mirror of
https://github.com/lobehub/lobe-chat.git
synced 2026-06-13 19:20:04 +00:00
🐛 fix: use server env config image models (#8478)
* docs: update fal provider invalid image links * docs: add FAL model provider environment variables documentation * 🐛 fix: update model type assignment in parseModels.ts to use dynamic lookup * 📝 docs: add FAQ for resolving AI image generation timeout issues on Vercel * ✨ feat: implement getModelPropertyWithFallback utility for dynamic model property retrieval * 📝 docs: expand testing guide with best practices for mock data strategies, error handling, and module pollution prevention * 🐛 fix: update model type in LobeOpenAICompatibleFactory tests to 'chat'
This commit is contained in:
@@ -214,6 +214,176 @@ describe('<UserProfile />', () => {
|
||||
**修复方法**: 更新了测试文件中的 mock 数据结构,使其与最新的 API 响应格式保持一致。具体修改了 `user.test.ts` 中的 `mockUserData` 对象结构。
|
||||
```
|
||||
|
||||
## 🎯 测试编写最佳实践
|
||||
|
||||
### Mock 数据策略:追求"低成本的真实性" 📋
|
||||
|
||||
**核心原则**: 测试数据应默认追求真实性,只有在引入"高昂的测试成本"时才进行简化。
|
||||
|
||||
#### 什么是"高昂的测试成本"?
|
||||
|
||||
"高成本"指的是测试中引入了外部依赖,使测试变慢、不稳定或复杂:
|
||||
|
||||
- **文件 I/O 操作**:读写硬盘文件
|
||||
- **网络请求**:HTTP 调用、数据库连接
|
||||
- **系统调用**:获取系统时间、环境变量等
|
||||
|
||||
#### ✅ 推荐做法:Mock 依赖,保留真实数据
|
||||
|
||||
```typescript
|
||||
// ✅ 好的做法:Mock I/O 操作,但使用真实的文件内容格式
|
||||
describe('parseContentType', () => {
|
||||
beforeEach(() => {
|
||||
// Mock 文件读取操作(避免真实 I/O)
|
||||
vi.spyOn(fs, 'readFileSync').mockImplementation((path) => {
|
||||
// 但返回真实的文件内容格式
|
||||
if (path.includes('.pdf')) return '%PDF-1.4\n%âãÏÓ'; // 真实 PDF 文件头
|
||||
if (path.includes('.png')) return '\x89PNG\r\n\x1a\n'; // 真实 PNG 文件头
|
||||
return '';
|
||||
});
|
||||
});
|
||||
|
||||
it('should detect PDF content type correctly', () => {
|
||||
const result = parseContentType('/path/to/file.pdf');
|
||||
expect(result).toBe('application/pdf');
|
||||
});
|
||||
});
|
||||
|
||||
// ❌ 过度简化:使用不真实的数据
|
||||
describe('parseContentType', () => {
|
||||
it('should detect PDF content type correctly', () => {
|
||||
// 这种简化数据没有测试价值
|
||||
const result = parseContentType('fake-pdf-content');
|
||||
expect(result).toBe('application/pdf');
|
||||
});
|
||||
});
|
||||
```
|
||||
|
||||
#### 🎯 真实标识符的价值
|
||||
|
||||
```typescript
|
||||
// ✅ 使用真实的提供商标识符
|
||||
it('should parse OpenAI model list correctly', () => {
|
||||
const result = parseModelString('openai', '+gpt-4,+gpt-3.5-turbo');
|
||||
expect(result.add).toHaveLength(2);
|
||||
expect(result.add[0].id).toBe('gpt-4');
|
||||
});
|
||||
|
||||
// ❌ 使用占位符标识符(价值较低)
|
||||
it('should parse model list correctly', () => {
|
||||
const result = parseModelString('test-provider', '+model1,+model2');
|
||||
expect(result.add).toHaveLength(2);
|
||||
// 这种测试对理解真实场景帮助不大
|
||||
});
|
||||
```
|
||||
|
||||
### 错误处理测试:测试"行为"而非"文本" ⚠️
|
||||
|
||||
**核心原则**: 测试应该验证程序在错误发生时的行为是可预测的,而不是验证易变的错误信息文本。
|
||||
|
||||
#### ✅ 推荐的错误测试方式
|
||||
|
||||
```typescript
|
||||
// ✅ 测试是否抛出错误
|
||||
it('should throw error when invalid input provided', () => {
|
||||
expect(() => processInput(null)).toThrow();
|
||||
});
|
||||
|
||||
// ✅ 测试错误类型(最推荐)
|
||||
it('should throw ValidationError for invalid data', () => {
|
||||
expect(() => validateUser({})).toThrow(ValidationError);
|
||||
});
|
||||
|
||||
// ✅ 测试错误属性而非消息文本
|
||||
it('should throw error with correct error code', () => {
|
||||
expect(() => processPayment({})).toThrow(
|
||||
expect.objectContaining({
|
||||
code: 'INVALID_PAYMENT_DATA',
|
||||
statusCode: 400,
|
||||
}),
|
||||
);
|
||||
});
|
||||
```
|
||||
|
||||
#### ❌ 应避免的做法
|
||||
|
||||
```typescript
|
||||
// ❌ 过度依赖具体错误信息文本
|
||||
it('should throw specific error message', () => {
|
||||
expect(() => processUser({})).toThrow('用户数据不能为空,请检查输入参数');
|
||||
// 这种测试很脆弱,错误文案稍有修改就会失败
|
||||
});
|
||||
```
|
||||
|
||||
#### 🎯 例外情况:何时可以测试错误信息
|
||||
|
||||
```typescript
|
||||
// ✅ 测试标准 API 错误(这是契约的一部分)
|
||||
it('should return proper HTTP error for API', () => {
|
||||
expect(response.statusCode).toBe(400);
|
||||
expect(response.error).toBe('Bad Request');
|
||||
});
|
||||
|
||||
// ✅ 测试错误信息的关键部分(使用正则)
|
||||
it('should include field name in validation error', () => {
|
||||
expect(() => validateField('email', '')).toThrow(/email/i);
|
||||
});
|
||||
```
|
||||
|
||||
### 疑难解答:警惕模块污染 🚨
|
||||
|
||||
**识别信号**: 当你的测试出现以下"灵异"现象时,优先怀疑模块污染:
|
||||
|
||||
- 单独运行某个测试通过,但和其他测试一起运行就失败
|
||||
- 测试的执行顺序影响结果
|
||||
- Mock 设置看起来正确,但实际使用的是旧的 Mock 版本
|
||||
|
||||
#### 典型场景:动态 Mock 同一模块
|
||||
|
||||
```typescript
|
||||
// ❌ 容易出现模块污染的写法
|
||||
describe('ConfigService', () => {
|
||||
it('should work in development mode', async () => {
|
||||
vi.doMock('./config', () => ({ isDev: true }));
|
||||
const { getSettings } = await import('./configService'); // 第一次加载
|
||||
expect(getSettings().debugMode).toBe(true);
|
||||
});
|
||||
|
||||
it('should work in production mode', async () => {
|
||||
vi.doMock('./config', () => ({ isDev: false }));
|
||||
const { getSettings } = await import('./configService'); // 可能使用缓存的旧版本!
|
||||
expect(getSettings().debugMode).toBe(false); // ❌ 可能失败
|
||||
});
|
||||
});
|
||||
|
||||
// ✅ 使用 resetModules 解决模块污染
|
||||
describe('ConfigService', () => {
|
||||
beforeEach(() => {
|
||||
vi.resetModules(); // 清除模块缓存,确保每个测试都是干净的环境
|
||||
});
|
||||
|
||||
it('should work in development mode', async () => {
|
||||
vi.doMock('./config', () => ({ isDev: true }));
|
||||
const { getSettings } = await import('./configService');
|
||||
expect(getSettings().debugMode).toBe(true);
|
||||
});
|
||||
|
||||
it('should work in production mode', async () => {
|
||||
vi.doMock('./config', () => ({ isDev: false }));
|
||||
const { getSettings } = await import('./configService');
|
||||
expect(getSettings().debugMode).toBe(false); // ✅ 测试通过
|
||||
});
|
||||
});
|
||||
```
|
||||
|
||||
#### 🔧 排查和解决步骤
|
||||
|
||||
1. **识别问题**: 测试失败时,首先问自己:"是否有多个测试在 Mock 同一个模块?"
|
||||
2. **添加隔离**: 在 `beforeEach` 中添加 `vi.resetModules()`
|
||||
3. **验证修复**: 重新运行测试,确认问题解决
|
||||
|
||||
**记住**: `vi.resetModules()` 是解决测试"灵异"失败的终极武器,当常规调试方法都无效时,它往往能一针见血地解决问题。
|
||||
|
||||
## 📂 测试文件组织
|
||||
|
||||
### 文件命名约定
|
||||
@@ -320,4 +490,7 @@ git show HEAD -- path/to/component.ts | cat # 查看最新提交的修改
|
||||
- **修复原则**: 失败1-2次后寻求帮助,测试命名关注行为而非实现细节
|
||||
- **调试流程**: 复现 → 分析 → 假设 → 修复 → 验证 → 总结
|
||||
- **文件组织**: 优先在现有 `describe` 块中添加测试,避免创建冗余顶级块
|
||||
- **数据策略**: 默认追求真实性,只有高成本(I/O、网络等)时才简化
|
||||
- **错误测试**: 测试错误类型和行为,避免依赖具体的错误信息文本
|
||||
- **模块污染**: 测试"灵异"失败时,优先怀疑模块污染,使用 `vi.resetModules()` 解决
|
||||
- **安全要求**: Model 测试必须包含权限检查,并在双环境下验证通过
|
||||
|
||||
@@ -625,4 +625,29 @@ If you need to use Azure OpenAI to provide model services, you can refer to the
|
||||
- Default: `-`
|
||||
- Example: `-all,+qwq-32b,+deepseek-r1`
|
||||
|
||||
## FAL
|
||||
|
||||
### `ENABLED_FAL`
|
||||
|
||||
- Type: Optional
|
||||
- Description: Enables FAL as a model provider by default. Set to `0` to disable the FAL service.
|
||||
- Default: `1`
|
||||
- Example: `0`
|
||||
|
||||
### `FAL_API_KEY`
|
||||
|
||||
- Type: Required
|
||||
- Description: This is the API key you applied for in the FAL service.
|
||||
- Default: -
|
||||
- Example: `fal-xxxxxx...xxxxxx`
|
||||
|
||||
### `FAL_MODEL_LIST`
|
||||
|
||||
- Type: Optional
|
||||
- Description: Used to control the FAL model list. Use `+` to add a model, `-` to hide a model, and `model_name=display_name` to customize the display name of a model. Separate multiple entries with commas. The definition syntax follows the same rules as other providers' model lists.
|
||||
- Default: `-`
|
||||
- Example: `-all,+fal-model-1,+fal-model-2=fal-special`
|
||||
|
||||
The above example disables all models first, then enables `fal-model-1` and `fal-model-2` (displayed as `fal-special`).
|
||||
|
||||
[model-list]: /docs/self-hosting/advanced/model-list
|
||||
|
||||
@@ -624,4 +624,29 @@ LobeChat 在部署时提供了丰富的模型服务商相关的环境变量,
|
||||
- 默认值:`-`
|
||||
- 示例:`-all,+qwq-32b,+deepseek-r1`
|
||||
|
||||
## FAL
|
||||
|
||||
### `ENABLED_FAL`
|
||||
|
||||
- 类型:可选
|
||||
- 描述:默认启用 FAL 作为模型供应商,当设为 0 时关闭 FAL 服务
|
||||
- 默认值:`1`
|
||||
- 示例:`0`
|
||||
|
||||
### `FAL_API_KEY`
|
||||
|
||||
- 类型:必选
|
||||
- 描述:这是你在 FAL 服务中申请的 API 密钥
|
||||
- 默认值:-
|
||||
- 示例:`fal-xxxxxx...xxxxxx`
|
||||
|
||||
### `FAL_MODEL_LIST`
|
||||
|
||||
- 类型:可选
|
||||
- 描述:用来控制 FAL 模型列表,使用 `+` 增加一个模型,使用 `-` 来隐藏一个模型,使用 `模型名=展示名` 来自定义模型的展示名,用英文逗号隔开。模型定义语法规则与其他 provider 保持一致。
|
||||
- 默认值:`-`
|
||||
- 示例:`-all,+fal-model-1,+fal-model-2=fal-special`
|
||||
|
||||
上述示例表示先禁用所有模型,再启用 `fal-model-1` 和 `fal-model-2`(显示名为 `fal-special`)。
|
||||
|
||||
[model-list]: /zh/docs/self-hosting/advanced/model-list
|
||||
|
||||
@@ -0,0 +1,65 @@
|
||||
---
|
||||
title: Resolving AI Image Generation Timeout on Vercel
|
||||
description: >-
|
||||
Learn how to resolve timeout issues when using AI image generation models like gpt-image-1 on Vercel by enabling Fluid Compute for extended execution time.
|
||||
|
||||
tags:
|
||||
- Vercel
|
||||
- AI Image Generation
|
||||
- Timeout
|
||||
- Fluid Compute
|
||||
- gpt-image-1
|
||||
---
|
||||
|
||||
# Resolving AI Image Generation Timeout on Vercel
|
||||
|
||||
## Problem Description
|
||||
|
||||
When using AI image generation models (such as `gpt-image-1`) on Vercel, you may encounter timeout errors. This occurs because AI image generation typically requires more than 1 minute to complete, which exceeds Vercel's default function execution time limit.
|
||||
|
||||
Common error symptoms include:
|
||||
|
||||
- Function timeout errors during image generation
|
||||
- Failed image generation requests after approximately 60 seconds
|
||||
- "Function execution timed out" messages
|
||||
|
||||
### Typical Log Symptoms
|
||||
|
||||
In your Vercel function logs, you may see entries like this:
|
||||
|
||||
```plaintext
|
||||
JUL 16 18:39:09.51 POST 504 /trpc/async/image.createImage
|
||||
Provider runtime map found for provider: openai
|
||||
```
|
||||
|
||||
The key indicators are:
|
||||
|
||||
- **Status Code**: `504` (Gateway Timeout)
|
||||
- **Endpoint**: `/trpc/async/image.createImage` or similar image generation endpoints
|
||||
- **Timing**: Usually occurs around 60 seconds after the request starts
|
||||
|
||||
## Solution: Enable Fluid Compute
|
||||
|
||||
For projects created before Vercel's dashboard update, you can resolve this issue by enabling Fluid Compute, which extends the maximum execution duration to 300 seconds.
|
||||
|
||||
### Steps to Enable Fluid Compute (Legacy Vercel Dashboard)
|
||||
|
||||
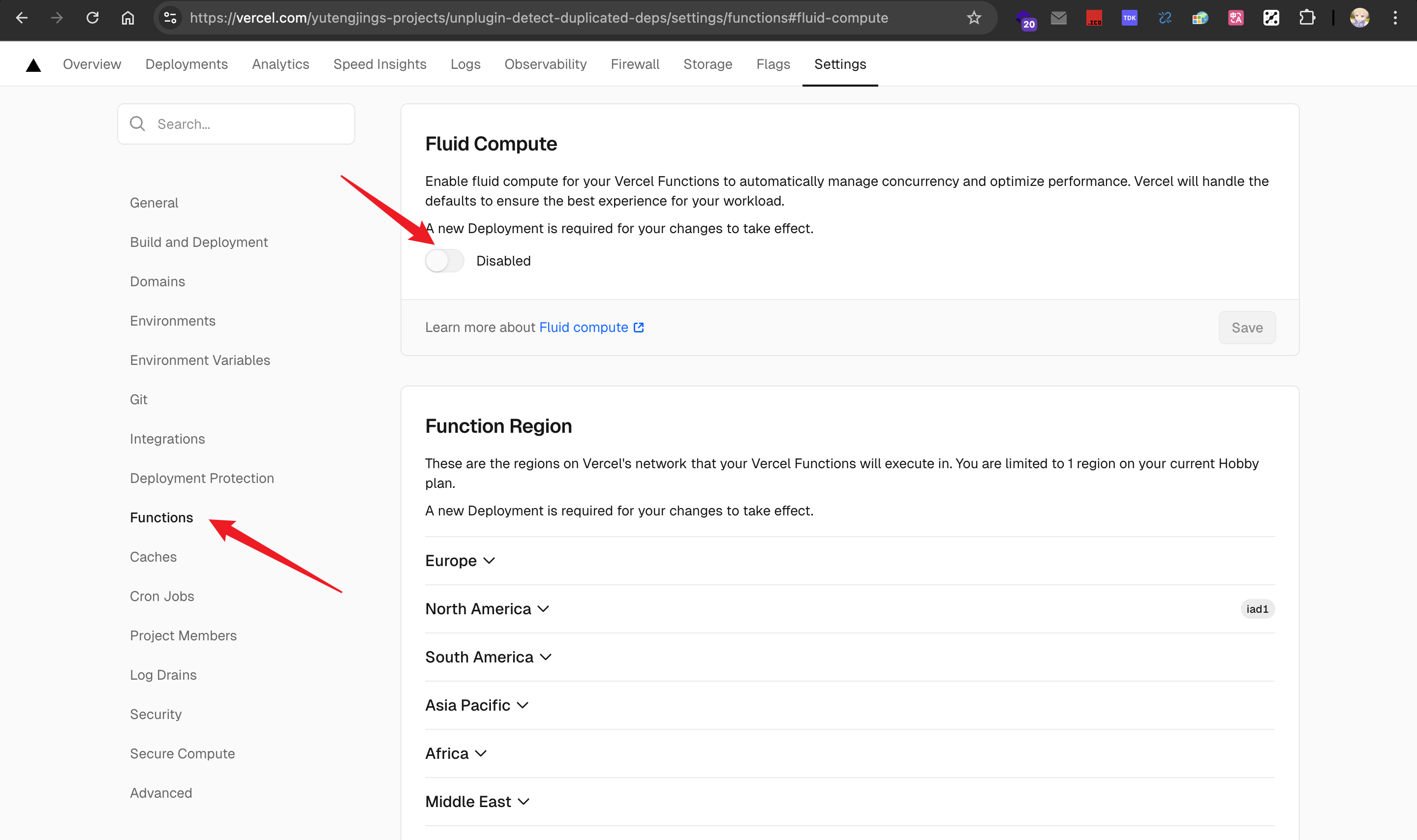
1. Go to your project dashboard on Vercel
|
||||
2. Navigate to the **Settings** tab
|
||||
3. Find the **Functions** section
|
||||
4. Enable **Fluid Compute** as shown in the screenshot below:
|
||||
|
||||
|
||||
|
||||
5. After enabling, the maximum execution duration will be extended to 300 seconds by default
|
||||
|
||||
### Important Notes
|
||||
|
||||
- **For new projects**: Newer Vercel projects have Fluid Compute enabled by default, so this issue primarily affects legacy projects
|
||||
|
||||
## Additional Resources
|
||||
|
||||
For more information about Vercel's function limitations and Fluid Compute:
|
||||
|
||||
- [Vercel Fluid Compute Documentation](https://vercel.com/docs/fluid-compute)
|
||||
- [Vercel Functions Limitations](https://vercel.com/docs/functions/limitations#max-duration)
|
||||
@@ -0,0 +1,63 @@
|
||||
---
|
||||
title: 解决 Vercel 上 AI 绘画生图超时问题
|
||||
description: 了解如何通过开启 Fluid Compute 来解决在 Vercel 上使用 gpt-image-1 等 AI 绘画模型时遇到的超时问题。
|
||||
tags:
|
||||
- Vercel
|
||||
- AI 绘画
|
||||
- 超时问题
|
||||
- Fluid Compute
|
||||
- gpt-image-1
|
||||
---
|
||||
|
||||
# 解决 Vercel 上 AI 绘画生图超时问题
|
||||
|
||||
## 问题描述
|
||||
|
||||
在 Vercel 上使用 AI 绘画模型(如 `gpt-image-1`)时,您可能会遇到超时错误。这是因为 AI 绘画生成通常需要超过 1 分钟的时间,超出了 Vercel 默认的函数执行时间限制。
|
||||
|
||||
常见的错误症状包括:
|
||||
|
||||
- 图像生成过程中出现函数超时错误
|
||||
- 图像生成请求在大约 60 秒后失败
|
||||
- 出现 "函数执行超时" 的错误消息
|
||||
|
||||
### 典型的日志现象
|
||||
|
||||
在您的 Vercel 函数日志中,您可能会看到类似这样的条目:
|
||||
|
||||
```plaintext
|
||||
JUL 16 18:39:09.51 POST 504 /trpc/async/image.createImage
|
||||
Provider runtime map found for provider: openai
|
||||
```
|
||||
|
||||
关键指标包括:
|
||||
|
||||
- **状态码**: `504`(网关超时)
|
||||
- **端点**: `/trpc/async/image.createImage` 或类似的图像生成端点
|
||||
- **时间**: 通常在请求开始后约 60 秒出现
|
||||
|
||||
## 解决方案:开启 Fluid Compute
|
||||
|
||||
对于在 Vercel 控制台更新前创建的项目,您可以通过开启 Fluid Compute 来解决此问题,这将最大执行时长延长至 300 秒。
|
||||
|
||||
### 开启 Fluid Compute 的步骤(旧版 Vercel 控制台)
|
||||
|
||||
1. 前往您在 Vercel 上的项目控制台
|
||||
2. 进入 **Settings**(设置)选项卡
|
||||
3. 找到 **Functions**(函数)部分
|
||||
4. 按照下方截图所示开启 **Fluid Compute**:
|
||||
|
||||

|
||||
|
||||
5. 开启后,最大执行时长将默认延长至 300 秒
|
||||
|
||||
### 重要说明
|
||||
|
||||
- **新项目**:较新的 Vercel 项目默认已启用 Fluid Compute,因此此问题主要影响旧版项目
|
||||
|
||||
## 其他资源
|
||||
|
||||
有关 Vercel 函数限制和 Fluid Compute 的更多信息:
|
||||
|
||||
- [Vercel Fluid Compute 文档](https://vercel.com/docs/fluid-compute)
|
||||
- [Vercel 函数限制说明](https://vercel.com/docs/functions/limitations#max-duration)
|
||||
@@ -13,7 +13,7 @@ tags:
|
||||
|
||||
# Using Fal in LobeChat
|
||||
|
||||
<Image alt={'Using Fal in LobeChat'} cover src={'https://github.com/user-attachments/assets/febb2ffb-8fe8-4f88-b8c9-8fa0985a2352'} />
|
||||
<Image alt={'Using Fal in LobeChat'} cover src={'https://hub-apac-1.lobeobjects.space/docs/f253e749baaa2ccac498014178f93091.png'} />
|
||||
|
||||
[Fal.ai](https://fal.ai/) is a lightning-fast inference platform specialized in AI media generation, hosting state-of-the-art models for image and video creation including FLUX, Kling, HiDream, and other cutting-edge generative models. This document will guide you on how to use Fal in LobeChat:
|
||||
|
||||
@@ -28,7 +28,7 @@ tags:
|
||||
alt={'Open the creation window'}
|
||||
inStep
|
||||
src={
|
||||
'https://github.com/user-attachments/assets/a2203b3a-1657-485a-a060-b018e7b2faaa'
|
||||
'https://hub-apac-1.lobeobjects.space/docs/3f3676e7f9c04a55603bc1174b636b45.png'
|
||||
}
|
||||
/>
|
||||
|
||||
@@ -36,7 +36,7 @@ tags:
|
||||
alt={'Create API Key'}
|
||||
inStep
|
||||
src={
|
||||
'https://github.com/user-attachments/assets/a216e326-6a51-4f3a-b8c1-23bb995ddac2'
|
||||
'https://hub-apac-1.lobeobjects.space/docs/214cc5019d9c0810951b33215349136e.png'
|
||||
}
|
||||
/>
|
||||
|
||||
@@ -44,7 +44,7 @@ tags:
|
||||
alt={'Retrieve API Key'}
|
||||
inStep
|
||||
src={
|
||||
'https://github.com/user-attachments/assets/faee998d-4349-4c17-a5c4-07a7ff65f18e'
|
||||
'https://hub-apac-1.lobeobjects.space/docs/499a447e98dcc79407d56495d0305e2a.png'
|
||||
}
|
||||
/>
|
||||
|
||||
@@ -53,12 +53,12 @@ tags:
|
||||
- Visit the `Settings` page in LobeChat.
|
||||
- Under **AI Service Provider**, locate the **Fal** configuration section.
|
||||
|
||||
<Image alt={'Enter API Key'} inStep src={'https://github.com/user-attachments/assets/7566f679-f935-4a5b-9c98-a8d99d9c7994'} />
|
||||
<Image alt={'Enter API Key'} inStep src={'https://hub-apac-1.lobeobjects.space/docs/fa056feecba0133c76abe1ad12706c05.png'} />
|
||||
|
||||
- Paste the API key you obtained.
|
||||
- Choose a Fal model (e.g. `fal-ai/flux-pro`, `fal-ai/kling-video`, `fal-ai/hidream-i1-fast`) for image or video generation.
|
||||
|
||||
<Image alt={'Select Fal model for media generation'} inStep src={'https://github.com/user-attachments/assets/817167ff-4723-4f84-8528-c779c5c3a118'} />
|
||||
<Image alt={'Select Fal model for media generation'} inStep src={'https://hub-apac-1.lobeobjects.space/docs/7560502f31b8500032922103fc22e69b.png'} />
|
||||
|
||||
<Callout type={'warning'}>
|
||||
During usage, you may incur charges according to Fal's pricing policy. Please review Fal's
|
||||
|
||||
@@ -13,7 +13,7 @@ tags:
|
||||
|
||||
# 在 LobeChat 中使用 Fal
|
||||
|
||||
<Image alt={'在 LobeChat 中使用 Fal'} cover src={'https://github.com/user-attachments/assets/febb2ffb-8fe8-4f88-b8c9-8fa0985a2352'} />
|
||||
<Image alt={'在 LobeChat 中使用 Fal'} cover src={'https://hub-apac-1.lobeobjects.space/docs/f253e749baaa2ccac498014178f93091.png'} />
|
||||
|
||||
[Fal.ai](https://fal.ai/) 是一个专门从事 AI 媒体生成的快速推理平台,提供包括 FLUX、Kling、HiDream 等在内的最先进图像和视频生成模型。本文将指导你如何在 LobeChat 中使用 Fal:
|
||||
|
||||
@@ -28,7 +28,7 @@ tags:
|
||||
alt={'打开创建窗口'}
|
||||
inStep
|
||||
src={
|
||||
'https://github.com/user-attachments/assets/a2203b3a-1657-485a-a060-b018e7b2faaa'
|
||||
'https://hub-apac-1.lobeobjects.space/docs/3f3676e7f9c04a55603bc1174b636b45.png'
|
||||
}
|
||||
/>
|
||||
|
||||
@@ -36,7 +36,7 @@ tags:
|
||||
alt={'创建 API Key'}
|
||||
inStep
|
||||
src={
|
||||
'https://github.com/user-attachments/assets/a216e326-6a51-4f3a-b8c1-23bb995ddac2'
|
||||
'https://hub-apac-1.lobeobjects.space/docs/214cc5019d9c0810951b33215349136e.png'
|
||||
}
|
||||
/>
|
||||
|
||||
@@ -44,7 +44,7 @@ tags:
|
||||
alt={'获取 API Key'}
|
||||
inStep
|
||||
src={
|
||||
'https://github.com/user-attachments/assets/faee998d-4349-4c17-a5c4-07a7ff65f18e'
|
||||
'https://hub-apac-1.lobeobjects.space/docs/499a447e98dcc79407d56495d0305e2a.png'
|
||||
}
|
||||
/>
|
||||
|
||||
@@ -53,12 +53,12 @@ tags:
|
||||
- 访问 LobeChat 的 `设置` 页面;
|
||||
- 在 `AI服务商` 下找到 `Fal` 的设置项;
|
||||
|
||||
<Image alt={'填入 API 密钥'} inStep src={'https://github.com/user-attachments/assets/7566f679-f935-4a5b-9c98-a8d99d9c7994'} />
|
||||
<Image alt={'填入 API 密钥'} inStep src={'https://hub-apac-1.lobeobjects.space/docs/fa056feecba0133c76abe1ad12706c05.png'} />
|
||||
|
||||
- 粘贴获取到的 API Key;
|
||||
- 选择一个 Fal 模型(如 `fal-ai/flux-pro`、`fal-ai/kling-video`、`fal-ai/hidream-i1-fast`)用于图像或视频生成。
|
||||
|
||||
<Image alt={'选择 Fal 模型进行媒体生成'} inStep src={'https://github.com/user-attachments/assets/817167ff-4723-4f84-8528-c779c5c3a118'} />
|
||||
<Image alt={'选择 Fal 模型进行媒体生成'} inStep src={'https://hub-apac-1.lobeobjects.space/docs/7560502f31b8500032922103fc22e69b.png'} />
|
||||
|
||||
<Callout type={'warning'}>
|
||||
在使用过程中,你可能需要向 Fal 支付相应费用,请在大量调用前查阅 Fal 的官方计费政策。
|
||||
|
||||
@@ -1392,7 +1392,7 @@ describe('LobeOpenAICompatibleFactory', () => {
|
||||
{
|
||||
id: 'gemini',
|
||||
releasedAt: '2025-01-10',
|
||||
type: undefined,
|
||||
type: 'chat',
|
||||
},
|
||||
]);
|
||||
});
|
||||
|
||||
@@ -7,6 +7,7 @@ import { Stream } from 'openai/streaming';
|
||||
import { LOBE_DEFAULT_MODEL_LIST } from '@/config/aiModels';
|
||||
import { RuntimeImageGenParamsValue } from '@/libs/standard-parameters/meta-schema';
|
||||
import type { ChatModelCard } from '@/types/llm';
|
||||
import { getModelPropertyWithFallback } from '@/utils/getFallbackModelProperty';
|
||||
|
||||
import { LobeRuntimeAI } from '../../BaseAI';
|
||||
import { AgentRuntimeErrorType, ILobeAgentRuntimeErrorType } from '../../error';
|
||||
@@ -462,7 +463,7 @@ export const createOpenAICompatibleRuntime = <T extends Record<string, any> = an
|
||||
return resultModels.map((model) => {
|
||||
return {
|
||||
...model,
|
||||
type: model.type || LOBE_DEFAULT_MODEL_LIST.find((m) => m.id === model.id)?.type,
|
||||
type: model.type || getModelPropertyWithFallback(model.id, 'type'),
|
||||
};
|
||||
}) as ChatModelCard[];
|
||||
}
|
||||
|
||||
@@ -0,0 +1,235 @@
|
||||
import { beforeEach, describe, expect, it, vi } from 'vitest';
|
||||
|
||||
import { ModelProvider } from '@/libs/model-runtime';
|
||||
import { AiFullModelCard } from '@/types/aiModel';
|
||||
|
||||
import { genServerAiProvidersConfig } from './genServerAiProviderConfig';
|
||||
|
||||
// Mock dependencies using importOriginal to preserve real provider data
|
||||
vi.mock('@/config/aiModels', async (importOriginal) => {
|
||||
const actual = await importOriginal<typeof import('@/config/aiModels')>();
|
||||
return {
|
||||
...actual,
|
||||
// Keep the original exports but we can override specific ones if needed
|
||||
};
|
||||
});
|
||||
|
||||
vi.mock('@/config/llm', () => ({
|
||||
getLLMConfig: vi.fn(() => ({
|
||||
ENABLED_OPENAI: true,
|
||||
ENABLED_ANTHROPIC: false,
|
||||
ENABLED_AI21: false,
|
||||
})),
|
||||
}));
|
||||
|
||||
vi.mock('@/utils/parseModels', () => ({
|
||||
extractEnabledModels: vi.fn((providerId: string, modelString?: string) => {
|
||||
if (!modelString) return undefined;
|
||||
return [`${providerId}-model-1`, `${providerId}-model-2`];
|
||||
}),
|
||||
transformToAiModelList: vi.fn((params) => {
|
||||
return params.defaultModels;
|
||||
}),
|
||||
}));
|
||||
|
||||
describe('genServerAiProvidersConfig', () => {
|
||||
beforeEach(() => {
|
||||
vi.clearAllMocks();
|
||||
// Clear environment variables
|
||||
Object.keys(process.env).forEach((key) => {
|
||||
if (key.includes('MODEL_LIST')) {
|
||||
delete process.env[key];
|
||||
}
|
||||
});
|
||||
});
|
||||
|
||||
it('should generate basic provider config with default settings', () => {
|
||||
const result = genServerAiProvidersConfig({});
|
||||
|
||||
expect(result).toHaveProperty('openai');
|
||||
expect(result).toHaveProperty('anthropic');
|
||||
|
||||
expect(result.openai).toEqual({
|
||||
enabled: true,
|
||||
enabledModels: undefined,
|
||||
serverModelLists: expect.any(Array),
|
||||
});
|
||||
|
||||
expect(result.anthropic).toEqual({
|
||||
enabled: false,
|
||||
enabledModels: undefined,
|
||||
serverModelLists: expect.any(Array),
|
||||
});
|
||||
});
|
||||
|
||||
it('should use custom enabled settings from specificConfig', () => {
|
||||
const specificConfig = {
|
||||
openai: {
|
||||
enabled: false,
|
||||
},
|
||||
anthropic: {
|
||||
enabled: true,
|
||||
},
|
||||
};
|
||||
|
||||
const result = genServerAiProvidersConfig(specificConfig);
|
||||
|
||||
expect(result.openai.enabled).toBe(false);
|
||||
expect(result.anthropic.enabled).toBe(true);
|
||||
});
|
||||
|
||||
it('should use custom enabledKey from specificConfig', async () => {
|
||||
const specificConfig = {
|
||||
openai: {
|
||||
enabledKey: 'CUSTOM_OPENAI_ENABLED',
|
||||
},
|
||||
};
|
||||
|
||||
// Mock the LLM config to include our custom key
|
||||
const { getLLMConfig } = vi.mocked(await import('@/config/llm'));
|
||||
getLLMConfig.mockReturnValue({
|
||||
ENABLED_OPENAI: true,
|
||||
ENABLED_ANTHROPIC: false,
|
||||
CUSTOM_OPENAI_ENABLED: true,
|
||||
} as any);
|
||||
|
||||
const result = genServerAiProvidersConfig(specificConfig);
|
||||
|
||||
expect(result.openai.enabled).toBe(true);
|
||||
});
|
||||
|
||||
it('should use environment variables for model lists', async () => {
|
||||
process.env.OPENAI_MODEL_LIST = '+gpt-4,+gpt-3.5-turbo';
|
||||
|
||||
const { extractEnabledModels } = vi.mocked(await import('@/utils/parseModels'));
|
||||
extractEnabledModels.mockReturnValue(['gpt-4', 'gpt-3.5-turbo']);
|
||||
|
||||
const result = genServerAiProvidersConfig({});
|
||||
|
||||
expect(extractEnabledModels).toHaveBeenCalledWith('openai', '+gpt-4,+gpt-3.5-turbo', false);
|
||||
expect(result.openai.enabledModels).toEqual(['gpt-4', 'gpt-3.5-turbo']);
|
||||
});
|
||||
|
||||
it('should use custom modelListKey from specificConfig', async () => {
|
||||
const specificConfig = {
|
||||
openai: {
|
||||
modelListKey: 'CUSTOM_OPENAI_MODELS',
|
||||
},
|
||||
};
|
||||
|
||||
process.env.CUSTOM_OPENAI_MODELS = '+custom-model';
|
||||
|
||||
const { extractEnabledModels } = vi.mocked(await import('@/utils/parseModels'));
|
||||
|
||||
genServerAiProvidersConfig(specificConfig);
|
||||
|
||||
expect(extractEnabledModels).toHaveBeenCalledWith('openai', '+custom-model', false);
|
||||
});
|
||||
|
||||
it('should handle withDeploymentName option', async () => {
|
||||
const specificConfig = {
|
||||
openai: {
|
||||
withDeploymentName: true,
|
||||
},
|
||||
};
|
||||
|
||||
process.env.OPENAI_MODEL_LIST = '+gpt-4->deployment1';
|
||||
|
||||
const { extractEnabledModels, transformToAiModelList } = vi.mocked(
|
||||
await import('@/utils/parseModels'),
|
||||
);
|
||||
|
||||
genServerAiProvidersConfig(specificConfig);
|
||||
|
||||
expect(extractEnabledModels).toHaveBeenCalledWith('openai', '+gpt-4->deployment1', true);
|
||||
expect(transformToAiModelList).toHaveBeenCalledWith({
|
||||
defaultModels: expect.any(Array),
|
||||
modelString: '+gpt-4->deployment1',
|
||||
providerId: 'openai',
|
||||
withDeploymentName: true,
|
||||
});
|
||||
});
|
||||
|
||||
it('should include fetchOnClient when specified in config', () => {
|
||||
const specificConfig = {
|
||||
openai: {
|
||||
fetchOnClient: true,
|
||||
},
|
||||
};
|
||||
|
||||
const result = genServerAiProvidersConfig(specificConfig);
|
||||
|
||||
expect(result.openai).toHaveProperty('fetchOnClient', true);
|
||||
});
|
||||
|
||||
it('should not include fetchOnClient when not specified in config', () => {
|
||||
const result = genServerAiProvidersConfig({});
|
||||
|
||||
expect(result.openai).not.toHaveProperty('fetchOnClient');
|
||||
});
|
||||
|
||||
it('should handle all available providers', () => {
|
||||
const result = genServerAiProvidersConfig({});
|
||||
|
||||
// Check that result includes some key providers
|
||||
expect(result).toHaveProperty('openai');
|
||||
expect(result).toHaveProperty('anthropic');
|
||||
|
||||
// Check structure for each provider
|
||||
Object.keys(result).forEach((provider) => {
|
||||
expect(result[provider]).toHaveProperty('enabled');
|
||||
expect(result[provider]).toHaveProperty('serverModelLists');
|
||||
// enabled can be boolean or undefined (when no config is provided)
|
||||
expect(['boolean', 'undefined']).toContain(typeof result[provider].enabled);
|
||||
expect(Array.isArray(result[provider].serverModelLists)).toBe(true);
|
||||
});
|
||||
});
|
||||
});
|
||||
|
||||
describe('genServerAiProvidersConfig Error Handling', () => {
|
||||
it('should throw error when a provider is not found in aiModels', async () => {
|
||||
// Reset all mocks to create a clean test environment
|
||||
vi.resetModules();
|
||||
|
||||
// Mock dependencies with a missing provider scenario
|
||||
vi.doMock('@/config/aiModels', () => ({
|
||||
// Explicitly set openai to undefined to simulate missing provider
|
||||
openai: undefined,
|
||||
anthropic: [
|
||||
{
|
||||
id: 'claude-3',
|
||||
displayName: 'Claude 3',
|
||||
type: 'chat',
|
||||
enabled: true,
|
||||
},
|
||||
],
|
||||
}));
|
||||
|
||||
vi.doMock('@/config/llm', () => ({
|
||||
getLLMConfig: vi.fn(() => ({})),
|
||||
}));
|
||||
|
||||
vi.doMock('@/utils/parseModels', () => ({
|
||||
extractEnabledModels: vi.fn(() => undefined),
|
||||
transformToAiModelList: vi.fn(() => []),
|
||||
}));
|
||||
|
||||
// Mock ModelProvider to include the missing provider
|
||||
vi.doMock('@/libs/model-runtime', () => ({
|
||||
ModelProvider: {
|
||||
openai: 'openai', // This exists in enum
|
||||
anthropic: 'anthropic', // This exists in both enum and aiModels
|
||||
},
|
||||
}));
|
||||
|
||||
// Import the function with the new mocks
|
||||
const { genServerAiProvidersConfig } = await import(
|
||||
'./genServerAiProviderConfig?v=' + Date.now()
|
||||
);
|
||||
|
||||
// This should throw because 'openai' is in ModelProvider but not in aiModels
|
||||
expect(() => {
|
||||
genServerAiProvidersConfig({});
|
||||
}).toThrow();
|
||||
});
|
||||
});
|
||||
@@ -3,7 +3,7 @@ import { getLLMConfig } from '@/config/llm';
|
||||
import { ModelProvider } from '@/libs/model-runtime';
|
||||
import { AiFullModelCard } from '@/types/aiModel';
|
||||
import { ProviderConfig } from '@/types/user/settings';
|
||||
import { extractEnabledModels, transformToAiChatModelList } from '@/utils/parseModels';
|
||||
import { extractEnabledModels, transformToAiModelList } from '@/utils/parseModels';
|
||||
|
||||
interface ProviderSpecificConfig {
|
||||
enabled?: boolean;
|
||||
@@ -19,19 +19,17 @@ export const genServerAiProvidersConfig = (specificConfig: Record<any, ProviderS
|
||||
return Object.values(ModelProvider).reduce(
|
||||
(config, provider) => {
|
||||
const providerUpperCase = provider.toUpperCase();
|
||||
const providerCard = AiModels[provider] as AiFullModelCard[];
|
||||
const aiModels = AiModels[provider] as AiFullModelCard[];
|
||||
|
||||
if (!providerCard)
|
||||
if (!aiModels)
|
||||
throw new Error(
|
||||
`Provider [${provider}] not found in aiModels, please make sure you have exported the provider in the \`aiModels/index.ts\``,
|
||||
);
|
||||
|
||||
const providerConfig = specificConfig[provider as keyof typeof specificConfig] || {};
|
||||
const providerModelList =
|
||||
const modelString =
|
||||
process.env[providerConfig.modelListKey ?? `${providerUpperCase}_MODEL_LIST`];
|
||||
|
||||
const defaultChatModels = providerCard.filter((c) => c.type === 'chat');
|
||||
|
||||
config[provider] = {
|
||||
enabled:
|
||||
typeof providerConfig.enabled !== 'undefined'
|
||||
@@ -39,12 +37,13 @@ export const genServerAiProvidersConfig = (specificConfig: Record<any, ProviderS
|
||||
: llmConfig[providerConfig.enabledKey || `ENABLED_${providerUpperCase}`],
|
||||
|
||||
enabledModels: extractEnabledModels(
|
||||
providerModelList,
|
||||
provider,
|
||||
modelString,
|
||||
providerConfig.withDeploymentName || false,
|
||||
),
|
||||
serverModelLists: transformToAiChatModelList({
|
||||
defaultChatModels: defaultChatModels || [],
|
||||
modelString: providerModelList,
|
||||
serverModelLists: transformToAiModelList({
|
||||
defaultModels: aiModels || [],
|
||||
modelString,
|
||||
providerId: provider,
|
||||
withDeploymentName: providerConfig.withDeploymentName || false,
|
||||
}),
|
||||
|
||||
@@ -19,6 +19,7 @@ import {
|
||||
UpdateAiProviderConfigParams,
|
||||
UpdateAiProviderParams,
|
||||
} from '@/types/aiProvider';
|
||||
import { getModelPropertyWithFallback } from '@/utils/getFallbackModelProperty';
|
||||
|
||||
enum AiProviderSwrKey {
|
||||
fetchAiProviderItem = 'FETCH_AI_PROVIDER_ITEM',
|
||||
@@ -216,7 +217,7 @@ export const createAiProviderSlice: StateCreator<
|
||||
...(model.type === 'image' && {
|
||||
parameters:
|
||||
(model as AIImageModelCard).parameters ||
|
||||
LOBE_DEFAULT_MODEL_LIST.find((m) => m.id === model.id)?.parameters,
|
||||
getModelPropertyWithFallback(model.id, 'parameters'),
|
||||
}),
|
||||
}));
|
||||
|
||||
|
||||
@@ -0,0 +1,193 @@
|
||||
import { vi } from 'vitest';
|
||||
|
||||
import { getModelPropertyWithFallback } from './getFallbackModelProperty';
|
||||
|
||||
// Mock LOBE_DEFAULT_MODEL_LIST for testing
|
||||
vi.mock('@/config/aiModels', () => ({
|
||||
LOBE_DEFAULT_MODEL_LIST: [
|
||||
{
|
||||
id: 'gpt-4',
|
||||
providerId: 'openai',
|
||||
type: 'chat',
|
||||
displayName: 'GPT-4',
|
||||
contextWindowTokens: 8192,
|
||||
enabled: true,
|
||||
abilities: {
|
||||
functionCall: true,
|
||||
vision: true,
|
||||
},
|
||||
parameters: {
|
||||
temperature: 0.7,
|
||||
maxTokens: 4096,
|
||||
},
|
||||
},
|
||||
{
|
||||
id: 'gpt-4',
|
||||
providerId: 'azure',
|
||||
type: 'chat',
|
||||
displayName: 'GPT-4 Azure',
|
||||
contextWindowTokens: 8192,
|
||||
enabled: true,
|
||||
abilities: {
|
||||
functionCall: true,
|
||||
},
|
||||
},
|
||||
{
|
||||
id: 'claude-3',
|
||||
providerId: 'anthropic',
|
||||
type: 'chat',
|
||||
displayName: 'Claude 3',
|
||||
contextWindowTokens: 200000,
|
||||
enabled: false,
|
||||
},
|
||||
{
|
||||
id: 'dall-e-3',
|
||||
providerId: 'openai',
|
||||
type: 'image',
|
||||
displayName: 'DALL-E 3',
|
||||
enabled: true,
|
||||
parameters: {
|
||||
size: '1024x1024',
|
||||
quality: 'standard',
|
||||
},
|
||||
},
|
||||
],
|
||||
}));
|
||||
|
||||
describe('getModelPropertyWithFallback', () => {
|
||||
describe('when providerId is specified', () => {
|
||||
it('should return exact match value when model exists with specified provider', () => {
|
||||
const result = getModelPropertyWithFallback('gpt-4', 'displayName', 'openai');
|
||||
expect(result).toBe('GPT-4');
|
||||
});
|
||||
|
||||
it('should return exact match type when model exists with specified provider', () => {
|
||||
const result = getModelPropertyWithFallback('gpt-4', 'type', 'openai');
|
||||
expect(result).toBe('chat');
|
||||
});
|
||||
|
||||
it('should return exact match contextWindowTokens when model exists with specified provider', () => {
|
||||
const result = getModelPropertyWithFallback('gpt-4', 'contextWindowTokens', 'azure');
|
||||
expect(result).toBe(8192);
|
||||
});
|
||||
|
||||
it('should fall back to other provider when exact provider match not found', () => {
|
||||
const result = getModelPropertyWithFallback('gpt-4', 'displayName', 'fake-provider');
|
||||
expect(result).toBe('GPT-4'); // Falls back to openai provider
|
||||
});
|
||||
|
||||
it('should return nested property like abilities', () => {
|
||||
const result = getModelPropertyWithFallback('gpt-4', 'abilities', 'openai');
|
||||
expect(result).toEqual({
|
||||
functionCall: true,
|
||||
vision: true,
|
||||
});
|
||||
});
|
||||
|
||||
it('should return parameters property correctly', () => {
|
||||
const result = getModelPropertyWithFallback('dall-e-3', 'parameters', 'openai');
|
||||
expect(result).toEqual({
|
||||
size: '1024x1024',
|
||||
quality: 'standard',
|
||||
});
|
||||
});
|
||||
});
|
||||
|
||||
describe('when providerId is not specified', () => {
|
||||
it('should return fallback match value when model exists', () => {
|
||||
const result = getModelPropertyWithFallback('claude-3', 'displayName');
|
||||
expect(result).toBe('Claude 3');
|
||||
});
|
||||
|
||||
it('should return fallback match type when model exists', () => {
|
||||
const result = getModelPropertyWithFallback('claude-3', 'type');
|
||||
expect(result).toBe('chat');
|
||||
});
|
||||
|
||||
it('should return fallback match enabled property', () => {
|
||||
const result = getModelPropertyWithFallback('claude-3', 'enabled');
|
||||
expect(result).toBe(false);
|
||||
});
|
||||
});
|
||||
|
||||
describe('when model is not found', () => {
|
||||
it('should return default value "chat" for type property', () => {
|
||||
const result = getModelPropertyWithFallback('non-existent-model', 'type');
|
||||
expect(result).toBe('chat');
|
||||
});
|
||||
|
||||
it('should return default value "chat" for type property even with providerId', () => {
|
||||
const result = getModelPropertyWithFallback('non-existent-model', 'type', 'fake-provider');
|
||||
expect(result).toBe('chat');
|
||||
});
|
||||
|
||||
it('should return undefined for non-type properties when model not found', () => {
|
||||
const result = getModelPropertyWithFallback('non-existent-model', 'displayName');
|
||||
expect(result).toBeUndefined();
|
||||
});
|
||||
|
||||
it('should return undefined for contextWindowTokens when model not found', () => {
|
||||
const result = getModelPropertyWithFallback('non-existent-model', 'contextWindowTokens');
|
||||
expect(result).toBeUndefined();
|
||||
});
|
||||
|
||||
it('should return undefined for enabled property when model not found', () => {
|
||||
const result = getModelPropertyWithFallback('non-existent-model', 'enabled');
|
||||
expect(result).toBeUndefined();
|
||||
});
|
||||
});
|
||||
|
||||
describe('provider precedence logic', () => {
|
||||
it('should prioritize exact provider match over general match', () => {
|
||||
// gpt-4 exists in both openai and azure providers with different displayNames
|
||||
const openaiResult = getModelPropertyWithFallback('gpt-4', 'displayName', 'openai');
|
||||
const azureResult = getModelPropertyWithFallback('gpt-4', 'displayName', 'azure');
|
||||
|
||||
expect(openaiResult).toBe('GPT-4');
|
||||
expect(azureResult).toBe('GPT-4 Azure');
|
||||
});
|
||||
|
||||
it('should fall back to first match when specified provider not found', () => {
|
||||
// When asking for 'fake-provider', should fall back to first match (openai)
|
||||
const result = getModelPropertyWithFallback('gpt-4', 'displayName', 'fake-provider');
|
||||
expect(result).toBe('GPT-4');
|
||||
});
|
||||
});
|
||||
|
||||
describe('property existence handling', () => {
|
||||
it('should handle undefined properties gracefully', () => {
|
||||
// claude-3 doesn't have abilities property defined
|
||||
const result = getModelPropertyWithFallback('claude-3', 'abilities');
|
||||
expect(result).toBeUndefined();
|
||||
});
|
||||
|
||||
it('should handle properties that exist but have falsy values', () => {
|
||||
// claude-3 has enabled: false
|
||||
const result = getModelPropertyWithFallback('claude-3', 'enabled');
|
||||
expect(result).toBe(false);
|
||||
});
|
||||
|
||||
it('should distinguish between undefined and null values', () => {
|
||||
// Testing that we check for undefined specifically, not just falsy values
|
||||
const result = getModelPropertyWithFallback('claude-3', 'contextWindowTokens');
|
||||
expect(result).toBe(200000); // Should find the defined value
|
||||
});
|
||||
});
|
||||
|
||||
describe('edge cases', () => {
|
||||
it('should handle empty string modelId', () => {
|
||||
const result = getModelPropertyWithFallback('', 'type');
|
||||
expect(result).toBe('chat'); // Should fall back to default
|
||||
});
|
||||
|
||||
it('should handle empty string providerId', () => {
|
||||
const result = getModelPropertyWithFallback('gpt-4', 'type', '');
|
||||
expect(result).toBe('chat'); // Should still find the model via fallback
|
||||
});
|
||||
|
||||
it('should handle case-sensitive modelId correctly', () => {
|
||||
const result = getModelPropertyWithFallback('GPT-4', 'type'); // Wrong case
|
||||
expect(result).toBe('chat'); // Should fall back to default since no match
|
||||
});
|
||||
});
|
||||
});
|
||||
@@ -0,0 +1,36 @@
|
||||
import { LOBE_DEFAULT_MODEL_LIST } from '@/config/aiModels';
|
||||
import { AiFullModelCard } from '@/types/aiModel';
|
||||
|
||||
/**
|
||||
* Get the model property value, first from the specified provider, and then from other providers as a fallback.
|
||||
* @param modelId The ID of the model.
|
||||
* @param propertyName The name of the property.
|
||||
* @param providerId Optional provider ID for an exact match.
|
||||
* @returns The property value or a default value.
|
||||
*/
|
||||
export const getModelPropertyWithFallback = <T>(
|
||||
modelId: string,
|
||||
propertyName: keyof AiFullModelCard,
|
||||
providerId?: string,
|
||||
): T => {
|
||||
// Step 1: If providerId is provided, prioritize an exact match (same provider + same id)
|
||||
if (providerId) {
|
||||
const exactMatch = LOBE_DEFAULT_MODEL_LIST.find(
|
||||
(m) => m.id === modelId && m.providerId === providerId,
|
||||
);
|
||||
|
||||
if (exactMatch && exactMatch[propertyName] !== undefined) {
|
||||
return exactMatch[propertyName] as T;
|
||||
}
|
||||
}
|
||||
|
||||
// Step 2: Fallback to a match ignoring the provider (match id only)
|
||||
const fallbackMatch = LOBE_DEFAULT_MODEL_LIST.find((m) => m.id === modelId);
|
||||
|
||||
if (fallbackMatch && fallbackMatch[propertyName] !== undefined) {
|
||||
return fallbackMatch[propertyName] as T;
|
||||
}
|
||||
|
||||
// Step 3: Return a default value
|
||||
return (propertyName === 'type' ? 'chat' : undefined) as T;
|
||||
};
|
||||
+150
-48
@@ -4,11 +4,12 @@ import { LOBE_DEFAULT_MODEL_LIST } from '@/config/aiModels';
|
||||
import { openaiChatModels } from '@/config/aiModels/openai';
|
||||
import { AiFullModelCard } from '@/types/aiModel';
|
||||
|
||||
import { parseModelString, transformToAiChatModelList } from './parseModels';
|
||||
import { extractEnabledModels, parseModelString, transformToAiModelList } from './parseModels';
|
||||
|
||||
describe('parseModelString', () => {
|
||||
it('custom deletion, addition, and renaming of models', () => {
|
||||
const result = parseModelString(
|
||||
'test-provider',
|
||||
'-all,+llama,+claude-2,-gpt-3.5-turbo,gpt-4-1106-preview=gpt-4-turbo,gpt-4-1106-preview=gpt-4-32k',
|
||||
);
|
||||
|
||||
@@ -16,24 +17,30 @@ describe('parseModelString', () => {
|
||||
});
|
||||
|
||||
it('duplicate naming model', () => {
|
||||
const result = parseModelString('gpt-4-1106-preview=gpt-4-turbo,gpt-4-1106-preview=gpt-4-32k');
|
||||
const result = parseModelString(
|
||||
'test-provider',
|
||||
'gpt-4-1106-preview=gpt-4-turbo,gpt-4-1106-preview=gpt-4-32k',
|
||||
);
|
||||
expect(result).toMatchSnapshot();
|
||||
});
|
||||
|
||||
it('only add the model', () => {
|
||||
const result = parseModelString('model1,model2,model3,model4');
|
||||
const result = parseModelString('test-provider', 'model1,model2,model3,model4');
|
||||
|
||||
expect(result).toMatchSnapshot();
|
||||
});
|
||||
|
||||
it('empty string model', () => {
|
||||
const result = parseModelString('gpt-4-1106-preview=gpt-4-turbo,, ,\n ,+claude-2');
|
||||
const result = parseModelString(
|
||||
'test-provider',
|
||||
'gpt-4-1106-preview=gpt-4-turbo,, ,\n ,+claude-2',
|
||||
);
|
||||
expect(result).toMatchSnapshot();
|
||||
});
|
||||
|
||||
describe('extension capabilities', () => {
|
||||
it('with token', () => {
|
||||
const result = parseModelString('chatglm-6b=ChatGLM 6B<4096>');
|
||||
const result = parseModelString('test-provider', 'chatglm-6b=ChatGLM 6B<4096>');
|
||||
|
||||
expect(result.add[0]).toEqual({
|
||||
displayName: 'ChatGLM 6B',
|
||||
@@ -45,7 +52,7 @@ describe('parseModelString', () => {
|
||||
});
|
||||
|
||||
it('token and function calling', () => {
|
||||
const result = parseModelString('spark-v3.5=讯飞星火 v3.5<8192:fc>');
|
||||
const result = parseModelString('test-provider', 'spark-v3.5=讯飞星火 v3.5<8192:fc>');
|
||||
|
||||
expect(result.add[0]).toEqual({
|
||||
displayName: '讯飞星火 v3.5',
|
||||
@@ -59,7 +66,7 @@ describe('parseModelString', () => {
|
||||
});
|
||||
|
||||
it('token and reasoning', () => {
|
||||
const result = parseModelString('deepseek-r1=Deepseek R1<65536:reasoning>');
|
||||
const result = parseModelString('test-provider', 'deepseek-r1=Deepseek R1<65536:reasoning>');
|
||||
|
||||
expect(result.add[0]).toEqual({
|
||||
displayName: 'Deepseek R1',
|
||||
@@ -73,7 +80,7 @@ describe('parseModelString', () => {
|
||||
});
|
||||
|
||||
it('token and search', () => {
|
||||
const result = parseModelString('qwen-max-latest=Qwen Max<32768:search>');
|
||||
const result = parseModelString('test-provider', 'qwen-max-latest=Qwen Max<32768:search>');
|
||||
|
||||
expect(result.add[0]).toEqual({
|
||||
displayName: 'Qwen Max',
|
||||
@@ -88,6 +95,7 @@ describe('parseModelString', () => {
|
||||
|
||||
it('token and image output', () => {
|
||||
const result = parseModelString(
|
||||
'test-provider',
|
||||
'gemini-2.0-flash-exp-image-generation=Gemini 2.0 Flash (Image Generation) Experimental<32768:imageOutput>',
|
||||
);
|
||||
|
||||
@@ -104,6 +112,7 @@ describe('parseModelString', () => {
|
||||
|
||||
it('multi models', () => {
|
||||
const result = parseModelString(
|
||||
'test-provider',
|
||||
'gemini-1.5-flash-latest=Gemini 1.5 Flash<16000:vision>,gpt-4-all=ChatGPT Plus<128000:fc:vision:file>',
|
||||
);
|
||||
|
||||
@@ -133,6 +142,7 @@ describe('parseModelString', () => {
|
||||
|
||||
it('should have file with builtin models like gpt-4-0125-preview', () => {
|
||||
const result = parseModelString(
|
||||
'openai',
|
||||
'-all,+gpt-4-0125-preview=ChatGPT-4<128000:fc:file>,+gpt-4-turbo-2024-04-09=ChatGPT-4 Vision<128000:fc:vision:file>',
|
||||
);
|
||||
expect(result.add).toEqual([
|
||||
@@ -161,7 +171,7 @@ describe('parseModelString', () => {
|
||||
});
|
||||
|
||||
it('should handle empty extension capability value', () => {
|
||||
const result = parseModelString('model1<1024:>');
|
||||
const result = parseModelString('test-provider', 'model1<1024:>');
|
||||
expect(result.add[0]).toEqual({
|
||||
abilities: {},
|
||||
type: 'chat',
|
||||
@@ -171,7 +181,7 @@ describe('parseModelString', () => {
|
||||
});
|
||||
|
||||
it('should handle empty extension capability name', () => {
|
||||
const result = parseModelString('model1<1024::file>');
|
||||
const result = parseModelString('test-provider', 'model1<1024::file>');
|
||||
expect(result.add[0]).toEqual({
|
||||
id: 'model1',
|
||||
contextWindowTokens: 1024,
|
||||
@@ -183,7 +193,7 @@ describe('parseModelString', () => {
|
||||
});
|
||||
|
||||
it('should handle duplicate extension capabilities', () => {
|
||||
const result = parseModelString('model1<1024:vision:vision>');
|
||||
const result = parseModelString('test-provider', 'model1<1024:vision:vision>');
|
||||
expect(result.add[0]).toEqual({
|
||||
id: 'model1',
|
||||
contextWindowTokens: 1024,
|
||||
@@ -195,7 +205,7 @@ describe('parseModelString', () => {
|
||||
});
|
||||
|
||||
it('should handle case-sensitive extension capability names', () => {
|
||||
const result = parseModelString('model1<1024:VISION:FC:file>');
|
||||
const result = parseModelString('test-provider', 'model1<1024:VISION:FC:file>');
|
||||
expect(result.add[0]).toEqual({
|
||||
id: 'model1',
|
||||
contextWindowTokens: 1024,
|
||||
@@ -207,7 +217,7 @@ describe('parseModelString', () => {
|
||||
});
|
||||
|
||||
it('should handle case-sensitive extension capability values', () => {
|
||||
const result = parseModelString('model1<1024:vision:Fc:File>');
|
||||
const result = parseModelString('test-provider', 'model1<1024:vision:Fc:File>');
|
||||
expect(result.add[0]).toEqual({
|
||||
id: 'model1',
|
||||
contextWindowTokens: 1024,
|
||||
@@ -219,12 +229,12 @@ describe('parseModelString', () => {
|
||||
});
|
||||
|
||||
it('should handle empty angle brackets', () => {
|
||||
const result = parseModelString('model1<>');
|
||||
const result = parseModelString('test-provider', 'model1<>');
|
||||
expect(result.add[0]).toEqual({ id: 'model1', abilities: {}, type: 'chat' });
|
||||
});
|
||||
|
||||
it('should handle not close angle brackets', () => {
|
||||
const result = parseModelString('model1<,model2');
|
||||
const result = parseModelString('test-provider', 'model1<,model2');
|
||||
expect(result.add).toEqual([
|
||||
{ id: 'model1', abilities: {}, type: 'chat' },
|
||||
{ id: 'model2', abilities: {}, type: 'chat' },
|
||||
@@ -232,7 +242,7 @@ describe('parseModelString', () => {
|
||||
});
|
||||
|
||||
it('should handle multi close angle brackets', () => {
|
||||
const result = parseModelString('model1<>>,model2');
|
||||
const result = parseModelString('test-provider', 'model1<>>,model2');
|
||||
expect(result.add).toEqual([
|
||||
{ id: 'model1', abilities: {}, type: 'chat' },
|
||||
{ id: 'model2', abilities: {}, type: 'chat' },
|
||||
@@ -240,22 +250,22 @@ describe('parseModelString', () => {
|
||||
});
|
||||
|
||||
it('should handle only colon inside angle brackets', () => {
|
||||
const result = parseModelString('model1<:>');
|
||||
const result = parseModelString('test-provider', 'model1<:>');
|
||||
expect(result.add[0]).toEqual({ id: 'model1', abilities: {}, type: 'chat' });
|
||||
});
|
||||
|
||||
it('should handle only non-digit characters inside angle brackets', () => {
|
||||
const result = parseModelString('model1<abc>');
|
||||
const result = parseModelString('test-provider', 'model1<abc>');
|
||||
expect(result.add[0]).toEqual({ id: 'model1', abilities: {}, type: 'chat' });
|
||||
});
|
||||
|
||||
it('should handle non-digit characters followed by digits inside angle brackets', () => {
|
||||
const result = parseModelString('model1<abc123>');
|
||||
const result = parseModelString('test-provider', 'model1<abc123>');
|
||||
expect(result.add[0]).toEqual({ id: 'model1', abilities: {}, type: 'chat' });
|
||||
});
|
||||
|
||||
it('should handle digits followed by non-colon characters inside angle brackets', () => {
|
||||
const result = parseModelString('model1<1024abc>');
|
||||
const result = parseModelString('test-provider', 'model1<1024abc>');
|
||||
expect(result.add[0]).toEqual({
|
||||
id: 'model1',
|
||||
contextWindowTokens: 1024,
|
||||
@@ -265,7 +275,7 @@ describe('parseModelString', () => {
|
||||
});
|
||||
|
||||
it('should handle digits followed by multiple colons inside angle brackets', () => {
|
||||
const result = parseModelString('model1<1024::>');
|
||||
const result = parseModelString('test-provider', 'model1<1024::>');
|
||||
expect(result.add[0]).toEqual({
|
||||
id: 'model1',
|
||||
contextWindowTokens: 1024,
|
||||
@@ -275,7 +285,7 @@ describe('parseModelString', () => {
|
||||
});
|
||||
|
||||
it('should handle digits followed by a colon and non-letter characters inside angle brackets', () => {
|
||||
const result = parseModelString('model1<1024:123>');
|
||||
const result = parseModelString('test-provider', 'model1<1024:123>');
|
||||
expect(result.add[0]).toEqual({
|
||||
id: 'model1',
|
||||
contextWindowTokens: 1024,
|
||||
@@ -285,7 +295,7 @@ describe('parseModelString', () => {
|
||||
});
|
||||
|
||||
it('should handle digits followed by a colon and spaces inside angle brackets', () => {
|
||||
const result = parseModelString('model1<1024: vision>');
|
||||
const result = parseModelString('test-provider', 'model1<1024: vision>');
|
||||
expect(result.add[0]).toEqual({
|
||||
id: 'model1',
|
||||
contextWindowTokens: 1024,
|
||||
@@ -295,7 +305,7 @@ describe('parseModelString', () => {
|
||||
});
|
||||
|
||||
it('should handle digits followed by multiple colons and spaces inside angle brackets', () => {
|
||||
const result = parseModelString('model1<1024: : vision>');
|
||||
const result = parseModelString('test-provider', 'model1<1024: : vision>');
|
||||
expect(result.add[0]).toEqual({
|
||||
id: 'model1',
|
||||
contextWindowTokens: 1024,
|
||||
@@ -305,9 +315,64 @@ describe('parseModelString', () => {
|
||||
});
|
||||
});
|
||||
|
||||
describe('FAL image models', () => {
|
||||
it('should correctly parse FAL image model ids with slash and custom display names', () => {
|
||||
const result = parseModelString(
|
||||
'fal',
|
||||
'-all,+flux-kontext/dev=KontextDev,+flux-pro/kontext=KontextPro,+flux/schnell=Schnell,+imagen4/preview=Imagen4',
|
||||
);
|
||||
expect(result.add).toEqual([
|
||||
{
|
||||
id: 'flux-kontext/dev',
|
||||
displayName: 'KontextDev',
|
||||
abilities: {},
|
||||
type: 'image',
|
||||
},
|
||||
{
|
||||
id: 'flux-pro/kontext',
|
||||
displayName: 'KontextPro',
|
||||
abilities: {},
|
||||
type: 'image',
|
||||
},
|
||||
{
|
||||
id: 'flux/schnell',
|
||||
displayName: 'Schnell',
|
||||
abilities: {},
|
||||
type: 'image',
|
||||
},
|
||||
{
|
||||
id: 'imagen4/preview',
|
||||
displayName: 'Imagen4',
|
||||
abilities: {},
|
||||
type: 'image',
|
||||
},
|
||||
]);
|
||||
expect(result.removeAll).toBe(true);
|
||||
expect(result.removed).toEqual(['all']);
|
||||
});
|
||||
|
||||
it('should correctly parse FAL image model ids with slash (no displayName)', () => {
|
||||
const result = parseModelString('fal', '-all,+flux-kontext/dev,+flux-pro/kontext');
|
||||
expect(result.add).toEqual([
|
||||
{
|
||||
id: 'flux-kontext/dev',
|
||||
abilities: {},
|
||||
type: 'image',
|
||||
},
|
||||
{
|
||||
id: 'flux-pro/kontext',
|
||||
abilities: {},
|
||||
type: 'image',
|
||||
},
|
||||
]);
|
||||
expect(result.removeAll).toBe(true);
|
||||
expect(result.removed).toEqual(['all']);
|
||||
});
|
||||
});
|
||||
|
||||
describe('deployment name', () => {
|
||||
it('should have no deployment name', () => {
|
||||
const result = parseModelString('model1=Model 1', true);
|
||||
const result = parseModelString('test-provider', 'model1=Model 1', true);
|
||||
expect(result.add[0]).toEqual({
|
||||
id: 'model1',
|
||||
displayName: 'Model 1',
|
||||
@@ -317,7 +382,7 @@ describe('parseModelString', () => {
|
||||
});
|
||||
|
||||
it('should have diff deployment name as id', () => {
|
||||
const result = parseModelString('gpt-35-turbo->my-deploy=GPT 3.5 Turbo', true);
|
||||
const result = parseModelString('azure', 'gpt-35-turbo->my-deploy=GPT 3.5 Turbo', true);
|
||||
expect(result.add[0]).toEqual({
|
||||
id: 'gpt-35-turbo',
|
||||
displayName: 'GPT 3.5 Turbo',
|
||||
@@ -331,6 +396,7 @@ describe('parseModelString', () => {
|
||||
|
||||
it('should handle with multi deployName', () => {
|
||||
const result = parseModelString(
|
||||
'azure',
|
||||
'gpt-4o->id1=GPT-4o,gpt-4o-mini->id2=gpt-4o-mini,o1-mini->id3=O1 mini',
|
||||
true,
|
||||
);
|
||||
@@ -361,6 +427,42 @@ describe('parseModelString', () => {
|
||||
});
|
||||
});
|
||||
|
||||
describe('extractEnabledModels', () => {
|
||||
it('should return undefined when no models are added', () => {
|
||||
const result = extractEnabledModels('test-provider', '-all');
|
||||
expect(result).toBeUndefined();
|
||||
});
|
||||
|
||||
it('should return undefined when modelString is empty', () => {
|
||||
const result = extractEnabledModels('test-provider', '');
|
||||
expect(result).toBeUndefined();
|
||||
});
|
||||
|
||||
it('should return array of model IDs when models are added', () => {
|
||||
const result = extractEnabledModels('test-provider', '+model1,+model2,+model3');
|
||||
expect(result).toEqual(['model1', 'model2', 'model3']);
|
||||
});
|
||||
|
||||
it('should handle mixed add/remove operations and return only added models', () => {
|
||||
const result = extractEnabledModels('test-provider', '+model1,-model2,+model3');
|
||||
expect(result).toEqual(['model1', 'model3']);
|
||||
});
|
||||
|
||||
it('should handle deployment names when withDeploymentName is true', () => {
|
||||
const result = extractEnabledModels(
|
||||
'azure',
|
||||
'+gpt-4->deployment1,+gpt-35-turbo->deployment2',
|
||||
true,
|
||||
);
|
||||
expect(result).toEqual(['gpt-4', 'gpt-35-turbo']);
|
||||
});
|
||||
|
||||
it('should handle complex model strings with custom names', () => {
|
||||
const result = extractEnabledModels('openai', '+gpt-4=Custom GPT-4,+claude-2=Custom Claude');
|
||||
expect(result).toEqual(['gpt-4', 'claude-2']);
|
||||
});
|
||||
});
|
||||
|
||||
describe('transformToChatModelCards', () => {
|
||||
const defaultChatModels: AiFullModelCard[] = [
|
||||
{ id: 'model1', displayName: 'Model 1', enabled: true, type: 'chat' },
|
||||
@@ -368,27 +470,27 @@ describe('transformToChatModelCards', () => {
|
||||
];
|
||||
|
||||
it('should return undefined when modelString is empty', () => {
|
||||
const result = transformToAiChatModelList({
|
||||
const result = transformToAiModelList({
|
||||
modelString: '',
|
||||
defaultChatModels,
|
||||
defaultModels: defaultChatModels,
|
||||
providerId: 'openai',
|
||||
});
|
||||
expect(result).toBeUndefined();
|
||||
});
|
||||
|
||||
it('should remove all models when removeAll is true', () => {
|
||||
const result = transformToAiChatModelList({
|
||||
const result = transformToAiModelList({
|
||||
modelString: '-all',
|
||||
defaultChatModels,
|
||||
defaultModels: defaultChatModels,
|
||||
providerId: 'openai',
|
||||
});
|
||||
expect(result).toEqual([]);
|
||||
});
|
||||
|
||||
it('should remove specified models', () => {
|
||||
const result = transformToAiChatModelList({
|
||||
const result = transformToAiModelList({
|
||||
modelString: '-model1',
|
||||
defaultChatModels,
|
||||
defaultModels: defaultChatModels,
|
||||
providerId: 'openai',
|
||||
});
|
||||
expect(result).toEqual([
|
||||
@@ -398,9 +500,9 @@ describe('transformToChatModelCards', () => {
|
||||
|
||||
it('should add a new known model', () => {
|
||||
const knownModel = LOBE_DEFAULT_MODEL_LIST.find((m) => m.providerId === 'ai21')!;
|
||||
const result = transformToAiChatModelList({
|
||||
const result = transformToAiModelList({
|
||||
modelString: `${knownModel.id}`,
|
||||
defaultChatModels,
|
||||
defaultModels: defaultChatModels,
|
||||
providerId: 'ai21',
|
||||
});
|
||||
|
||||
@@ -413,9 +515,9 @@ describe('transformToChatModelCards', () => {
|
||||
|
||||
it('should update an existing known model', () => {
|
||||
const knownModel = LOBE_DEFAULT_MODEL_LIST.find((m) => m.providerId === 'openai')!;
|
||||
const result = transformToAiChatModelList({
|
||||
const result = transformToAiModelList({
|
||||
modelString: `+${knownModel.id}=Updated Model`,
|
||||
defaultChatModels: [knownModel],
|
||||
defaultModels: [knownModel],
|
||||
providerId: 'openai',
|
||||
});
|
||||
|
||||
@@ -427,9 +529,9 @@ describe('transformToChatModelCards', () => {
|
||||
});
|
||||
|
||||
it('should add a new custom model', () => {
|
||||
const result = transformToAiChatModelList({
|
||||
const result = transformToAiModelList({
|
||||
modelString: '+custom_model=Custom Model',
|
||||
defaultChatModels,
|
||||
defaultModels: defaultChatModels,
|
||||
providerId: 'openai',
|
||||
});
|
||||
expect(result).toContainEqual({
|
||||
@@ -442,10 +544,10 @@ describe('transformToChatModelCards', () => {
|
||||
});
|
||||
|
||||
it('should have file with builtin models like gpt-4-0125-preview', () => {
|
||||
const result = transformToAiChatModelList({
|
||||
const result = transformToAiModelList({
|
||||
modelString:
|
||||
'-all,+gpt-4-0125-preview=ChatGPT-4<128000:fc:file>,+gpt-4-turbo-2024-04-09=ChatGPT-4 Vision<128000:fc:vision:file>',
|
||||
defaultChatModels: openaiChatModels,
|
||||
defaultModels: openaiChatModels,
|
||||
providerId: 'openai',
|
||||
});
|
||||
|
||||
@@ -457,9 +559,9 @@ describe('transformToChatModelCards', () => {
|
||||
(m) => m.id === 'deepseek-r1' && m.providerId === 'volcengine',
|
||||
);
|
||||
const defaultChatModels: AiFullModelCard[] = [];
|
||||
const result = transformToAiChatModelList({
|
||||
const result = transformToAiModelList({
|
||||
modelString: '+deepseek-r1',
|
||||
defaultChatModels,
|
||||
defaultModels: defaultChatModels,
|
||||
providerId: 'volcengine',
|
||||
withDeploymentName: true,
|
||||
});
|
||||
@@ -474,9 +576,9 @@ describe('transformToChatModelCards', () => {
|
||||
const knownModel = LOBE_DEFAULT_MODEL_LIST.find(
|
||||
(m) => m.id === 'deepseek-r1' && m.providerId === 'volcengine',
|
||||
);
|
||||
const result = transformToAiChatModelList({
|
||||
const result = transformToAiModelList({
|
||||
modelString: `+deepseek-r1->my-custom-deploy`,
|
||||
defaultChatModels,
|
||||
defaultModels: defaultChatModels,
|
||||
providerId: 'volcengine',
|
||||
withDeploymentName: true,
|
||||
});
|
||||
@@ -489,9 +591,9 @@ describe('transformToChatModelCards', () => {
|
||||
|
||||
it('should set both id and deploymentName to the full string when no -> is used and withDeploymentName is true', () => {
|
||||
const defaultChatModels: AiFullModelCard[] = [];
|
||||
const result = transformToAiChatModelList({
|
||||
const result = transformToAiModelList({
|
||||
modelString: `+my_model`,
|
||||
defaultChatModels,
|
||||
defaultModels: defaultChatModels,
|
||||
providerId: 'volcengine',
|
||||
withDeploymentName: true,
|
||||
});
|
||||
@@ -602,9 +704,9 @@ describe('transformToChatModelCards', () => {
|
||||
const modelString =
|
||||
'-all,gpt-4o->id1=GPT-4o,gpt-4o-mini->id2=GPT 4o Mini,o1-mini->id3=OpenAI o1-mini';
|
||||
|
||||
const data = transformToAiChatModelList({
|
||||
const data = transformToAiModelList({
|
||||
modelString,
|
||||
defaultChatModels,
|
||||
defaultModels: defaultChatModels,
|
||||
providerId: 'azure',
|
||||
withDeploymentName: true,
|
||||
});
|
||||
|
||||
+26
-11
@@ -1,13 +1,18 @@
|
||||
import { produce } from 'immer';
|
||||
|
||||
import { LOBE_DEFAULT_MODEL_LIST } from '@/config/aiModels';
|
||||
import { AiFullModelCard } from '@/types/aiModel';
|
||||
import { AiFullModelCard, AiModelType } from '@/types/aiModel';
|
||||
import { getModelPropertyWithFallback } from '@/utils/getFallbackModelProperty';
|
||||
import { merge } from '@/utils/merge';
|
||||
|
||||
/**
|
||||
* Parse model string to add or remove models.
|
||||
*/
|
||||
export const parseModelString = (modelString: string = '', withDeploymentName = false) => {
|
||||
export const parseModelString = (
|
||||
providerId: string,
|
||||
modelString: string = '',
|
||||
withDeploymentName = false,
|
||||
) => {
|
||||
let models: AiFullModelCard[] = [];
|
||||
let removeAll = false;
|
||||
const removedModels: string[] = [];
|
||||
@@ -46,12 +51,18 @@ export const parseModelString = (modelString: string = '', withDeploymentName =
|
||||
models.splice(existingIndex, 1);
|
||||
}
|
||||
|
||||
// Use new type lookup function, prioritizing same provider first, then fallback to other providers
|
||||
const modelType: AiModelType = getModelPropertyWithFallback<AiModelType>(
|
||||
id,
|
||||
'type',
|
||||
providerId,
|
||||
);
|
||||
|
||||
const model: AiFullModelCard = {
|
||||
abilities: {},
|
||||
displayName: displayName || undefined,
|
||||
id,
|
||||
// TODO: 临时写死为 chat ,后续基于元数据迭代成对应的类型
|
||||
type: 'chat',
|
||||
type: modelType,
|
||||
};
|
||||
|
||||
if (deploymentName) {
|
||||
@@ -108,21 +119,21 @@ export const parseModelString = (modelString: string = '', withDeploymentName =
|
||||
/**
|
||||
* Extract a special method to process chatModels
|
||||
*/
|
||||
export const transformToAiChatModelList = ({
|
||||
export const transformToAiModelList = ({
|
||||
modelString = '',
|
||||
defaultChatModels,
|
||||
defaultModels,
|
||||
providerId,
|
||||
withDeploymentName = false,
|
||||
}: {
|
||||
defaultChatModels: AiFullModelCard[];
|
||||
defaultModels: AiFullModelCard[];
|
||||
modelString?: string;
|
||||
providerId: string;
|
||||
withDeploymentName?: boolean;
|
||||
}): AiFullModelCard[] | undefined => {
|
||||
if (!modelString) return undefined;
|
||||
|
||||
const modelConfig = parseModelString(modelString, withDeploymentName);
|
||||
let chatModels = modelConfig.removeAll ? [] : defaultChatModels;
|
||||
const modelConfig = parseModelString(providerId, modelString, withDeploymentName);
|
||||
let chatModels = modelConfig.removeAll ? [] : defaultModels;
|
||||
|
||||
// 处理移除逻辑
|
||||
if (!modelConfig.removeAll) {
|
||||
@@ -182,8 +193,12 @@ export const transformToAiChatModelList = ({
|
||||
});
|
||||
};
|
||||
|
||||
export const extractEnabledModels = (modelString: string = '', withDeploymentName = false) => {
|
||||
const modelConfig = parseModelString(modelString, withDeploymentName);
|
||||
export const extractEnabledModels = (
|
||||
providerId: string,
|
||||
modelString: string = '',
|
||||
withDeploymentName = false,
|
||||
) => {
|
||||
const modelConfig = parseModelString(providerId, modelString, withDeploymentName);
|
||||
const list = modelConfig.add.map((m) => m.id);
|
||||
|
||||
if (list.length === 0) return;
|
||||
|
||||
Reference in New Issue
Block a user