トークン",
|
||||
"ModelSwitchPanel.detail.pricing.credits.image": "クレジット/画像",
|
||||
"ModelSwitchPanel.detail.pricing.credits.input": "入力 {{amount}} クレジット/M トークン",
|
||||
"ModelSwitchPanel.detail.pricing.credits.megapixel": "クレジット/MP",
|
||||
"ModelSwitchPanel.detail.pricing.credits.millionCharacters": "クレジット/M 文字",
|
||||
"ModelSwitchPanel.detail.pricing.credits.millionTokens": "クレジット/M トークン",
|
||||
"ModelSwitchPanel.detail.pricing.credits.output": "出力 {{amount}} クレジット/M トークン",
|
||||
"ModelSwitchPanel.detail.pricing.credits.perImage": "約 {{amount}} クレジット / 画像",
|
||||
"ModelSwitchPanel.detail.pricing.credits.perVideo": "約 {{amount}} クレジット / 動画",
|
||||
"ModelSwitchPanel.detail.pricing.credits.second": "クレジット/秒",
|
||||
"ModelSwitchPanel.detail.pricing.group.audio": "音声",
|
||||
"ModelSwitchPanel.detail.pricing.group.image": "画像",
|
||||
"ModelSwitchPanel.detail.pricing.group.text": "テキスト",
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user